使用 IDA 处理 U-Boot 二进制流文件
作者:Hcamael@知道创宇404实验室
时间:2019年11月29日
最近在研究IoT设备的过程中遇到一种情况。一个IoT设备,官方不提供固件包,网上也搜不到相关的固件包,所以我从flash中直接读取。因为系统是VxWorks,能看到flash布局,所以能很容易把uboot/firmware从flash中分解出来。对于firmware的部分前一半左右是通过lzma压缩,后面的一半,是相隔一定的区间有一部分有lzma压缩数据。而固件的符号信息就在这后半部分。因为不知道后半部分是通过什么格式和前半部分代码段一起放入内存的,所以对于我逆向产生了一定的阻碍。所以我就想着看看uboot的逻辑,但是uboot不能直接丢入ida中进行分析,所以有了这篇文章,分析uboot格式,如何使用ida分析uboot。
uboot格式
正常的一个uboot格式应该如下所示:
|
1 2 3 4 5 6 7 |
$ binwalk bootimg.bin DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 13648 0x3550 CRC32 polynomial table, big endian 14908 0x3A3C uImage header, header size: 64 bytes, header CRC: 0x25ED0948, created: 2019-12-02 03:39:51, image size: 54680 bytes, Data Address: 0x80010000, Entry Point: 0x80010000, data CRC: 0x3DFB76CD, OS: Linux, CPU: MIPS, image type: Firmware Image, compression type: lzma, image name: "u-boot image" 14972 0x3A7C LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes |
而这uboot其实还得分为三部分:
1.从0x00 - 0x346C是属于bootstrap的部分
2.0x346C-0x34AC有0x40字节的uboot image的头部信息
3.从0x34AC到结尾才是uboot image的主体,经过lzma压缩后的结果
那么uboot是怎么生成的呢?Github上随便找了一个uboot源码: https://github.com/OnionIoT/uboot,编译安装了一下,查看uboot的生成过程。
1.第一步,把bootstrap和uboot源码使用gcc编译成两个ELF程序,得到bootstrap和uboot
2.第二步,使用objcopy把两个文件分别转换成二进制流文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
$ mips-openwrt-linux-uclibc-objcopy --gap-fill=0xff -O binary bootstrap bootstrap.bin $ mips-openwrt-linux-uclibc-objcopy --gap-fill=0xff -O binary uboot uboot.bin $ binwalk u-boot/bootstrap DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 ELF, 32-bit MSB executable, MIPS, version 1 (SYSV) 13776 0x35D0 CRC32 polynomial table, big endian 28826 0x709A Unix path: /uboot/u-boot/cpu/mips/start_bootstrap.S $ binwalk u-boot/bootstrap.bin DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 13648 0x3550 CRC32 polynomial table, big endian $ binwalk u-boot/u-boot DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 ELF, 32-bit MSB executable, MIPS, version 1 (SYSV) 132160 0x20440 U-Boot version string, "U-Boot 1.1.4 (Dec 2 2019, 11:39:50)" 132827 0x206DB HTML document header 133794 0x20AA2 HTML document footer 134619 0x20DDB HTML document header 135508 0x21154 HTML document footer 135607 0x211B7 HTML document header 137363 0x21893 HTML document footer 137463 0x218F7 HTML document header 138146 0x21BA2 HTML document footer 138247 0x21C07 HTML document header 139122 0x21F72 HTML document footer 139235 0x21FE3 HTML document header 139621 0x22165 HTML document footer 139632 0x22170 CRC32 polynomial table, big endian 179254 0x2BC36 Unix path: /uboot/u-boot/cpu/mips/start.S $ binwalk u-boot/u-boot.bin DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 132032 0x203C0 U-Boot version string, "U-Boot 1.1.4 (Dec 2 2019, 11:39:50)" 132699 0x2065B HTML document header 133666 0x20A22 HTML document footer 134491 0x20D5B HTML document header 135380 0x210D4 HTML document footer 135479 0x21137 HTML document header 137235 0x21813 HTML document footer 137335 0x21877 HTML document header 138018 0x21B22 HTML document footer 138119 0x21B87 HTML document header 138994 0x21EF2 HTML document footer 139107 0x21F63 HTML document header 139493 0x220E5 HTML document footer 139504 0x220F0 CRC32 polynomial table, big endian |
3.把u-boot.bin使用lzma算法压缩,得到u-boot.bin.lzma
|
1 2 3 4 5 |
$ binwalk u-boot/u-boot.bin.lzma DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes |
4.使用mkimage,给u-boot.bin.lzma加上0x40字节的头部信息得到u-boot.lzming
|
1 2 3 4 5 6 |
$ binwalk u-boot/u-boot.lzimg DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 uImage header, header size: 64 bytes, header CRC: 0x25ED0948, created: 2019-12-02 03:39:51, image size: 54680 bytes, Data Address: 0x80010000, Entry Point: 0x80010000, data CRC: 0x3DFB76CD, OS: Linux, CPU: MIPS, image type: Firmware Image, compression type: lzma, image name: "u-boot image" 64 0x40 LZMA compressed data, properties: 0x5D, dictionary size: 33554432 bytes, uncompressed size: 161184 bytes |
5.最后把bootstrap.bin和u-boot.lzming合并到一起,然后根据需要uboot的实际大小,比如需要一个128k的uboot,在末尾使用0xff补齐到128k大小
使用ida处理bootstrap二进制流文件
在上面的结构中,需要注意几点:
1.Data Address: 0x80010000, Entry Point: 0x80010000 表示设备启动后,会把后续uboot通过lzma解压出来的数据存入内存地址0x80010000,然后把$pc设置为: 0x80010000,所以uboot最开头4字节肯定是指令。
2.uncompressed size: 161184 bytes,可以使用dd把LZMA数据单独取出来,然后使用lzma解压缩,解压缩后的大小要跟这个字段一样。如果还想确认解压缩的结果有没有问题,可以使用CRC算法验证。
接下来就是通过dd或者其他程序把二进制流从uboot中分离出来,再丢到ida中。先来看看bootstrap,首先指定相应的CPU类型,比如对于上例,则需要设置MIPS大端。
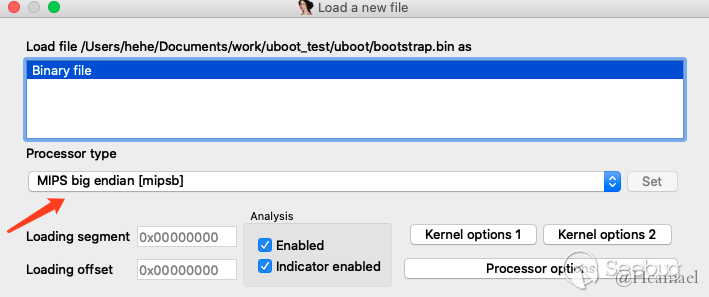
随后我们暂时设置一下起始地址为0x80010000,通电以后CPU第一个执行的地址默认情况下我们是不知道的,不同CPU有不同的起始地址。设置如下图所示:
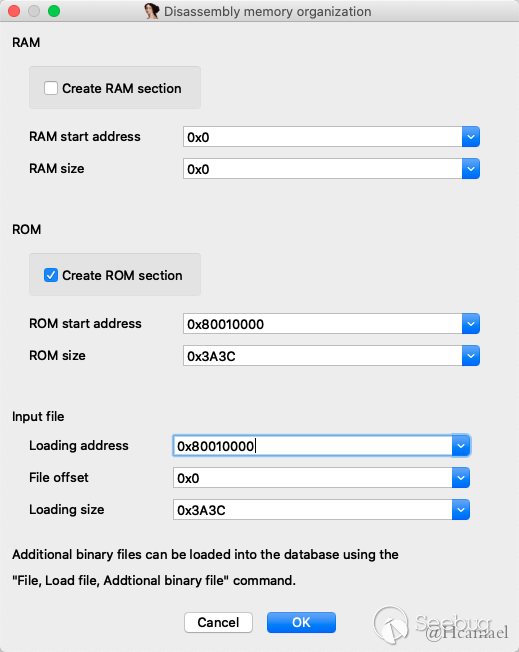
bootstrap最开头也指令,所以按C转换成指令,如下图所示:

跳转到0x80010400, 随后是一段初始化代码,下一步我们需要确定程序基地址,因为是mips,所以我们可以根据$gp来判断基地址。
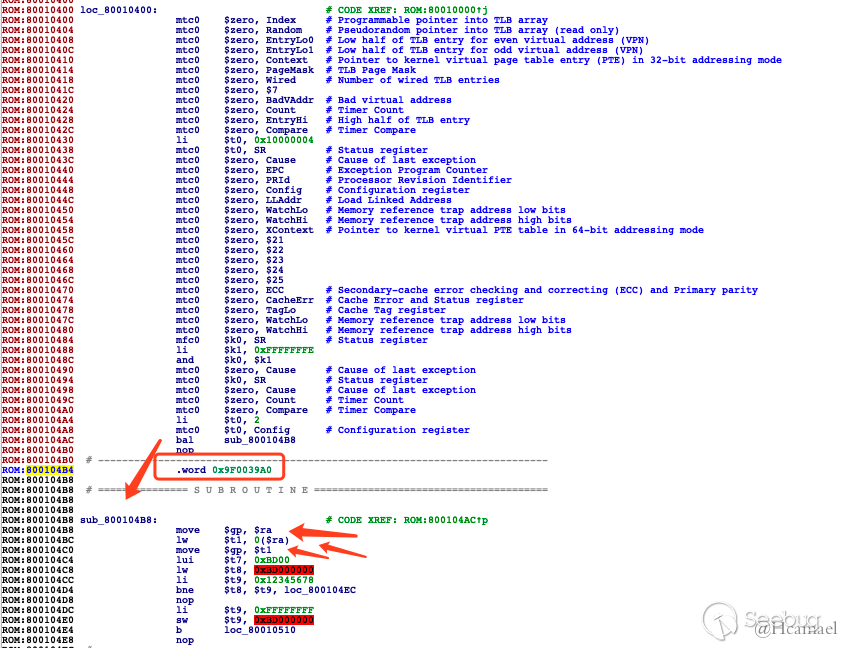
如上图所示,因为bootstrap的大小为0x3a3c bytes,所以可以初步估计基地址为0x9f000000,所以下面修改一下基地址:
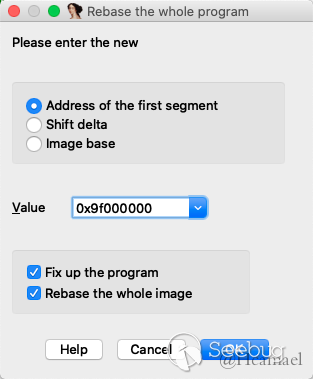
并且修改在Options -> General -> Analysis -> Processor specific ......设置$gp=0x9F0039A0
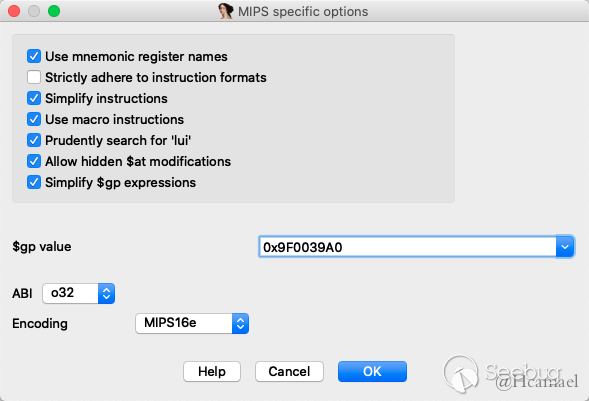
0x9F0039A0地址开始属于got表的范围,存储的是函数地址,所以把0x9F0039A0地址往后的数据都转成word:

到此就处理完毕了,后面就是存逆向的工作了,具体bootstrap代码都做了什么,不是本文的重点,所以暂不管。
使用ida处理uboot流文件
处理bootstrap,我们再看看uboot,和上面的处理思路大致相同。
1.使用dd或其他程序,把uboot数据先分离出来。 2.使用lzma解压缩 3.丢到ida,设置CPU类型,设置基地址,因为uboot头部有明确定义基地址为0x80010000,所以不用再自己判断基地址 4.同样把第一句设置为指令
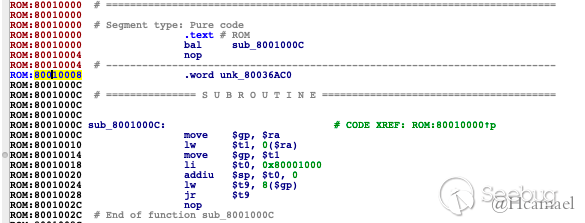
正常情况下,uboot都是这种格式,0x80010008为got表指针,也是$gp的值。
5.根据0x80010008的值,去设置$gp 6.处理got表,该地址往后基本都是函数指针和少部分的字符串指针。结尾还有uboot命令的结构体。
到此uboot也算基础处理完了,后续也都是逆向的工作了,也不是本文的关注的内容。
编写idapython自动处理uboot
拿uboot的处理流程进行举例,使用Python编写一个ida插件,自动处理uboot二进制流文件。
1.我们把0x80010000设置为__start函数
|
1 2 |
idc.add_func(0x80010000) idc.set_name(0x80010000, "__start") |
2.0x80010008是got表指针,因为我们处理了0x80010000,所以got表指针地址也被自动翻译成了代码,我们需要改成word格式。
|
1 2 3 4 |
idc.del_items(0x80010008) idc.MakeDword(0x80010008) got_ptr = idc.Dword(0x80010008) idc.set_name(idc.Dword(0x80010008), ".got.ptr") |
3.把got表都转成Word格式,如果是字符串指针,在注释中体现出来
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def got(): assert(got_ptr) for address in range(got_ptr, end_addr, 4): value = idc.Dword(address) if value == 0xFFFFFFFF:2019-12-03 15:36:56 星期二 break idc.MakeDword(address) idaapi.autoWait() if idc.Dword(value) != 0xFFFFFFFF: func_name = idc.get_func_name(value) if not idc.get_func_name(value): idc.create_strlit(value, idc.BADADDR) else: funcs.append(func_name) |
基本都这里就ok了,后面还可以加一些.text段信息,但不是必要的,最后的源码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
#!/usr/bin/env python # -*- coding=utf-8 -*- import idc import idaapi class Anlysis: def __init__(self): self.start_addr = idc.MinEA() self.end_addr = idc.MaxEA() self.funcs = [] def uboot_header(self): idc.add_func(self.start_addr) idc.set_name(self.start_addr, "__start") idc.del_items(self.start_addr + 0x8) idc.MakeDword(self.start_addr + 0x8) self.got_ptr = idc.Dword(self.start_addr+8) idc.set_name(idc.Dword(self.start_addr+8), ".got.ptr") def got(self): assert(self.got_ptr) for address in range(self.got_ptr, self.end_addr, 4): value = idc.Dword(address) if value == 0xFFFFFFFF: break idc.MakeDword(address) idaapi.autoWait() if idc.Dword(value) != 0xFFFFFFFF: func_name = idc.get_func_name(value) if not idc.get_func_name(value): idc.create_strlit(value, idc.BADADDR) else: self.funcs.append(func_name) def get_max_text_addr(self): assert(self.funcs) max_addr = 0 for func_name in self.funcs: addr = idc.get_name_ea_simple(func_name) end_addr = idc.find_func_end(addr) if end_addr > max_addr: max_addr = end_addr if max_addr % 0x10 == 0: self.max_text_addr = max_addr else: self.max_text_addr = max_addr + 0x10 - (max_addr % 0x10) def add_segment(self, start, end, name, type_): segment = idaapi.segment_t() segment.startEA = start segment.endEA = end segment.bitness = 1 idaapi.add_segm_ex(segment, name, type_, idaapi.ADDSEG_SPARSE | idaapi.ADDSEG_OR_DIE) def start(self): # text seg self.uboot_header() self.got() self.get_max_text_addr() self.add_segment(self.start_addr, self.max_text_addr, ".text", "CODE") # end idc.jumpto(self.start_addr) if __name__ == "__main__": print("Hello World") |

本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1090/