网站隐患解决系列2_被报挂马后的查找去除1——ua和refer作弊
网站在被黑的情况下,也许会在站长不知情的情况下进行了ua和refer作弊
以下提供相关的技术点供站长进行排查
1、针对ua作弊:
通常称为Cloaking,指的是作弊者通过区分搜索引擎爬虫和用户浏览器,展示不同内容的手段,主要是为了欺骗搜索引擎。
cloaking介绍:http://baike.baidu.com/view/1979085.htm
判断方法:需要修改自己的浏览器设置,以搜索引擎爬虫的方式来浏览网页,打开火狐,Ctrl+T新建一个浏览标签,输入:about:config,打开配置页面,右键点击页面选择“新建→字符串”,在弹出的窗口中 输入:general.useragent.override,确定之后,输入:Googlebot/2.1,继续确定,关闭窗口。
用百度蜘蛛爬这些网页,就是坏网页。浏览器直接访问,就是好网页。
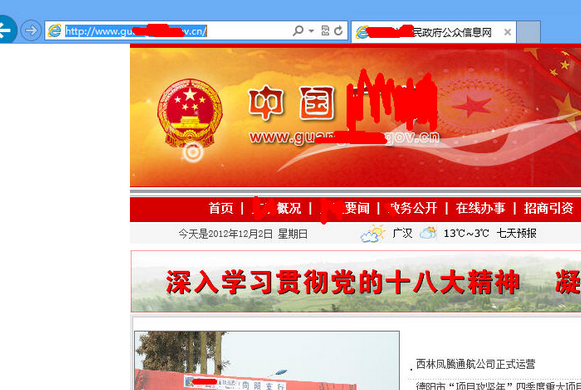
如站点:http://www。guangh**。gov。cn/
使用浏览器访问,这是个正常的政府网站,的确代码页不存在问题,如图
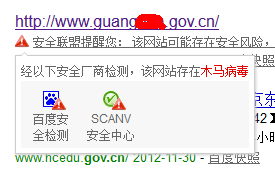
那为什么又被百度和scanv报挂马拦截了呢?不是scanv误报了这个网站
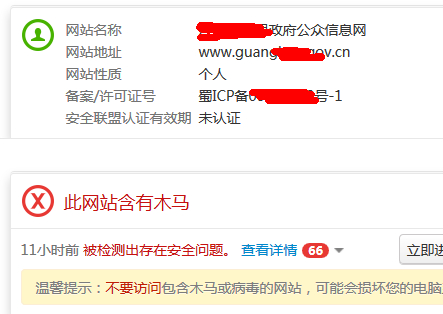
我想如果站长不明事理,估计也该骂百度和scanv了
我们按照1的判断 方法试试把
用火狐浏览器修改配置
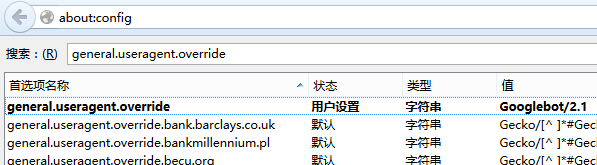

现在呢?是不是页面变了?
这就是Cloaking
那么要怎么解决呢?
我们先看看它的实现方法,看看百科怎么说
Cloaking实现方法:
使用iis rewrite服务器伪静态工具,可以实现根据用户浏览器类别进行跳转 ,也就是当访问此页面的类型是Googlebot/2.1或Baiduspider那么执行命令跳转相应黑页:
RewriteCond %{HTTP_USER_AGENT}Java/1.6.0-oem(Java/1.6.0-oem就好比Googlebot/2.1) RewriteRule ^/(.*)1 [F]
那么要解决也就很简单,找到对应的项,去掉对应的rewrite,去掉对应的页面就OK了
2、针对refer作弊:
作弊者通过判断流量refer,区分来自搜索引擎的流量还是其它流量。一般作弊者的目标流量都是搜索引擎流量,所以需要通过refer来判断流量是否有价值。
判断方法:通过百度搜url,并加上关键词。
用户通过百度访问这些url就能跳转到坏网站,直接通过浏览器访问就不能复现跳转。
这个的问题也是出在代码,一般js/header等,找到首页或者其他通用模块的代码中的这个代码去除掉就能解决
如:http://www.yyrb.cn/xwzx/news/6218.html
直接访问这个网址
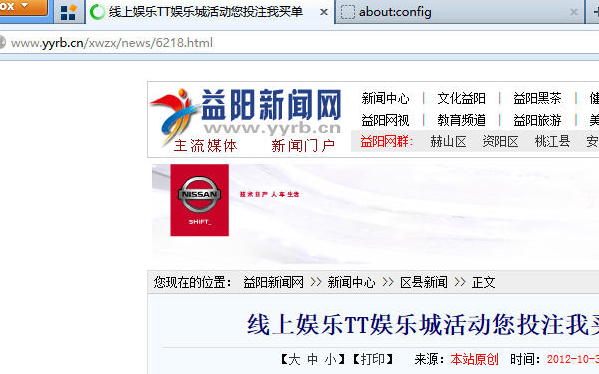
可以看到是个新闻网
大家可以百度搜索这个网址,只有一个结果,点击访问
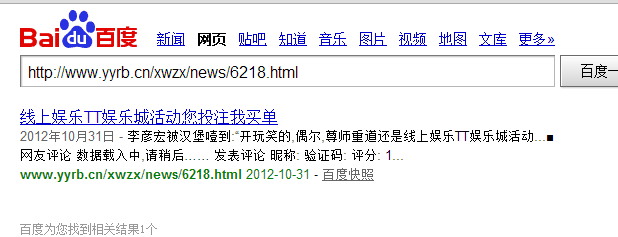
进入后,网址直接跳转了
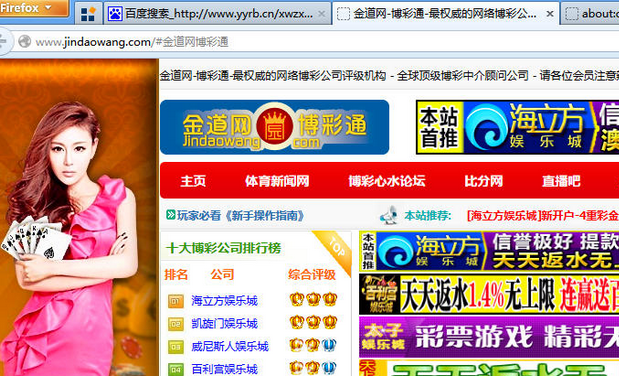
清除方法刚才说了,这个的问题也是出在代码,一般js/header等,找到首页或者其他通用模块的代码中的这个代码去除掉就能解决
3条评论
This is a test”>
没有把码打好。亲,你再打一次吧。
很感谢分享,学习了…